
1. Wprowadzenie
W tym laboratorium nauczysz się wykonywać pełny przepływ pracy nadzorowanego dostrajania modelu Google Gemini, aby dostosować go do konkretnego zadania: podsumowywania artykułów. Duże modele językowe są bardzo wydajne, ale ich uniwersalny charakter sprawia, że można je jeszcze bardziej dostosować do konkretnych zastosowań, przeprowadzając dostrajanie. Trenując model na wysokiej jakości zbiorze danych z przykładami, możesz zwiększyć jego spójność, jakość i wydajność w przypadku docelowego zadania.
Użyjesz Gemini 2.5 Flash, lekkiego i ekonomicznego modelu, a dostrajanie przeprowadzisz za pomocą Vertex AI.
Omówienie architektury
Oto co stworzymy:
- Cloud Shell: środowisko programistyczne.
- Cloud Storage: przechowuje dane trenujące i weryfikacyjne w formacie JSONL.
- Vertex AI Training: zarządza zadaniem dostrajania.
- Punkt końcowy Vertex AI: hostuje dostrojony model.
Czego się nauczysz
- Przygotuj wysokiej jakości zbiory danych do dostrajania nadzorowanego.
- Konfigurowanie i uruchamianie zadań dostrajania za pomocą pakietu SDK Vertex AI dla Pythona.
- Ocenianie modeli za pomocą zautomatyzowanych danych (wyników ROUGE).
- Porównaj modele bazowe i dostrojone, aby określić ilościowo wprowadzone ulepszenia.
2. Konfigurowanie projektu
Konto Google
Jeśli nie masz jeszcze osobistego konta Google, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
Logowanie się w konsoli Google Cloud
Zaloguj się w konsoli Google Cloud, korzystając z osobistego konta Google.
Włącz płatności
Odbieranie środków w Google Cloud (opcjonalnie)
Aby przeprowadzić te warsztaty, musisz mieć konto rozliczeniowe z określonymi środkami. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Tworzenie projektu (opcjonalnie)
Jeśli nie masz bieżącego projektu, którego chcesz użyć w tym ćwiczeniu, utwórz nowy projekt.
3. Otwórz edytor Cloud Shell
- Kliknij ten link, aby przejść bezpośrednio do edytora Cloud Shell
- Jeśli w dowolnym momencie pojawi się prośba o autoryzację, kliknij Autoryzuj, aby kontynuować.
- Jeśli terminal nie pojawi się u dołu ekranu, otwórz go:
- Kliknij Wyświetl.
- Kliknij Terminal
 .
.
- W terminalu ustaw projekt za pomocą tego polecenia:
gcloud config set project [PROJECT_ID]- Przykład:
gcloud config set project lab-project-id-example - Jeśli nie pamiętasz identyfikatora projektu, możesz wyświetlić listę wszystkich identyfikatorów projektów za pomocą tego polecenia:
gcloud projects list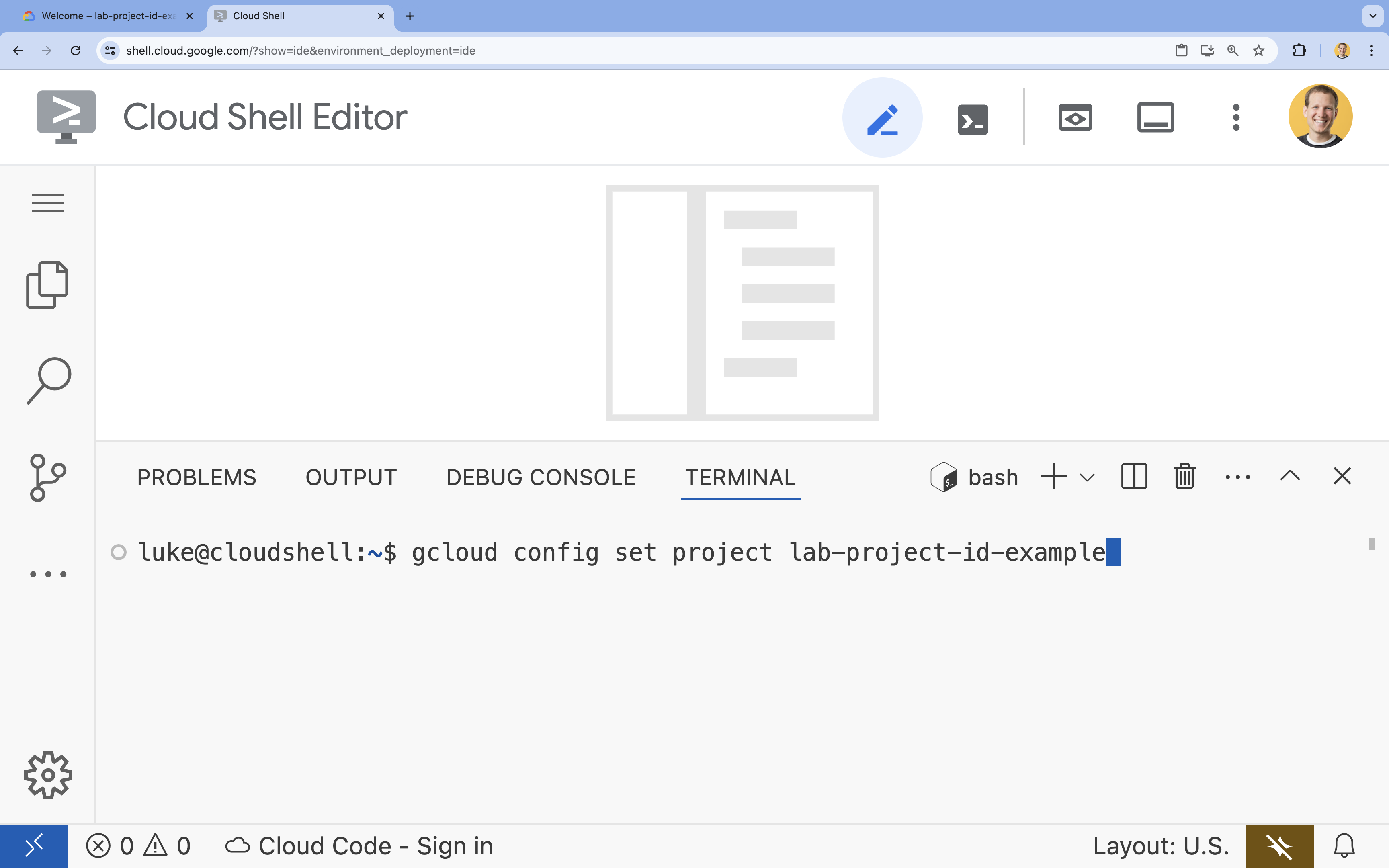
- Przykład:
- Powinien wyświetlić się ten komunikat:
Updated property [core/project].
4. Włącz interfejsy API
Aby korzystać z Vertex AI i innych usług, musisz włączyć w projekcie Google Cloud niezbędne interfejsy API.
- W terminalu włącz interfejsy API:
- Vertex AI API (
aiplatform.googleapis.com): umożliwia korzystanie z Vertex AI do dostrajania i udostępniania modeli. - Cloud Storage API (
storage.googleapis.com): umożliwia przechowywanie zbiorów danych i artefaktów modeli.
gcloud services enable aiplatform.googleapis.com \ storage.googleapis.com - Vertex AI API (
5. Konfigurowanie środowiska projektu
Tworzenie katalogu roboczego
- W terminalu utwórz katalog dla swojego projektu i przejdź do niego.
mkdir gemini-finetuning cd gemini-finetuning
Konfigurowanie zmiennych środowiskowych
- W terminalu zdefiniuj zmienne środowiskowe dla projektu. Utworzymy plik
env.sh, w którym zapiszemy te zmienne, aby można było je łatwo ponownie wczytać w przypadku rozłączenia sesji.cat <<EOF > env.sh export PROJECT_ID=\$(gcloud config get-value project) export REGION="us-central1" export BUCKET_NAME="\${PROJECT_ID}-gemini-tuning" EOF source env.sh
Tworzenie zasobnika Cloud Storage
- W terminalu utwórz zasobnik do przechowywania zbioru danych i artefaktów modelu.
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION
Konfigurowanie środowiska wirtualnego
- Do zarządzania środowiskiem Pythona będziemy używać
uv. W terminalu uruchom:uv venv .venv source .venv/bin/activate - W terminalu zainstaluj wymagane pakiety Pythona.
uv pip install google-cloud-aiplatform rouge-score matplotlib pandas tqdm
6. Przygotowywanie danych treningowych
Wysokiej jakości dane to podstawa skutecznego dostrajania. Użyjesz zbioru danych WikiLingua, przekształcisz go w określony format JSONL wymagany przez Gemini i prześlesz do zasobnika pamięci.
- W terminalu utwórz plik o nazwie
prepare_data.py.cloudshell edit prepare_data.py - Wklej ten kod do pliku
prepare_data.py.import json import os import pandas as pd from google.cloud import storage import subprocess # Configuration BUCKET_NAME = os.environ["BUCKET_NAME"] PROJECT_ID = os.environ["PROJECT_ID"] def download_data(): print("Downloading WikiLingua dataset...") # Using gsutil to copy from public bucket subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/*", "."], check=True) def convert_to_gemini_format(input_file, output_file, max_samples=1000): print(f"Converting {input_file} to Gemini format (first {max_samples} samples)...") converted_data = [] with open(input_file, 'r') as f: for i, line in enumerate(f): if i >= max_samples: break obj = json.loads(line) messages = obj.get("messages", []) # Convert messages to Gemini 2.5 format # Input: {"messages": [{"role": "user", "content": "..."}, {"role": "model", "content": "..."}]} # Output: {"contents": [{"role": "user", "parts": [{"text": "..."}]}, {"role": "model", "parts": [{"text": "..."}]}]} contents = [] for msg in messages: role = msg["role"] content = msg["content"] contents.append({ "role": role, "parts": [{"text": content}] }) converted_data.append({"contents": contents}) with open(output_file, 'w') as f: for item in converted_data: f.write(json.dumps(item) + "\n") print(f"Saved {len(converted_data)} examples to {output_file}") def upload_to_gcs(local_file, destination_blob_name): print(f"Uploading {local_file} to gs://{BUCKET_NAME}/{destination_blob_name}...") storage_client = storage.Client(project=PROJECT_ID) bucket = storage_client.bucket(BUCKET_NAME) blob = bucket.blob(destination_blob_name) blob.upload_from_filename(local_file) print("Upload complete.") def main(): download_data() # Process Training Data convert_to_gemini_format("sft_train_samples.jsonl", "train_gemini.jsonl") upload_to_gcs("train_gemini.jsonl", "datasets/train/train_gemini.jsonl") # Process Validation Data convert_to_gemini_format("sft_val_samples.jsonl", "val_gemini.jsonl") upload_to_gcs("val_gemini.jsonl", "datasets/val/val_gemini.jsonl") print("Data preparation complete!") if __name__ == "__main__": main() - W terminalu uruchom skrypt przygotowania danych.
python prepare_data.py
7. Określanie wydajności bazowej
Przed dostrajaniem musisz mieć punkt odniesienia. Za pomocą wyników ROUGE zmierzysz, jak dobrze podstawowy model gemini-2.5-flash radzi sobie z podsumowywaniem.
- W terminalu utwórz plik o nazwie
evaluate.py.cloudshell edit evaluate.py - Wklej ten kod do pliku
evaluate.py.import argparse import json import os import pandas as pd from google.cloud import aiplatform import vertexai from vertexai.generative_models import GenerativeModel, GenerationConfig, HarmCategory, HarmBlockThreshold from rouge_score import rouge_scorer from tqdm import tqdm import matplotlib.pyplot as plt import time # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] aiplatform.init(project=PROJECT_ID, location=REGION) def evaluate(model_name, test_file, max_samples=50, output_json="results.json"): print(f"Evaluating model: {model_name}") # Load Test Data test_df = pd.read_csv(test_file) test_df = test_df.head(max_samples) model = GenerativeModel(model_name) safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, } generation_config = GenerationConfig( temperature=0.1, max_output_tokens=1024, ) scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True) results = [] for index, row in tqdm(test_df.iterrows(), total=len(test_df)): input_text = row['input_text'] reference_summary = row['output_text'] try: response = model.generate_content( input_text, generation_config=generation_config, safety_settings=safety_settings ) generated_summary = response.text scores = scorer.score(reference_summary, generated_summary) results.append({ "generated": generated_summary, "reference": reference_summary, "rouge1": scores['rouge1'].fmeasure, "rouge2": scores['rouge2'].fmeasure, "rougeL": scores['rougeL'].fmeasure }) except Exception as e: print(f"Error processing example {index}: {e}") # Sleep briefly to avoid quota issues if hitting limits time.sleep(1) # Save results with open(output_json, 'w') as f: json.dump(results, f, indent=2) return pd.DataFrame(results) def plot_results(df, title, filename): os.makedirs("plots", exist_ok=True) metrics = ['rouge1', 'rouge2', 'rougeL'] fig, axes = plt.subplots(1, 3, figsize=(15, 5)) for i, metric in enumerate(metrics): axes[i].hist(df[metric], bins=10, alpha=0.7, color='skyblue', edgecolor='black') axes[i].set_title(f'{metric} Distribution') axes[i].set_xlabel('Score') axes[i].set_ylabel('Count') plt.suptitle(title) plt.tight_layout() plt.savefig(f"plots/{filename}") print(f"Plot saved to plots/{filename}") def compare_results(baseline_file, tuned_file): with open(baseline_file, 'r') as f: baseline_data = pd.DataFrame(json.load(f)) with open(tuned_file, 'r') as f: tuned_data = pd.DataFrame(json.load(f)) print("\n--- Comparison ---") metrics = ['rouge1', 'rouge2', 'rougeL'] for metric in metrics: base_mean = baseline_data[metric].mean() tuned_mean = tuned_data[metric].mean() diff = tuned_mean - base_mean print(f"{metric}: Base={base_mean:.4f}, Tuned={tuned_mean:.4f}, Diff={diff:+.4f}") # Comparative Plot os.makedirs("plots", exist_ok=True) comparison_df = pd.DataFrame({ 'Metric': metrics, 'Baseline': [baseline_data[m].mean() for m in metrics], 'Tuned': [tuned_data[m].mean() for m in metrics] }) comparison_df.plot(x='Metric', y=['Baseline', 'Tuned'], kind='bar', figsize=(10, 6)) plt.title('Baseline vs Tuned Model Performance') plt.ylabel('Average Score') plt.xticks(rotation=0) plt.tight_layout() plt.savefig("plots/comparison.png") print("Comparison plot saved to plots/comparison.png") def main(): parser = argparse.ArgumentParser() parser.add_argument("--model", type=str, default="gemini-2.5-flash", help="Model resource name") parser.add_argument("--baseline", type=str, help="Path to baseline results json for comparison") parser.add_argument("--output", type=str, default="results.json", help="Output file for results") args = parser.parse_args() # Ensure test data exists (it was downloaded in prepare_data step) if not os.path.exists("sft_test_samples.csv"): # Fallback download if needed subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/sft_test_samples.csv", "."], check=True) df = evaluate(args.model, "sft_test_samples.csv", output_json=args.output) print("\n--- Results Summary ---") print(df.describe()) plot_filename = "baseline_dist.png" if not args.baseline else "tuned_dist.png" plot_results(df, f"ROUGE Scores - {args.model}", plot_filename) if args.baseline: compare_results(args.baseline, args.output) if __name__ == "__main__": main() - W terminalu uruchom ocenę podstawową.
python evaluate.py --model "gemini-2.5-flash" --output "baseline.json"baseline.jsoni wykresu w formacieplots/baseline_dist.png.
8. Konfigurowanie i uruchamianie dostrajania
Teraz uruchomisz zarządzane zadanie dostrajania w Vertex AI.
- W terminalu utwórz plik o nazwie
tune.py.cloudshell edit tune.py - Wklej ten kod do pliku
tune.py.import os import time from google.cloud import aiplatform import vertexai from vertexai.preview.tuning import sft # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] BUCKET_NAME = os.environ["BUCKET_NAME"] aiplatform.init(project=PROJECT_ID, location=REGION) def train(): print("Launching fine-tuning job...") sft_tuning_job = sft.train( source_model="gemini-2.5-flash", # Using specific version for stability train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl", validation_dataset=f"gs://{BUCKET_NAME}/datasets/val/val_gemini.jsonl", epochs=1, # Keep it short for the lab adapter_size=4, learning_rate_multiplier=1.0, tuned_model_display_name="gemini-2.5-flash-wikilingua", ) print(f"Job started: {sft_tuning_job.resource_name}") print("Waiting for job to complete... (this may take ~45 minutes)") # Wait for the job to complete while not sft_tuning_job.has_ended: time.sleep(60) sft_tuning_job.refresh() print(f"Status: {sft_tuning_job.state.name}") print("Job completed!") print(f"Tuned Model Endpoint: {sft_tuning_job.tuned_model_endpoint_name}") return sft_tuning_job.tuned_model_endpoint_name if __name__ == "__main__": train() - W terminalu uruchom skrypt dostrajania.
python tune.py
9. Omówienie kodu trenowania
Podczas działania zadania przyjrzyjmy się bliżej tune.py skryptowi, aby zrozumieć, jak działa dostrajanie.
Zarządzane dostrajanie nadzorowane
Skrypt używa metody vertexai.tuning.sft.train do przesyłania zadania dostrajania zarządzanego. Upraszcza to proces udostępniania infrastruktury, dystrybucji trenowania i zarządzania punktami kontrolnymi.
sft_tuning_job = sft.train(
source_model="gemini-2.5-flash",
train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl",
# ...
)
Konfiguracja LoRA
Zamiast ręcznie definiować LoraConfig, jak to się robi w przypadku platform open source, Vertex AI upraszcza ten proces do kilku kluczowych parametrów:
adapter_size: ten parametr (w naszym skrypcie ma wartość4) określa rangę adapterów LoRA. Większy rozmiar umożliwia modelowi uczenie się bardziej złożonych adaptacji, ale zwiększa liczbę parametrów z możliwością trenowania.epochs: w tym laboratorium ustawiamy tę wartość na1, aby skrócić czas trenowania (~20 minut). W scenariuszu produkcyjnym możesz zwiększyć tę wartość, aby umożliwić modelowi dokładniejsze uczenie się na podstawie danych, ale musisz uważać na przeuczenie.
Wybór modelu
Wyraźnie określamy wartość source_model="gemini-2.5-flash". Vertex AI obsługuje różne wersje Gemini, a przypinanie konkretnej wersji zapewnia stabilność i powtarzalność potoku.
10. Porównanie modeli
Po zakończeniu zadania dostrajania możesz porównać skuteczność nowego modelu z wartością bazową.
- Uzyskaj punkt końcowy dostrojonego modelu. Został on wydrukowany na końcu skryptu
tune.py. Będzie wyglądać mniej więcej tak:projects/.../locations/.../endpoints/.... - Ponownie uruchom skrypt oceny, tym razem przekazując dostrojony model i wyniki bazowe do porównania.
# Replace [YOUR_TUNED_MODEL_ENDPOINT] with the actual endpoint name export TUNED_MODEL="projects/[YOUR_PROJECT_ID]/locations/[YOUR_REGION]/endpoints/[YOUR_ENDPOINT_ID]" python evaluate.py --model "$TUNED_MODEL" --baseline "baseline.json" --output "tuned.json" - wyświetlić wyniki, Skrypt wyświetli porównanie wyników ROUGE i wygeneruje wykres
plots/comparison.pngpokazujący poprawę.Wykresy możesz wyświetlić, otwierając folderplotsw edytorze Cloud Shell.
11. Czyszczenie danych
Aby uniknąć opłat, usuń utworzone zasoby.
- W terminalu usuń zasobnik Cloud Storage i dostrojony model.
gcloud storage rm -r gs://$BUCKET_NAME # Note: You can delete the model endpoint from the Vertex AI Console
12. Gratulacje!
Model Gemini 2.5 Flash został dostrojony w Vertex AI.
Podsumowanie
W tym module omówimy następujące zagadnienia:
- Przygotuj zbiór danych w formacie JSONL do dostrajania modelu Gemini.
- Ustalono punkt odniesienia przy użyciu podstawowego modelu Gemini 2.5 Flash.
- Uruchomiono zadanie dostrajania nadzorowanego w Vertex AI.
- Ocena i porównanie dostrojonego modelu z modelem bazowym.
Co dalej?
Ten moduł jest częścią ścieżki szkoleniowej AI gotowa do wdrożenia w Google Cloud.
Zapoznaj się z pełnym programem nauczania, aby przejść od prototypu do produkcji.
Udostępnij swoje postępy, używając hashtaga #ProductionReadyAI.