
۱. مقدمه
در این آزمایشگاه، شما یاد میگیرید که گردش کار کامل تنظیم دقیق نظارتشده را روی یک مدل Google Gemini انجام دهید تا آن را برای یک کار خاص تطبیق دهید: خلاصهسازی مقاله. در حالی که مدلهای زبانی بزرگ قدرتمند هستند، ماهیت عمومی آنها به این معنی است که میتوان آنها را از طریق تنظیم دقیق، برای موارد استفاده خاص، حتی مؤثرتر کرد. با آموزش مدل روی یک مجموعه داده با کیفیت بالا از مثالها، میتوانید سازگاری، کیفیت و کارایی آن را برای کار هدف خود بهبود بخشید.
شما از Gemini 2.5 Flash ، یک مدل سبک و مقرون به صرفه، استفاده خواهید کرد و تنظیم دقیق را با استفاده از Vertex AI انجام خواهید داد.
نمای کلی معماری
این چیزی است که ما خواهیم ساخت:
- پوسته ابری : محیط توسعه شما.
- فضای ذخیرهسازی ابری : دادههای آموزش/اعتبارسنجی را با فرمت JSONL ذخیره میکند.
- آموزش هوش مصنوعی ورتکس : کار تنظیم دقیق را مدیریت میکند.
- Vertex AI Endpoint : میزبان مدل تنظیمشدهی دقیق شما است.
آنچه یاد خواهید گرفت
- مجموعه دادههای با کیفیت بالا را برای تنظیم دقیق تحت نظارت آماده کنید.
- با استفاده از Vertex AI SDK برای پایتون، کارهای تنظیم دقیق را پیکربندی و اجرا کنید.
- مدلها را با استفاده از معیارهای خودکار (نمرات ROUGE) ارزیابی کنید.
- مدلهای پایه و مدلهای تنظیمشده دقیق را برای سنجش بهبودها مقایسه کنید.
۲. راهاندازی پروژه
حساب گوگل
اگر از قبل حساب گوگل شخصی ندارید، باید یک حساب گوگل ایجاد کنید .
به جای حساب کاری یا تحصیلی از حساب شخصی استفاده کنید .
ورود به کنسول ابری گوگل
با استفاده از یک حساب کاربری شخصی گوگل، وارد کنسول ابری گوگل شوید.
فعال کردن صورتحساب
استفاده از اعتبار گوگل کلود (اختیاری)
برای اجرای این کارگاه، به یک حساب صورتحساب با مقداری اعتبار نیاز دارید. برای شروع از اعتبارهای موجود در بنر بالای این codelab استفاده کنید. اگر از قبل به یک حساب صورتحساب متصل هستید، میتوانید از این مرحله صرف نظر کنید.
ایجاد پروژه (اختیاری)
اگر پروژه فعلی ندارید که بخواهید برای این آزمایشگاه استفاده کنید، اینجا یک پروژه جدید ایجاد کنید .
۳. ویرایشگر Cloud Shell را باز کنید
- برای دسترسی مستقیم به ویرایشگر Cloud Shell ، روی این لینک کلیک کنید.
- اگر امروز در هر مرحلهای از شما خواسته شد که مجوز دهید، برای ادامه روی تأیید کلیک کنید.
- اگر ترمینال در پایین صفحه نمایش داده نشد، آن را باز کنید:
- روی مشاهده کلیک کنید
- روی ترمینال کلیک کنید
- در ترمینال، پروژه خود را با این دستور تنظیم کنید:
gcloud config set project [PROJECT_ID]- مثال:
gcloud config set project lab-project-id-example - اگر نمیتوانید شناسه پروژه خود را به خاطر بیاورید، میتوانید تمام شناسههای پروژه خود را با استفاده از دستور زیر فهرست کنید:
gcloud projects list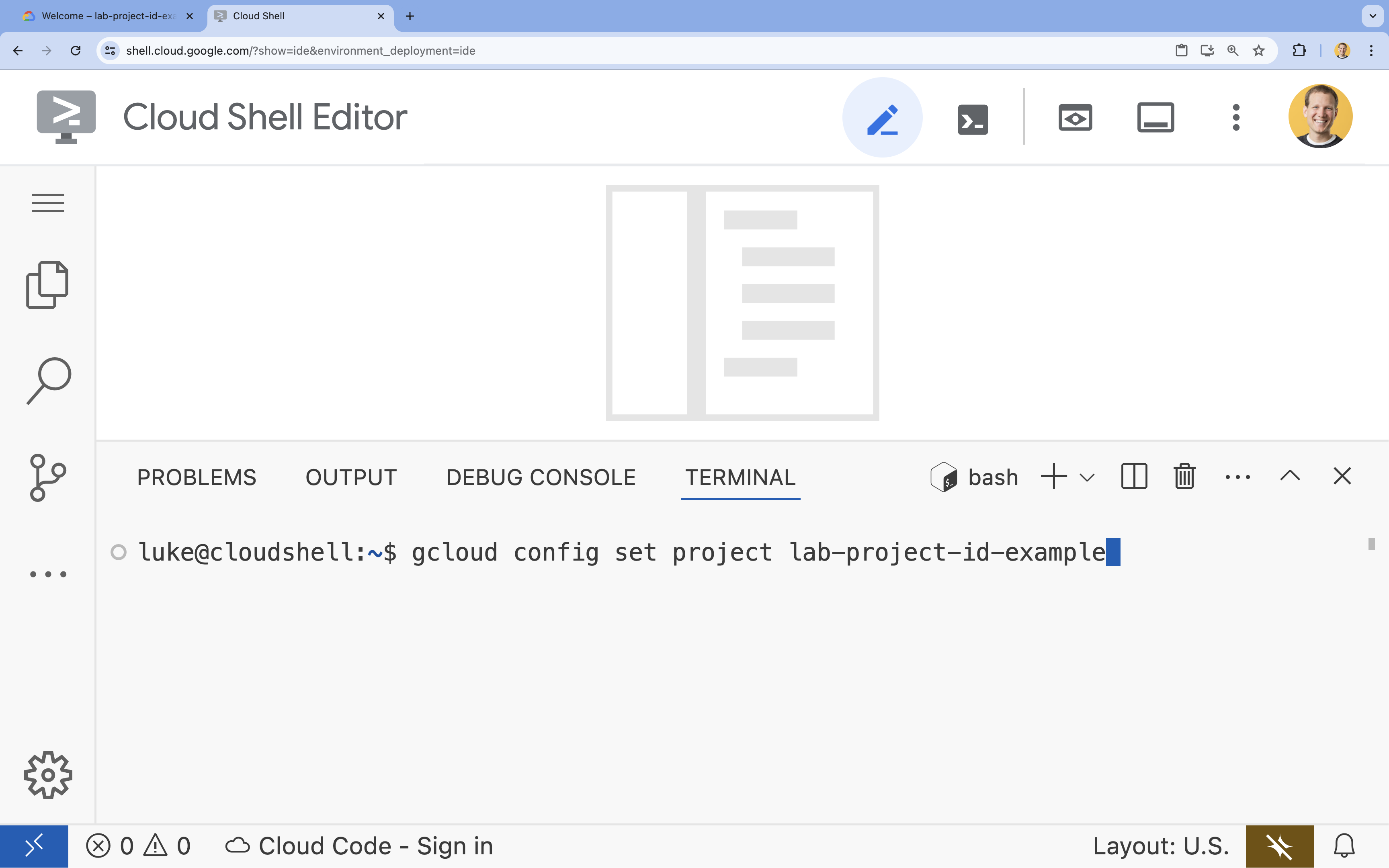
- مثال:
- شما باید این پیام را ببینید:
Updated property [core/project].
۴. فعال کردن APIها
برای استفاده از Vertex AI و سایر سرویسها، باید APIهای لازم را در پروژه Google Cloud خود فعال کنید.
- در ترمینال، APIها را فعال کنید:
- رابط برنامهنویسی کاربردی هوش مصنوعی ورتکس (
aiplatform.googleapis.com): استفاده از هوش مصنوعی ورتکس را برای تنظیم دقیق و ارائه مدلها امکانپذیر میکند. - رابط برنامهنویسی کاربردی ذخیرهسازی ابری (
storage.googleapis.com): امکان ذخیرهسازی مجموعه دادهها و مصنوعات مدل را فراهم میکند.
gcloud services enable aiplatform.googleapis.com \ storage.googleapis.com - رابط برنامهنویسی کاربردی هوش مصنوعی ورتکس (
۵. محیط پروژه را تنظیم کنید
ایجاد یک دایرکتوری کاری
- در ترمینال ، یک دایرکتوری برای پروژه خود ایجاد کنید و به داخل آن بروید.
mkdir gemini-finetuning cd gemini-finetuning
تنظیم متغیرهای محیطی
- در ترمینال ، متغیرهای محیطی پروژه خود را تعریف کنید. ما یک فایل
env.shبرای ذخیره این متغیرها ایجاد خواهیم کرد تا در صورت قطع شدن session، بتوان آنها را به راحتی دوباره بارگذاری کرد.cat <<EOF > env.sh export PROJECT_ID=\$(gcloud config get-value project) export REGION="us-central1" export BUCKET_NAME="\${PROJECT_ID}-gemini-tuning" EOF source env.sh
یک سطل ذخیرهسازی ابری ایجاد کنید
- در ترمینال ، یک سطل (bucket) برای ذخیره مجموعه دادهها و مصنوعات مدل خود ایجاد کنید.
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION
راهاندازی محیط مجازی
- ما از
uvبرای مدیریت محیط پایتون خود استفاده خواهیم کرد. در ترمینال ، دستور زیر را اجرا کنید:uv venv .venv source .venv/bin/activate - در ترمینال ، بستههای پایتون مورد نیاز را نصب کنید.
uv pip install google-cloud-aiplatform rouge-score matplotlib pandas tqdm
۶. دادههای آموزشی را آماده کنید
دادههای باکیفیت، پایه و اساس تنظیم دقیق و موفقیتآمیز هستند. شما از مجموعه دادههای WikiLingua استفاده خواهید کرد، آن را به فرمت JSONL خاصی که Gemini به آن نیاز دارد تبدیل کرده و در مخزن ذخیرهسازی خود بارگذاری خواهید کرد.
- در ترمینال ، فایلی با نام
prepare_data.pyایجاد کنید.cloudshell edit prepare_data.py - کد زیر را در
prepare_data.pyقرار دهید.import json import os import pandas as pd from google.cloud import storage import subprocess # Configuration BUCKET_NAME = os.environ["BUCKET_NAME"] PROJECT_ID = os.environ["PROJECT_ID"] def download_data(): print("Downloading WikiLingua dataset...") # Using gsutil to copy from public bucket subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/*", "."], check=True) def convert_to_gemini_format(input_file, output_file, max_samples=1000): print(f"Converting {input_file} to Gemini format (first {max_samples} samples)...") converted_data = [] with open(input_file, 'r') as f: for i, line in enumerate(f): if i >= max_samples: break obj = json.loads(line) messages = obj.get("messages", []) # Convert messages to Gemini 2.5 format # Input: {"messages": [{"role": "user", "content": "..."}, {"role": "model", "content": "..."}]} # Output: {"contents": [{"role": "user", "parts": [{"text": "..."}]}, {"role": "model", "parts": [{"text": "..."}]}]} contents = [] for msg in messages: role = msg["role"] content = msg["content"] contents.append({ "role": role, "parts": [{"text": content}] }) converted_data.append({"contents": contents}) with open(output_file, 'w') as f: for item in converted_data: f.write(json.dumps(item) + "\n") print(f"Saved {len(converted_data)} examples to {output_file}") def upload_to_gcs(local_file, destination_blob_name): print(f"Uploading {local_file} to gs://{BUCKET_NAME}/{destination_blob_name}...") storage_client = storage.Client(project=PROJECT_ID) bucket = storage_client.bucket(BUCKET_NAME) blob = bucket.blob(destination_blob_name) blob.upload_from_filename(local_file) print("Upload complete.") def main(): download_data() # Process Training Data convert_to_gemini_format("sft_train_samples.jsonl", "train_gemini.jsonl") upload_to_gcs("train_gemini.jsonl", "datasets/train/train_gemini.jsonl") # Process Validation Data convert_to_gemini_format("sft_val_samples.jsonl", "val_gemini.jsonl") upload_to_gcs("val_gemini.jsonl", "datasets/val/val_gemini.jsonl") print("Data preparation complete!") if __name__ == "__main__": main() - در ترمینال ، اسکریپت آمادهسازی دادهها را اجرا کنید.
python prepare_data.py
۷. عملکرد پایه را تعیین کنید
قبل از تنظیم دقیق، به یک معیار نیاز دارید. شما با استفاده از امتیازات ROUGE، میزان عملکرد مدل پایه gemini-2.5-flash را در کار خلاصهسازی اندازهگیری خواهید کرد.
- در ترمینال ، فایلی با نام
evaluate.pyایجاد کنید.cloudshell edit evaluate.py - کد زیر را در
evaluate.pyقرار دهید.import argparse import json import os import pandas as pd from google.cloud import aiplatform import vertexai from vertexai.generative_models import GenerativeModel, GenerationConfig, HarmCategory, HarmBlockThreshold from rouge_score import rouge_scorer from tqdm import tqdm import matplotlib.pyplot as plt import time # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] aiplatform.init(project=PROJECT_ID, location=REGION) def evaluate(model_name, test_file, max_samples=50, output_json="results.json"): print(f"Evaluating model: {model_name}") # Load Test Data test_df = pd.read_csv(test_file) test_df = test_df.head(max_samples) model = GenerativeModel(model_name) safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, } generation_config = GenerationConfig( temperature=0.1, max_output_tokens=1024, ) scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True) results = [] for index, row in tqdm(test_df.iterrows(), total=len(test_df)): input_text = row['input_text'] reference_summary = row['output_text'] try: response = model.generate_content( input_text, generation_config=generation_config, safety_settings=safety_settings ) generated_summary = response.text scores = scorer.score(reference_summary, generated_summary) results.append({ "generated": generated_summary, "reference": reference_summary, "rouge1": scores['rouge1'].fmeasure, "rouge2": scores['rouge2'].fmeasure, "rougeL": scores['rougeL'].fmeasure }) except Exception as e: print(f"Error processing example {index}: {e}") # Sleep briefly to avoid quota issues if hitting limits time.sleep(1) # Save results with open(output_json, 'w') as f: json.dump(results, f, indent=2) return pd.DataFrame(results) def plot_results(df, title, filename): os.makedirs("plots", exist_ok=True) metrics = ['rouge1', 'rouge2', 'rougeL'] fig, axes = plt.subplots(1, 3, figsize=(15, 5)) for i, metric in enumerate(metrics): axes[i].hist(df[metric], bins=10, alpha=0.7, color='skyblue', edgecolor='black') axes[i].set_title(f'{metric} Distribution') axes[i].set_xlabel('Score') axes[i].set_ylabel('Count') plt.suptitle(title) plt.tight_layout() plt.savefig(f"plots/{filename}") print(f"Plot saved to plots/{filename}") def compare_results(baseline_file, tuned_file): with open(baseline_file, 'r') as f: baseline_data = pd.DataFrame(json.load(f)) with open(tuned_file, 'r') as f: tuned_data = pd.DataFrame(json.load(f)) print("\n--- Comparison ---") metrics = ['rouge1', 'rouge2', 'rougeL'] for metric in metrics: base_mean = baseline_data[metric].mean() tuned_mean = tuned_data[metric].mean() diff = tuned_mean - base_mean print(f"{metric}: Base={base_mean:.4f}, Tuned={tuned_mean:.4f}, Diff={diff:+.4f}") # Comparative Plot os.makedirs("plots", exist_ok=True) comparison_df = pd.DataFrame({ 'Metric': metrics, 'Baseline': [baseline_data[m].mean() for m in metrics], 'Tuned': [tuned_data[m].mean() for m in metrics] }) comparison_df.plot(x='Metric', y=['Baseline', 'Tuned'], kind='bar', figsize=(10, 6)) plt.title('Baseline vs Tuned Model Performance') plt.ylabel('Average Score') plt.xticks(rotation=0) plt.tight_layout() plt.savefig("plots/comparison.png") print("Comparison plot saved to plots/comparison.png") def main(): parser = argparse.ArgumentParser() parser.add_argument("--model", type=str, default="gemini-2.5-flash", help="Model resource name") parser.add_argument("--baseline", type=str, help="Path to baseline results json for comparison") parser.add_argument("--output", type=str, default="results.json", help="Output file for results") args = parser.parse_args() # Ensure test data exists (it was downloaded in prepare_data step) if not os.path.exists("sft_test_samples.csv"): # Fallback download if needed subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/sft_test_samples.csv", "."], check=True) df = evaluate(args.model, "sft_test_samples.csv", output_json=args.output) print("\n--- Results Summary ---") print(df.describe()) plot_filename = "baseline_dist.png" if not args.baseline else "tuned_dist.png" plot_results(df, f"ROUGE Scores - {args.model}", plot_filename) if args.baseline: compare_results(args.baseline, args.output) if __name__ == "__main__": main() - در ترمینال ، ارزیابی پایه را اجرا کنید.
python evaluate.py --model "gemini-2.5-flash" --output "baseline.json"baseline.jsonو یک نمودار درplots/baseline_dist.pngایجاد میکند.
۸. پیکربندی و راهاندازی تنظیمات دقیق
اکنون یک کار تنظیم دقیق مدیریتشده را روی Vertex AI آغاز خواهید کرد.
- در ترمینال ، فایلی با نام
tune.pyایجاد کنید.cloudshell edit tune.py - کد زیر را در
tune.pyقرار دهید.import os import time from google.cloud import aiplatform import vertexai from vertexai.preview.tuning import sft # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] BUCKET_NAME = os.environ["BUCKET_NAME"] aiplatform.init(project=PROJECT_ID, location=REGION) def train(): print("Launching fine-tuning job...") sft_tuning_job = sft.train( source_model="gemini-2.5-flash", # Using specific version for stability train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl", validation_dataset=f"gs://{BUCKET_NAME}/datasets/val/val_gemini.jsonl", epochs=1, # Keep it short for the lab adapter_size=4, learning_rate_multiplier=1.0, tuned_model_display_name="gemini-2.5-flash-wikilingua", ) print(f"Job started: {sft_tuning_job.resource_name}") print("Waiting for job to complete... (this may take ~45 minutes)") # Wait for the job to complete while not sft_tuning_job.has_ended: time.sleep(60) sft_tuning_job.refresh() print(f"Status: {sft_tuning_job.state.name}") print("Job completed!") print(f"Tuned Model Endpoint: {sft_tuning_job.tuned_model_endpoint_name}") return sft_tuning_job.tuned_model_endpoint_name if __name__ == "__main__": train() - در ترمینال ، اسکریپت تنظیم دقیق را اجرا کنید.
python tune.py
۹. کد آموزشی را درک کنید
در حالی که job شما در حال اجرا است، بیایید نگاهی دقیقتر به اسکریپت tune.py بیندازیم تا نحوهی تنظیم دقیق را درک کنیم.
تنظیم دقیق مدیریتشده و تحت نظارت
این اسکریپت از متد vertexai.tuning.sft.train برای ارسال یک کار تنظیم مدیریتشده استفاده میکند. این کار پیچیدگیهای تأمین زیرساخت، توزیع آموزش و مدیریت نقاط کنترل را حذف میکند.
sft_tuning_job = sft.train(
source_model="gemini-2.5-flash",
train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl",
# ...
)
پیکربندی LoRA
به جای تعریف دستی LoraConfig مانند آنچه در چارچوبهای متنباز انجام میدهید، Vertex AI این کار را با چند پارامتر کلیدی ساده میکند:
-
adapter_size: این پارامتر (که در اسکریپت ما روی4تنظیم شده است) رتبه آداپتورهای LoRA را کنترل میکند. اندازه بزرگتر به مدل اجازه میدهد تا سازگاریهای پیچیدهتری را یاد بگیرد، اما تعداد پارامترهای قابل آموزش را افزایش میدهد. -
epochs): ما این مقدار را برای این آزمایش روی1تنظیم کردیم تا زمان آموزش کوتاه باشد (حدود ۲۰ دقیقه). در یک سناریوی تولید، میتوانید این مقدار را افزایش دهید تا مدل بتواند عمیقتر از دادههای شما یاد بگیرد، هرچند باید مراقب بیشبرازش (overfitting) باشید.
انتخاب مدل
ما به صراحت source_model="gemini-2.5-flash" را مشخص میکنیم. Vertex AI از نسخههای مختلف Gemini پشتیبانی میکند و پین کردن یک نسخه خاص تضمین میکند که خط تولید شما پایدار و قابل تکرار باقی بماند.
۱۰. مدلها را مقایسه کنید
پس از اتمام کار تنظیم دقیق، میتوانید عملکرد مدل جدید خود را با مدل پایه مقایسه کنید.
- نقطه پایانی مدل تنظیمشده خود را دریافت کنید. این نقطه در انتهای اسکریپت
tune.pyچاپ شده است. چیزی شبیه بهprojects/.../locations/.../endpoints/...خواهد بود. - اسکریپت ارزیابی را دوباره اجرا کنید، این بار مدل تنظیمشده و نتایج پایه را برای مقایسه ارسال کنید.
# Replace [YOUR_TUNED_MODEL_ENDPOINT] with the actual endpoint name export TUNED_MODEL="projects/[YOUR_PROJECT_ID]/locations/[YOUR_REGION]/endpoints/[YOUR_ENDPOINT_ID]" python evaluate.py --model "$TUNED_MODEL" --baseline "baseline.json" --output "tuned.json" - نتایج را مشاهده کنید. اسکریپت مقایسهای از امتیازات ROUGE را نمایش میدهد و نمودار
plots/comparison.pngرا ایجاد میکند که بهبود را نشان میدهد. میتوانید نمودارها را با باز کردن پوشهplotsدر ویرایشگر Cloud Shell مشاهده کنید.
۱۱. تمیز کردن
برای جلوگیری از تحمیل هزینه، منابعی را که ایجاد کردهاید حذف کنید.
- در ترمینال ، مخزن ذخیرهسازی ابری و مدل تنظیمشده را حذف کنید.
gcloud storage rm -r gs://$BUCKET_NAME # Note: You can delete the model endpoint from the Vertex AI Console
۱۲. تبریک میگویم!
شما با موفقیت Gemini 2.5 Flash را روی Vertex AI تنظیم کردید!
خلاصه
در این آزمایشگاه، شما:
- یک مجموعه داده با فرمت JSONL برای تنظیم دقیق Gemini آماده کردم.
- با استفاده از مدل پایه Gemini 2.5 Flash، یک خط مبنا ایجاد شد.
- یک کار تنظیم دقیق تحت نظارت روی Vertex AI راهاندازی شد.
- مدل تنظیمشده دقیق را با مدل پایه ارزیابی و مقایسه کرد.
قدم بعدی چیست؟
این آزمایشگاه بخشی از پروژه «هوش مصنوعی آماده تولید با مسیر یادگیری ابری گوگل» است.
برای پر کردن شکاف بین نمونه اولیه و تولید، برنامه درسی کامل را بررسی کنید.
پیشرفت خود را با هشتگ #ProductionReadyAI به اشتراک بگذارید.