
1. مقدمة
في هذا الدرس العملي، ستتعلّم كيفية إنشاء مسار متكامل ودقيق لضبط نموذج اللغة الشهير والمفتوح المصدر Llama 2، وذلك باستخدام Google Kubernetes Engine (GKE). ستتعرّف على القرارات المتعلقة بالتصميم، والمفاضلات الشائعة، والمكوّنات التي تحاكي أساليب سير عمل عمليات تعلُّم الآلة (MLOps) في العالم الحقيقي.
ستوفّر مجموعة GKE، وتنشئ مسار تدريب مستندًا إلى الحاويات باستخدام LoRA (Low-Rank Adaptation)، وتشغّل مهمة التدريب على GKE.
نظرة عامة على الهندسة المعمارية
إليك ما سننشئه اليوم:
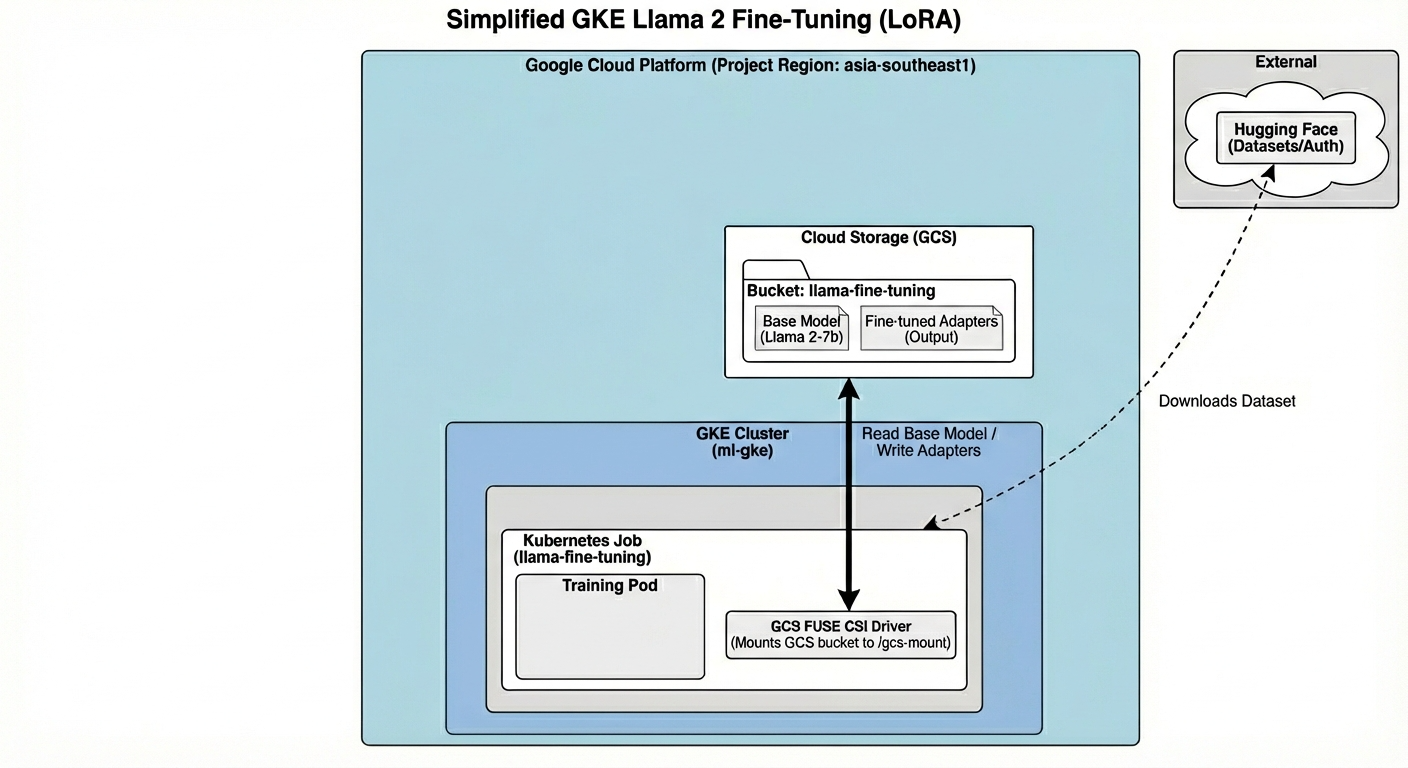
تشمل البنية ما يلي:
- مجموعة GKE: تدير موارد الحوسبة
- مجموعة عقدة وحدة معالجة الرسومات: وحدة معالجة رسومات L4 واحدة (Spot) للتدريب
- حزمة GCS: تخزِّن النماذج ومجموعات البيانات
- Workload Identity: الوصول الآمن بين K8s وGCS
أهداف الدورة التعليمية
- توفير مجموعة GKE وتكوينها باستخدام ميزات محسَّنة لأحمال عمل تعلُّم الآلة
- يمكنك تنفيذ وصول آمن وبدون مفتاح من GKE إلى خدمات Google Cloud الأخرى باستخدام Workload Identity.
- إنشاء مسار تدريب في حاوية باستخدام Docker
- يمكنك ضبط نموذج مفتوح المصدر بدقة وبكفاءة باستخدام تقنية الضبط الدقيق الفعّال للمعلَمات (PEFT) مع LoRA.
2. إعداد المشروع
حساب Google
إذا لم يكن لديك حساب Google شخصي، عليك إنشاء حساب على Google.
استخدام حساب شخصي بدلاً من حساب تابع للعمل أو تديره مؤسسة تعليمية
تسجيل الدخول إلى Google Cloud Console
سجِّل الدخول إلى Google Cloud Console باستخدام حساب Google شخصي.
إنشاء مشروع (اختياري)
إذا لم يكن لديك مشروع حالي تريد استخدامه في هذا المختبر، يمكنك إنشاء مشروع جديد هنا.
3- فتح "محرّر Cloud Shell"
- انقر على هذا الرابط للانتقال مباشرةً إلى محرّر Cloud Shell
- إذا طُلب منك منح الإذن في أي وقت اليوم، انقر على منح الإذن للمتابعة.
- إذا لم تظهر المحطة الطرفية في أسفل الشاشة، افتحها باتّباع الخطوات التالية:
- انقر على عرض.
- انقر على Terminal
- في الوحدة الطرفية، اضبط مشروعك باستخدام الأمر التالي:
gcloud config set project [PROJECT_ID]- مثال:
gcloud config set project lab-project-id-example - إذا تعذّر عليك تذكُّر رقم تعريف مشروعك، يمكنك إدراج جميع أرقام تعريف المشاريع باستخدام:
gcloud projects list
- مثال:
- من المفترض أن تظهر لك هذه الرسالة:
Updated property [core/project].
4. تفعيل واجهات برمجة التطبيقات
لاستخدام GKE والخدمات الأخرى، عليك تفعيل واجهات برمجة التطبيقات اللازمة في مشروعك على Google Cloud.
- في الوحدة الطرفية، فعِّل واجهات برمجة التطبيقات:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
لمحة عن واجهات برمجة التطبيقات
- تتيح لك واجهة برمجة التطبيقات Google Kubernetes Engine API (
container.googleapis.com) إنشاء مجموعة GKE التي تشغّل تطبيقك وإدارتها. - توفّر Artifact Registry API (
artifactregistry.googleapis.com) مستودعًا آمنًا وخاصًا لتخزين صور الحاويات. - يتم استخدام Cloud Build API (
cloudbuild.googleapis.com) من خلال الأمرgcloud builds submitلإنشاء صورة الحاوية في السحابة الإلكترونية. - تتيح لك واجهة برمجة التطبيقات IAM (
iam.googleapis.com) إدارة التحكّم في الوصول والهوية لموارد Google Cloud. - توفّر Compute Engine API (
compute.googleapis.com) أجهزة افتراضية آمنة وقابلة للتخصيص تعمل على بنية Google التحتية. - تتيح واجهة IAM Service Account Credentials API (
iamcredentials.googleapis.com) إنشاء بيانات اعتماد قصيرة الأمد لحسابات الخدمة. - تتيح لك Cloud Storage API (
storage.googleapis.com) تخزين البيانات واسترجاعها في السحابة الإلكترونية، ويتم استخدامها هنا لتخزين النماذج ومجموعات البيانات.
5- إعداد بيئة المشروع
إنشاء دليل عمل
- في نافذة الأوامر، أنشئ دليلاً لمشروعك وانتقِل إليه.
mkdir llama-finetuning cd llama-finetuning
إعداد متغيّرات البيئة
- في وحدة التحكّم، أنشئ ملفًا باسم
env.shلتخزين متغيرات البيئة. يضمن ذلك إمكانية إعادة تحميلها بسهولة في حال انقطاع اتصال جلستك.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - استخدِم الملف لتحميل المتغيرات إلى جلستك الحالية:
source env.sh
6. توفير مجموعة GKE
- في وحدة التحكّم، أنشئ مجموعة GKE مع مجموعة عقد تلقائية. سيستغرق ذلك حوالي 5 دقائق.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - بعد ذلك، أضِف مجموعة أجهزة ذات التخصيص نفسه لوحدة معالجة رسومات إلى المجموعة. سيتم استخدام مجموعة العُقد هذه لتدريب النموذج.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - وأخيرًا، احصل على بيانات اعتماد مجموعتك الجديدة وتأكَّد من إمكانية الاتصال بها.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. ضبط إعدادات وصول Hugging Face
بعد أن أصبحت البنية الأساسية جاهزة، عليك الآن تزويد مشروعك ببيانات الاعتماد اللازمة للوصول إلى النموذج والبيانات. في هذه المهمة، ستحصل أولاً على رمز مميز من Hugging Face.
الحصول على رمز مميّز من Hugging Face
- إذا لم يكن لديك حساب على Hugging Face، انتقِل إلى huggingface.co/join في علامة تبويب جديدة في المتصفّح وأكمِل عملية التسجيل.
- بعد التسجيل وتسجيل الدخول، انتقِل إلى huggingface.co/meta-llama/Llama-2-7b-hf.
- اقرأ بنود الترخيص وانقر على الزر لقبولها.
- انتقِل إلى صفحة رموز الوصول المميز في Hugging Face على huggingface.co/settings/tokens.
- انقر على رمز مميز جديد.
- بالنسبة إلى الدور، اختَر قراءة.
- بالنسبة إلى الاسم، أدخِل اسمًا وصفيًا (مثل finetuning-lab).
- انقر على إنشاء رمز مميز.
- انسخ الرمز المميز الذي تم إنشاؤه إلى الحافظة. ستحتاج إليه في الخطوة التالية.
تعديل متغيرات البيئة
لنضِف الآن رمز Hugging Face المميز واسم حزمة GCS إلى ملف env.sh. استبدِل [your-hf-token] بالرمز المميّز الذي نسخته للتوّ.
- في نافذة الأوامر، أضِف المتغيرات الجديدة إلى
env.shوأعِد تحميلها:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. ضبط Workload Identity
بعد ذلك، عليك إعداد Workload Identity، وهي الطريقة المقترَحة للسماح للتطبيقات التي تعمل على GKE بالوصول إلى خدمات Google Cloud بدون الحاجة إلى إدارة مفاتيح حساب الخدمة الثابتة. يمكنك الاطّلاع على مزيد من المعلومات في مستندات Workload Identity.
- أولاً، أنشئ حساب خدمة Google (GSA). في الوحدة الطرفية، شغِّل الأمر التالي:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - بعد ذلك، أنشِئ حزمة GCS وامنح حساب الخدمة المُدار من Google أذونات الوصول إليها:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - الآن، أنشئ حساب خدمة Kubernetes (KSA):
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - أخيرًا، أنشئ ربطًا لسياسة إدارة الهوية وإمكانية الوصول (IAM) بين حساب الخدمة المُدار من Google وحساب الخدمة المُدار من Kubernetes:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9- تجهيز النموذج الأساسي
في عمليات تعلُّم الآلة المتسلسلة، يتم عادةً إعداد نماذج كبيرة مثل Llama 2 (حوالي 13 غيغابايت) مسبقًا في Cloud Storage بدلاً من تنزيلها أثناء التدريب. يوفّر هذا الأسلوب موثوقية أفضل وإمكانية وصول أسرع ويتجنّب مشاكل الشبكة. توفّر Google Cloud إصدارات تم تنزيلها مسبقًا من النماذج الشائعة في حِزم GCS العامة، والتي ستستخدمها في هذا التمرين العملي.
- أولاً، لننتحقق من إمكانية وصولك إلى نموذج Llama 2 الذي توفّره Google:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - انسخ نموذج Llama 2 من هذا الحزمة المتاحة للجميع إلى حزمة مشروعك باستخدام الأمر
gcloud storage. تستخدِم عملية النقل هذه شبكة Google الداخلية العالية السرعة، ومن المفترض أن تستغرق دقيقة أو دقيقتَين فقط.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - تأكَّد من نسخ ملفات النموذج بشكل صحيح من خلال إدراج محتويات الحزمة.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. إعداد رمز التدريب
الآن، ستنشئ التطبيق الذي يعمل في حاوية والذي يضبط النموذج بدقة. تستخدم هذه المهمة أسلوب LoRA (التكييف المنخفض الترتيب)، وهو أسلوب فعّال من حيث المَعلمات لضبط النموذج بدقة، ويقلّل بشكل كبير من متطلبات الذاكرة من خلال تدريب طبقات "المحوّل" الصغيرة فقط بدلاً من النموذج بأكمله.
الآن، أنشئ نصوص Python البرمجية لمسار التدريب.
- في الوحدة الطرفية، نفِّذ الأمر التالي لفتح ملف
train.py:cloudshell edit train.py - ألصِق الرمز التالي في ملف
train.py:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. فهم رمز التدريب
يُدير النص البرمجي train.py عملية الضبط الدقيق. لنلقِ نظرة على مكوّناته الرئيسية.
التهيئة
يستخدم النص البرمجي LoraConfig لتحديد إعدادات Low-Rank Adaptation. يقلّل LoRA بشكل كبير عدد المَعلمات القابلة للتدريب، ما يتيح لك ضبط النماذج الكبيرة بدقة على وحدات معالجة الرسومات الأصغر حجمًا.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
إعداد مجموعة البيانات
تحمّل الدالة prepare_dataset مجموعة بيانات "قصص أمريكية" وتعالجها في أجزاء مقسّمة إلى رموز مميّزة. يستخدم هذا المشغّل SimpleTextDataset مخصّصًا للتعامل مع موترات الإدخال بكفاءة.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
قطار
تُعدّ الدالة train_model Trainer باستخدام وسيطات معيّنة محسّنة لعبء العمل هذا. تشمل المَعلمات الرئيسية ما يلي:
gradient_accumulation_steps: تساعد في محاكاة حجم الدفعة الأكبر بدون زيادة استخدام الذاكرة.fp16=True: تستخدم التدريب بدقة مختلطة لتقليل الذاكرة وزيادة السرعة.gradient_checkpointing=True: يتم حفظ الذاكرة من خلال إعادة احتساب عمليات التنشيط أثناء التمرير الخلفي بدلاً من تخزينها.-
optim="adamw_torch": تستخدم هذه السمة التنفيذ العادي لمحسِّن AdamW من PyTorch.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
الاستنتاج
تنفّذ الدالة run_inference اختبارًا سريعًا للنموذج المضبوط باستخدام عيّنة من الطلبات. يضمن ذلك أنّ النموذج في وضع التقييم وينشئ نصًا للتحقّق من أنّ المحوّلات تعمل بشكلٍ صحيح.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. تضمين التطبيق في حاوية
الآن، أنشئ صورة حاوية التدريب باستخدام Docker وادفعها إلى Google Artifact Registry.
- في الوحدة الطرفية، نفِّذ الأمر التالي لفتح ملف
Dockerfile:cloudshell edit Dockerfile - ألصِق الرمز التالي في ملف
Dockerfile:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
إنشاء الحاوية ونقلها
- أنشئ مستودع Artifact Registry:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - أنشئ الصورة وادفعها باستخدام Cloud Build:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. نشر مهمة التوليف الدقيق
- أنشئ بيان مهمة Kubernetes لبدء مهمة الضبط الدقيق. في الوحدة الطرفية، شغِّل الأمر التالي:
cloudshell edit training_job.yaml - ألصِق الرمز التالي في ملف
training_job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- أخيرًا، طبِّق بيان مهمة Kubernetes لبدء مهمة الضبط الدقيق على مجموعة GKE.
envsubst < training_job.yaml | kubectl apply -f -
14. مراقبة مهمة التدريب
يمكنك مراقبة مستوى تقدّم مهمة التدريب في Google Cloud Console.
- انتقِل إلى صفحة Kubernetes Engine > أحمال العمل.
عرض أحمال عمل GKE - انقر على مهمة
llama-fine-tuningللاطّلاع على تفاصيلها. - يتم عرض علامة التبويب التفاصيل تلقائيًا. يمكنك الاطّلاع على مقاييس استخدام وحدة معالجة الرسومات في قسم الموارد.
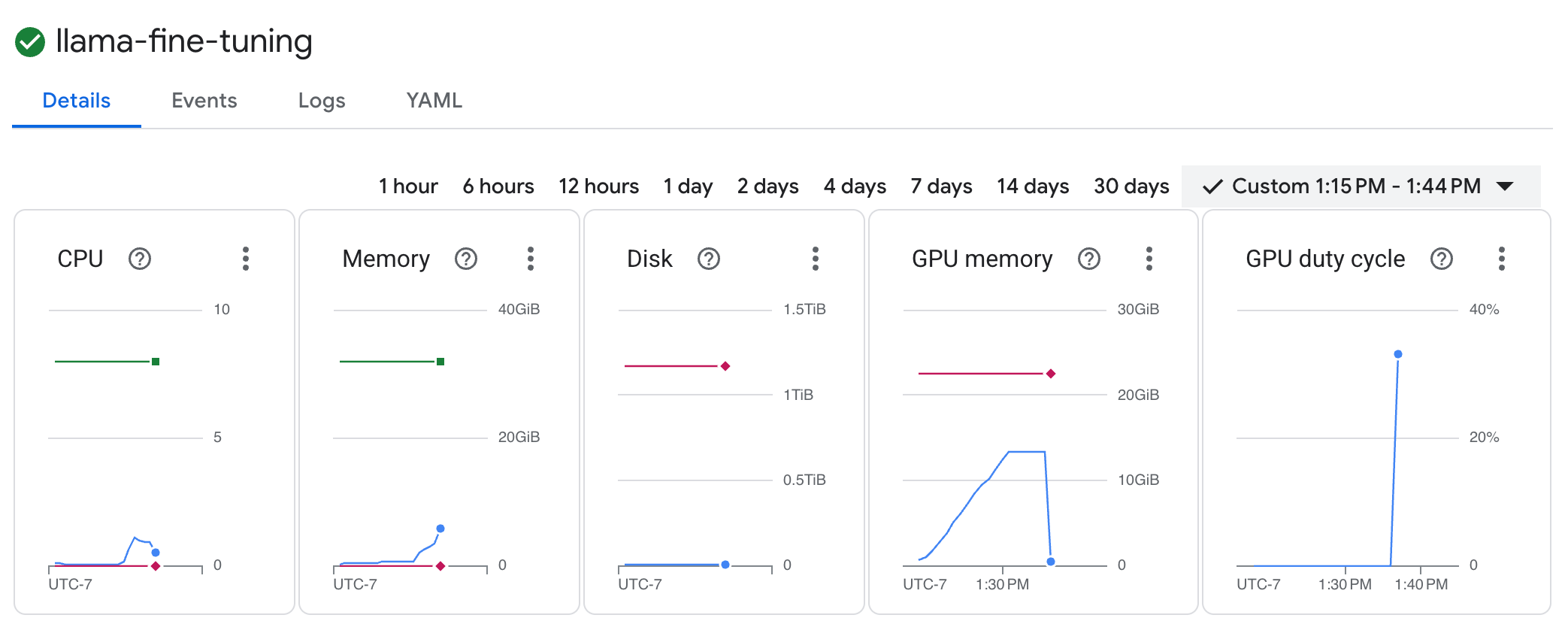
- انقر على علامة التبويب السجلات لعرض سجلات التدريب. يجب أن يظهر لك مستوى التقدّم في التدريب، بما في ذلك معدّل الخسارة ومعدّل التعلّم.
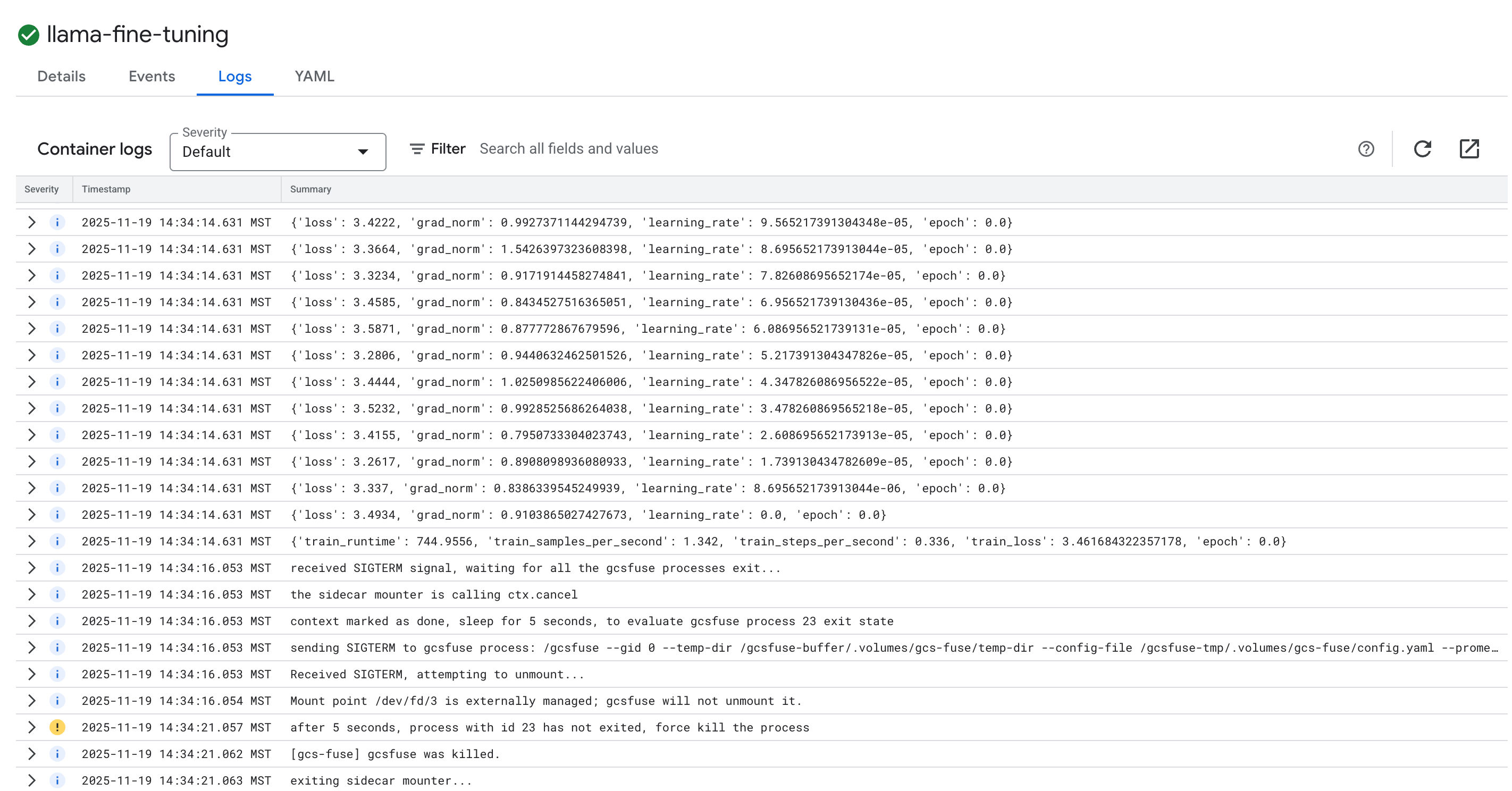
15. تَنظيم
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذا البرنامج التعليمي، احذف المشروع الذي يحتوي على الموارد أو احتفظ بالمشروع واحذف الموارد الفردية.
حذف مجموعة GKE
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
حذف مستودع Artifact Registry
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
حذف حزمة GCS
gcloud storage rm -r gs://${BUCKET_NAME}
16. تهانينا!
لقد نجحت في ضبط نموذج لغوي كبير مفتوح المصدر على GKE.
ملخّص
في هذا التمرين العملي، عليك:
- تم توفير مجموعة GKE مع تسريع وحدة معالجة الرسومات.
- تم إعداد Workload Identity للوصول الآمن إلى خدمات Google Cloud.
- إنشاء حاوية لوظيفة تدريب PyTorch باستخدام Docker وArtifact Registry
- تم نشر مهمة ضبط دقيق باستخدام LoRA لتكييف Llama 2 مع مجموعة بيانات جديدة.
الخطوات التالية
- مزيد من المعلومات حول الذكاء الاصطناعي على GKE
- استكشِف Model Garden في Vertex AI.
- انضم إلى منتدى Google Cloud للتواصل مع مطوّرين آخرين.
مسار التعلّم في Google Cloud
يشكّل هذا المختبر جزءًا من المسار التعليمي الذكاء الاصطناعي الجاهز للإنتاج باستخدام Google Cloud. استكشاف المنهج الدراسي الكامل لسدّ الفجوة بين النموذج الأوّلي والإنتاج
شارِك مستوى تقدّمك باستخدام الهاشتاغ #ProductionReadyAI.