
1. Introduzione
In questo lab imparerai a eseguire il flusso di lavoro completo del fine-tuning supervisionato su un modello Google Gemini per adattarlo a un'attività specifica: il riepilogo di articoli. Sebbene i modelli linguistici di grandi dimensioni siano potenti, la loro natura generica significa che possono essere resi ancora più efficaci per casi d'uso specifici tramite l'ottimizzazione. Addestrando il modello su un set di dati di esempi di alta qualità, puoi migliorarne la coerenza, la qualità e l'efficienza per l'attività di destinazione.
Utilizzerai Gemini 2.5 Flash, un modello leggero ed economico, ed eseguirai il perfezionamento utilizzando Vertex AI.
Panoramica dell'architettura
Ecco cosa creeremo:
- Cloud Shell: il tuo ambiente di sviluppo.
- Cloud Storage: archivia i dati di addestramento/convalida in formato JSONL.
- Vertex AI Training: gestisce il job di ottimizzazione.
- Endpoint Vertex AI: ospita il modello ottimizzato.
Obiettivi didattici
- Prepara set di dati di alta qualità per il fine-tuning supervisionato.
- Configura e avvia i job di ottimizzazione utilizzando l'SDK Vertex AI Python.
- Valuta i modelli utilizzando metriche automatizzate (punteggi ROUGE).
- Confronta i modelli di base e ottimizzati per quantificare i miglioramenti.
2. Configurazione del progetto
Account Google
Se non hai ancora un Account Google personale, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
Accedi alla console Google Cloud
Accedi alla console Google Cloud utilizzando un Account Google personale.
Abilita fatturazione
Riscatta i crediti Google Cloud (facoltativo)
Per partecipare a questo workshop, devi disporre di un account di fatturazione con del credito. Per iniziare, utilizza i crediti del banner nella parte superiore di questo codelab. Se hai già collegato un account di fatturazione, puoi saltare questo passaggio.
Creare un progetto (facoltativo)
Se non hai un progetto attuale che vuoi utilizzare per questo lab, creane uno nuovo qui.
3. Apri editor di Cloud Shell
- Fai clic su questo link per andare direttamente all'editor di Cloud Shell.
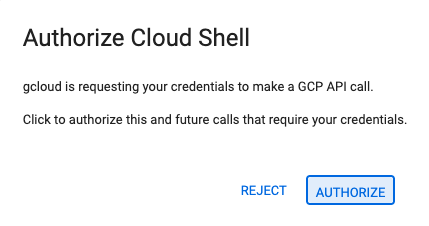
- Se ti viene richiesto di concedere l'autorizzazione in qualsiasi momento della giornata, fai clic su Autorizza per continuare.
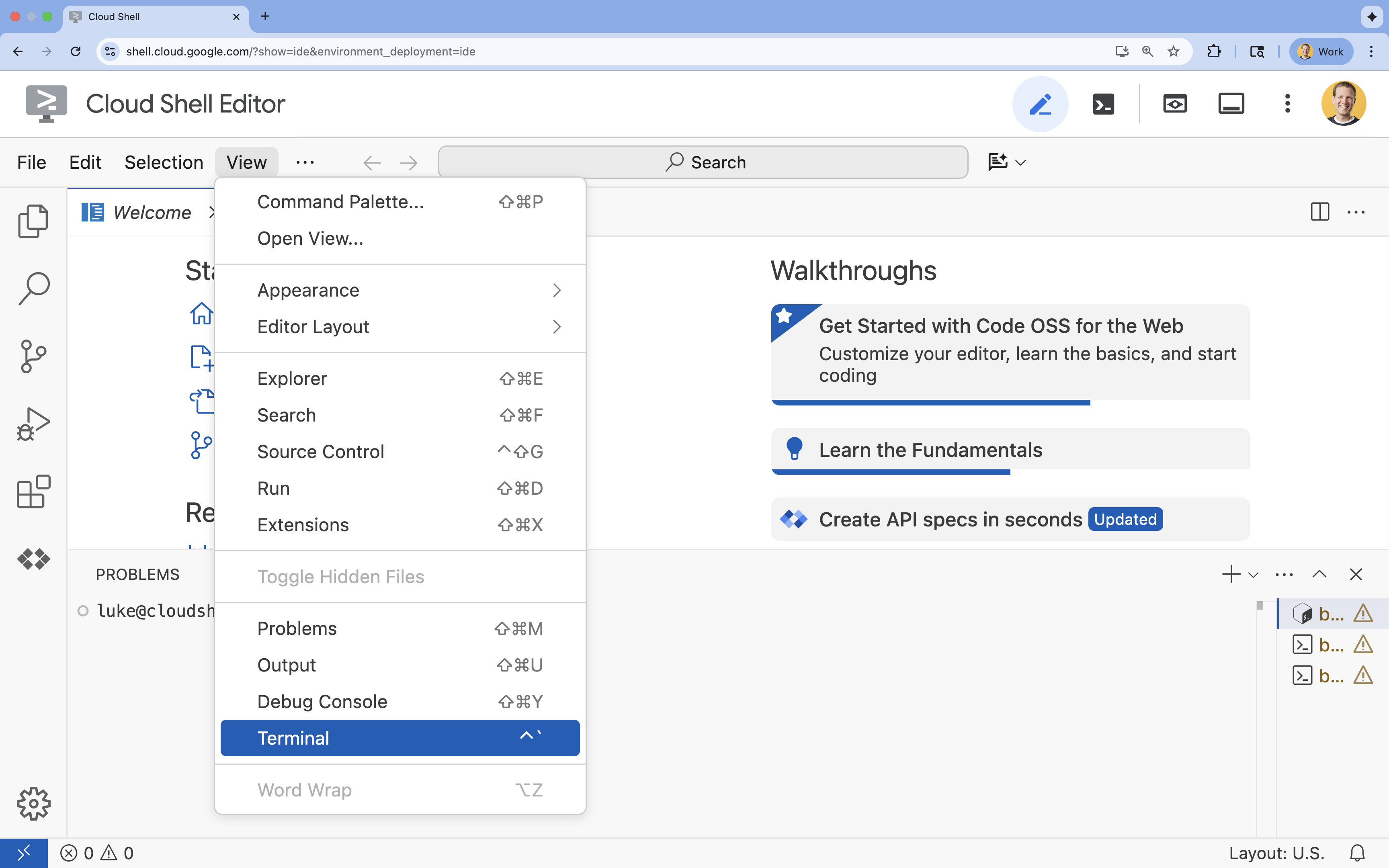
- Se il terminale non viene visualizzato nella parte inferiore dello schermo, aprilo:
- Fai clic su Visualizza.
- Fai clic su Terminale
 .
.
- Nel terminale, imposta il progetto con questo comando:
gcloud config set project [PROJECT_ID]- Esempio:
gcloud config set project lab-project-id-example - Se non ricordi l'ID progetto, puoi elencare tutti i tuoi ID progetto con:
gcloud projects list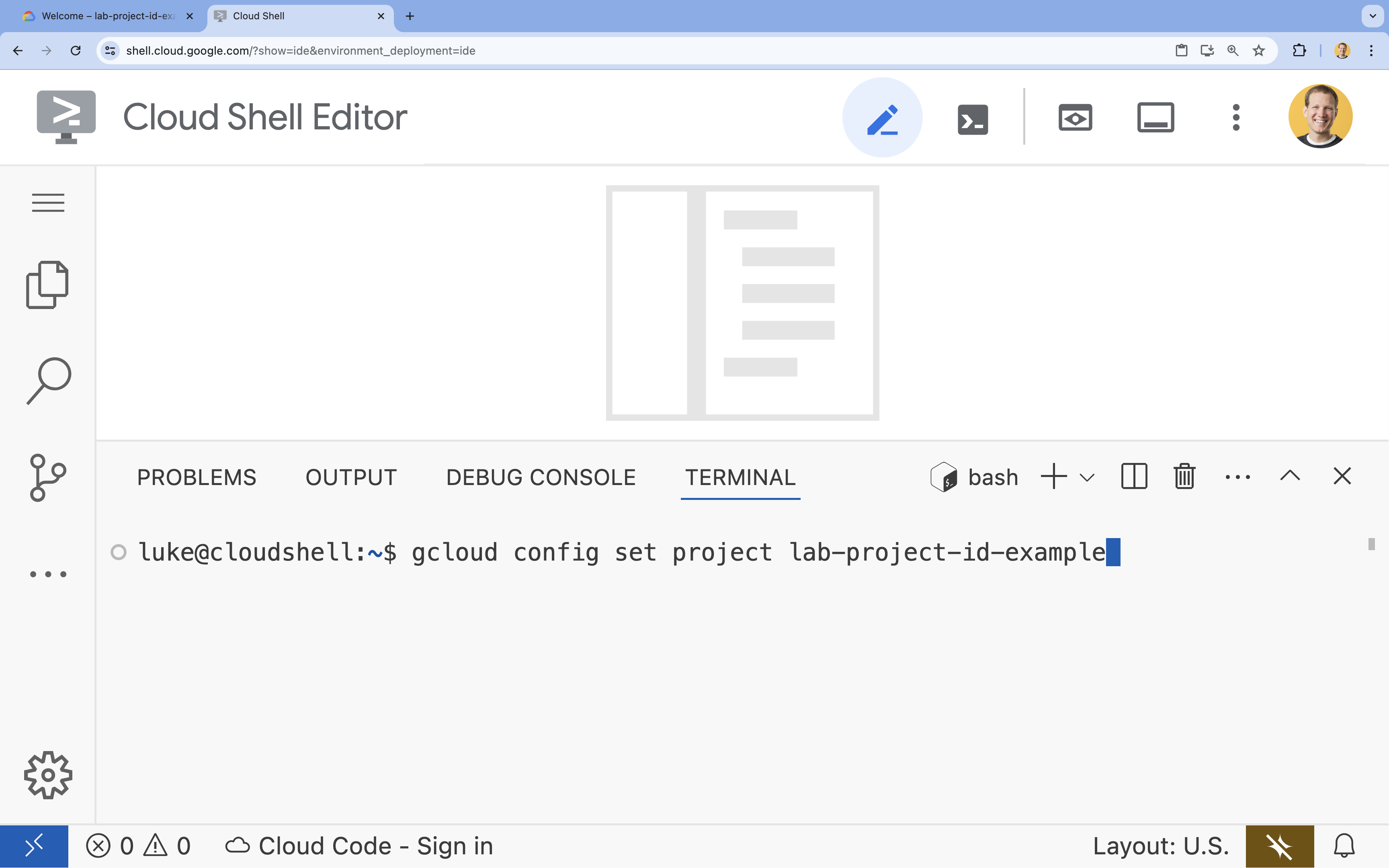
- Esempio:
- Dovresti visualizzare questo messaggio:
Updated property [core/project].
4. Abilita API
Per utilizzare Vertex AI e altri servizi, devi abilitare le API necessarie nel tuo progetto Google Cloud.
- Nel terminale, abilita le API:
- API Vertex AI (
aiplatform.googleapis.com): consente l'utilizzo di Vertex AI per il perfezionamento e la pubblicazione dei modelli. - API Cloud Storage (
storage.googleapis.com): consente l'archiviazione di set di dati e artefatti del modello.
gcloud services enable aiplatform.googleapis.com \ storage.googleapis.com - API Vertex AI (
5. Configurare l'ambiente del progetto
Crea una directory di lavoro
- Nel terminale, crea una directory per il tuo progetto e accedi alla directory.
mkdir gemini-finetuning cd gemini-finetuning
Imposta le variabili di ambiente
- Nel terminale, definisci le variabili di ambiente per il progetto. Creeremo un file
env.shper archiviare queste variabili in modo che possano essere ricaricate facilmente in caso di disconnessione della sessione.cat <<EOF > env.sh export PROJECT_ID=\$(gcloud config get-value project) export REGION="us-central1" export BUCKET_NAME="\${PROJECT_ID}-gemini-tuning" EOF source env.sh
Crea un bucket Cloud Storage
- Nel terminale, crea un bucket per archiviare il set di dati e gli artefatti del modello.
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION
Configura l'ambiente virtuale
- Utilizzeremo
uvper gestire il nostro ambiente Python. Nel terminale, esegui:uv venv .venv source .venv/bin/activate - Nel terminale, installa i pacchetti Python richiesti.
uv pip install google-cloud-aiplatform rouge-score matplotlib pandas tqdm
6. prepara i dati di addestramento
Dati di qualità sono la base per un'ottimizzazione efficace. Utilizzerai il set di dati WikiLingua, lo trasformerai nel formato JSONL specifico richiesto da Gemini e lo caricherai nel bucket di archiviazione.
- Nel terminale, crea un file denominato
prepare_data.py.cloudshell edit prepare_data.py - Incolla il seguente codice in
prepare_data.py.import json import os import pandas as pd from google.cloud import storage import subprocess # Configuration BUCKET_NAME = os.environ["BUCKET_NAME"] PROJECT_ID = os.environ["PROJECT_ID"] def download_data(): print("Downloading WikiLingua dataset...") # Using gsutil to copy from public bucket subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/*", "."], check=True) def convert_to_gemini_format(input_file, output_file, max_samples=1000): print(f"Converting {input_file} to Gemini format (first {max_samples} samples)...") converted_data = [] with open(input_file, 'r') as f: for i, line in enumerate(f): if i >= max_samples: break obj = json.loads(line) messages = obj.get("messages", []) # Convert messages to Gemini 2.5 format # Input: {"messages": [{"role": "user", "content": "..."}, {"role": "model", "content": "..."}]} # Output: {"contents": [{"role": "user", "parts": [{"text": "..."}]}, {"role": "model", "parts": [{"text": "..."}]}]} contents = [] for msg in messages: role = msg["role"] content = msg["content"] contents.append({ "role": role, "parts": [{"text": content}] }) converted_data.append({"contents": contents}) with open(output_file, 'w') as f: for item in converted_data: f.write(json.dumps(item) + "\n") print(f"Saved {len(converted_data)} examples to {output_file}") def upload_to_gcs(local_file, destination_blob_name): print(f"Uploading {local_file} to gs://{BUCKET_NAME}/{destination_blob_name}...") storage_client = storage.Client(project=PROJECT_ID) bucket = storage_client.bucket(BUCKET_NAME) blob = bucket.blob(destination_blob_name) blob.upload_from_filename(local_file) print("Upload complete.") def main(): download_data() # Process Training Data convert_to_gemini_format("sft_train_samples.jsonl", "train_gemini.jsonl") upload_to_gcs("train_gemini.jsonl", "datasets/train/train_gemini.jsonl") # Process Validation Data convert_to_gemini_format("sft_val_samples.jsonl", "val_gemini.jsonl") upload_to_gcs("val_gemini.jsonl", "datasets/val/val_gemini.jsonl") print("Data preparation complete!") if __name__ == "__main__": main() - Nel terminale, esegui lo script di preparazione dei dati.
python prepare_data.py
7. Stabilire il rendimento di base
Prima di eseguire il perfezionamento, devi avere un benchmark. Misurerai le prestazioni del modello gemini-2.5-flash di base nell'attività di riepilogo utilizzando i punteggi ROUGE.
- Nel terminale, crea un file denominato
evaluate.py.cloudshell edit evaluate.py - Incolla il seguente codice in
evaluate.py.import argparse import json import os import pandas as pd from google.cloud import aiplatform import vertexai from vertexai.generative_models import GenerativeModel, GenerationConfig, HarmCategory, HarmBlockThreshold from rouge_score import rouge_scorer from tqdm import tqdm import matplotlib.pyplot as plt import time # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] aiplatform.init(project=PROJECT_ID, location=REGION) def evaluate(model_name, test_file, max_samples=50, output_json="results.json"): print(f"Evaluating model: {model_name}") # Load Test Data test_df = pd.read_csv(test_file) test_df = test_df.head(max_samples) model = GenerativeModel(model_name) safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, } generation_config = GenerationConfig( temperature=0.1, max_output_tokens=1024, ) scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True) results = [] for index, row in tqdm(test_df.iterrows(), total=len(test_df)): input_text = row['input_text'] reference_summary = row['output_text'] try: response = model.generate_content( input_text, generation_config=generation_config, safety_settings=safety_settings ) generated_summary = response.text scores = scorer.score(reference_summary, generated_summary) results.append({ "generated": generated_summary, "reference": reference_summary, "rouge1": scores['rouge1'].fmeasure, "rouge2": scores['rouge2'].fmeasure, "rougeL": scores['rougeL'].fmeasure }) except Exception as e: print(f"Error processing example {index}: {e}") # Sleep briefly to avoid quota issues if hitting limits time.sleep(1) # Save results with open(output_json, 'w') as f: json.dump(results, f, indent=2) return pd.DataFrame(results) def plot_results(df, title, filename): os.makedirs("plots", exist_ok=True) metrics = ['rouge1', 'rouge2', 'rougeL'] fig, axes = plt.subplots(1, 3, figsize=(15, 5)) for i, metric in enumerate(metrics): axes[i].hist(df[metric], bins=10, alpha=0.7, color='skyblue', edgecolor='black') axes[i].set_title(f'{metric} Distribution') axes[i].set_xlabel('Score') axes[i].set_ylabel('Count') plt.suptitle(title) plt.tight_layout() plt.savefig(f"plots/{filename}") print(f"Plot saved to plots/{filename}") def compare_results(baseline_file, tuned_file): with open(baseline_file, 'r') as f: baseline_data = pd.DataFrame(json.load(f)) with open(tuned_file, 'r') as f: tuned_data = pd.DataFrame(json.load(f)) print("\n--- Comparison ---") metrics = ['rouge1', 'rouge2', 'rougeL'] for metric in metrics: base_mean = baseline_data[metric].mean() tuned_mean = tuned_data[metric].mean() diff = tuned_mean - base_mean print(f"{metric}: Base={base_mean:.4f}, Tuned={tuned_mean:.4f}, Diff={diff:+.4f}") # Comparative Plot os.makedirs("plots", exist_ok=True) comparison_df = pd.DataFrame({ 'Metric': metrics, 'Baseline': [baseline_data[m].mean() for m in metrics], 'Tuned': [tuned_data[m].mean() for m in metrics] }) comparison_df.plot(x='Metric', y=['Baseline', 'Tuned'], kind='bar', figsize=(10, 6)) plt.title('Baseline vs Tuned Model Performance') plt.ylabel('Average Score') plt.xticks(rotation=0) plt.tight_layout() plt.savefig("plots/comparison.png") print("Comparison plot saved to plots/comparison.png") def main(): parser = argparse.ArgumentParser() parser.add_argument("--model", type=str, default="gemini-2.5-flash", help="Model resource name") parser.add_argument("--baseline", type=str, help="Path to baseline results json for comparison") parser.add_argument("--output", type=str, default="results.json", help="Output file for results") args = parser.parse_args() # Ensure test data exists (it was downloaded in prepare_data step) if not os.path.exists("sft_test_samples.csv"): # Fallback download if needed subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/sft_test_samples.csv", "."], check=True) df = evaluate(args.model, "sft_test_samples.csv", output_json=args.output) print("\n--- Results Summary ---") print(df.describe()) plot_filename = "baseline_dist.png" if not args.baseline else "tuned_dist.png" plot_results(df, f"ROUGE Scores - {args.model}", plot_filename) if args.baseline: compare_results(args.baseline, args.output) if __name__ == "__main__": main() - Nel terminale, esegui la valutazione di base.
python evaluate.py --model "gemini-2.5-flash" --output "baseline.json"baseline.jsone un grafico inplots/baseline_dist.png.
8. Configura e avvia il fine tuning
Ora avvierai un job di ottimizzazione gestita su Vertex AI.
- Nel terminale, crea un file denominato
tune.py.cloudshell edit tune.py - Incolla il seguente codice in
tune.py.import os import time from google.cloud import aiplatform import vertexai from vertexai.preview.tuning import sft # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] BUCKET_NAME = os.environ["BUCKET_NAME"] aiplatform.init(project=PROJECT_ID, location=REGION) def train(): print("Launching fine-tuning job...") sft_tuning_job = sft.train( source_model="gemini-2.5-flash", # Using specific version for stability train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl", validation_dataset=f"gs://{BUCKET_NAME}/datasets/val/val_gemini.jsonl", epochs=1, # Keep it short for the lab adapter_size=4, learning_rate_multiplier=1.0, tuned_model_display_name="gemini-2.5-flash-wikilingua", ) print(f"Job started: {sft_tuning_job.resource_name}") print("Waiting for job to complete... (this may take ~45 minutes)") # Wait for the job to complete while not sft_tuning_job.has_ended: time.sleep(60) sft_tuning_job.refresh() print(f"Status: {sft_tuning_job.state.name}") print("Job completed!") print(f"Tuned Model Endpoint: {sft_tuning_job.tuned_model_endpoint_name}") return sft_tuning_job.tuned_model_endpoint_name if __name__ == "__main__": train() - Nel terminale, esegui lo script di perfezionamento.
python tune.py
9. Comprendere il codice di addestramento
Mentre il job è in esecuzione, diamo un'occhiata più da vicino allo script tune.py per capire come funziona il perfezionamento.
Fine-tuning supervisionato gestito
Lo script utilizza il metodo vertexai.tuning.sft.train per inviare un job di ottimizzazione gestita. In questo modo si astrae la complessità del provisioning dell'infrastruttura, della distribuzione dell'addestramento e della gestione dei checkpoint.
sft_tuning_job = sft.train(
source_model="gemini-2.5-flash",
train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl",
# ...
)
Configurazione LoRA
Invece di definire manualmente un LoraConfig come faresti nei framework open source, Vertex AI semplifica questa operazione in alcuni parametri chiave:
adapter_size: questo parametro (impostato su4nel nostro script) controlla il ranking degli adattatori LoRA. Una dimensione maggiore consente al modello di apprendere adattamenti più complessi, ma aumenta il numero di parametri addestrabili.epochs: abbiamo impostato questo valore su1per questo lab per ridurre il tempo di addestramento (~20 minuti). In uno scenario di produzione, potresti aumentare questo valore per consentire al modello di apprendere più a fondo dai tuoi dati, anche se devi fare attenzione all'overfitting.
Selezione del modello
Specifichiamo esplicitamente source_model="gemini-2.5-flash". Vertex AI supporta varie versioni di Gemini e il blocco di una versione specifica garantisce che la pipeline rimanga stabile e riproducibile.
10. Confronta i modelli
Una volta completato il job di perfezionamento, puoi confrontare il rendimento del nuovo modello con la baseline.
- Recupera l'endpoint del modello ottimizzato. È stato stampato alla fine dello script
tune.py. Avrà un aspetto simile a questo:projects/.../locations/.../endpoints/.... - Esegui di nuovo lo script di valutazione, questa volta passando il modello ottimizzato e i risultati di riferimento per il confronto.
# Replace [YOUR_TUNED_MODEL_ENDPOINT] with the actual endpoint name export TUNED_MODEL="projects/[YOUR_PROJECT_ID]/locations/[YOUR_REGION]/endpoints/[YOUR_ENDPOINT_ID]" python evaluate.py --model "$TUNED_MODEL" --baseline "baseline.json" --output "tuned.json" - Visualizzare i risultati. Lo script restituirà un confronto dei punteggi ROUGE e genererà un grafico
plots/comparison.pngche mostra il miglioramento.Puoi visualizzare i grafici aprendo la cartellaplotsnell'editor di Cloud Shell.
11. Esegui la pulizia
Per evitare addebiti, elimina le risorse che hai creato.
- Nel terminale, elimina il bucket Cloud Storage e il modello ottimizzato.
gcloud storage rm -r gs://$BUCKET_NAME # Note: You can delete the model endpoint from the Vertex AI Console
12. Complimenti!
Hai eseguito l'ottimizzazione di Gemini 2.5 Flash su Vertex AI.
Riepilogo
In questo lab imparerai a:
- Hai preparato un set di dati in formato JSONL per il fine-tuning di Gemini.
- È stata stabilita una base di riferimento utilizzando il modello Gemini 2.5 Flash di base.
- Avviato un job di fine-tuning supervisionato su Vertex AI.
- Ha valutato e confrontato il modello ottimizzato con la baseline.
Passaggi successivi
Questo lab fa parte del percorso di apprendimento AI pronta per la produzione con Google Cloud.
Esplora il curriculum completo per colmare il divario tra prototipo e produzione.
Condividi i tuoi progressi con l'hashtag #ProductionReadyAI.