
1. Giới thiệu
Trong phòng thí nghiệm này, bạn sẽ học cách thực hiện toàn bộ quy trình tinh chỉnh có giám sát trên một mô hình Google Gemini để điều chỉnh mô hình đó cho một tác vụ cụ thể: tóm tắt bài viết. Mặc dù mô hình ngôn ngữ lớn rất mạnh mẽ, nhưng bản chất đa năng của chúng có nghĩa là bạn có thể điều chỉnh mô hình để tăng hiệu quả cho các trường hợp sử dụng cụ thể. Bằng cách huấn luyện mô hình trên một tập dữ liệu chất lượng cao gồm các ví dụ, bạn có thể cải thiện tính nhất quán, chất lượng và hiệu quả của mô hình cho nhiệm vụ mục tiêu.
Bạn sẽ sử dụng Gemini 2.5 Flash, một mô hình gọn nhẹ và tiết kiệm chi phí, đồng thời tinh chỉnh bằng Vertex AI.
Tổng quan về Cấu trúc (Architecture)
Sau đây là những gì chúng ta sẽ xây dựng:
- Cloud Shell: Môi trường phát triển của bạn.
- Cloud Storage: Lưu trữ dữ liệu huấn luyện/xác thực ở định dạng JSONL.
- Vertex AI Training: Quản lý quy trình tinh chỉnh.
- Điểm cuối Vertex AI: Lưu trữ mô hình được tinh chỉnh của bạn.
Kiến thức bạn sẽ học được
- Chuẩn bị các tập dữ liệu chất lượng cao để tinh chỉnh có giám sát.
- Định cấu hình và chạy các tác vụ tinh chỉnh bằng Vertex AI SDK cho Python.
- Đánh giá các mô hình bằng cách sử dụng các chỉ số tự động (điểm ROUGE).
- So sánh các mô hình cơ sở và mô hình được tinh chỉnh để định lượng mức độ cải thiện.
2. Thiết lập dự án
Tài khoản Google
Nếu chưa có Tài khoản Google cá nhân, bạn phải tạo một Tài khoản Google.
Sử dụng tài khoản cá nhân thay vì tài khoản do nơi làm việc hoặc trường học cấp.
Đăng nhập vào Google Cloud Console
Đăng nhập vào Google Cloud Console bằng Tài khoản Google cá nhân.
Bật thanh toán
Sử dụng tín dụng Google Cloud (không bắt buộc)
Để tham gia hội thảo này, bạn cần có một tài khoản thanh toán có sẵn một số tín dụng. Hãy sử dụng tín dụng trong biểu ngữ ở đầu lớp học lập trình này để bắt đầu. Nếu đã kết nối với một tài khoản thanh toán, bạn có thể bỏ qua bước này.
Tạo dự án (không bắt buộc)
Nếu bạn không có dự án hiện tại nào muốn sử dụng cho lớp học này, hãy tạo một dự án mới tại đây.
3. Mở Trình chỉnh sửa Cloud Shell
- Nhấp vào đường liên kết này để chuyển trực tiếp đến Cloud Shell Editor
- Nếu được nhắc uỷ quyền vào bất kỳ thời điểm nào trong ngày hôm nay, hãy nhấp vào Uỷ quyền để tiếp tục.
- Nếu thiết bị đầu cuối không xuất hiện ở cuối màn hình, hãy mở thiết bị đầu cuối:
- Nhấp vào Xem
- Nhấp vào Terminal (Thiết bị đầu cuối)
- Trong cửa sổ dòng lệnh, hãy thiết lập dự án bằng lệnh sau:
gcloud config set project [PROJECT_ID]- Ví dụ:
gcloud config set project lab-project-id-example - Nếu không nhớ mã dự án, bạn có thể liệt kê tất cả mã dự án bằng cách dùng lệnh:
gcloud projects list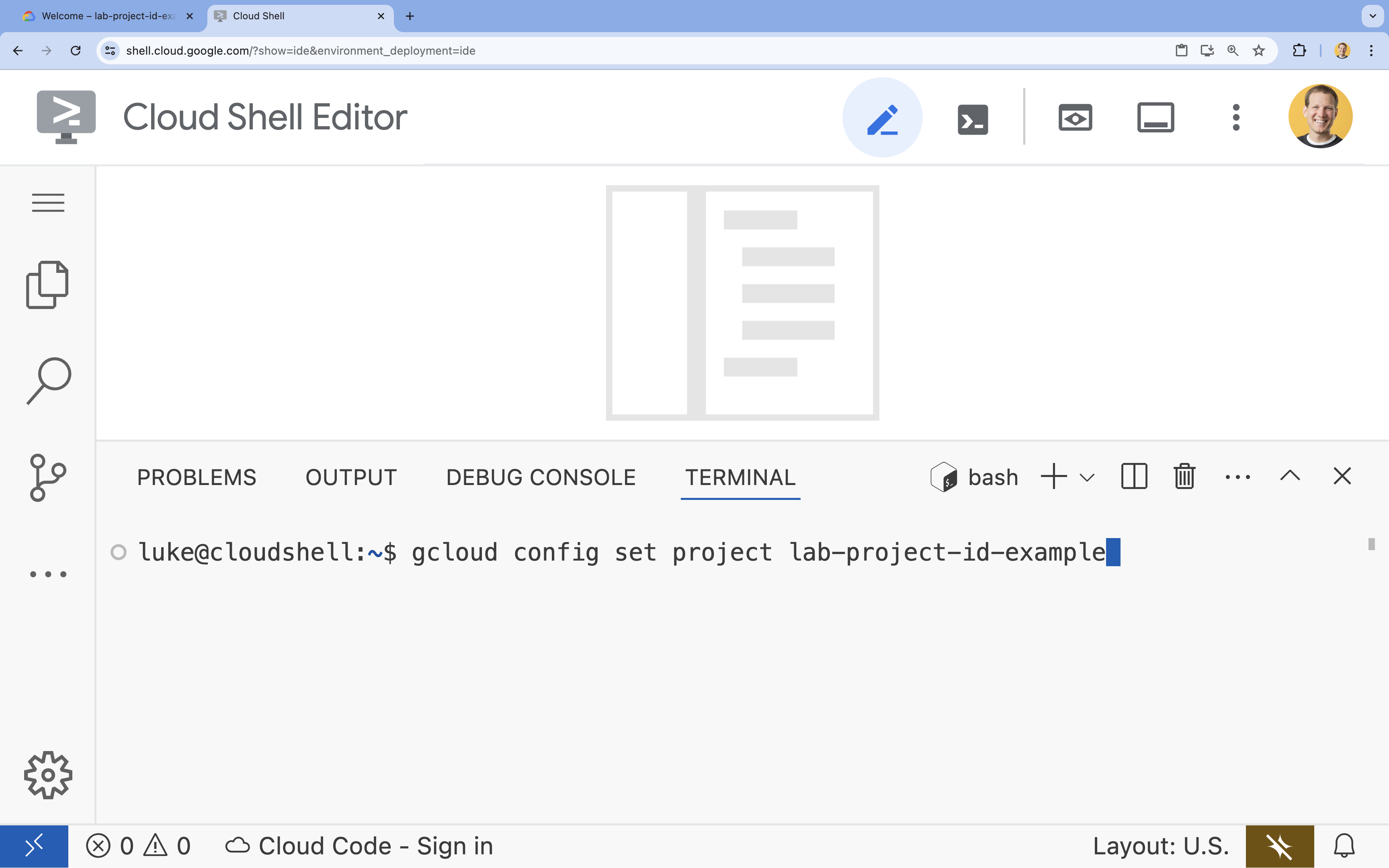
- Ví dụ:
- Bạn sẽ thấy thông báo sau:
Updated property [core/project].
4. Bật API
Để sử dụng Vertex AI và các dịch vụ khác, bạn cần bật các API cần thiết trong dự án trên đám mây của mình.
- Trong dòng lệnh, hãy bật các API:
- Vertex AI API (
aiplatform.googleapis.com): Cho phép sử dụng Vertex AI để tinh chỉnh và phân phát các mô hình. - Cloud Storage API (
storage.googleapis.com): Cho phép lưu trữ các tập dữ liệu và cấu phần phần mềm mô hình.
gcloud services enable aiplatform.googleapis.com \ storage.googleapis.com - Vertex AI API (
5. Thiết lập môi trường dự án
Tạo thư mục làm việc
- Trong thiết bị đầu cuối, hãy tạo một thư mục cho dự án của bạn rồi chuyển đến thư mục đó.
mkdir gemini-finetuning cd gemini-finetuning
Thiết lập các biến môi trường
- Trong thiết bị đầu cuối, hãy xác định các biến môi trường cho dự án của bạn. Chúng ta sẽ tạo một tệp
env.shđể lưu trữ các biến này để có thể dễ dàng tải lại nếu phiên của bạn bị ngắt kết nối.cat <<EOF > env.sh export PROJECT_ID=\$(gcloud config get-value project) export REGION="us-central1" export BUCKET_NAME="\${PROJECT_ID}-gemini-tuning" EOF source env.sh
Tạo một bộ chứa Cloud Storage
- Trong thiết bị đầu cuối, hãy tạo một vùng chứa để lưu trữ tập dữ liệu và các cấu phần phần mềm mô hình.
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION
Thiết lập môi trường ảo
- Chúng ta sẽ dùng
uvđể quản lý môi trường Python. Trong thiết bị đầu cuối, hãy chạy:uv venv .venv source .venv/bin/activate - Trong terminal, hãy cài đặt các gói Python cần thiết.
uv pip install google-cloud-aiplatform rouge-score matplotlib pandas tqdm
6. Chuẩn bị dữ liệu huấn luyện
Dữ liệu chất lượng là nền tảng của quá trình tinh chỉnh thành công. Bạn sẽ sử dụng tập dữ liệu WikiLingua, chuyển đổi tập dữ liệu đó thành định dạng JSONL cụ thể mà Gemini yêu cầu và tải tập dữ liệu đó lên bộ chứa lưu trữ của bạn.
- Trong thiết bị đầu cuối, hãy tạo một tệp có tên là
prepare_data.py.cloudshell edit prepare_data.py - Dán mã sau vào
prepare_data.py.import json import os import pandas as pd from google.cloud import storage import subprocess # Configuration BUCKET_NAME = os.environ["BUCKET_NAME"] PROJECT_ID = os.environ["PROJECT_ID"] def download_data(): print("Downloading WikiLingua dataset...") # Using gsutil to copy from public bucket subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/*", "."], check=True) def convert_to_gemini_format(input_file, output_file, max_samples=1000): print(f"Converting {input_file} to Gemini format (first {max_samples} samples)...") converted_data = [] with open(input_file, 'r') as f: for i, line in enumerate(f): if i >= max_samples: break obj = json.loads(line) messages = obj.get("messages", []) # Convert messages to Gemini 2.5 format # Input: {"messages": [{"role": "user", "content": "..."}, {"role": "model", "content": "..."}]} # Output: {"contents": [{"role": "user", "parts": [{"text": "..."}]}, {"role": "model", "parts": [{"text": "..."}]}]} contents = [] for msg in messages: role = msg["role"] content = msg["content"] contents.append({ "role": role, "parts": [{"text": content}] }) converted_data.append({"contents": contents}) with open(output_file, 'w') as f: for item in converted_data: f.write(json.dumps(item) + "\n") print(f"Saved {len(converted_data)} examples to {output_file}") def upload_to_gcs(local_file, destination_blob_name): print(f"Uploading {local_file} to gs://{BUCKET_NAME}/{destination_blob_name}...") storage_client = storage.Client(project=PROJECT_ID) bucket = storage_client.bucket(BUCKET_NAME) blob = bucket.blob(destination_blob_name) blob.upload_from_filename(local_file) print("Upload complete.") def main(): download_data() # Process Training Data convert_to_gemini_format("sft_train_samples.jsonl", "train_gemini.jsonl") upload_to_gcs("train_gemini.jsonl", "datasets/train/train_gemini.jsonl") # Process Validation Data convert_to_gemini_format("sft_val_samples.jsonl", "val_gemini.jsonl") upload_to_gcs("val_gemini.jsonl", "datasets/val/val_gemini.jsonl") print("Data preparation complete!") if __name__ == "__main__": main() - Trong thiết bị đầu cuối, hãy chạy tập lệnh chuẩn bị dữ liệu.
python prepare_data.py
7. Thiết lập hiệu suất cơ sở
Trước khi tinh chỉnh, bạn cần có một điểm chuẩn. Bạn sẽ đo lường hiệu suất của mô hình cơ sở gemini-2.5-flash trong nhiệm vụ tóm tắt bằng cách sử dụng điểm ROUGE.
- Trong thiết bị đầu cuối, hãy tạo một tệp có tên là
evaluate.py.cloudshell edit evaluate.py - Dán mã sau vào
evaluate.py.import argparse import json import os import pandas as pd from google.cloud import aiplatform import vertexai from vertexai.generative_models import GenerativeModel, GenerationConfig, HarmCategory, HarmBlockThreshold from rouge_score import rouge_scorer from tqdm import tqdm import matplotlib.pyplot as plt import time # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] aiplatform.init(project=PROJECT_ID, location=REGION) def evaluate(model_name, test_file, max_samples=50, output_json="results.json"): print(f"Evaluating model: {model_name}") # Load Test Data test_df = pd.read_csv(test_file) test_df = test_df.head(max_samples) model = GenerativeModel(model_name) safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, } generation_config = GenerationConfig( temperature=0.1, max_output_tokens=1024, ) scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True) results = [] for index, row in tqdm(test_df.iterrows(), total=len(test_df)): input_text = row['input_text'] reference_summary = row['output_text'] try: response = model.generate_content( input_text, generation_config=generation_config, safety_settings=safety_settings ) generated_summary = response.text scores = scorer.score(reference_summary, generated_summary) results.append({ "generated": generated_summary, "reference": reference_summary, "rouge1": scores['rouge1'].fmeasure, "rouge2": scores['rouge2'].fmeasure, "rougeL": scores['rougeL'].fmeasure }) except Exception as e: print(f"Error processing example {index}: {e}") # Sleep briefly to avoid quota issues if hitting limits time.sleep(1) # Save results with open(output_json, 'w') as f: json.dump(results, f, indent=2) return pd.DataFrame(results) def plot_results(df, title, filename): os.makedirs("plots", exist_ok=True) metrics = ['rouge1', 'rouge2', 'rougeL'] fig, axes = plt.subplots(1, 3, figsize=(15, 5)) for i, metric in enumerate(metrics): axes[i].hist(df[metric], bins=10, alpha=0.7, color='skyblue', edgecolor='black') axes[i].set_title(f'{metric} Distribution') axes[i].set_xlabel('Score') axes[i].set_ylabel('Count') plt.suptitle(title) plt.tight_layout() plt.savefig(f"plots/{filename}") print(f"Plot saved to plots/{filename}") def compare_results(baseline_file, tuned_file): with open(baseline_file, 'r') as f: baseline_data = pd.DataFrame(json.load(f)) with open(tuned_file, 'r') as f: tuned_data = pd.DataFrame(json.load(f)) print("\n--- Comparison ---") metrics = ['rouge1', 'rouge2', 'rougeL'] for metric in metrics: base_mean = baseline_data[metric].mean() tuned_mean = tuned_data[metric].mean() diff = tuned_mean - base_mean print(f"{metric}: Base={base_mean:.4f}, Tuned={tuned_mean:.4f}, Diff={diff:+.4f}") # Comparative Plot os.makedirs("plots", exist_ok=True) comparison_df = pd.DataFrame({ 'Metric': metrics, 'Baseline': [baseline_data[m].mean() for m in metrics], 'Tuned': [tuned_data[m].mean() for m in metrics] }) comparison_df.plot(x='Metric', y=['Baseline', 'Tuned'], kind='bar', figsize=(10, 6)) plt.title('Baseline vs Tuned Model Performance') plt.ylabel('Average Score') plt.xticks(rotation=0) plt.tight_layout() plt.savefig("plots/comparison.png") print("Comparison plot saved to plots/comparison.png") def main(): parser = argparse.ArgumentParser() parser.add_argument("--model", type=str, default="gemini-2.5-flash", help="Model resource name") parser.add_argument("--baseline", type=str, help="Path to baseline results json for comparison") parser.add_argument("--output", type=str, default="results.json", help="Output file for results") args = parser.parse_args() # Ensure test data exists (it was downloaded in prepare_data step) if not os.path.exists("sft_test_samples.csv"): # Fallback download if needed subprocess.run(["gsutil", "cp", "gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/sft_test_samples.csv", "."], check=True) df = evaluate(args.model, "sft_test_samples.csv", output_json=args.output) print("\n--- Results Summary ---") print(df.describe()) plot_filename = "baseline_dist.png" if not args.baseline else "tuned_dist.png" plot_results(df, f"ROUGE Scores - {args.model}", plot_filename) if args.baseline: compare_results(args.baseline, args.output) if __name__ == "__main__": main() - Trong thiết bị đầu cuối, hãy chạy quy trình đánh giá cơ sở.
python evaluate.py --model "gemini-2.5-flash" --output "baseline.json"baseline.jsonvà một biểu đồ trongplots/baseline_dist.png.
8. Định cấu hình và khởi chạy quy trình tinh chỉnh
Bây giờ, bạn sẽ chạy một quy trình tinh chỉnh được quản lý trên Vertex AI.
- Trong thiết bị đầu cuối, hãy tạo một tệp có tên là
tune.py.cloudshell edit tune.py - Dán mã sau vào
tune.py.import os import time from google.cloud import aiplatform import vertexai from vertexai.preview.tuning import sft # Configuration PROJECT_ID = os.environ["PROJECT_ID"] REGION = os.environ["REGION"] BUCKET_NAME = os.environ["BUCKET_NAME"] aiplatform.init(project=PROJECT_ID, location=REGION) def train(): print("Launching fine-tuning job...") sft_tuning_job = sft.train( source_model="gemini-2.5-flash", # Using specific version for stability train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl", validation_dataset=f"gs://{BUCKET_NAME}/datasets/val/val_gemini.jsonl", epochs=1, # Keep it short for the lab adapter_size=4, learning_rate_multiplier=1.0, tuned_model_display_name="gemini-2.5-flash-wikilingua", ) print(f"Job started: {sft_tuning_job.resource_name}") print("Waiting for job to complete... (this may take ~45 minutes)") # Wait for the job to complete while not sft_tuning_job.has_ended: time.sleep(60) sft_tuning_job.refresh() print(f"Status: {sft_tuning_job.state.name}") print("Job completed!") print(f"Tuned Model Endpoint: {sft_tuning_job.tuned_model_endpoint_name}") return sft_tuning_job.tuned_model_endpoint_name if __name__ == "__main__": train() - Trong thiết bị đầu cuối, hãy chạy tập lệnh tinh chỉnh.
python tune.py
9. Tìm hiểu về mã đào tạo
Trong khi công việc của bạn đang chạy, hãy xem xét kỹ hơn tập lệnh tune.py để hiểu cách hoạt động của quy trình tinh chỉnh.
Tinh chỉnh có giám sát được quản lý
Tập lệnh này sử dụng phương thức vertexai.tuning.sft.train để gửi một lệnh điều chỉnh có quản lý. Điều này giúp loại bỏ sự phức tạp của việc cung cấp cơ sở hạ tầng, phân phối hoạt động huấn luyện và quản lý các điểm kiểm tra.
sft_tuning_job = sft.train(
source_model="gemini-2.5-flash",
train_dataset=f"gs://{BUCKET_NAME}/datasets/train/train_gemini.jsonl",
# ...
)
Cấu hình LoRA
Thay vì xác định LoraConfig theo cách thủ công như bạn có thể làm trong các khung mã nguồn mở, Vertex AI đơn giản hoá việc này thành một vài thông số chính:
adapter_size: Tham số này (được đặt thành4trong tập lệnh của chúng tôi) kiểm soát thứ hạng của các bộ điều hợp LoRA. Kích thước lớn hơn cho phép mô hình học được những điểm thích ứng phức tạp hơn nhưng làm tăng số lượng tham số có thể huấn luyện.epochs: Chúng tôi đặt giá trị này thành1cho phòng thí nghiệm này để rút ngắn thời gian huấn luyện (~20 phút). Trong trường hợp sản xuất, bạn có thể tăng giá trị này để cho phép mô hình học sâu hơn từ dữ liệu của bạn, mặc dù bạn nên chú ý đến việc mô hình khớp quá mức.
Lựa chọn mô hình
Chúng tôi chỉ định rõ ràng source_model="gemini-2.5-flash". Vertex AI hỗ trợ nhiều phiên bản của Gemini và việc ghim một phiên bản cụ thể sẽ đảm bảo quy trình của bạn luôn ổn định và có thể tái tạo.
10. So sánh các mô hình
Sau khi hoàn tất quy trình tinh chỉnh, bạn có thể so sánh hiệu suất của mô hình mới với mô hình cơ sở.
- Lấy điểm cuối của mô hình đã được điều chỉnh. Nội dung này được in ở cuối kịch bản
tune.py. Biểu tượng này sẽ có dạng nhưprojects/.../locations/.../endpoints/.... - Chạy lại tập lệnh đánh giá, lần này truyền mô hình đã điều chỉnh và kết quả cơ sở để so sánh.
# Replace [YOUR_TUNED_MODEL_ENDPOINT] with the actual endpoint name export TUNED_MODEL="projects/[YOUR_PROJECT_ID]/locations/[YOUR_REGION]/endpoints/[YOUR_ENDPOINT_ID]" python evaluate.py --model "$TUNED_MODEL" --baseline "baseline.json" --output "tuned.json" - Xem kết quả. Tập lệnh sẽ xuất ra thông tin so sánh về điểm ROUGE và tạo biểu đồ
plots/comparison.pngcho thấy mức độ cải thiện.Bạn có thể xem các biểu đồ bằng cách mở thư mụcplotstrong Cloud Shell Editor.
11. Dọn dẹp
Để tránh bị tính phí, hãy xoá các tài nguyên mà bạn đã tạo.
- Trong thiết bị đầu cuối, hãy xoá bộ chứa Cloud Storage và mô hình đã điều chỉnh.
gcloud storage rm -r gs://$BUCKET_NAME # Note: You can delete the model endpoint from the Vertex AI Console
12. Xin chúc mừng!
Bạn đã tinh chỉnh thành công Gemini 2.5 Flash trên Vertex AI!
Tóm tắt
Trong lớp học lập trình này, bạn sẽ:
- Chuẩn bị một tập dữ liệu ở định dạng JSONL để tinh chỉnh Gemini.
- Thiết lập một đường cơ sở bằng mô hình Gemini 2.5 Flash cơ bản.
- Khởi chạy một quy trình tinh chỉnh có giám sát trên Vertex AI.
- Đánh giá và so sánh mô hình được tinh chỉnh với mô hình cơ sở.
Bước tiếp theo
Phòng thí nghiệm này thuộc Lộ trình học tập AI sẵn sàng cho hoạt động sản xuất với Google Cloud.
Khám phá toàn bộ chương trình học để thu hẹp khoảng cách từ nguyên mẫu đến sản xuất.
Chia sẻ tiến trình của bạn bằng hashtag #ProductionReadyAI.