
1. Introduction
Dans cet atelier, vous allez apprendre à effectuer le workflow complet d'affinage supervisé sur un modèle Google Gemini pour l'adapter à une tâche spécifique : la synthèse d'articles. Bien que les grands modèles de langage soient puissants, leur nature à usage général signifie qu'ils peuvent être encore plus efficaces pour des cas d'utilisation spécifiques grâce à l'affinage. En entraînant le modèle sur un ensemble de données d'exemples de haute qualité, vous pouvez améliorer sa cohérence, sa qualité et son efficacité pour votre tâche cible.
Vous utiliserez Gemini 2.5 Flash, un modèle léger et économique, et effectuerez l'affinage à l'aide de Vertex AI.
Présentation de l'architecture
Voici ce que nous allons créer :
- Cloud Shell : votre environnement de développement.
- Cloud Storage : stocke les données d'entraînement/de validation au format JSONL.
- Vertex AI Training : gère le job d'affinage.
- Point de terminaison Vertex AI : héberge votre modèle affiné.
Points abordés
- Préparer des ensembles de données de haute qualité pour l'affinage supervisé
- Configurer et lancer des jobs d'affinage à l'aide du SDK Vertex AI pour Python.
- Évaluer les modèles à l'aide de métriques automatisées (scores ROUGE)
- Comparer les modèles de base et affinés pour quantifier les améliorations
2. Configuration du projet
Compte Google
Si vous ne possédez pas encore de compte Google personnel, vous devez en créer un.
Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire.
Se connecter à la console Google Cloud
Connectez-vous à la console Google Cloud à l'aide d'un compte Google personnel.
Activer la facturation
Utiliser des crédits Google Cloud (facultatif)
Pour suivre cet atelier, vous avez besoin d'un compte de facturation avec des crédits. Utilisez les crédits de la bannière en haut de cet atelier de programmation pour commencer. Si vous êtes déjà connecté à un compte de facturation, vous pouvez ignorer cette étape.
Créer un projet (facultatif)
Si vous ne disposez pas d'un projet que vous souhaitez utiliser pour cet atelier, créez-en un ici.
3. Ouvrir l'éditeur Cloud Shell
- Cliquez sur ce lien pour accéder directement à l'éditeur Cloud Shell.
- Si vous êtes invité à autoriser à tout moment aujourd'hui, cliquez sur Autoriser pour continuer.
- Si le terminal ne s'affiche pas en bas de l'écran, ouvrez-le :
- Cliquez sur Afficher.
- Cliquez sur Terminal
 .
.
- Dans le terminal, définissez votre projet à l'aide de la commande suivante :
gcloud config set project [PROJECT_ID]- Exemple :
gcloud config set project lab-project-id-example - Si vous ne vous souvenez pas de votre ID de projet, vous pouvez répertorier tous vos ID de projet avec la commande suivante :
gcloud projects list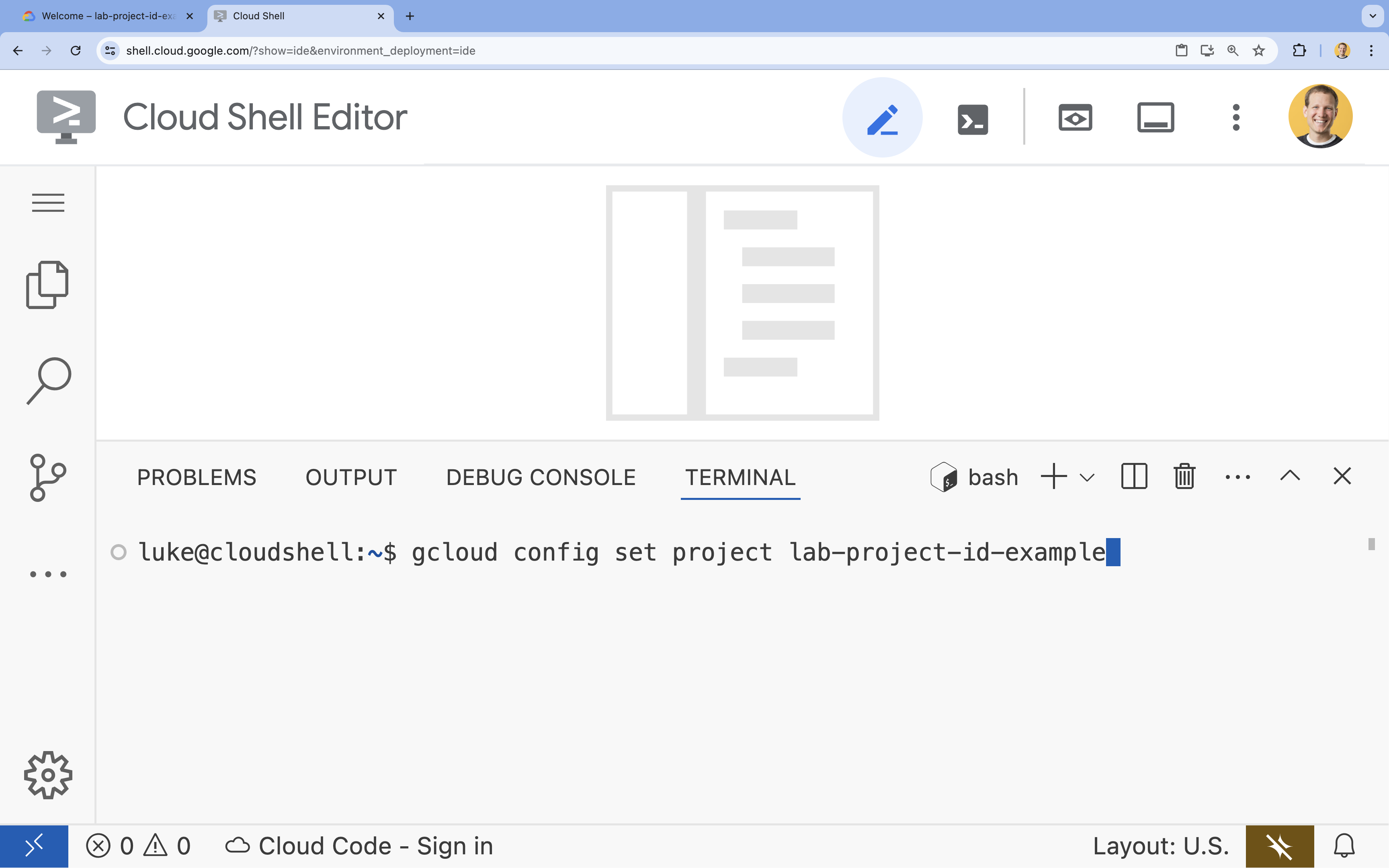
- Exemple :
- Le message suivant doit s'afficher :
Updated property [core/project].
4. Activer les API
Pour utiliser Vertex AI et d'autres services, vous devez activer les API nécessaires dans votre projet Google Cloud.
- Dans le terminal, activez les API :
- API Vertex AI (
aiplatform.googleapis.com) : permet d'utiliser Vertex AI pour l'affinage et la diffusion de modèles. - API Cloud Storage (
storage.googleapis.com) : permet de stocker des ensembles de données et des artefacts de modèle.
gcloud services enable aiplatform.googleapis.com \ storage.googleapis.com - API Vertex AI (
5. Configurer l'environnement du projet
Créer un répertoire de travail
- Dans le terminal, créez un répertoire pour votre projet et accédez-y.
mkdir gemini-finetuning cd gemini-finetuning
Configurer des variables d'environnement
- Dans le terminal, définissez les variables d'environnement pour votre projet. Nous allons créer un fichier
env.shpour stocker ces variables afin qu'elles puissent être facilement rechargées si votre session est déconnectée.cat <<EOF > env.sh export PROJECT_ID=\$(gcloud config get-value project) export REGION="us-central1" export BUCKET_NAME="\${PROJECT_ID}-gemini-tuning" EOF source env.sh
Créer un bucket Cloud Storage
- Dans le terminal, créez un bucket pour stocker votre ensemble de données et vos artefacts de modèle.
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION
Configurer l'environnement virtuel
- Nous allons utiliser
uvpour gérer notre environnement Python. Dans le terminal, exécutez la commande suivante :uv venv .venv source .venv/bin/activate - Dans le terminal, installez les packages Python requis.
uv pip install google-cloud-aiplatform rouge-score matplotlib pandas tqdm
6. Préparer les données d'entraînement
Des données de qualité sont essentielles pour un affinage réussi. Vous allez utiliser l'ensemble de données WikiLingua, le transformer au format JSONL spécifique requis par Gemini et l'importer dans votre bucket de stockage.
- Dans le terminal, créez un fichier nommé
prepare_data.py.cloudshell edit prepare_data.py - Collez le code suivant dans
prepare_data.py.import json import os import pandas as pd from google.cloud import storage import subprocess # Configuration BUCKET_NAME = os.environ["BUCKET_NAME"] PROJECT_ID = os.environ["PROJECT_ID"] def download_data(): print("Downloading WikiLingua dataset...") # Using gsutil to copy from public bucket subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/*", "."], check=True) def convert_to_gemini_format(input_file, output_file, max_samples=1000): print(f"Converting {input_file} to Gemini format (first {max_samples} samples)...") converted_data = [] with open(input_file, 'r') as f: for i, line in enumerate(f): if i >= max_samples: break obj = json.loads(line) messages = obj.get("messages", []) # Convert messages to Gemini 2.5 format # Input: {"messages": [{"role": "user", "content": "..."}, {"role": "model", "content": "..."}]} # Output: {"contents": [{"role": "user", "parts": [{"text": "..."}]}, {"role": "model", "parts": [{"text": "..."}]}]} contents = [] for msg in messages: role = msg["role"] content = msg["content"] contents.append({ "role": role, "parts": [{"text": content}] }) converted_data.append({"contents": contents}) with open(output_file, 'w') as f: for item in converted_data: f.write(json.dumps(item) + "\n") print(f"Saved {len(converted_data)} examples to {output_file}") def upload_to_gcs(local_file, destination_blob_name): print(f"Uploading {local_file} to gs://{BUCKET_NAME}/{destination_blob_name}...") storage_client = storage.Client(project=PROJECT_ID) bucket = storage_client.bucket(BUCKET_NAME) blob = bucket.blob(destination_blob_name) blob.upload_from_filename(local_file) print("Upload complete.") def main(): download_data() # Process Training Data convert_to_gemini_format("sft_train_samples.jsonl", "train_gemini.jsonl") upload_to_gcs("train_gemini.jsonl", "datasets/train/train_gemini.jsonl") # Process Validation Data convert_to_gemini_format("sft_val_samples.jsonl", "val_gemini.jsonl") upload_to_gcs("val_gemini.jsonl", "datasets/val/val_gemini.jsonl") print("Data preparation complete!") if __name__ == "__main__": main() - Dans le terminal, exécutez le script de préparation des données.
python prepare_data.py
7. Établir des performances de référence
Avant l'affinage, vous avez besoin d'un benchmark. Vous allez mesurer les performances du modèle de base gemini-2.5-flash sur la tâche de synthèse à l'aide des scores ROUGE.
- Dans le terminal, créez un fichier nommé
evaluate.py.cloudshell edit evaluate.py - Collez le code suivant dans
evaluate.py.import argparse import json import os import pandas as pd from google.cloud import aiplatform import vertexai from vertexai.generative_models import GenerativeModel, GenerationConfig, HarmCategory, HarmBlockThreshold from rouge_score import rouge_scorer from tqdm import tqdm import matplotlib.pyplot as plt import time # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] aiplatform.init(project=PROJECT_ID, location=REGION) def evaluate(model_name, test_file, max_samples=50, output_json="results.json"): print(f"Evaluating model: {model_name}") # Load Test Data test_df = pd.read_csv(test_file) test_df = test_df.head(max_samples) model = GenerativeModel(model_name) safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, } generation_config = GenerationConfig( temperature=0.1, max_output_tokens=1024, ) scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True) results = [] for index, row in tqdm(test_df.iterrows(), total=len(test_df)): input_text = row['input_text'] reference_summary = row['output_text'] try: response = model.generate_content( input_text, generation_config=generation_config, safety_settings=safety_settings ) generated_summary = response.text scores = scorer.score(reference_summary, generated_summary) results.append({ "generated": generated_summary, "reference": reference_summary, "rouge1": scores['rouge1'].fmeasure, "rouge2": scores['rouge2'].fmeasure, "rougeL": scores['rougeL'].fmeasure }) except Exception as e: print(f"Error processing example {index}: {e}") # Sleep briefly to avoid quota issues if hitting limits time.sleep(1) # Save results with open(output_json, 'w') as f: json.dump(results, f, indent=2) return pd.DataFrame(results) def plot_results(df, title, filename): os.makedirs("plots", exist_ok=True) metrics = ['rouge1', 'rouge2', 'rougeL'] fig, axes = plt.subplots(1, 3, figsize=(15, 5)) for i, metric in enumerate(metrics): axes[i].hist(df[metric], bins=10, alpha=0.7, color='skyblue', edgecolor='black') axes[i].set_title(f'{metric} Distribution') axes[i].set_xlabel('Score') axes[i].set_ylabel('Count') plt.suptitle(title) plt.tight_layout() plt.savefig(f"plots/{filename}") print(f"Plot saved to plots/{filename}") def compare_results(baseline_file, tuned_file): with open(baseline_file, 'r') as f: baseline_data = pd.DataFrame(json.load(f)) with open(tuned_file, 'r') as f: tuned_data = pd.DataFrame(json.load(f)) print("\n--- Comparison ---") metrics = ['rouge1', 'rouge2', 'rougeL'] for metric in metrics: base_mean = baseline_data[metric].mean() tuned_mean = tuned_data[metric].mean() diff = tuned_mean - base_mean print(f"{metric}: Base={base_mean:.4f}, Tuned={tuned_mean:.4f}, Diff={diff:+.4f}") # Comparative Plot os.makedirs("plots", exist_ok=True) comparison_df = pd.DataFrame({ 'Metric': metrics, 'Baseline': [baseline_data[m].mean() for m in metrics], 'Tuned': [tuned_data[m].mean() for m in metrics] }) comparison_df.plot(x='Metric', y=['Baseline', 'Tuned'], kind='bar', figsize=(10, 6)) plt.title('Baseline vs Tuned Model Performance') plt.ylabel('Average Score') plt.xticks(rotation=0) plt.tight_layout() plt.savefig("plots/comparison.png") print("Comparison plot saved to plots/comparison.png") def main(): parser = argparse.ArgumentParser() parser.add_argument("--model", type=str, default="gemini-2.5-flash", help="Model resource name") parser.add_argument("--baseline", type=str, help="Path to baseline results json for comparison") parser.add_argument("--output", type=str, default="results.json", help="Output file for results") args = parser.parse_args() # Ensure test data exists (it was downloaded in prepare_data step) if not os.path.exists("sft_test_samples.csv"): # Fallback download if needed subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/sft_test_samples.csv", "."], check=True) df = evaluate(args.model, "sft_test_samples.csv", output_json=args.output) print("\n--- Results Summary ---") print(df.describe()) plot_filename = "baseline_dist.png" if not args.baseline else "tuned_dist.png" plot_results(df, f"ROUGE Scores - {args.model}", plot_filename) if args.baseline: compare_results(args.baseline, args.output) if __name__ == "__main__": main() - Dans le terminal, exécutez l'évaluation de référence.
python evaluate.py --model "gemini-2.5-flash" --output "baseline.json"baseline.jsonet un graphique dansplots/baseline_dist.png.
8. Configurer et lancer l'affinage
Vous allez maintenant lancer un job d'affinage géré sur Vertex AI.
- Dans le terminal, créez un fichier nommé
tune.py.cloudshell edit tune.py - Collez le code suivant dans
tune.py.import os import time from google.cloud import aiplatform import vertexai from vertexai.preview.tuning import sft # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] BUCKET_NAME = os.environ["BUCKET_NAME"] aiplatform.init(project=PROJECT_ID, location=REGION) def train(): print("Launching fine-tuning job...") sft_tuning_job = sft.train( source_model="gemini-2.5-flash", # Using specific version for stability train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl", validation_dataset=f"gs://{BUCKET_NAME}/datasets/val/val_gemini.jsonl", epochs=1, # Keep it short for the lab adapter_size=4, learning_rate_multiplier=1.0, tuned_model_display_name="gemini-2.5-flash-wikilingua", ) print(f"Job started: {sft_tuning_job.resource_name}") print("Waiting for job to complete... (this may take ~45 minutes)") # Wait for the job to complete while not sft_tuning_job.has_ended: time.sleep(60) sft_tuning_job.refresh() print(f"Status: {sft_tuning_job.state.name}") print("Job completed!") print(f"Tuned Model Endpoint: {sft_tuning_job.tuned_model_endpoint_name}") return sft_tuning_job.tuned_model_endpoint_name if __name__ == "__main__": train() - Dans le terminal, exécutez le script d'affinage.
python tune.py
9. Comprendre le code d'entraînement
Pendant l'exécution de votre job, examinons de plus près le script tune.py pour comprendre le fonctionnement de l'affinage.
Affinage supervisé géré
Le script utilise la méthode vertexai.tuning.sft.train pour envoyer un job de réglage géré. Cela élimine la complexité du provisionnement de l'infrastructure, de la distribution de l'entraînement et de la gestion des points de contrôle.
sft_tuning_job = sft.train(
source_model="gemini-2.5-flash",
train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl",
# ...
)
Configuration LoRA
Au lieu de définir manuellement un LoraConfig comme vous le feriez dans des frameworks Open Source, Vertex AI simplifie cette opération en quelques paramètres clés :
adapter_size: ce paramètre (défini sur4dans notre script) contrôle le rang des adaptateurs LoRA. Une taille plus importante permet au modèle d'apprendre des adaptations plus complexes, mais augmente le nombre de paramètres entraînables.epochs: nous avons défini ce paramètre sur1pour cet atelier afin de réduire le temps d'entraînement (environ 20 minutes). Dans un scénario de production, vous pouvez augmenter cette valeur pour permettre au modèle d'apprendre plus en profondeur à partir de vos données, mais vous devez faire attention au surapprentissage.
Sélection du modèle
Nous spécifions explicitement source_model="gemini-2.5-flash". Vertex AI est compatible avec différentes versions de Gemini. Le fait d'épingler une version spécifique garantit la stabilité et la reproductibilité de votre pipeline.
10. Comparer des modèles
Une fois le job d'affinage terminé, vous pouvez comparer les performances de votre nouveau modèle avec celles de référence.
- Obtenez le point de terminaison de votre modèle réglé. Il a été imprimé à la fin du script
tune.py. Il se présente sous la formeprojects/.../locations/.../endpoints/.... - Exécutez à nouveau le script d'évaluation, en transmettant cette fois votre modèle réglé et les résultats de référence à des fins de comparaison.
# Replace [YOUR_TUNED_MODEL_ENDPOINT] with the actual endpoint name export TUNED_MODEL="projects/[YOUR_PROJECT_ID]/locations/[YOUR_REGION]/endpoints/[YOUR_ENDPOINT_ID]" python evaluate.py --model "$TUNED_MODEL" --baseline "baseline.json" --output "tuned.json" - afficher les résultats. Le script génère une comparaison des scores ROUGE et un graphique
plots/comparison.pngindiquant l'amélioration.Vous pouvez afficher les graphiques en ouvrant le dossierplotsdans l'éditeur Cloud Shell.
11. Effectuer un nettoyage
Pour éviter que des frais ne vous soient facturés, supprimez les ressources que vous avez créées.
- Dans le terminal, supprimez le bucket Cloud Storage et le modèle réglé.
gcloud storage rm -r gs://$BUCKET_NAME # Note: You can delete the model endpoint from the Vertex AI Console
12. Félicitations !
Vous avez affiné Gemini 2.5 Flash sur Vertex AI avec succès !
Récapitulatif
Au cours de cet atelier, vous allez :
- Préparer un ensemble de données au format JSONL pour l'affinage de Gemini
- Établir une référence à l'aide du modèle de base Gemini 2.5 Flash
- Lancer un job d'affinage supervisé sur Vertex AI
- Évaluer et comparer le modèle affiné avec la référence
Étape suivante
Cet atelier fait partie du parcours de formation L'IA prête pour la production avec Google Cloud.
Explorez le programme complet pour passer du prototype à la production.
Partagez vos progrès avec le hashtag #ProductionReadyAI.