
۱. مقدمه
در این آزمایشگاه، شما یاد میگیرید که یک خط لوله تنظیم دقیق کامل و در سطح تولید برای Llama 2، یک مدل زبان متنباز محبوب، با استفاده از موتور Google Kubernetes (GKE) بسازید. شما در مورد تصمیمات معماری، بدهبستانهای رایج و اجزایی که گردشهای کاری عملیات یادگیری ماشین (MLops) در دنیای واقعی را منعکس میکنند، خواهید آموخت.
شما یک کلاستر GKE تهیه خواهید کرد، یک خط لوله آموزشی کانتینر شده با استفاده از LoRA (سازگاری با رتبه پایین) ایجاد خواهید کرد و کار آموزشی خود را روی GKE اجرا خواهید کرد.
نمای کلی معماری
این چیزی است که امروز خواهیم ساخت:
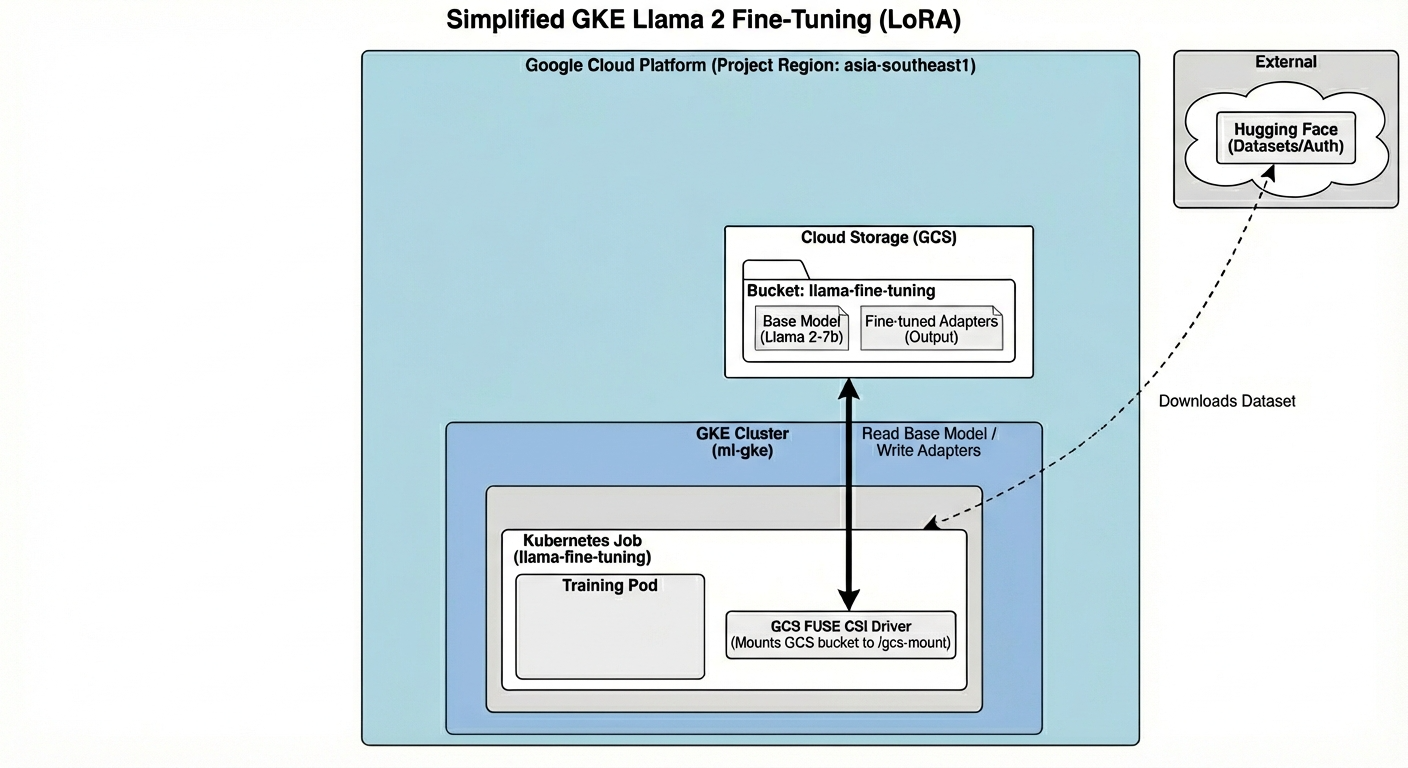
معماری شامل موارد زیر است:
- خوشه GKE : منابع محاسباتی ما را مدیریت میکند
- استخر گره GPU : 1x پردازنده گرافیکی L4 ( نقطهای ) برای آموزش
- GCS Bucket : مدلها و مجموعه دادهها را ذخیره میکند.
- هویت بار کاری : دسترسی امن بین K8s و GCS
آنچه یاد خواهید گرفت
- یک کلاستر GKE با ویژگیهای بهینهشده برای بارهای کاری یادگیری ماشینی تهیه و پیکربندی کنید.
- با استفاده از Workload Identity، دسترسی امن و بدون کلید از GKE به سایر سرویسهای Google Cloud را پیادهسازی کنید.
- با استفاده از داکر، یک خط لوله آموزشی کانتینر شده بسازید.
- با استفاده از تنظیم دقیق پارامتر-کارآمد (PEFT) با LoRA، یک مدل متنباز را به طور کارآمد تنظیم دقیق کنید.
۲. راهاندازی پروژه
حساب گوگل
اگر از قبل حساب گوگل شخصی ندارید، باید یک حساب گوگل ایجاد کنید .
به جای حساب کاری یا تحصیلی از حساب شخصی استفاده کنید .
ورود به کنسول ابری گوگل
با استفاده از یک حساب کاربری شخصی گوگل، وارد کنسول ابری گوگل شوید.
ایجاد پروژه (اختیاری)
اگر پروژه فعلی ندارید که بخواهید برای این آزمایشگاه استفاده کنید، اینجا یک پروژه جدید ایجاد کنید .
۳. ویرایشگر Cloud Shell را باز کنید
- برای دسترسی مستقیم به ویرایشگر Cloud Shell ، روی این لینک کلیک کنید.
- اگر امروز در هر مرحلهای از شما خواسته شد که مجوز دهید، برای ادامه روی تأیید کلیک کنید.
- اگر ترمینال در پایین صفحه نمایش داده نشد، آن را باز کنید:
- روی مشاهده کلیک کنید
- روی ترمینال کلیک کنید
- در ترمینال، پروژه خود را با این دستور تنظیم کنید:
gcloud config set project [PROJECT_ID]- مثال:
gcloud config set project lab-project-id-example - اگر نمیتوانید شناسه پروژه خود را به خاطر بیاورید، میتوانید تمام شناسههای پروژه خود را با استفاده از دستور زیر فهرست کنید:
gcloud projects list
- مثال:
- شما باید این پیام را ببینید:
Updated property [core/project].
۴. فعال کردن APIها
برای استفاده از GKE و سایر سرویسها، باید APIهای لازم را در پروژه Google Cloud خود فعال کنید.
- در ترمینال، APIها را فعال کنید:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
معرفی API ها
- رابط برنامهنویسی کاربردی موتور کوبرنتیز گوگل (
container.googleapis.com) به شما امکان میدهد تا خوشه GKE را که برنامه شما را اجرا میکند، ایجاد و مدیریت کنید. - رابط برنامهنویسی کاربردی (API) رجیستری مصنوعات (
artifactregistry.googleapis.com) یک مخزن امن و خصوصی برای ذخیره تصاویر کانتینر شما فراهم میکند. - رابط برنامهنویسی کاربردی ساخت ابری (
cloudbuild.googleapis.com) توسط دستورgcloud builds submitبرای ساخت تصویر کانتینر شما در فضای ابری استفاده میشود. - رابط برنامهنویسی کاربردی IAM (
iam.googleapis.com) به شما امکان میدهد کنترل دسترسی و هویت را برای منابع Google Cloud خود مدیریت کنید. - رابط برنامهنویسی کاربردی موتور محاسبات (compute Engine API ) (
compute.googleapis.com) ماشینهای مجازی امن و قابل تنظیمی را فراهم میکند که روی زیرساخت گوگل اجرا میشوند. - API مربوط به اعتبارنامههای حساب کاربری سرویس IAM (
iamcredentials.googleapis.com) امکان ایجاد اعتبارنامههای کوتاهمدت برای حسابهای کاربری سرویس را فراهم میکند. - رابط برنامهنویسی کاربردی ذخیرهسازی ابری (
storage.googleapis.com) به شما امکان میدهد دادهها را در فضای ابری ذخیره و بازیابی کنید، که در اینجا برای ذخیرهسازی مدل و مجموعه دادهها استفاده میشود.
۵. محیط پروژه را تنظیم کنید
ایجاد یک دایرکتوری کاری
- در ترمینال ، یک دایرکتوری برای پروژه خود ایجاد کنید و به داخل آن بروید.
mkdir llama-finetuning cd llama-finetuning
تنظیم متغیرهای محیطی
- در ترمینال ، فایلی به نام
env.shایجاد کنید تا متغیرهای محیطی خود را در آن ذخیره کنید. این کار تضمین میکند که در صورت قطع شدن ارتباط، بتوانید به راحتی آنها را دوباره بارگذاری کنید.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - فایل را برای بارگذاری متغیرها در جلسه فعلی خود، منبعیابی کنید:
source env.sh
۶. تأمین خوشه GKE
- در ترمینال ، کلاستر GKE را با یک مجموعه گره پیشفرض ایجاد کنید. این کار حدود ۵ دقیقه طول خواهد کشید.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - در مرحله بعد، یک مجموعه گره GPU به کلاستر اضافه کنید. این مجموعه گره برای آموزش مدل استفاده خواهد شد.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - در نهایت، اعتبارنامههای مربوط به کلاستر جدید خود را دریافت کنید و تأیید کنید که میتوانید به آن متصل شوید.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
۷. پیکربندی دسترسی آغوشی چهره
با آماده شدن زیرساخت، اکنون باید اعتبارنامههای لازم را برای دسترسی به مدل و دادههای خود در اختیار پروژه قرار دهید. در این کار، ابتدا یک توکن چهره در آغوش گرفته (Hugging Face) دریافت خواهید کرد.
یک توکن چهره در آغوش بگیرید
- اگر حساب کاربری Hugging Face ندارید، در یک تب جدید مرورگر به huggingface.co/join بروید و مراحل ثبت نام را تکمیل کنید.
- پس از ثبت نام و ورود به سیستم، به huggingface.co/meta-llama/Llama-2-7b-hf بروید.
- شرایط مجوز را بخوانید و برای پذیرش آنها روی دکمه کلیک کنید.
- به صفحه توکنهای دسترسی Hugging Face خود در huggingface.co/settings/tokens بروید.
- روی توکن جدید کلیک کنید.
- برای نقش ، «خواندن» را انتخاب کنید.
- برای Name ، یک نام توصیفی وارد کنید (مثلاً finetuning-lab).
- روی ایجاد یک توکن کلیک کنید.
- توکن تولید شده را در کلیپبورد خود کپی کنید. در مرحله بعدی به آن نیاز خواهید داشت.
بهروزرسانی متغیرهای محیطی
حالا، بیایید توکن Hugging Face و یک نام برای سطل GCS خود به فایل env.sh اضافه کنیم. [your-hf-token] را با توکنی که کپی کردهاید جایگزین کنید.
- در ترمینال ، متغیرهای جدید را به
env.shاضافه کنید و آنها را مجدداً بارگذاری کنید:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
۸. پیکربندی هویت بار کاری
در مرحله بعد، شما Workload Identity را تنظیم خواهید کرد، که روش پیشنهادی برای دسترسی برنامههای در حال اجرا روی GKE به سرویسهای Google Cloud بدون نیاز به مدیریت کلیدهای حساب کاربری سرویس استاتیک است. میتوانید اطلاعات بیشتر را در مستندات Workload Identity بیابید.
- ابتدا، یک حساب کاربری سرویس گوگل (GSA) ایجاد کنید. در ترمینال ، دستور زیر را اجرا کنید:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - سپس، GCS bucket را ایجاد کنید و مجوزهای دسترسی به GSA را به آن اعطا کنید:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - اکنون، یک حساب کاربری سرویس Kubernetes (KSA) ایجاد کنید:
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - در نهایت، اتصال سیاست IAM بین GSA و KSA را ایجاد کنید:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
۹. مدل پایه را مرحلهبندی کنید
در خطوط تولید یادگیری ماشین، مدلهای بزرگی مانند Llama 2 (حدود ۱۳ گیگابایت) معمولاً به جای دانلود در طول آموزش، در فضای ذخیرهسازی ابری از قبل آمادهسازی میشوند. این رویکرد قابلیت اطمینان بهتر، دسترسی سریعتر و جلوگیری از مشکلات شبکه را فراهم میکند. Google Cloud نسخههای از پیش دانلود شده از مدلهای محبوب را در سطلهای عمومی GCS ارائه میدهد که شما برای این آزمایش از آنها استفاده خواهید کرد.
- ابتدا، بیایید تأیید کنیم که میتوانید به مدل Llama 2 ارائه شده توسط گوگل دسترسی داشته باشید:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - مدل Llama 2 را با استفاده از دستور
gcloud storageاز این باکت عمومی به باکت پروژه خودتان کپی کنید. این انتقال از شبکه داخلی پرسرعت گوگل استفاده میکند و فقط یک یا دو دقیقه طول میکشد.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - با فهرست کردن محتویات سطل خود، تأیید کنید که فایلهای مدل به درستی کپی شدهاند.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
۱۰. کد آموزشی را آماده کنید
اکنون شما برنامه کانتینر شدهای را خواهید ساخت که مدل را به طور دقیق تنظیم میکند. این کار از LoRA (تطبیق با رتبه پایین)، یک تکنیک تنظیم دقیق پارامتر-کارآمد (PEFT) استفاده میکند که با آموزش تنها لایههای کوچک "آداپتور" به جای کل مدل، نیاز به حافظه را به طور چشمگیری کاهش میدهد.
اکنون، اسکریپتهای پایتون را برای خط لوله آموزشی ایجاد کنید.
- در ترمینال ، دستور زیر را برای باز کردن فایل
train.pyاجرا کنید:cloudshell edit train.py - کد زیر را در فایل
train.pyقرار دهید:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
۱۱. کد آموزشی را درک کنید
اسکریپت train.py فرآیند تنظیم دقیق را هماهنگ میکند. بیایید اجزای کلیدی آن را بررسی کنیم.
پیکربندی
این اسکریپت از LoraConfig برای تعریف تنظیمات سازگاری با رتبه پایین استفاده میکند. LoRA تعداد پارامترهای قابل آموزش را به میزان قابل توجهی کاهش میدهد و به شما امکان میدهد مدلهای بزرگ را روی پردازندههای گرافیکی کوچکتر به دقت تنظیم کنید.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
آمادهسازی مجموعه دادهها
تابع prepare_dataset مجموعه داده "American Stories" را بارگذاری کرده و آن را به تکههای توکنشده پردازش میکند. این تابع از یک SimpleTextDataset سفارشی برای مدیریت کارآمد تانسورهای ورودی استفاده میکند.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
قطار
تابع train_model Trainer با آرگومانهای خاصی که برای این حجم کار بهینه شدهاند، تنظیم میکند. پارامترهای کلیدی عبارتند از:
-
gradient_accumulation_steps: به شبیهسازی اندازه دسته بزرگتر بدون افزایش استفاده از حافظه کمک میکند. -
fp16=True: از آموزش دقیق ترکیبی برای کاهش حافظه و افزایش سرعت استفاده میکند. -
gradient_checkpointing=True: با محاسبه مجدد فعالسازیها در طول مسیر رو به عقب به جای ذخیره آنها، در حافظه صرفهجویی میکند. -
optim="adamw_torch": از پیادهسازی استاندارد بهینهساز AdamW از PyTorch استفاده میکند.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
استنتاج
تابع run_inference با استفاده از یک نمونه اعلان، یک آزمایش سریع از مدل تنظیمشده انجام میدهد. این تابع تضمین میکند که مدل در حالت ارزیابی است و متنی را برای تأیید صحت عملکرد آداپتورها تولید میکند.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
۱۲. اپلیکیشن را کانتینرایز کنید
اکنون، تصویر کانتینر آموزشی را با استفاده از Docker بسازید و آن را به Google Artifact Registry ارسال کنید.
- در ترمینال ، دستور زیر را برای باز کردن فایل
Dockerfileاجرا کنید:cloudshell edit Dockerfile - کد زیر را در فایل
Dockerfileقرار دهید:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
کانتینر را بسازید و فشار دهید
- مخزن رجیستری مصنوعات را ایجاد کنید:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - با استفاده از Cloud Build، ایمیج را بسازید و ارسال کنید:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
۱۳. کار تنظیم دقیق را آغاز کنید
- برای شروع کار تنظیم دقیق، فایل مانیفست کار Kubernetes را ایجاد کنید. در ترمینال ، دستور زیر را اجرا کنید:
cloudshell edit training_job.yaml - کد زیر را در فایل
training_job.yamlقرار دهید:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- در نهایت، برای شروع کار تنظیم دقیق روی کلاستر GKE خود، مانیفست کار Kubernetes را اعمال کنید.
envsubst < training_job.yaml | kubectl apply -f -
۱۴. بر کار آموزشی نظارت کنید
شما میتوانید پیشرفت کار آموزشی خود را در کنسول ابری گوگل (Google Cloud Console) پیگیری کنید.
- به صفحه Kubernetes Engine > Workloads بروید.
مشاهده بارهای کاری GKE - برای مشاهده جزئیات کار
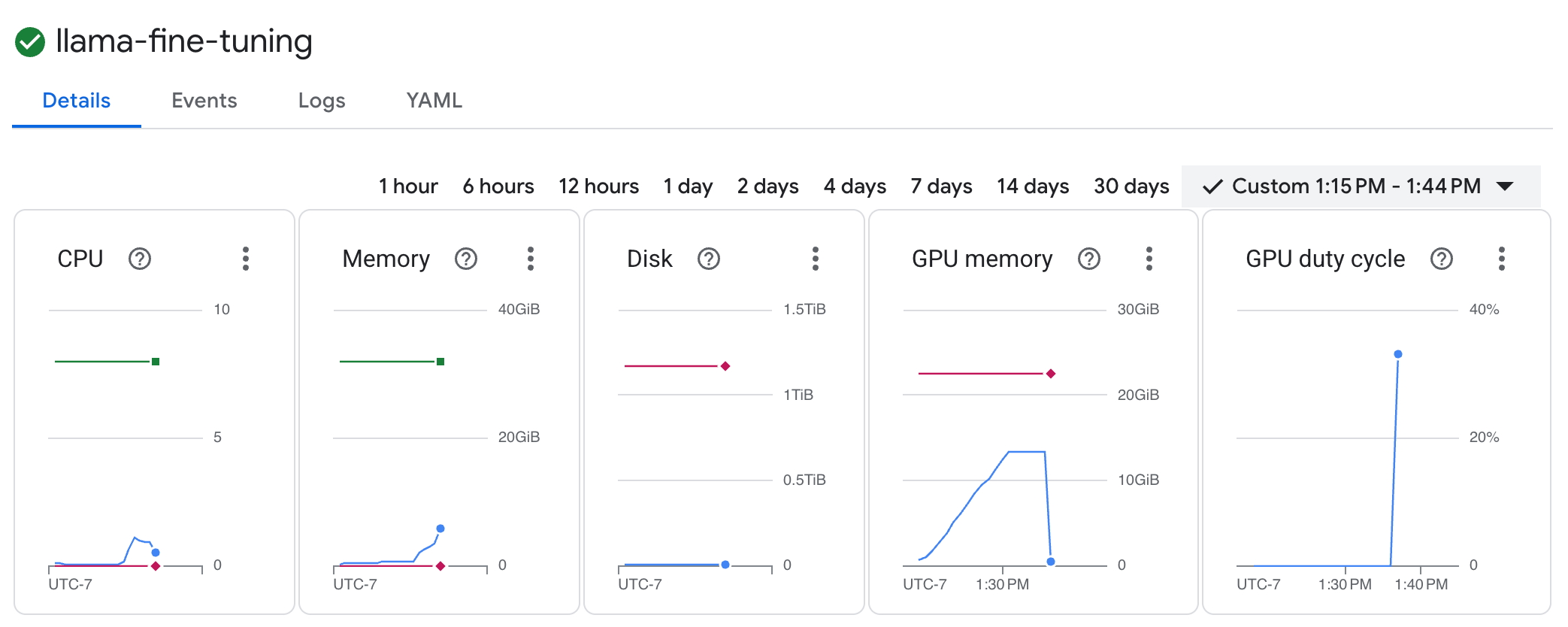
llama-fine-tuningروی آن کلیک کنید. - تب جزئیات (Details) به طور پیشفرض نمایش داده میشود. میتوانید معیارهای استفاده از پردازنده گرافیکی (GPU) را در بخش منابع (Resources) مشاهده کنید.
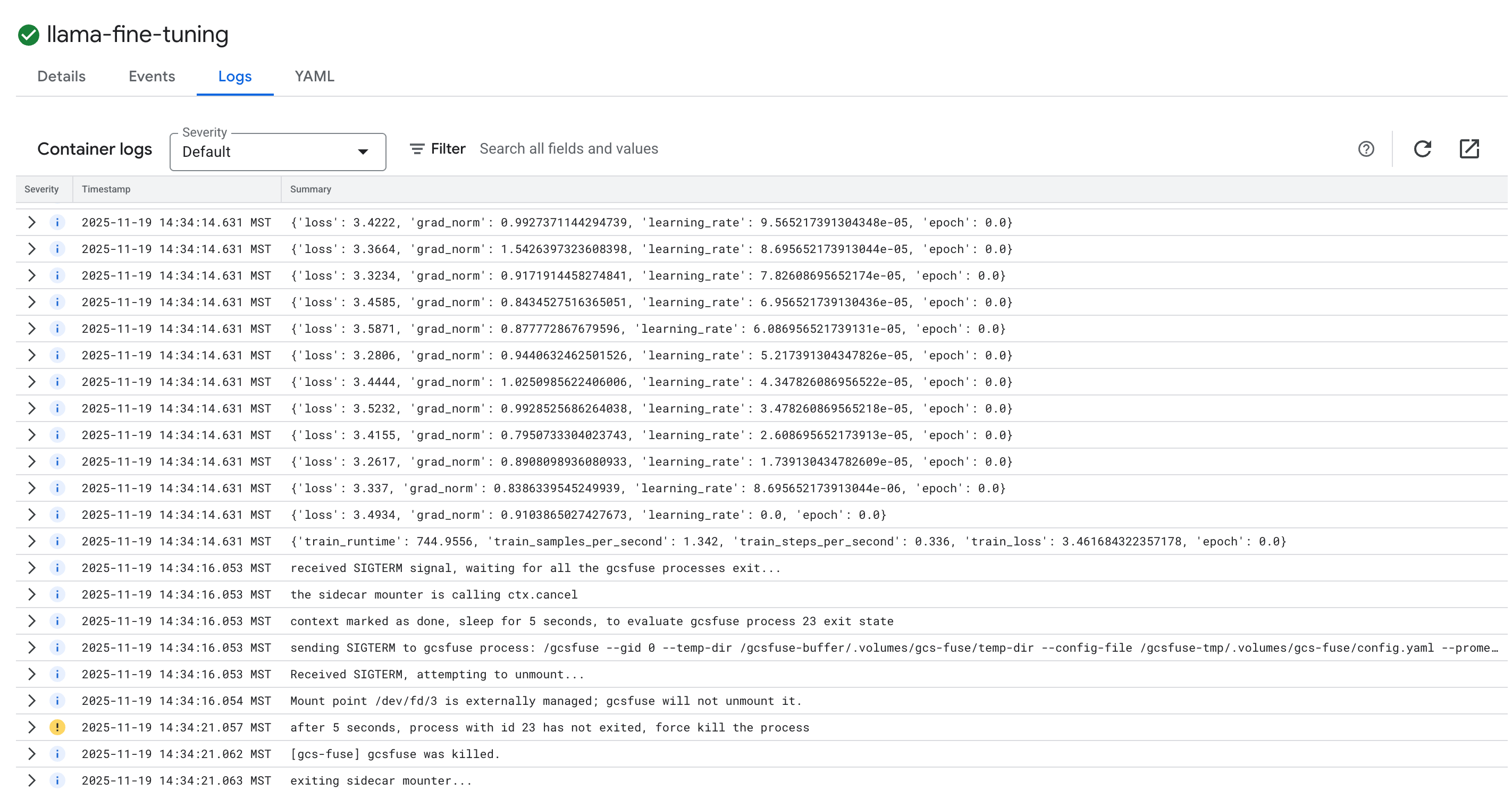
- برای مشاهده گزارشهای آموزشی، روی برگه « گزارشها» کلیک کنید. شما باید پیشرفت آموزش، از جمله میزان از دست دادن داده و نرخ یادگیری را ببینید.
۱۵. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب گوگل کلود خود برای منابع استفاده شده در این آموزش، یا پروژهای که شامل منابع است را حذف کنید، یا پروژه را نگه دارید و منابع تکی را حذف کنید.
خوشه GKE را حذف کنید
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
مخزن رجیستری Artifact را حذف کنید
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
سطل GCS را حذف کنید
gcloud storage rm -r gs://${BUCKET_NAME}
۱۶. تبریک میگویم!
شما با موفقیت یک LLM متنباز را روی GKE تنظیم کردید!
خلاصه
در این آزمایشگاه، شما:
- یک کلاستر GKE با شتابدهندهی GPU فراهم شد.
- پیکربندی هویت حجم کار برای دسترسی ایمن به سرویسهای ابری گوگل.
- یک پروژه آموزشی PyTorch را با استفاده از Docker و Artifact Registry کانتینرایز کردم.
- یک کار تنظیم دقیق با استفاده از LoRA برای تطبیق Llama 2 با یک مجموعه داده جدید انجام شد.
قدم بعدی چیست؟
- درباره هوش مصنوعی در GKE بیشتر بدانید.
- باغ مدل هوش مصنوعی ورتکس را کاوش کنید.
- برای ارتباط با دیگر توسعهدهندگان، به انجمن گوگل کلود بپیوندید.
مسیر یادگیری فضای ابری گوگل
این آزمایشگاه بخشی از مسیر یادگیری هوش مصنوعی آماده برای تولید با Google Cloud است. برای پر کردن شکاف از نمونه اولیه تا تولید، برنامه درسی کامل را بررسی کنید .
پیشرفت خود را با هشتگ #ProductionReadyAI به اشتراک بگذارید.