
1. Einführung
In diesem Lab lernen Sie, wie Sie mit Google Kubernetes Engine (GKE) eine vollständige, produktionsreife Pipeline zum Optimieren von Llama 2 erstellen, einem beliebten Open-Source-Sprachmodell. Sie erfahren mehr über Architekturentscheidungen, häufige Kompromisse und Komponenten, die Workflows für Machine Learning Operations (MLOps) in der Praxis widerspiegeln.
Sie stellen einen GKE-Cluster bereit, erstellen eine containerisierte Trainingspipeline mit LoRA (Low-Rank Adaptation) und führen Ihren Trainingsjob in GKE aus.
Überblick über die Architektur
Das werden wir heute erstellen:
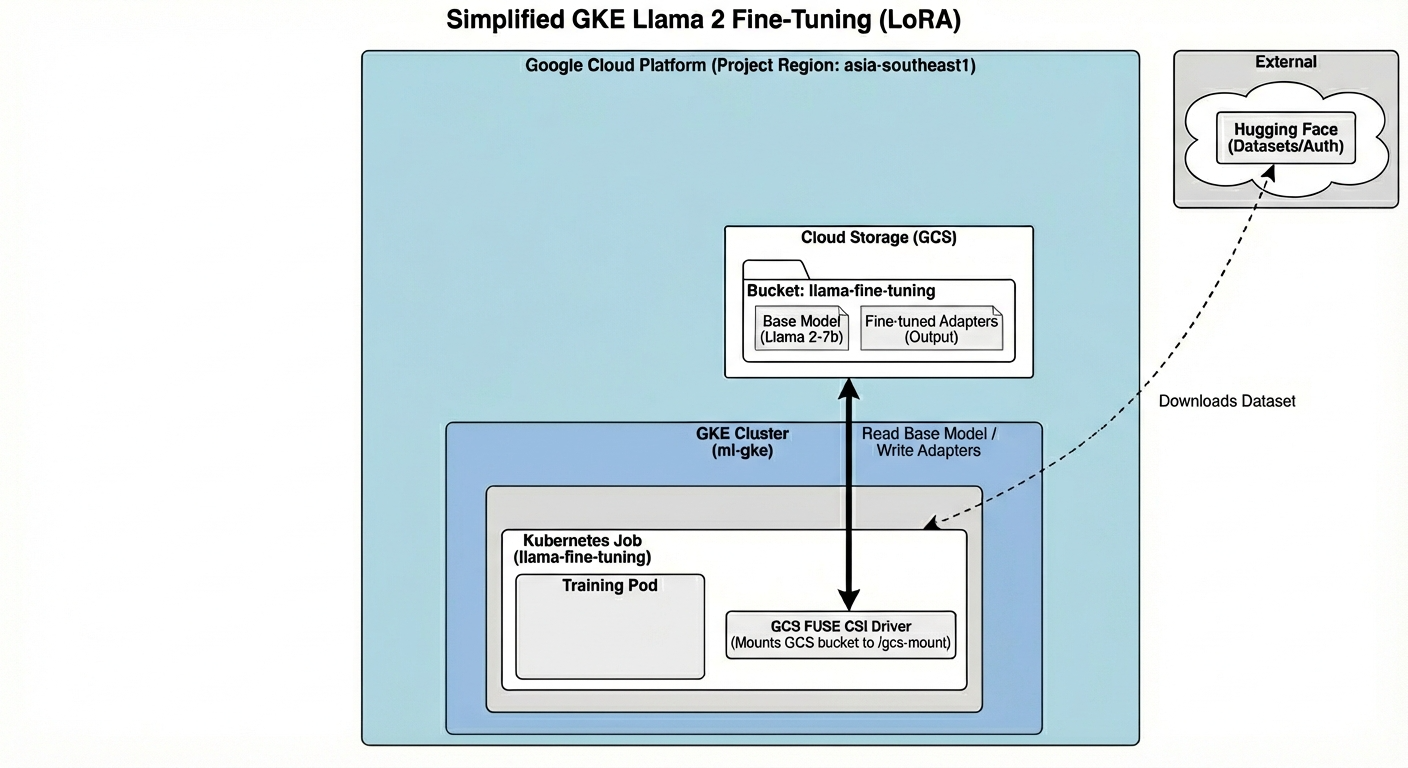
Die Architektur umfasst:
- GKE-Cluster: Verwaltet unsere Rechenressourcen
- GPU-Knotenpool: 1 L4-GPU (Spot) für das Training
- GCS-Bucket: Speichert Modelle und Datasets
- Workload Identity: Sicherer Zugriff zwischen K8s und GCS
Lerninhalte
- GKE-Cluster mit für ML-Arbeitslasten optimierten Funktionen bereitstellen und konfigurieren
- Implementieren Sie mit Workload Identity einen sicheren, schlüssellosen Zugriff von GKE auf andere Google Cloud-Dienste.
- Erstellen Sie eine containerisierte Trainingspipeline mit Docker.
- Ein Open-Source-Modell mit Parameter-Efficient Fine-Tuning (PEFT) mit LoRA effizient abstimmen.
2. Projekt einrichten
Google-Konto
Wenn Sie noch kein privates Google-Konto haben, müssen Sie ein Google-Konto erstellen.
Verwenden Sie stattdessen ein privates Konto.
In der Google Cloud Console anmelden
Melden Sie sich mit einem privaten Google-Konto in der Google Cloud Console an.
Projekt erstellen (optional)
Wenn Sie kein aktuelles Projekt haben, das Sie für dieses Lab verwenden möchten, erstellen Sie hier ein neues Projekt.
3. Cloud Shell-Editor öffnen
- Klicken Sie auf diesen Link, um direkt zum Cloud Shell-Editor zu gelangen.
- Wenn Sie heute an irgendeinem Punkt zur Autorisierung aufgefordert werden, klicken Sie auf Autorisieren, um fortzufahren.
- Wenn das Terminal nicht unten auf dem Bildschirm angezeigt wird, öffnen Sie es:
- Klicken Sie auf Ansehen.
- Klicken Sie auf Terminal
 .
.
- Legen Sie im Terminal Ihr Projekt mit diesem Befehl fest:
gcloud config set project [PROJECT_ID]- Beispiel:
gcloud config set project lab-project-id-example - Wenn Sie sich nicht mehr an Ihre Projekt-ID erinnern, können Sie alle Ihre Projekt-IDs mit folgendem Befehl auflisten:
gcloud projects list
- Beispiel:
- Es sollte folgende Meldung angezeigt werden:
Updated property [core/project].
4. APIs aktivieren
Damit Sie GKE und andere Dienste verwenden können, müssen Sie die erforderlichen APIs in Ihrem Google Cloud-Projekt aktivieren.
- Aktivieren Sie die APIs im Terminal:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
Einführung in die APIs
- Mit der Google Kubernetes Engine API (
container.googleapis.com) können Sie den GKE-Cluster erstellen und verwalten, in dem Ihre Anwendung ausgeführt wird. - Die Artifact Registry API (
artifactregistry.googleapis.com) bietet ein sicheres, privates Repository zum Speichern Ihrer Container-Images. - Die Cloud Build API (
cloudbuild.googleapis.com) wird vom Befehlgcloud builds submitverwendet, um Ihr Container-Image in der Cloud zu erstellen. - Mit der IAM API (
iam.googleapis.com) können Sie die Zugriffssteuerung und Identität für Ihre Google Cloud-Ressourcen verwalten. - Die Compute Engine API (
compute.googleapis.com) bietet sichere und anpassbare virtuelle Maschinen, die in der Infrastruktur von Google ausgeführt werden. - Mit der IAM Service Account Credentials API (
iamcredentials.googleapis.com) lassen sich kurzlebige Anmeldedaten für Dienstkonten erstellen. - Mit der Cloud Storage API (
storage.googleapis.com) können Sie Daten in der Cloud speichern und abrufen. Sie wird hier zum Speichern von Modellen und Datasets verwendet.
5. Projektumgebung einrichten
Arbeitsverzeichnis erstellen
- Erstellen Sie im Terminal ein Verzeichnis für Ihr Projekt und wechseln Sie zu diesem Verzeichnis.
mkdir llama-finetuning cd llama-finetuning
Umgebungsvariablen einrichten
- Erstellen Sie im Terminal eine Datei mit dem Namen
env.sh, in der Sie Ihre Umgebungsvariablen speichern. So können Sie sie ganz einfach neu laden, wenn die Verbindung zu Ihrer Sitzung getrennt wird.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - Rufen Sie die Datei auf, um die Variablen in Ihre aktuelle Sitzung zu laden:
source env.sh
6. GKE-Cluster bereitstellen
- Erstellen Sie im Terminal den GKE-Cluster mit einem Standardknotenpool. Das dauert etwa 5 Minuten.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - Fügen Sie als Nächstes dem Cluster einen GPU-Knotenpool hinzu. Dieser Knotenpool wird zum Trainieren des Modells verwendet.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - Rufen Sie schließlich die Anmeldedaten für den neuen Cluster ab und prüfen Sie, ob Sie eine Verbindung zu ihm herstellen können.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Hugging Face-Zugriff konfigurieren
Nachdem Sie Ihre Infrastruktur eingerichtet haben, müssen Sie Ihrem Projekt die erforderlichen Anmeldedaten für den Zugriff auf Ihr Modell und Ihre Daten zur Verfügung stellen. In dieser Aufgabe erhalten Sie zuerst ein Hugging Face-Token.
Hugging Face-Token abrufen
- Wenn Sie noch kein Hugging Face-Konto haben, rufen Sie in einem neuen Tab huggingface.co/join auf und schließen Sie die Registrierung ab.
- Rufen Sie nach der Registrierung und Anmeldung huggingface.co/meta-llama/Llama-2-7b-hf auf.
- Lesen Sie die Lizenzbedingungen und klicken Sie auf die Schaltfläche, um sie zu akzeptieren.
- Rufen Sie die Seite mit Ihren Hugging Face-Zugriffstokens unter huggingface.co/settings/tokens auf.
- Klicken Sie auf Neues Token.
- Wählen Sie unter Rolle die Option Lesen aus.
- Geben Sie unter Name einen aussagekräftigen Namen ein, z.B. „finetuning-lab“.
- Klicken Sie auf Create a token (Token erstellen).
- Kopieren Sie das Token in die Zwischenablage. Sie benötigen sie im nächsten Schritt.
Umgebungsvariablen aktualisieren
Fügen Sie nun Ihr Hugging Face-Token und einen Namen für Ihren GCS-Bucket in die Datei env.sh ein. Ersetzen Sie [your-hf-token] durch das Token, das Sie gerade kopiert haben.
- Hängen Sie im Terminal die neuen Variablen an
env.shan und laden Sie sie neu:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. Workload Identity konfigurieren
Als Nächstes richten Sie Workload Identity ein. Dies ist die empfohlene Methode, um Anwendungen, die in GKE ausgeführt werden, den Zugriff auf Google Cloud-Dienste zu ermöglichen, ohne dass statische Dienstkontoschlüssel verwaltet werden müssen. Weitere Informationen finden Sie in der Workload Identity-Dokumentation.
- Erstellen Sie zuerst ein Google-Dienstkonto (Google Service Account, GSA). Führen Sie im Terminal folgenden Befehl aus:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - Erstellen Sie als Nächstes den GCS-Bucket und erteilen Sie dem GSA die Berechtigung für den Zugriff darauf:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - Erstellen Sie nun ein Kubernetes-Dienstkonto (Kubernetes Service Account, KSA):
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - Erstellen Sie zum Schluss die IAM-Richtlinienbindung zwischen dem GSA und dem KSA:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. Basismodell bereitstellen
In Produktions-ML-Pipelines werden große Modelle wie Llama 2 (~13 GB) in der Regel in Cloud Storage vorab bereitgestellt, anstatt während des Trainings heruntergeladen zu werden. Dieser Ansatz bietet eine höhere Zuverlässigkeit, einen schnelleren Zugriff und vermeidet Netzwerkprobleme. Google Cloud bietet vorab heruntergeladene Versionen beliebter Modelle in öffentlichen GCS-Buckets, die Sie für dieses Lab verwenden.
- Prüfen Sie zuerst, ob Sie auf das von Google bereitgestellte Llama 2-Modell zugreifen können:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - Kopieren Sie das Llama 2-Modell mit dem Befehl
gcloud storageaus diesem öffentlichen Bucket in den Bucket Ihres eigenen Projekts. Für diese Übertragung wird das schnelle interne Netzwerk von Google verwendet. Sie sollte nur ein oder zwei Minuten dauern.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - Prüfen Sie, ob die Modelldateien korrekt kopiert wurden, indem Sie den Inhalt Ihres Buckets auflisten.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. Trainingscode vorbereiten
Jetzt erstellen Sie die Containeranwendung, mit der das Modell feinabgestimmt wird. Bei dieser Aufgabe wird LoRA (Low-Rank Adaptation) verwendet, eine PEFT-Technik (Parameter-Efficient Fine-Tuning), die den Speicherbedarf erheblich reduziert, da nur kleine „Adapter“-Ebenen anstelle des gesamten Modells trainiert werden.
Erstellen Sie nun die Python-Skripts für die Trainingspipeline.
- Führen Sie im Terminal den folgenden Befehl aus, um die Datei
train.pyzu öffnen:cloudshell edit train.py - Fügen Sie den folgenden Code in die
train.py-Datei ein:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. Trainingscode verstehen
Das train.py-Skript orchestriert den Prozess der Feinabstimmung. Sehen wir uns die wichtigsten Komponenten an.
Konfiguration
Im Skript werden LoraConfig verwendet, um die Einstellungen für die Low-Rank Adaptation zu definieren. LoRA reduziert die Anzahl der trainierbaren Parameter erheblich, sodass Sie große Modelle auf kleineren GPUs abstimmen können.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
Dataset vorbereiten
Die Funktion prepare_dataset lädt das Dataset „American Stories“ und verarbeitet es in tokenisierte Chunks. Dabei wird ein benutzerdefiniertes SimpleTextDataset verwendet, um die Eingabetensoren effizient zu verarbeiten.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
Zug
Mit der Funktion train_model wird Trainer mit bestimmten Argumenten eingerichtet, die für diese Arbeitslast optimiert sind. Zu den wichtigsten Parametern gehören:
gradient_accumulation_steps: Hilft, eine größere Batchgröße zu simulieren, ohne die Arbeitsspeichernutzung zu erhöhen.fp16=True: Verwendet das Training mit gemischter Genauigkeit, um den Speicherbedarf zu verringern und die Geschwindigkeit zu erhöhen.gradient_checkpointing=True: Durch die Neuberechnung von Aktivierungen während des Rückwärtsdurchlaufs anstelle der Speicherung wird Arbeitsspeicher gespart.optim="adamw_torch": Verwendet die Standardimplementierung des AdamW-Optimierers aus PyTorch.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
Inferenz
Mit der Funktion run_inference wird ein Schnelltest des feinabgestimmten Modells mit einem Beispiel-Prompt durchgeführt. Dadurch wird sichergestellt, dass sich das Modell im Bewertungsmodus befindet und Text generiert, um zu prüfen, ob die Adapter ordnungsgemäß funktionieren.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. Anwendung containerisieren
Erstellen Sie jetzt das Trainingscontainer-Image mit Docker und übertragen Sie es per Push in die Google Artifact Registry.
- Führen Sie im Terminal den folgenden Befehl aus, um die Datei
Dockerfilezu öffnen:cloudshell edit Dockerfile - Fügen Sie den folgenden Code in die
Dockerfile-Datei ein:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
Container erstellen und per Push übertragen
- Erstellen Sie das Artifact Registry-Repository:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Erstellen Sie das Image mit Cloud Build und übertragen Sie es per Push:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. Job für die Feinabstimmung bereitstellen
- Erstellen Sie das Kubernetes-Jobmanifest, um den Job für die Feinabstimmung zu starten. Führen Sie im Terminal folgenden Befehl aus:
cloudshell edit training_job.yaml - Fügen Sie den folgenden Code in die
training_job.yaml-Datei ein:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- Wenden Sie schließlich das Kubernetes-Jobmanifest an, um den Job für die Feinabstimmung in Ihrem GKE-Cluster zu starten.
envsubst < training_job.yaml | kubectl apply -f -
14. Trainingsjob überwachen
Sie können den Fortschritt Ihres Trainingsjobs in der Google Cloud Console verfolgen.
- Rufen Sie die Seite Kubernetes Engine > Arbeitslasten auf.
GKE-Arbeitslasten ansehen - Klicken Sie auf den Job
llama-fine-tuning, um die Details aufzurufen. - Der Tab Details wird standardmäßig angezeigt. Die Messwerte zur GPU-Nutzung finden Sie im Bereich Ressourcen.
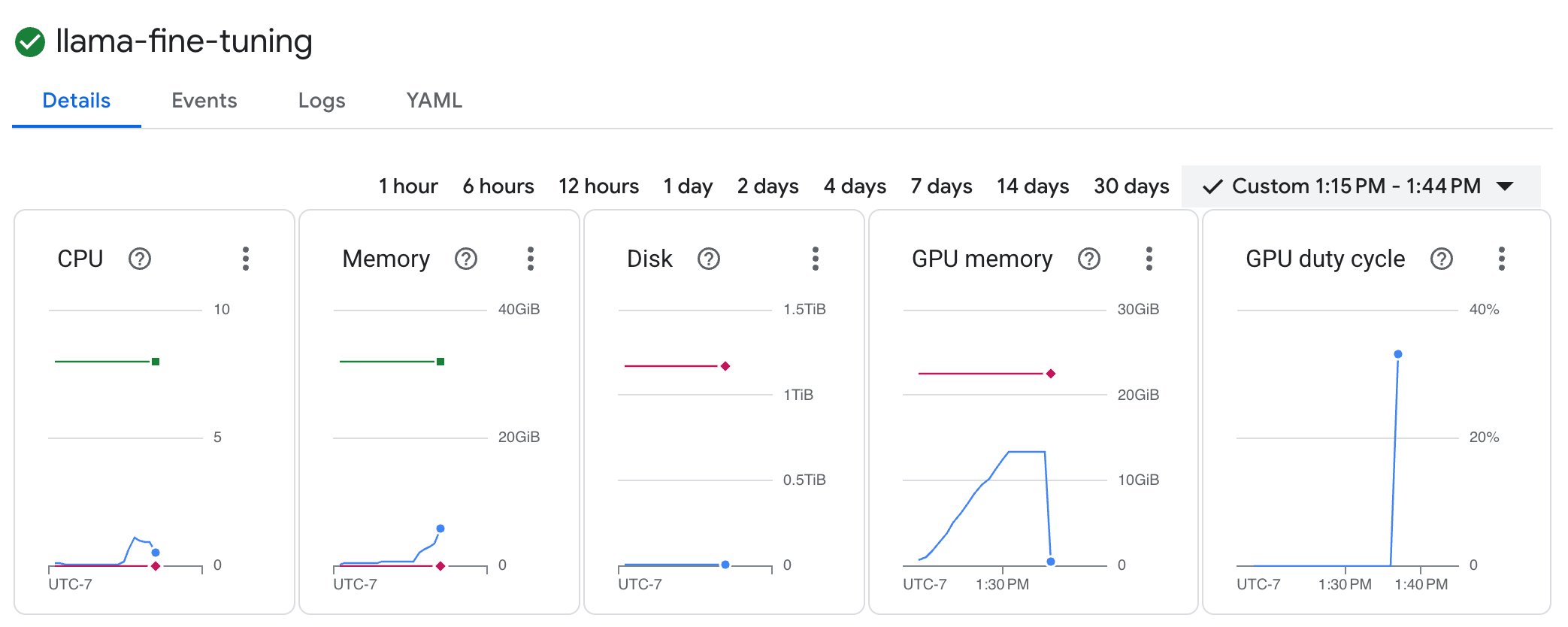
- Klicken Sie auf den Tab Logs, um die Trainingslogs aufzurufen. Sie sollten den Trainingsfortschritt sehen, einschließlich des Verlusts und der Lernrate.
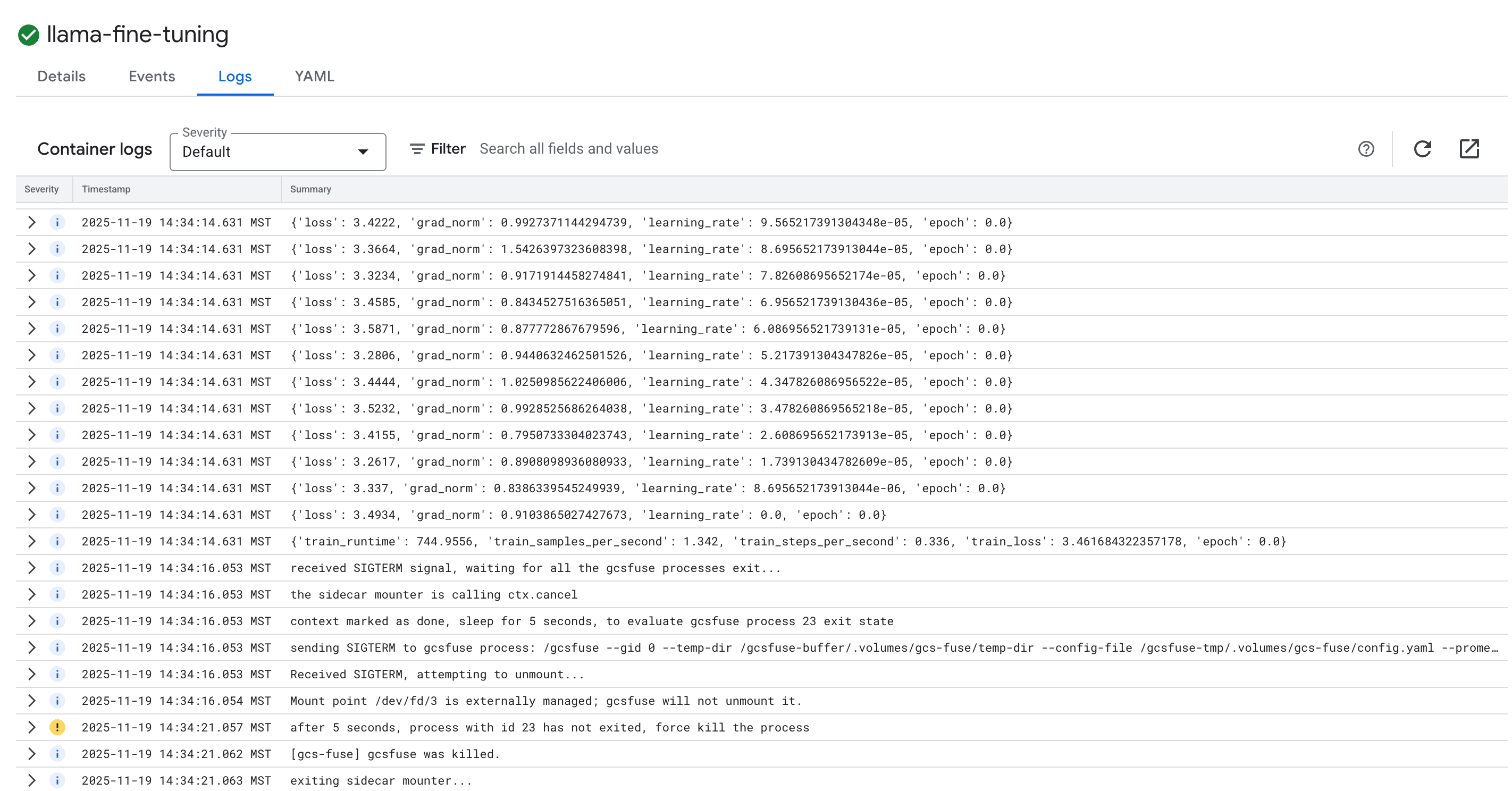
15. Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, können Sie entweder das Projekt löschen, das die Ressourcen enthält, oder das Projekt beibehalten und die einzelnen Ressourcen löschen.
GKE-Cluster löschen
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Artifact Registry-Repository löschen
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
GCS-Bucket löschen
gcloud storage rm -r gs://${BUCKET_NAME}
16. Glückwunsch!
Sie haben ein Open-Source-LLM erfolgreich in GKE feinabgestimmt.
Zusammenfassung
Die Aufgaben in diesem Lab:
- Sie haben einen GKE-Cluster mit GPU-Beschleunigung bereitgestellt.
- Workload Identity für den sicheren Zugriff auf Google Cloud-Dienste konfiguriert.
- Sie haben einen PyTorch-Trainingsjob mit Docker und Artifact Registry containerisiert.
- Sie haben einen Fine-Tuning-Job mit LoRA bereitgestellt, um Llama 2 an ein neues Dataset anzupassen.
Nächste Schritte
- Weitere Informationen zu KI in GKE
- Vertex AI Model Garden
- Treten Sie der Google Cloud-Community bei, um sich mit anderen Entwicklern auszutauschen.
Google Cloud-Lernpfad
Dieses Lab ist Teil des Lernpfads Produktionsreife KI mit Google Cloud. Gesamten Lehrplan ansehen
Teilen Sie Ihren Fortschritt unter dem Hashtag #ProductionReadyAI.