
1. Introducción
En este lab, aprenderás a compilar una canalización de ajuste fino completa y apta para la producción para Llama 2, un modelo de lenguaje de código abierto popular, con Google Kubernetes Engine (GKE). Aprenderás sobre las decisiones de arquitectura, las compensaciones comunes y los componentes que reflejan los flujos de trabajo de las Operaciones de aprendizaje automático (MLOps) del mundo real.
Aprovisionarás un clúster de GKE, compilarás una canalización de entrenamiento alojada en contenedores con LoRA (adaptación de bajo rango) y ejecutarás tu trabajo de entrenamiento en GKE.
Descripción general de la arquitectura
Esto es lo que compilaremos hoy:
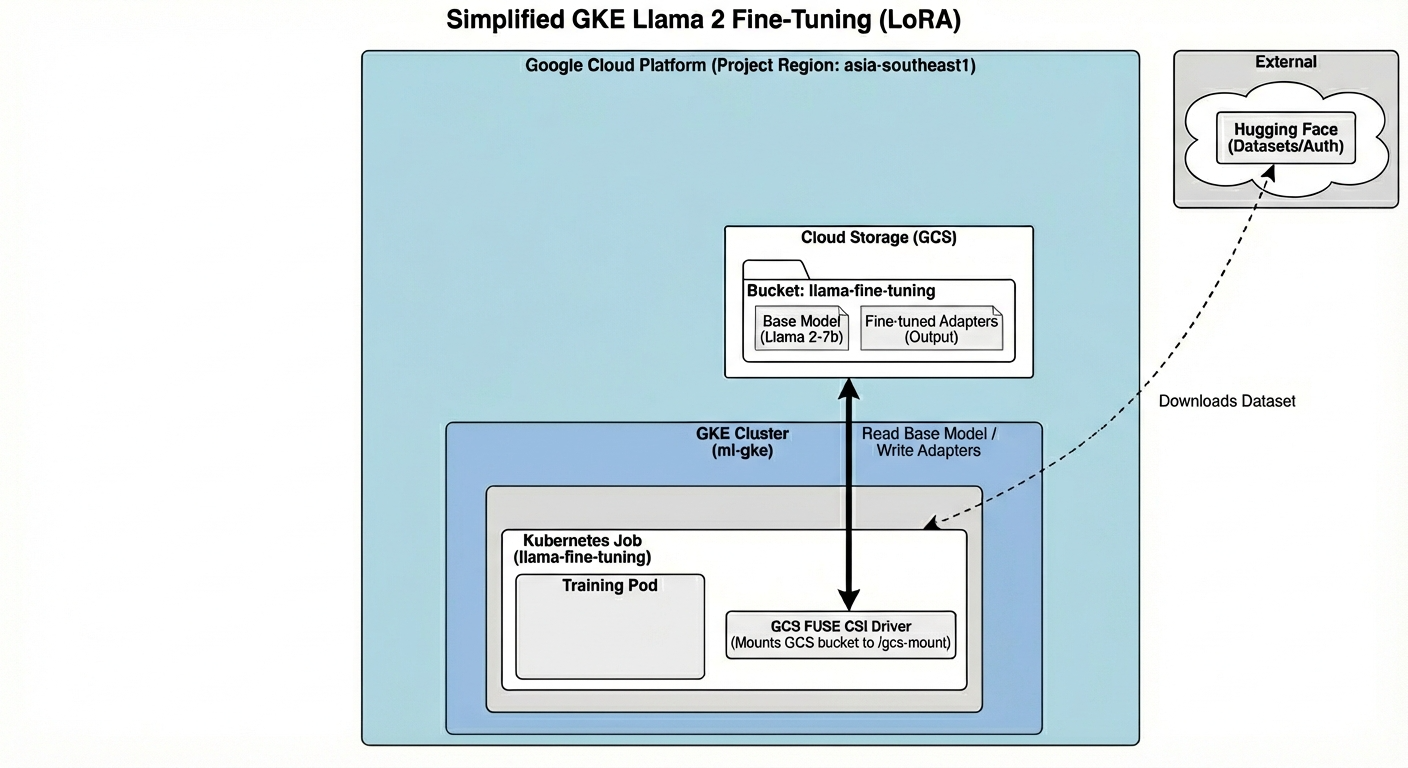
La arquitectura incluye lo siguiente:
- Clúster de GKE: Administra nuestros recursos de procesamiento
- Grupo de nodos de GPU: 1 GPU L4 (Spot) para el entrenamiento
- Bucket de GCS: Almacena modelos y conjuntos de datos
- Workload Identity: Acceso seguro entre K8s y GCS
Qué aprenderás
- Aprovisiona y configura un clúster de GKE con funciones optimizadas para cargas de trabajo de AA.
- Implementa acceso seguro y sin claves desde GKE a otros servicios de Google Cloud con Workload Identity.
- Compila una canalización de entrenamiento alojada en contenedores con Docker.
- Ajusta un modelo de código abierto de manera eficiente con el ajuste eficiente de parámetros (PEFT) con LoRA.
2. Configura el proyecto
Cuenta de Google
Si aún no tienes una Cuenta de Google personal, debes crear una.
Usa una cuenta personal en lugar de una cuenta de trabajo o institución educativa.
Accede a la consola de Google Cloud
Accede a la consola de Google Cloud con una Cuenta de Google personal.
Crear un proyecto (opcional)
Si no tienes un proyecto actual que quieras usar para este lab, crea uno nuevo aquí.
3. Abre el editor de Cloud Shell
- Haz clic en este vínculo para navegar directamente al editor de Cloud Shell.
- Si se te solicita autorización en algún momento, haz clic en Autorizar para continuar.
- Si la terminal no aparece en la parte inferior de la pantalla, ábrela:
- Haz clic en Ver.
- Haz clic en Terminal.
- En la terminal, configura tu proyecto con este comando:
gcloud config set project [PROJECT_ID]- Ejemplo:
gcloud config set project lab-project-id-example - Si no recuerdas el ID de tu proyecto, puedes enumerar todos tus IDs de proyecto con el siguiente comando:
gcloud projects list
- Ejemplo:
- Deberías ver el siguiente mensaje:
Updated property [core/project].
4. Habilita las APIs
Para usar GKE y otros servicios, debes habilitar las APIs necesarias en tu proyecto de Google Cloud.
- En la terminal, habilita las APIs:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
Presentamos las APIs
- La API de Google Kubernetes Engine (
container.googleapis.com) te permite crear y administrar el clúster de GKE que ejecuta tu aplicación. - La API de Artifact Registry (
artifactregistry.googleapis.com) proporciona un repositorio privado y seguro para almacenar tus imágenes de contenedor. - El comando
gcloud builds submitusa la API de Cloud Build (cloudbuild.googleapis.com) para compilar tu imagen de contenedor en la nube. - La API de IAM (
iam.googleapis.com) te permite administrar el control de acceso y la identidad de tus recursos de Google Cloud. - La API de Compute Engine (
compute.googleapis.com) proporciona máquinas virtuales seguras y personalizables que se ejecutan en la infraestructura de Google. - La API de IAM Service Account Credentials (
iamcredentials.googleapis.com) permite crear credenciales de corta duración para las cuentas de servicio. - La API de Cloud Storage (
storage.googleapis.com) te permite almacenar y recuperar datos en la nube, y aquí se usa para el almacenamiento de modelos y conjuntos de datos.
5. Configurar el entorno del proyecto
Crea un directorio de trabajo
- En la terminal, crea un directorio para tu proyecto y navega a él.
mkdir llama-finetuning cd llama-finetuning
Configura variables de entorno
- En la terminal, crea un archivo llamado
env.shpara almacenar tus variables de entorno. Esto garantiza que puedas volver a cargarlas fácilmente si se desconecta tu sesión.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - Obtén el archivo para cargar las variables en tu sesión actual:
source env.sh
6. Aprovisiona el clúster de GKE
- En la terminal, crea el clúster de GKE con un grupo de nodos predeterminado. El proceso tardará unos 5 minutos.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - A continuación, agrega un grupo de nodos de GPU al clúster. Este grupo de nodos se usará para entrenar el modelo.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - Por último, obtén las credenciales para el clúster nuevo y verifica que puedas conectarte a él.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Configura el acceso a Hugging Face
Con tu infraestructura lista, ahora debes proporcionar a tu proyecto las credenciales necesarias para acceder a tu modelo y a tus datos. En esta tarea, primero obtendrás un token de Hugging Face.
Cómo obtener un token de Hugging Face
- Si no tienes una cuenta de Hugging Face, ve a huggingface.co/join en una pestaña nueva del navegador y completa el proceso de registro.
- Una vez que te hayas registrado y hayas accedido, navega a huggingface.co/meta-llama/Llama-2-7b-hf.
- Lee las condiciones de la licencia y haz clic en el botón para aceptarlas.
- Navega a la página de tokens de acceso de Hugging Face en huggingface.co/settings/tokens.
- Haz clic en Token nuevo.
- En Rol, selecciona Lectura.
- En Nombre, ingresa un nombre descriptivo (p.ej., finetuning-lab).
- Haz clic en Crear un token.
- Copia el token generado al portapapeles. La necesitarás en el próximo paso.
Actualiza las variables de entorno
Ahora, agreguemos tu token de Hugging Face y un nombre para tu bucket de GCS al archivo env.sh. Reemplaza [your-hf-token] por el token que acabas de copiar.
- En la terminal, agrega las variables nuevas a
env.shy vuelve a cargarlas:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. Configura Workload Identity
A continuación, configurarás Workload Identity, que es la forma recomendada de permitir que las aplicaciones que se ejecutan en GKE accedan a los servicios de Google Cloud sin necesidad de administrar claves de cuentas de servicio estáticas. Puedes obtener más información en la documentación de Workload Identity.
- Primero, crea una cuenta de servicio de Google (GSA). En la terminal, ejecuta lo siguiente:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - A continuación, crea el bucket de GCS y otorga a la GSA permisos para acceder a él:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - Ahora, crea una cuenta de servicio de Kubernetes (KSA):
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - Por último, crea la vinculación de política de IAM entre la GSA y la KSA:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. Prepara el modelo base
En las canalizaciones de AA de producción, los modelos grandes, como Llama 2 (alrededor de 13 GB), suelen prepararse previamente en Cloud Storage en lugar de descargarse durante el entrenamiento. Este enfoque proporciona una mejor confiabilidad, un acceso más rápido y evita problemas de red. Google Cloud proporciona versiones descargadas previamente de modelos populares en buckets públicos de GCS, que usarás para este lab.
- Primero, verifiquemos que puedes acceder al modelo Llama 2 proporcionado por Google:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - Copia el modelo de Llama 2 de este bucket público al bucket de tu propio proyecto con el comando
gcloud storage. Esta transferencia usa la red interna de alta velocidad de Google y solo debería tardar uno o dos minutos.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - Para verificar que los archivos del modelo se copiaron correctamente, enumera el contenido de tu bucket.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. Prepara el código de entrenamiento
Ahora compilarás la aplicación alojada en contenedores que ajusta el modelo. Esta tarea usa LoRA (adaptación de bajo rango), una técnica de ajuste eficiente de parámetros (PEFT) que reduce drásticamente los requisitos de memoria, ya que solo entrena pequeñas capas de "adaptador" en lugar de todo el modelo.
Ahora, crea las secuencias de comandos de Python para la canalización de entrenamiento.
- En la terminal, ejecuta el siguiente comando para abrir el archivo
train.py:cloudshell edit train.py - Pega el siguiente código en el archivo
train.py:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. Comprende el código de entrenamiento
La secuencia de comandos train.py organiza el proceso de ajuste. Desglosemos sus componentes clave.
Configuración
La secuencia de comandos usa LoraConfig para definir la configuración de Low-Rank Adaptation. LoRA reduce significativamente la cantidad de parámetros entrenables, lo que te permite ajustar modelos grandes en GPU más pequeñas.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
Prepara el conjunto de datos
La función prepare_dataset carga el conjunto de datos "American Stories" y lo procesa en fragmentos tokenizados. Usa un SimpleTextDataset personalizado para controlar los tensores de entrada de manera eficiente.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
Tren
La función train_model configura Trainer con argumentos específicos optimizados para esta carga de trabajo. Entre los parámetros clave, se incluyen los siguientes:
gradient_accumulation_steps: Ayuda a simular un tamaño de lote más grande sin aumentar el uso de memoria.fp16=True: Usa el entrenamiento de precisión mixto para reducir la memoria y aumentar la velocidad.gradient_checkpointing=True: Ahorra memoria volviendo a calcular las activaciones durante la retropropagación en lugar de almacenarlas.optim="adamw_torch": Usa la implementación estándar del optimizador AdamW de PyTorch.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
Inferencia
La función run_inference realiza una prueba rápida del modelo ajustado con una instrucción de muestra. Garantiza que el modelo esté en modo de evaluación y genera texto para verificar que los adaptadores funcionen correctamente.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. Organiza la aplicación en contenedores
Ahora, compila la imagen del contenedor de entrenamiento con Docker y envíala a Google Artifact Registry.
- En la terminal, ejecuta el siguiente comando para abrir el archivo
Dockerfile:cloudshell edit Dockerfile - Pega el siguiente código en el archivo
Dockerfile:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
Compila y envía el contenedor
- Crea el repositorio de Artifact Registry:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Compila y envía la imagen con Cloud Build:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. Implementa el trabajo de ajuste
- Crea el manifiesto del trabajo de Kubernetes para iniciar el trabajo de ajuste. En la terminal, ejecuta lo siguiente:
cloudshell edit training_job.yaml - Pega el siguiente código en el archivo
training_job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- Por último, aplica el manifiesto de trabajo de Kubernetes para iniciar el trabajo de ajuste en tu clúster de GKE.
envsubst < training_job.yaml | kubectl apply -f -
14. Supervisa el trabajo de entrenamiento
Puedes supervisar el progreso de tu trabajo de entrenamiento en la consola de Google Cloud.
- Ve a la página Kubernetes Engine > Cargas de trabajo.
Ver cargas de trabajo de GKE - Haz clic en el trabajo
llama-fine-tuningpara ver sus detalles. - La pestaña Detalles se muestra de forma predeterminada. Puedes ver las métricas de uso de GPU en la sección Recursos.
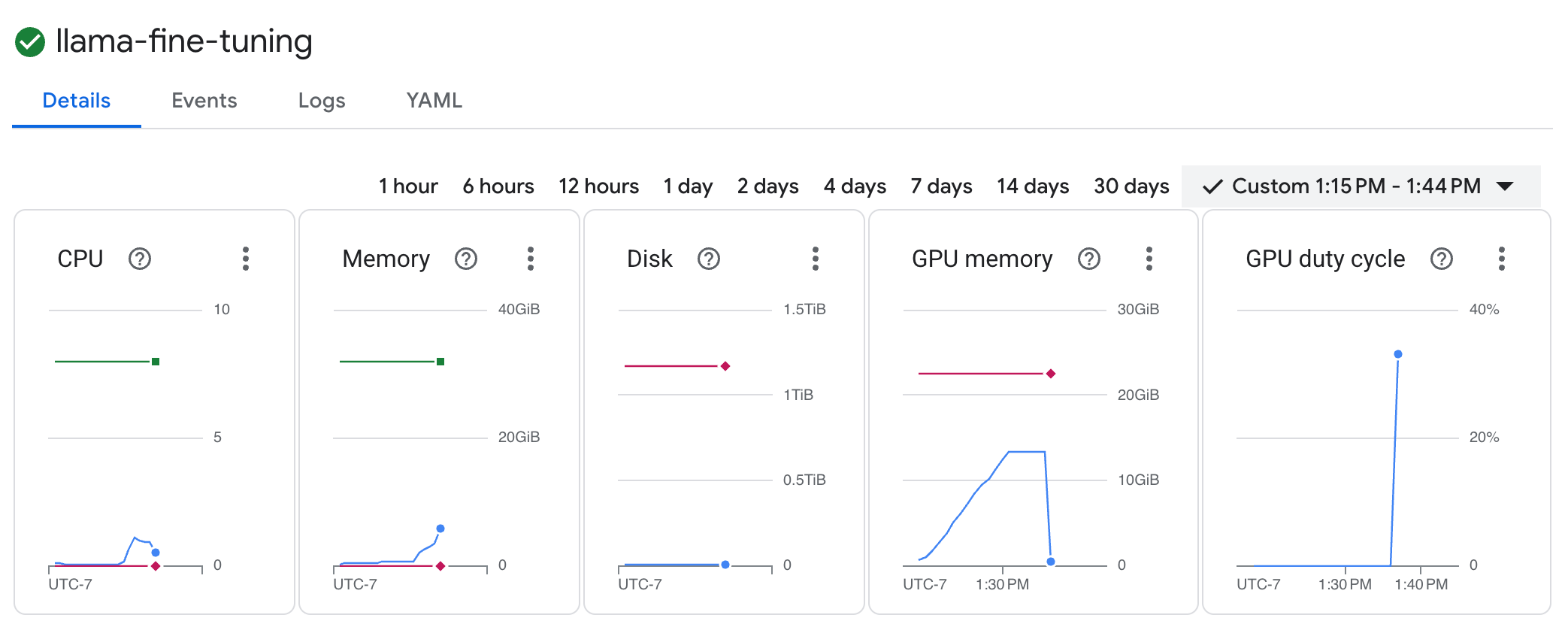
- Haz clic en la pestaña Registros para ver los registros de entrenamiento. Deberías ver el progreso del entrenamiento, incluida la pérdida y la tasa de aprendizaje.
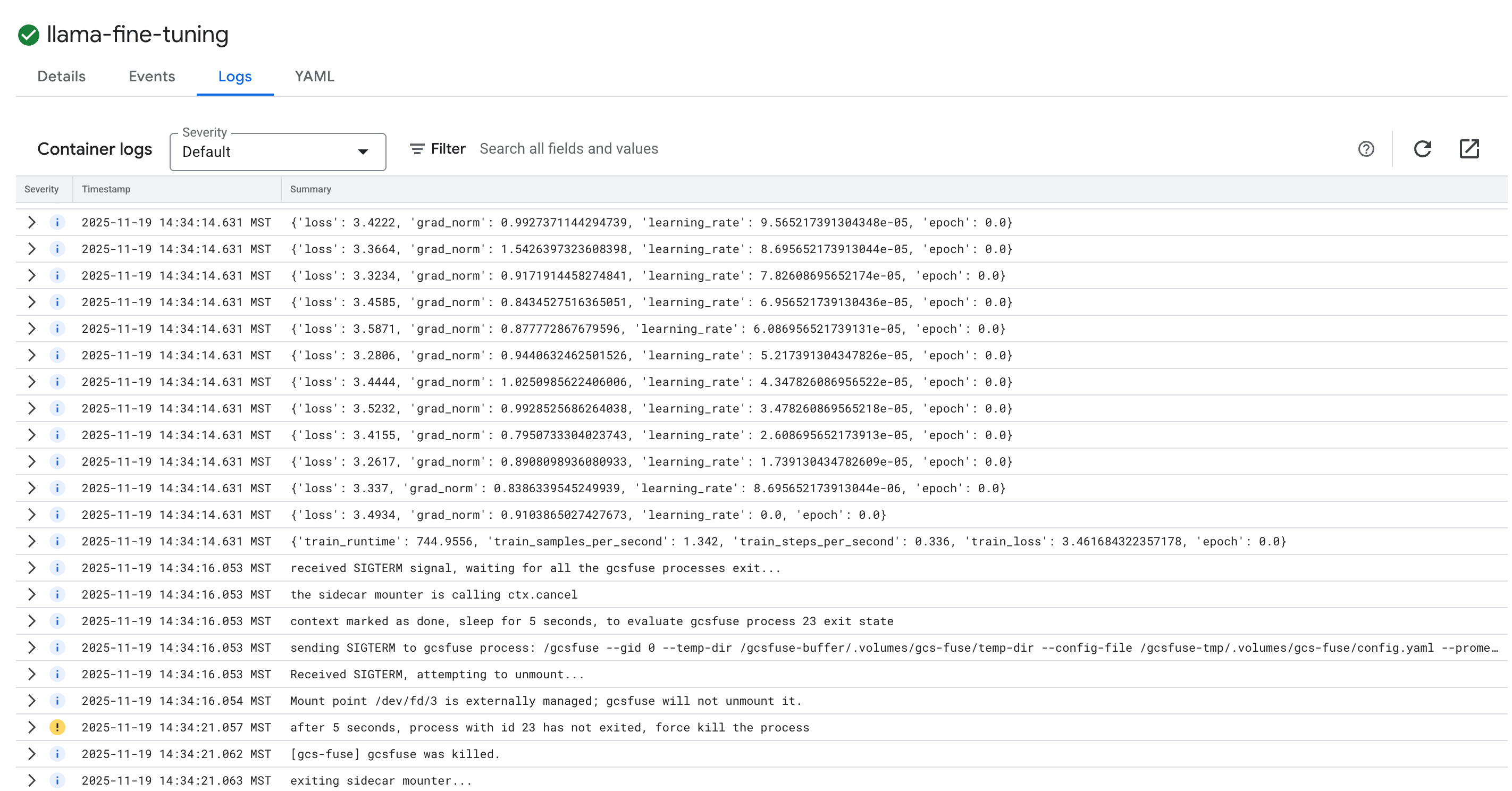
15. Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el clúster de GKE
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Borra el repositorio de Artifact Registry
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
Borra el bucket de GCS
gcloud storage rm -r gs://${BUCKET_NAME}
16. ¡Felicitaciones!
Ajustaste correctamente un LLM de código abierto en GKE.
Resumen
En este lab, aprenderás a hacer lo siguiente:
- Se aprovisionó un clúster de GKE con aceleración de GPU.
- Configuraste Workload Identity para acceder de forma segura a los servicios de Google Cloud.
- Se creó un contenedor para un trabajo de entrenamiento de PyTorch con Docker y Artifact Registry.
- Se implementó un trabajo de ajuste con LoRA para adaptar Llama 2 a un nuevo conjunto de datos.
¿Qué sigue?
- Obtén más información sobre la IA en GKE.
- Explora Vertex AI Model Garden.
- Únete a la comunidad de Google Cloud para conectarte con otros desarrolladores.
Ruta de aprendizaje de Google Cloud
Este lab forma parte de la ruta de aprendizaje IA lista para producción con Google Cloud. Explora el plan de estudios completo para cerrar la brecha entre el prototipo y la producción.
Comparte tu progreso con el hashtag #ProductionReadyAI.