
1. مقدمة
في هذا التمرين العملي، ستتعلّم كيفية تنفيذ سير العمل الكامل لعملية التحسين الدقيق الخاضعة للإشراف على نموذج Google Gemini لتكييفه مع مهمة معيّنة، وهي تلخيص المقالات. على الرغم من أنّ النماذج اللغوية الكبيرة فعّالة، إلا أنّ طبيعتها العامة تعني أنّه يمكن جعلها أكثر فعالية لحالات استخدام معيّنة من خلال الضبط الدقيق. من خلال تدريب النموذج على مجموعة بيانات عالية الجودة تتضمّن أمثلة، يمكنك تحسين اتساقه وجودته وفعاليته في المهمة المستهدَفة.
ستستخدم Gemini 2.5 Flash، وهو نموذج خفيف الوزن وفعّال من حيث التكلفة، وستجري عملية الضبط الدقيق باستخدام Vertex AI.
نظرة عامة على الهندسة المعمارية
في ما يلي ما سننشئه:
- Cloud Shell: بيئة التطوير
- Cloud Storage: لتخزين بيانات التدريب/التحقّق بتنسيق JSONL
- Vertex AI Training: تدير مهمة الضبط الدقيق.
- نقطة نهاية Vertex AI: تستضيف النموذج الذي تم ضبطه بدقة.
أهداف الدورة التعليمية
- إعداد مجموعات بيانات عالية الجودة لضبط النموذج بدقة بإشراف
- إعداد مهام الضبط الدقيق وتشغيلها باستخدام Vertex AI SDK للغة Python
- تقييم النماذج باستخدام مقاييس مبرمَجة (نتائج ROUGE)
- قارِن بين النماذج الأساسية والنماذج المعدَّلة لتحديد التحسينات.
2. إعداد المشروع
حساب Google
إذا لم يكن لديك حساب Google شخصي، عليك إنشاء حساب على Google.
استخدام حساب شخصي بدلاً من حساب تابع للعمل أو تديره مؤسسة تعليمية
تسجيل الدخول إلى Google Cloud Console
سجِّل الدخول إلى Google Cloud Console باستخدام حساب Google شخصي.
تفعيل الفوترة
تحصيل قيمة أرصدة Google Cloud (اختياري)
لإجراء ورشة العمل هذه، يجب أن يكون لديك حساب فوترة يتضمّن بعض الرصيد. استخدِم الرصيد من البانر في أعلى هذا الدرس التطبيقي للبدء. إذا كنت مرتبطًا بحساب فوترة، يمكنك تخطّي هذه الخطوة.
إنشاء مشروع (اختياري)
إذا لم يكن لديك مشروع حالي تريد استخدامه في هذا المختبر، يمكنك إنشاء مشروع جديد هنا.
3- فتح "محرّر Cloud Shell"
- انقر على هذا الرابط للانتقال مباشرةً إلى محرّر Cloud Shell
- إذا طُلب منك منح الإذن في أي وقت اليوم، انقر على منح الإذن للمتابعة.
- إذا لم تظهر المحطة الطرفية في أسفل الشاشة، افتحها باتّباع الخطوات التالية:
- انقر على عرض.
- انقر على Terminal
- في الوحدة الطرفية، اضبط مشروعك باستخدام الأمر التالي:
gcloud config set project [PROJECT_ID]- مثال:
gcloud config set project lab-project-id-example - إذا تعذّر عليك تذكُّر رقم تعريف مشروعك، يمكنك إدراج جميع أرقام تعريف المشاريع باستخدام:
gcloud projects list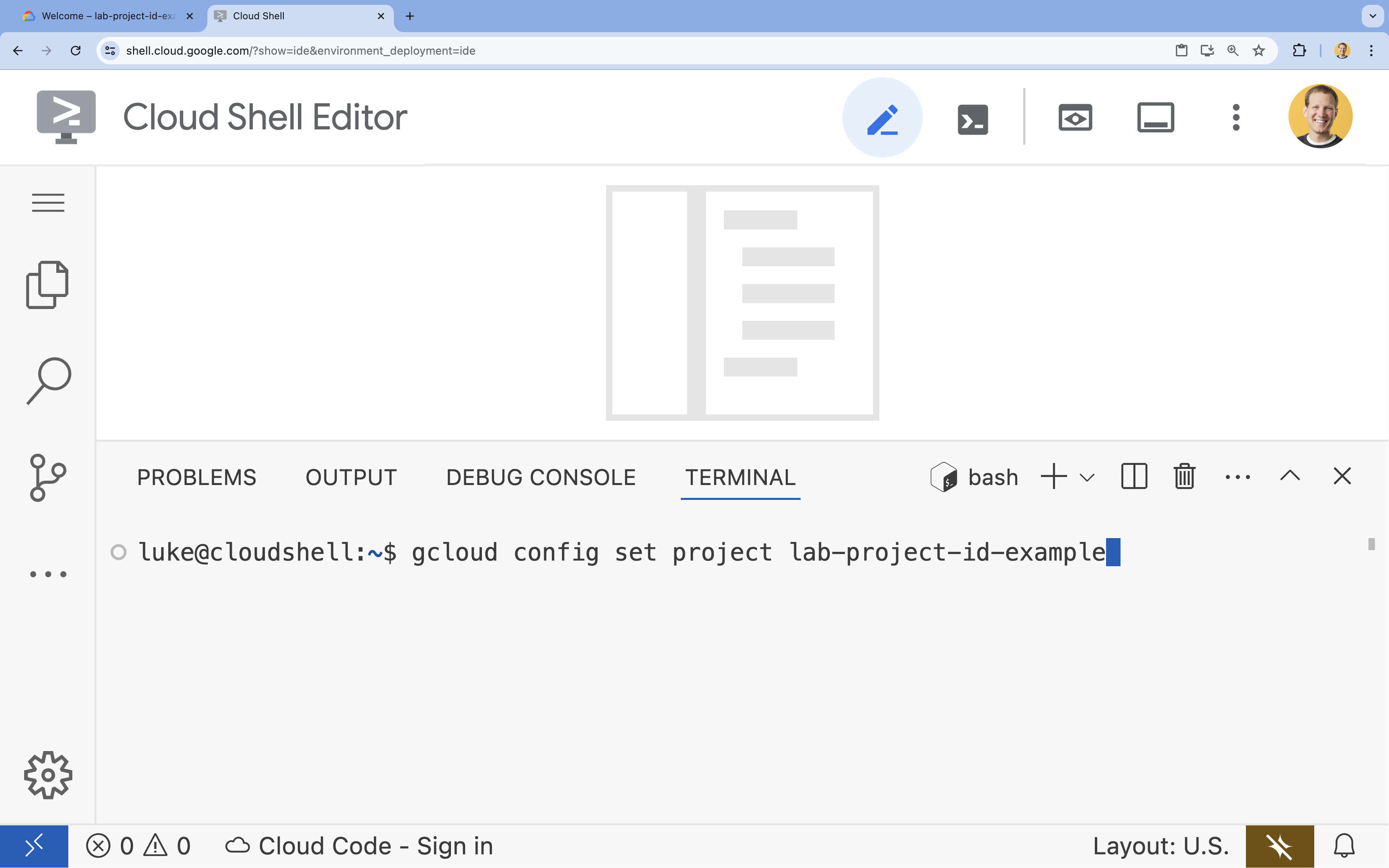
- مثال:
- من المفترض أن تظهر لك هذه الرسالة:
Updated property [core/project].
4. تفعيل واجهات برمجة التطبيقات
لاستخدام Vertex AI والخدمات الأخرى، عليك تفعيل واجهات برمجة التطبيقات اللازمة في مشروعك على Google Cloud.
- في نافذة الوحدة الطرفية، فعِّل واجهات برمجة التطبيقات:
- واجهة برمجة التطبيقات Vertex AI API (
aiplatform.googleapis.com): تتيح استخدام Vertex AI لضبط النماذج بدقة وتقديمها. - واجهة برمجة التطبيقات في Cloud Storage (
storage.googleapis.com): تتيح تخزين مجموعات البيانات وعناصر النموذج.
gcloud services enable aiplatform.googleapis.com \ storage.googleapis.com - واجهة برمجة التطبيقات Vertex AI API (
5- إعداد بيئة المشروع
إنشاء دليل عمل
- في نافذة الأوامر الطرفية، أنشئ دليلاً لمشروعك وانتقِل إليه.
mkdir gemini-finetuning cd gemini-finetuning
إعداد متغيرات البيئة
- في وحدة التحكّم، حدِّد متغيّرات البيئة لمشروعك. سننشئ ملف
env.shلتخزين هذه المتغيرات حتى يمكن إعادة تحميلها بسهولة في حال انقطاع الاتصال بالجلسة.cat <<EOF > env.sh export PROJECT_ID=\$(gcloud config get-value project) export REGION="us-central1" export BUCKET_NAME="\${PROJECT_ID}-gemini-tuning" EOF source env.sh
إنشاء حزمة في Cloud Storage
- في وحدة التحكّم، أنشئ حزمة لتخزين مجموعة البيانات وعناصر النموذج.
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION
إعداد البيئة الافتراضية
- سنستخدم
uvلإدارة بيئة Python. في الوحدة الطرفية، شغِّل الأمر التالي:uv venv .venv source .venv/bin/activate - في وحدة التحكّم، ثبِّت حِزم Python المطلوبة.
uv pip install google-cloud-aiplatform rouge-score matplotlib pandas tqdm
6. إعداد بيانات التدريب
تُعدّ البيانات عالية الجودة أساسًا لعملية الضبط الدقيق الناجحة. ستستخدم مجموعة بيانات WikiLingua، وتحوّلها إلى تنسيق JSONL المحدّد الذي يتطلّبه Gemini، ثم تحمّلها إلى حزمة التخزين.
- في وحدة التحكّم، أنشئ ملفًا باسم
prepare_data.py.cloudshell edit prepare_data.py - ألصِق الرمز التالي في
prepare_data.py.import json import os import pandas as pd from google.cloud import storage import subprocess # Configuration BUCKET_NAME = os.environ["BUCKET_NAME"] PROJECT_ID = os.environ["PROJECT_ID"] def download_data(): print("Downloading WikiLingua dataset...") # Using gsutil to copy from public bucket subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/*", "."], check=True) def convert_to_gemini_format(input_file, output_file, max_samples=1000): print(f"Converting {input_file} to Gemini format (first {max_samples} samples)...") converted_data = [] with open(input_file, 'r') as f: for i, line in enumerate(f): if i >= max_samples: break obj = json.loads(line) messages = obj.get("messages", []) # Convert messages to Gemini 2.5 format # Input: {"messages": [{"role": "user", "content": "..."}, {"role": "model", "content": "..."}]} # Output: {"contents": [{"role": "user", "parts": [{"text": "..."}]}, {"role": "model", "parts": [{"text": "..."}]}]} contents = [] for msg in messages: role = msg["role"] content = msg["content"] contents.append({ "role": role, "parts": [{"text": content}] }) converted_data.append({"contents": contents}) with open(output_file, 'w') as f: for item in converted_data: f.write(json.dumps(item) + "\n") print(f"Saved {len(converted_data)} examples to {output_file}") def upload_to_gcs(local_file, destination_blob_name): print(f"Uploading {local_file} to gs://{BUCKET_NAME}/{destination_blob_name}...") storage_client = storage.Client(project=PROJECT_ID) bucket = storage_client.bucket(BUCKET_NAME) blob = bucket.blob(destination_blob_name) blob.upload_from_filename(local_file) print("Upload complete.") def main(): download_data() # Process Training Data convert_to_gemini_format("sft_train_samples.jsonl", "train_gemini.jsonl") upload_to_gcs("train_gemini.jsonl", "datasets/train/train_gemini.jsonl") # Process Validation Data convert_to_gemini_format("sft_val_samples.jsonl", "val_gemini.jsonl") upload_to_gcs("val_gemini.jsonl", "datasets/val/val_gemini.jsonl") print("Data preparation complete!") if __name__ == "__main__": main() - في الوحدة الطرفية، شغِّل البرنامج النصي لإعداد البيانات.
python prepare_data.py
7. تحديد الأداء الأساسي
قبل إجراء عملية الضبط الدقيق، تحتاج إلى معيار. ستقيس مدى جودة أداء النموذج الأساسي gemini-2.5-flash في مهمة التلخيص باستخدام نتائج ROUGE.
- في وحدة التحكّم، أنشئ ملفًا باسم
evaluate.py.cloudshell edit evaluate.py - ألصِق الرمز التالي في
evaluate.py.import argparse import json import os import pandas as pd from google.cloud import aiplatform import vertexai from vertexai.generative_models import GenerativeModel, GenerationConfig, HarmCategory, HarmBlockThreshold from rouge_score import rouge_scorer from tqdm import tqdm import matplotlib.pyplot as plt import time # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] aiplatform.init(project=PROJECT_ID, location=REGION) def evaluate(model_name, test_file, max_samples=50, output_json="results.json"): print(f"Evaluating model: {model_name}") # Load Test Data test_df = pd.read_csv(test_file) test_df = test_df.head(max_samples) model = GenerativeModel(model_name) safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, } generation_config = GenerationConfig( temperature=0.1, max_output_tokens=1024, ) scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True) results = [] for index, row in tqdm(test_df.iterrows(), total=len(test_df)): input_text = row['input_text'] reference_summary = row['output_text'] try: response = model.generate_content( input_text, generation_config=generation_config, safety_settings=safety_settings ) generated_summary = response.text scores = scorer.score(reference_summary, generated_summary) results.append({ "generated": generated_summary, "reference": reference_summary, "rouge1": scores['rouge1'].fmeasure, "rouge2": scores['rouge2'].fmeasure, "rougeL": scores['rougeL'].fmeasure }) except Exception as e: print(f"Error processing example {index}: {e}") # Sleep briefly to avoid quota issues if hitting limits time.sleep(1) # Save results with open(output_json, 'w') as f: json.dump(results, f, indent=2) return pd.DataFrame(results) def plot_results(df, title, filename): os.makedirs("plots", exist_ok=True) metrics = ['rouge1', 'rouge2', 'rougeL'] fig, axes = plt.subplots(1, 3, figsize=(15, 5)) for i, metric in enumerate(metrics): axes[i].hist(df[metric], bins=10, alpha=0.7, color='skyblue', edgecolor='black') axes[i].set_title(f'{metric} Distribution') axes[i].set_xlabel('Score') axes[i].set_ylabel('Count') plt.suptitle(title) plt.tight_layout() plt.savefig(f"plots/{filename}") print(f"Plot saved to plots/{filename}") def compare_results(baseline_file, tuned_file): with open(baseline_file, 'r') as f: baseline_data = pd.DataFrame(json.load(f)) with open(tuned_file, 'r') as f: tuned_data = pd.DataFrame(json.load(f)) print("\n--- Comparison ---") metrics = ['rouge1', 'rouge2', 'rougeL'] for metric in metrics: base_mean = baseline_data[metric].mean() tuned_mean = tuned_data[metric].mean() diff = tuned_mean - base_mean print(f"{metric}: Base={base_mean:.4f}, Tuned={tuned_mean:.4f}, Diff={diff:+.4f}") # Comparative Plot os.makedirs("plots", exist_ok=True) comparison_df = pd.DataFrame({ 'Metric': metrics, 'Baseline': [baseline_data[m].mean() for m in metrics], 'Tuned': [tuned_data[m].mean() for m in metrics] }) comparison_df.plot(x='Metric', y=['Baseline', 'Tuned'], kind='bar', figsize=(10, 6)) plt.title('Baseline vs Tuned Model Performance') plt.ylabel('Average Score') plt.xticks(rotation=0) plt.tight_layout() plt.savefig("plots/comparison.png") print("Comparison plot saved to plots/comparison.png") def main(): parser = argparse.ArgumentParser() parser.add_argument("--model", type=str, default="gemini-2.5-flash", help="Model resource name") parser.add_argument("--baseline", type=str, help="Path to baseline results json for comparison") parser.add_argument("--output", type=str, default="results.json", help="Output file for results") args = parser.parse_args() # Ensure test data exists (it was downloaded in prepare_data step) if not os.path.exists("sft_test_samples.csv"): # Fallback download if needed subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/sft_test_samples.csv", "."], check=True) df = evaluate(args.model, "sft_test_samples.csv", output_json=args.output) print("\n--- Results Summary ---") print(df.describe()) plot_filename = "baseline_dist.png" if not args.baseline else "tuned_dist.png" plot_results(df, f"ROUGE Scores - {args.model}", plot_filename) if args.baseline: compare_results(args.baseline, args.output) if __name__ == "__main__": main() - في الوحدة الطرفية، شغِّل التقييم الأساسي.
python evaluate.py --model "gemini-2.5-flash" --output "baseline.json"baseline.jsonومخطّط فيplots/baseline_dist.png.
8. ضبط عملية الضبط الدقيق وبدءها
الآن، ستطلق مهمة ضبط دقيق مُدارة على Vertex AI.
- في وحدة التحكّم، أنشئ ملفًا باسم
tune.py.cloudshell edit tune.py - ألصِق الرمز التالي في
tune.py.import os import time from google.cloud import aiplatform import vertexai from vertexai.preview.tuning import sft # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] BUCKET_NAME = os.environ["BUCKET_NAME"] aiplatform.init(project=PROJECT_ID, location=REGION) def train(): print("Launching fine-tuning job...") sft_tuning_job = sft.train( source_model="gemini-2.5-flash", # Using specific version for stability train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl", validation_dataset=f"gs://{BUCKET_NAME}/datasets/val/val_gemini.jsonl", epochs=1, # Keep it short for the lab adapter_size=4, learning_rate_multiplier=1.0, tuned_model_display_name="gemini-2.5-flash-wikilingua", ) print(f"Job started: {sft_tuning_job.resource_name}") print("Waiting for job to complete... (this may take ~45 minutes)") # Wait for the job to complete while not sft_tuning_job.has_ended: time.sleep(60) sft_tuning_job.refresh() print(f"Status: {sft_tuning_job.state.name}") print("Job completed!") print(f"Tuned Model Endpoint: {sft_tuning_job.tuned_model_endpoint_name}") return sft_tuning_job.tuned_model_endpoint_name if __name__ == "__main__": train() - في النافذة الطرفية، شغِّل النص البرمجي لضبط النموذج.
python tune.py
9- فهم رمز التدريب
أثناء تنفيذ مهمتك، لنلقِ نظرة فاحصة على النص البرمجي tune.py لفهم كيفية عمل الضبط الدقيق.
الضبط الدقيق الخاضع للإشراف والمدار
يستخدم النص البرمجي طريقة vertexai.tuning.sft.train لإرسال مهمة ضبط مُدارة. ويؤدي ذلك إلى إخفاء تعقيد توفير البنية الأساسية وتوزيع التدريب وإدارة نقاط التفتيش.
sft_tuning_job = sft.train(
source_model="gemini-2.5-flash",
train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl",
# ...
)
إعدادات LoRA
بدلاً من تحديد LoraConfig يدويًا كما تفعل في أُطر المصدر المفتوح، يسهّل Vertex AI هذه العملية من خلال بضع مَعلمات رئيسية:
-
adapter_size: تتحكّم هذه المَعلمة (التي تم ضبطها على4في النص البرمجي) في ترتيب مهايئات LoRA. يسمح الحجم الأكبر للنموذج بتعلُّم عمليات تكييف أكثر تعقيدًا، ولكنّه يزيد من عدد المَعلمات القابلة للتدريب. epochs: ضبطنا هذه القيمة على1في هذا المختبر لإبقاء مدة التدريب قصيرة (حوالي 20 دقيقة). في سيناريو الإنتاج، يمكنك زيادة هذا العدد للسماح للنموذج بالتعلم بشكل أعمق من بياناتك، ولكن يجب الانتباه إلى الإفراط في التكيّف.
اختيار النموذج
نحدّد قيمة source_model="gemini-2.5-flash" بشكل صريح. تتوافق Vertex AI مع إصدارات مختلفة من Gemini، ويضمن تثبيت إصدار معيّن بقاء مسار البيانات ثابتًا وقابلاً للتكرار.
10. مقارنة النماذج
بعد اكتمال مهمة الضبط الدقيق، يمكنك مقارنة أداء النموذج الجديد بالأداء الأساسي.
- احصل على نقطة نهاية النموذج المضبوط. تمت طباعته في نهاية نص
tune.py. سيبدو على النحو التالي:projects/.../locations/.../endpoints/.... - نفِّذ نص التقييم البرمجي مرة أخرى، ولكن هذه المرة مرِّر النموذج المعدَّل والنتائج الأساسية للمقارنة.
# Replace [YOUR_TUNED_MODEL_ENDPOINT] with the actual endpoint name export TUNED_MODEL="projects/[YOUR_PROJECT_ID]/locations/[YOUR_REGION]/endpoints/[YOUR_ENDPOINT_ID]" python evaluate.py --model "$TUNED_MODEL" --baseline "baseline.json" --output "tuned.json" - اطّلِع على النتائج. سيُخرج النص البرمجي مقارنة بين نتائج ROUGE وينشئ رسمًا بيانيًا
plots/comparison.pngيعرض التحسّن.يمكنك عرض الرسومات البيانية من خلال فتح المجلدplotsفي Cloud Shell Editor.
11. تَنظيم
لتجنُّب تحمّل رسوم، احذف الموارد التي أنشأتها.
- في وحدة التحكّم، احذف حزمة Cloud Storage والنموذج المعدَّل.
gcloud storage rm -r gs://$BUCKET_NAME # Note: You can delete the model endpoint from the Vertex AI Console
12. تهانينا!
لقد تم ضبط نموذج Gemini 2.5 Flash على Vertex AI بنجاح.
ملخّص
في هذا التمرين العملي، عليك:
- أعددتُ مجموعة بيانات بتنسيق JSONL لضبط Gemini بدقة.
- تحديد مستوى أداء أساسي باستخدام نموذج Gemini 2.5 Flash الأساسي
- تم إطلاق مهمة ضبط دقيق خاضعة للإشراف على Vertex AI.
- تم تقييم النموذج المعدَّل ومقارنته بالنموذج الأساسي.
الخطوات التالية
يشكّل هذا المختبر جزءًا من المسار التعليمي الذكاء الاصطناعي الجاهز للإنتاج باستخدام Google Cloud.
استكشاف المنهج الدراسي الكامل لسدّ الفجوة بين النموذج الأوّلي والإنتاج
شارِك مستوى تقدّمك باستخدام الهاشتاغ #ProductionReadyAI.