
1. Giriş
Bu laboratuvarda, Google Gemini modelinde denetimli ince ayar iş akışının tamamını gerçekleştirerek modeli belirli bir göreve (makale özetleme) uyarlamayı öğreneceksiniz. Büyük dil modelleri güçlü olsa da genel amaçlı olmaları nedeniyle ince ayar yapılarak belirli kullanım alanlarında daha da etkili hale getirilebilirler. Modeli yüksek kaliteli bir örnek veri kümesi üzerinde eğiterek hedef göreviniz için tutarlılığını, kalitesini ve verimliliğini artırabilirsiniz.
Hafif ve uygun maliyetli bir model olan Gemini 2.5 Flash'i kullanacak ve Vertex AI'ı kullanarak ince ayar yapacaksınız.
Mimarisine Genel Bakış
Bu etkinlikte oluşturacağımız öğeler:
- Cloud Shell: Geliştirme ortamınız.
- Cloud Storage: Eğitim/doğrulama verilerini JSONL biçiminde depolar.
- Vertex AI Training: İnce ayar işini yönetir.
- Vertex AI uç noktası: İnce ayar yaptığınız modeli barındırır.
Neler öğreneceksiniz?
- Gözetimli ince ayar için yüksek kaliteli veri kümeleri hazırlayın.
- Python için Vertex AI SDK'yı kullanarak ince ayar işlerini yapılandırma ve başlatma
- Modelleri otomatik metrikleri (ROUGE puanları) kullanarak değerlendirin.
- İyileştirmeleri ölçmek için temel ve ince ayarlı modelleri karşılaştırın.
2. Proje ayarlama
Google Hesabı
Kişisel Google Hesabınız yoksa Google Hesabı oluşturmanız gerekir.
İş veya okul hesabı yerine kişisel hesap kullanın.
Google Cloud Console'da oturum açma
Kişisel bir Google Hesabı kullanarak Google Cloud Console'da oturum açın.
Faturalandırmayı Etkinleştir
Google Cloud kredilerini kullanma (isteğe bağlı)
Bu atölyeyi düzenlemek için biraz kredisi olan bir faturalandırma hesabınızın olması gerekir. Başlamak için bu codelab'in üst kısmındaki banner'da yer alan kredileri kullanın. Zaten bir faturalandırma hesabına bağlıysanız bu adımı atlayabilirsiniz.
Proje oluşturma (isteğe bağlı)
Bu laboratuvarda kullanmak istediğiniz mevcut bir projeniz yoksa buradan yeni bir proje oluşturun.
3. Cloud Shell Düzenleyici'yi açma
- Doğrudan Cloud Shell Düzenleyici'ye gitmek için bu bağlantıyı tıklayın.
- Bugün herhangi bir noktada yetkilendirmeniz istenirse devam etmek için Yetkilendir'i tıklayın.
- Terminal ekranın alt kısmında görünmüyorsa açın:
- Görünüm'ü tıklayın.
- Terminal'i tıklayın.
- Terminalde şu komutla projenizi ayarlayın:
gcloud config set project [PROJECT_ID]- Örnek:
gcloud config set project lab-project-id-example - Proje kimliğinizi hatırlamıyorsanız tüm proje kimliklerinizi şu komutla listeleyebilirsiniz:
gcloud projects list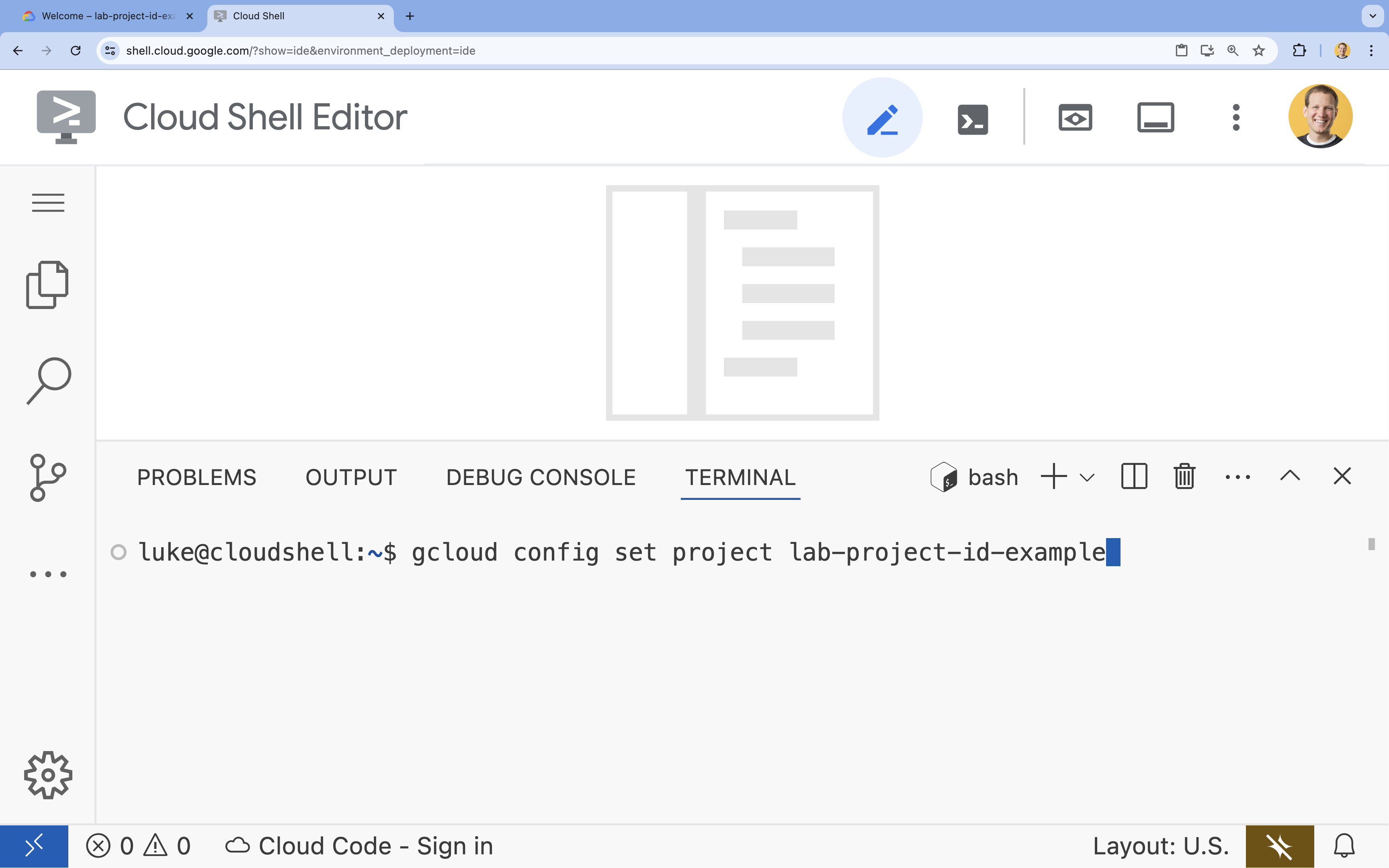
- Örnek:
- Şu mesajı görmeniz gerekir:
Updated property [core/project].
4. API'leri etkinleştir
Vertex AI ve diğer hizmetleri kullanmak için Google Cloud projenizde gerekli API'leri etkinleştirmeniz gerekir.
- Terminalde API'leri etkinleştirin:
- Vertex AI API (
aiplatform.googleapis.com): Modelleri ince ayarlamak ve sunmak için Vertex AI'ın kullanılmasını sağlar. - Cloud Storage API (
storage.googleapis.com): Veri kümelerinin ve model yapıtlarının depolanmasını sağlar.
gcloud services enable aiplatform.googleapis.com \ storage.googleapis.com - Vertex AI API (
5. Proje ortamını ayarlama
Çalışma dizini oluşturma
- Terminalde projeniz için bir dizin oluşturun ve bu dizine gidin.
mkdir gemini-finetuning cd gemini-finetuning
Ortam değişkenlerini ayarlama
- Terminalde projenizin ortam değişkenlerini tanımlayın. Oturumunuzun bağlantısı kesilirse kolayca yeniden yüklenebilmeleri için bu değişkenleri saklamak üzere bir
env.shdosyası oluşturacağız.cat <<EOF > env.sh export PROJECT_ID=\$(gcloud config get-value project) export REGION="us-central1" export BUCKET_NAME="\${PROJECT_ID}-gemini-tuning" EOF source env.sh
Cloud Storage paketi oluşturma
- Terminalde, veri kümenizi ve model yapıtlarınızı depolayacak bir paket oluşturun.
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION
Sanal ortamı ayarlama
- Python ortamımızı yönetmek için
uvkullanacağız. Terminalde şunu çalıştırın:uv venv .venv source .venv/bin/activate - Terminalde gerekli Python paketlerini yükleyin.
uv pip install google-cloud-aiplatform rouge-score matplotlib pandas tqdm
6. Eğitim verilerini hazırlama
Kaliteli veriler, başarılı ince ayarın temelini oluşturur. WikiLingua veri kümesini kullanacak, bunu Gemini'ın gerektirdiği belirli JSONL biçimine dönüştürecek ve depolama paketinize yükleyeceksiniz.
- Terminalde
prepare_data.pyadlı bir dosya oluşturun.cloudshell edit prepare_data.py - Aşağıdaki kodu
prepare_data.pydosyasına yapıştırın.import json import os import pandas as pd from google.cloud import storage import subprocess # Configuration BUCKET_NAME = os.environ["BUCKET_NAME"] PROJECT_ID = os.environ["PROJECT_ID"] def download_data(): print("Downloading WikiLingua dataset...") # Using gsutil to copy from public bucket subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/*", "."], check=True) def convert_to_gemini_format(input_file, output_file, max_samples=1000): print(f"Converting {input_file} to Gemini format (first {max_samples} samples)...") converted_data = [] with open(input_file, 'r') as f: for i, line in enumerate(f): if i >= max_samples: break obj = json.loads(line) messages = obj.get("messages", []) # Convert messages to Gemini 2.5 format # Input: {"messages": [{"role": "user", "content": "..."}, {"role": "model", "content": "..."}]} # Output: {"contents": [{"role": "user", "parts": [{"text": "..."}]}, {"role": "model", "parts": [{"text": "..."}]}]} contents = [] for msg in messages: role = msg["role"] content = msg["content"] contents.append({ "role": role, "parts": [{"text": content}] }) converted_data.append({"contents": contents}) with open(output_file, 'w') as f: for item in converted_data: f.write(json.dumps(item) + "\n") print(f"Saved {len(converted_data)} examples to {output_file}") def upload_to_gcs(local_file, destination_blob_name): print(f"Uploading {local_file} to gs://{BUCKET_NAME}/{destination_blob_name}...") storage_client = storage.Client(project=PROJECT_ID) bucket = storage_client.bucket(BUCKET_NAME) blob = bucket.blob(destination_blob_name) blob.upload_from_filename(local_file) print("Upload complete.") def main(): download_data() # Process Training Data convert_to_gemini_format("sft_train_samples.jsonl", "train_gemini.jsonl") upload_to_gcs("train_gemini.jsonl", "datasets/train/train_gemini.jsonl") # Process Validation Data convert_to_gemini_format("sft_val_samples.jsonl", "val_gemini.jsonl") upload_to_gcs("val_gemini.jsonl", "datasets/val/val_gemini.jsonl") print("Data preparation complete!") if __name__ == "__main__": main() - Terminalde veri hazırlama komut dosyasını çalıştırın.
python prepare_data.py
7. Temel performans oluşturma
İnce ayar yapmadan önce bir karşılaştırma yapmanız gerekir. ROUGE puanlarını kullanarak temel gemini-2.5-flash modelin özetleme görevindeki performansını ölçersiniz.
- Terminalde
evaluate.pyadlı bir dosya oluşturun.cloudshell edit evaluate.py - Aşağıdaki kodu
evaluate.pydosyasına yapıştırın.import argparse import json import os import pandas as pd from google.cloud import aiplatform import vertexai from vertexai.generative_models import GenerativeModel, GenerationConfig, HarmCategory, HarmBlockThreshold from rouge_score import rouge_scorer from tqdm import tqdm import matplotlib.pyplot as plt import time # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] aiplatform.init(project=PROJECT_ID, location=REGION) def evaluate(model_name, test_file, max_samples=50, output_json="results.json"): print(f"Evaluating model: {model_name}") # Load Test Data test_df = pd.read_csv(test_file) test_df = test_df.head(max_samples) model = GenerativeModel(model_name) safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, } generation_config = GenerationConfig( temperature=0.1, max_output_tokens=1024, ) scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True) results = [] for index, row in tqdm(test_df.iterrows(), total=len(test_df)): input_text = row['input_text'] reference_summary = row['output_text'] try: response = model.generate_content( input_text, generation_config=generation_config, safety_settings=safety_settings ) generated_summary = response.text scores = scorer.score(reference_summary, generated_summary) results.append({ "generated": generated_summary, "reference": reference_summary, "rouge1": scores['rouge1'].fmeasure, "rouge2": scores['rouge2'].fmeasure, "rougeL": scores['rougeL'].fmeasure }) except Exception as e: print(f"Error processing example {index}: {e}") # Sleep briefly to avoid quota issues if hitting limits time.sleep(1) # Save results with open(output_json, 'w') as f: json.dump(results, f, indent=2) return pd.DataFrame(results) def plot_results(df, title, filename): os.makedirs("plots", exist_ok=True) metrics = ['rouge1', 'rouge2', 'rougeL'] fig, axes = plt.subplots(1, 3, figsize=(15, 5)) for i, metric in enumerate(metrics): axes[i].hist(df[metric], bins=10, alpha=0.7, color='skyblue', edgecolor='black') axes[i].set_title(f'{metric} Distribution') axes[i].set_xlabel('Score') axes[i].set_ylabel('Count') plt.suptitle(title) plt.tight_layout() plt.savefig(f"plots/{filename}") print(f"Plot saved to plots/{filename}") def compare_results(baseline_file, tuned_file): with open(baseline_file, 'r') as f: baseline_data = pd.DataFrame(json.load(f)) with open(tuned_file, 'r') as f: tuned_data = pd.DataFrame(json.load(f)) print("\n--- Comparison ---") metrics = ['rouge1', 'rouge2', 'rougeL'] for metric in metrics: base_mean = baseline_data[metric].mean() tuned_mean = tuned_data[metric].mean() diff = tuned_mean - base_mean print(f"{metric}: Base={base_mean:.4f}, Tuned={tuned_mean:.4f}, Diff={diff:+.4f}") # Comparative Plot os.makedirs("plots", exist_ok=True) comparison_df = pd.DataFrame({ 'Metric': metrics, 'Baseline': [baseline_data[m].mean() for m in metrics], 'Tuned': [tuned_data[m].mean() for m in metrics] }) comparison_df.plot(x='Metric', y=['Baseline', 'Tuned'], kind='bar', figsize=(10, 6)) plt.title('Baseline vs Tuned Model Performance') plt.ylabel('Average Score') plt.xticks(rotation=0) plt.tight_layout() plt.savefig("plots/comparison.png") print("Comparison plot saved to plots/comparison.png") def main(): parser = argparse.ArgumentParser() parser.add_argument("--model", type=str, default="gemini-2.5-flash", help="Model resource name") parser.add_argument("--baseline", type=str, help="Path to baseline results json for comparison") parser.add_argument("--output", type=str, default="results.json", help="Output file for results") args = parser.parse_args() # Ensure test data exists (it was downloaded in prepare_data step) if not os.path.exists("sft_test_samples.csv"): # Fallback download if needed subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/sft_test_samples.csv", "."], check=True) df = evaluate(args.model, "sft_test_samples.csv", output_json=args.output) print("\n--- Results Summary ---") print(df.describe()) plot_filename = "baseline_dist.png" if not args.baseline else "tuned_dist.png" plot_results(df, f"ROUGE Scores - {args.model}", plot_filename) if args.baseline: compare_results(args.baseline, args.output) if __name__ == "__main__": main() - Terminalde temel değerlendirmeyi çalıştırın.
python evaluate.py --model "gemini-2.5-flash" --output "baseline.json"baseline.jsondosyası veplots/baseline_dist.pngiçinde bir grafik oluşturur.
8. İnce ayarı yapılandırma ve başlatma
Şimdi Vertex AI'da yönetilen bir temel model özelleştirme işi başlatacaksınız.
- Terminalde
tune.pyadlı bir dosya oluşturun.cloudshell edit tune.py - Aşağıdaki kodu
tune.pydosyasına yapıştırın.import os import time from google.cloud import aiplatform import vertexai from vertexai.preview.tuning import sft # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] BUCKET_NAME = os.environ["BUCKET_NAME"] aiplatform.init(project=PROJECT_ID, location=REGION) def train(): print("Launching fine-tuning job...") sft_tuning_job = sft.train( source_model="gemini-2.5-flash", # Using specific version for stability train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl", validation_dataset=f"gs://{BUCKET_NAME}/datasets/val/val_gemini.jsonl", epochs=1, # Keep it short for the lab adapter_size=4, learning_rate_multiplier=1.0, tuned_model_display_name="gemini-2.5-flash-wikilingua", ) print(f"Job started: {sft_tuning_job.resource_name}") print("Waiting for job to complete... (this may take ~45 minutes)") # Wait for the job to complete while not sft_tuning_job.has_ended: time.sleep(60) sft_tuning_job.refresh() print(f"Status: {sft_tuning_job.state.name}") print("Job completed!") print(f"Tuned Model Endpoint: {sft_tuning_job.tuned_model_endpoint_name}") return sft_tuning_job.tuned_model_endpoint_name if __name__ == "__main__": train() - Terminalde ince ayar komut dosyasını çalıştırın.
python tune.py
9. Eğitim kodunu anlama
İşiniz çalışırken ince ayarın nasıl çalıştığını anlamak için tune.py komut dosyasına daha yakından bakalım.
Yönetilen denetimli ince ayar
Komut dosyası, yönetilen ayarlama işi göndermek için vertexai.tuning.sft.train yöntemini kullanıyor. Bu sayede, altyapı hazırlama, eğitimi dağıtma ve kontrol noktalarını yönetme gibi karmaşık işlemler soyutlanır.
sft_tuning_job = sft.train(
source_model="gemini-2.5-flash",
train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl",
# ...
)
LoRA Yapılandırması
Açık kaynak çerçevelerinde olduğu gibi LoraConfig değerini manuel olarak tanımlamak yerine Vertex AI, bu işlemi birkaç temel parametreye indirger:
adapter_size: Bu parametre (komut dosyamızda4olarak ayarlanır), LoRA bağdaştırıcılarının sıralamasını kontrol eder. Daha büyük bir boyut, modelin daha karmaşık uyarlamaları öğrenmesine olanak tanır ancak eğitilebilir parametrelerin sayısını artırır.epochs: Bu laboratuvarda eğitim süresini kısa tutmak için (~20 dakika) bu değeri1olarak ayarladık. Üretim senaryosunda, modelin verilerinizden daha derinlemesine öğrenmesini sağlamak için bu değeri artırabilirsiniz ancak aşırı uyum konusunda dikkatli olmanız gerekir.
Model Seçimi
source_model="gemini-2.5-flash" değerini açıkça belirtiriz. Vertex AI, Gemini'ın çeşitli sürümlerini destekler. Belirli bir sürümü sabitlemek, ardışık düzeninizin kararlı ve yeniden üretilebilir kalmasını sağlar.
10. Model karşılaştırma
İnce ayar işi tamamlandıktan sonra yeni modelinizin performansını temel performansla karşılaştırabilirsiniz.
- Hassaslaştırılmış modelinizin uç noktasını alın.
tune.pysenaryosunun sonunda basılmıştır. Bu,projects/.../locations/.../endpoints/...gibi görünür. - Değerlendirme komut dosyasını tekrar çalıştırın. Bu kez, karşılaştırma için ayarlanmış modelinizi ve temel sonuçları iletin.
# Replace [YOUR_TUNED_MODEL_ENDPOINT] with the actual endpoint name export TUNED_MODEL="projects/[YOUR_PROJECT_ID]/locations/[YOUR_REGION]/endpoints/[YOUR_ENDPOINT_ID]" python evaluate.py --model "$TUNED_MODEL" --baseline "baseline.json" --output "tuned.json" - Sonuçları görüntüleyin. Komut dosyası, ROUGE puanlarının karşılaştırmasını verir ve iyileşmeyi gösteren bir
plots/comparison.pnggrafiği oluşturur.Grafikleri Cloud Shell Düzenleyici'deplots/comparison.pngklasörünü açarak görüntüleyebilirsiniz.plots
11. Temizleme
Ücretlendirilmemek için oluşturduğunuz kaynakları silin.
- Terminalde Cloud Storage paketini ve ince ayarlı modeli silin.
gcloud storage rm -r gs://$BUCKET_NAME # Note: You can delete the model endpoint from the Vertex AI Console
12. Tebrikler!
Vertex AI'da Gemini 2.5 Flash'a başarıyla ince ayar yaptınız.
Özet
Bu laboratuvarda şunları öğreneceksiniz:
- Gemini ince ayarı için JSONL biçiminde bir veri kümesi hazırladıysanız.
- Temel Gemini 2.5 Flash modelini kullanarak bir temel oluşturdu.
- Vertex AI'da denetimli ince ayar işi başlattıysanız.
- İnce ayarlı modeli değerlendirip referans değerle karşılaştırdı.
Sırada ne var?
Bu laboratuvar, Google Cloud ile Üretime Hazır Yapay Zeka öğrenme rotasının bir parçasıdır.
Prototip aşamasından üretim aşamasına geçiş yapmak için tüm müfredatı inceleyin.
İlerlemenizi #ProductionReadyAI hashtag'iyle paylaşın.