
1. Introduction
Dans cet atelier, vous allez apprendre à créer un pipeline d'affinage complet et adapté à la production pour Llama 2, un modèle de langage open source populaire, à l'aide de Google Kubernetes Engine (GKE). Vous découvrirez les décisions architecturales, les compromis courants et les composants qui reflètent les workflows d'opérations de machine learning (MLOps) réels.
Vous provisionnerez un cluster GKE, créerez un pipeline d'entraînement conteneurisé à l'aide de LoRA (Low-Rank Adaptation) et exécuterez votre tâche d'entraînement sur GKE.
Présentation de l'architecture
Voici ce que nous allons créer aujourd'hui :
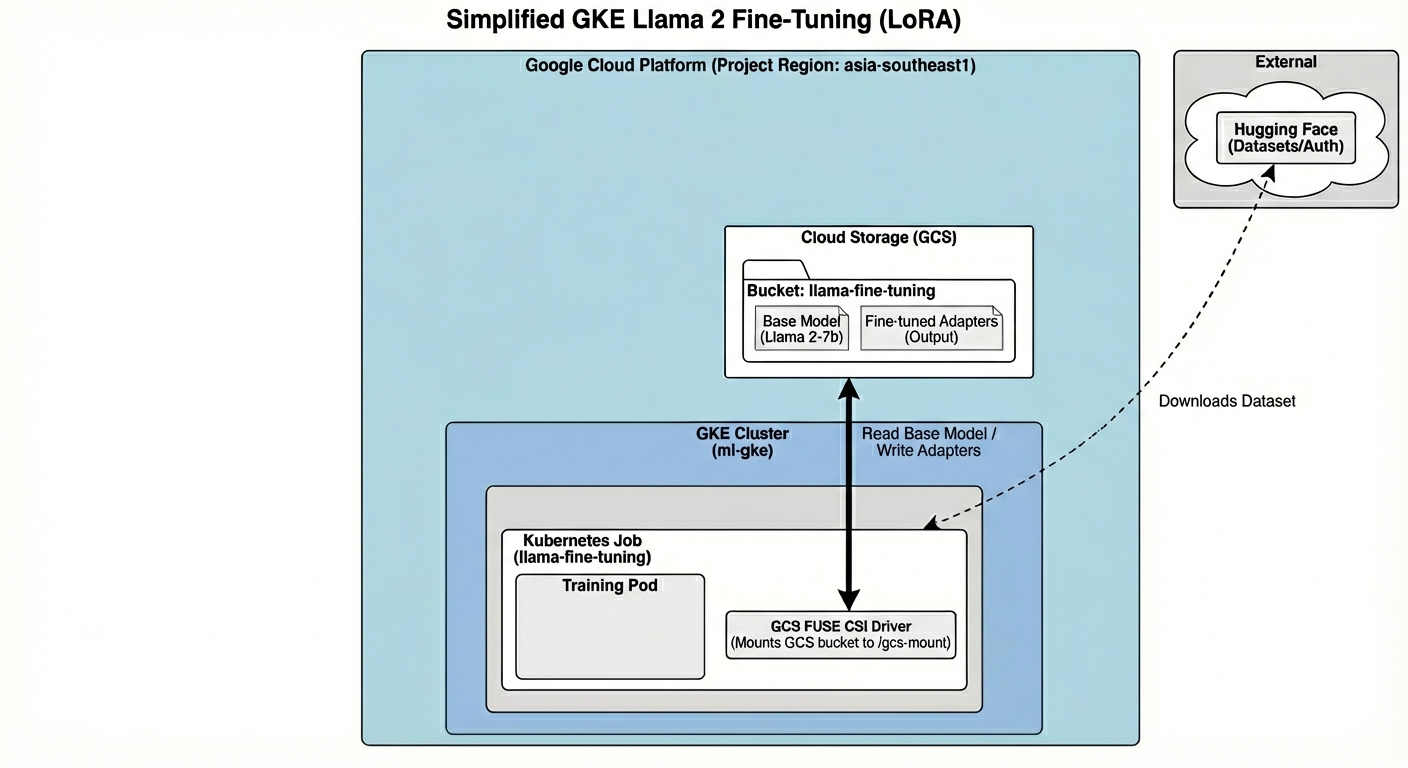
L'architecture comprend les éléments suivants :
- Cluster GKE : gère nos ressources de calcul
- Pool de nœuds GPU : 1 GPU L4 (Spot) pour l'entraînement
- Bucket GCS : stocke les modèles et les ensembles de données
- Workload Identity : accès sécurisé entre K8s et GCS
Points abordés
- Provisionnez et configurez un cluster GKE avec des fonctionnalités optimisées pour les charges de travail de ML.
- Implémentez un accès sécurisé et sans clé de GKE à d'autres services Google Cloud à l'aide de Workload Identity.
- Créez un pipeline d'entraînement conteneurisé à l'aide de Docker.
- Ajustez efficacement un modèle Open Source à l'aide de l'optimisation du réglage des paramètres (PEFT) avec LoRA.
2. Configuration du projet
Compte Google
Si vous ne possédez pas encore de compte Google personnel, vous devez en créer un.
Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire.
Se connecter à la console Google Cloud
Connectez-vous à la console Google Cloud à l'aide d'un compte Google personnel.
Créer un projet (facultatif)
Si vous n'avez pas de projet que vous souhaitez utiliser pour cet atelier, créez-en un.
3. Ouvrir l'éditeur Cloud Shell
- Cliquez sur ce lien pour accéder directement à l'éditeur Cloud Shell.
- Si vous êtes invité à autoriser l'accès à un moment donné aujourd'hui, cliquez sur Autoriser pour continuer.
- Si le terminal ne s'affiche pas en bas de l'écran, ouvrez-le :
- Cliquez sur Afficher.
- Cliquez sur Terminal
 .
.
- Dans le terminal, définissez votre projet à l'aide de la commande suivante :
gcloud config set project [PROJECT_ID]- Exemple :
gcloud config set project lab-project-id-example - Si vous ne vous souvenez pas de l'ID de votre projet, vous pouvez lister tous vos ID de projet avec la commande suivante :
gcloud projects list
- Exemple :
- Le message suivant doit s'afficher :
Updated property [core/project].
4. Activer les API
Pour utiliser GKE et d'autres services, vous devez activer les API nécessaires dans votre projet Google Cloud.
- Dans le terminal, activez les API :
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
Présentation des API
- L'API Google Kubernetes Engine (
container.googleapis.com) vous permet de créer et de gérer le cluster GKE qui exécute votre application. - L'API Artifact Registry (
artifactregistry.googleapis.com) fournit un dépôt sécurisé et privé pour stocker vos images de conteneurs. - L'API Cloud Build (
cloudbuild.googleapis.com) est utilisée par la commandegcloud builds submitpour créer votre image de conteneur dans le cloud. - L'API IAM (
iam.googleapis.com) vous permet de gérer le contrôle des accès et l'identité de vos ressources Google Cloud. - L'API Compute Engine (
compute.googleapis.com) fournit des machines virtuelles sécurisées et personnalisables qui s'exécutent sur l'infrastructure de Google. - L'API IAM Service Account Credentials (
iamcredentials.googleapis.com) permet de créer des identifiants de courte durée pour les comptes de service. - L'API Cloud Storage (
storage.googleapis.com) vous permet de stocker et de récupérer des données dans le cloud. Elle est utilisée ici pour le stockage des modèles et des ensembles de données.
5. Configurer l'environnement du projet
Créer un répertoire de travail
- Dans le terminal, créez un répertoire pour votre projet et accédez-y.
mkdir llama-finetuning cd llama-finetuning
Configurer des variables d'environnement
- Dans le terminal, créez un fichier nommé
env.shpour stocker vos variables d'environnement. Vous pourrez ainsi les recharger facilement si votre session est déconnectée.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - Importez le fichier pour charger les variables dans votre session actuelle :
source env.sh
6. Provisionner le cluster GKE
- Dans le terminal, créez le cluster GKE avec un pool de nœuds par défaut. Cela prendra environ cinq minutes.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - Ajoutez ensuite un pool de nœuds GPU au cluster. Ce pool de nœuds sera utilisé pour entraîner le modèle.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - Enfin, obtenez les identifiants de votre nouveau cluster et vérifiez que vous pouvez vous y connecter.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Configurer l'accès à Hugging Face
Maintenant que votre infrastructure est prête, vous devez fournir à votre projet les identifiants nécessaires pour accéder à votre modèle et à vos données. Dans cette tâche, vous allez d'abord obtenir un jeton Hugging Face.
Obtenir un jeton Hugging Face
- Si vous n'avez pas de compte Hugging Face, accédez à huggingface.co/join dans un nouvel onglet de navigateur et suivez la procédure d'inscription.
- Une fois inscrit et connecté, accédez à huggingface.co/meta-llama/Llama-2-7b-hf.
- Lisez les conditions de licence, puis cliquez sur le bouton pour les accepter.
- Accédez à la page des jetons d'accès Hugging Face à l'adresse huggingface.co/settings/tokens.
- Cliquez sur Nouveau jeton.
- Pour Rôle, sélectionnez Lecture.
- Dans le champ Name (Nom), saisissez un nom descriptif (par exemple, finetuning-lab).
- Cliquez sur Créer un jeton.
- Copiez le jeton dans votre presse-papiers. Vous en aurez besoin à l'étape suivante.
Mettre à jour les variables d'environnement
Ajoutons maintenant votre jeton Hugging Face et un nom pour votre bucket GCS à votre fichier env.sh. Remplacez [your-hf-token] par le jeton que vous venez de copier.
- Dans le terminal, ajoutez les nouvelles variables à
env.shet rechargez-les :cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. Configurer Workload Identity
Vous allez ensuite configurer Workload Identity, qui est la méthode recommandée pour permettre aux applications exécutées sur GKE d'accéder aux services Google Cloud sans avoir à gérer les clés de compte de service statiques. Pour en savoir plus, consultez la documentation Workload Identity.
- Commencez par créer un compte de service Google. Dans le terminal, exécutez la commande suivante :
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - Créez ensuite le bucket GCS et accordez au GSA les autorisations nécessaires pour y accéder :
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - Créez maintenant un compte de service Kubernetes (KSA) :
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - Enfin, créez la liaison de stratégie IAM entre le GSA et le KSA :
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. Préparer le modèle de base
Dans les pipelines de ML de production, les grands modèles tels que Llama 2 (~13 Go) sont généralement pré-organisés dans Cloud Storage plutôt que téléchargés lors de l'entraînement. Cette approche offre une meilleure fiabilité, un accès plus rapide et évite les problèmes de réseau. Google Cloud fournit des versions pré-téléchargées de modèles populaires dans des buckets GCS publics, que vous utiliserez pour cet atelier.
- Tout d'abord, vérifions que vous pouvez accéder au modèle Llama 2 fourni par Google :
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - Copiez le modèle Llama 2 de ce bucket public vers le bucket de votre propre projet à l'aide de la commande
gcloud storage. Ce transfert utilise le réseau interne à haut débit de Google et ne devrait prendre qu'une ou deux minutes.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - Vérifiez que les fichiers du modèle ont été correctement copiés en listant le contenu de votre bucket.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. Préparer le code d'entraînement
Vous allez maintenant créer l'application conteneurisée qui ajuste le modèle. Cette tâche utilise LoRA (Low-Rank Adaptation), une technique d'optimisation de l'affinage des paramètres (PEFT, Parameter-Efficient Fine-Tuning) qui réduit considérablement les besoins en mémoire en n'entraînant que de petites couches "d'adaptation" au lieu de l'ensemble du modèle.
Créez maintenant les scripts Python pour le pipeline d'entraînement.
- Dans le terminal, exécutez la commande suivante pour ouvrir le fichier
train.py:cloudshell edit train.py - Collez le code suivant dans le fichier
train.py:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. Comprendre le code d'entraînement
Le script train.py orchestre le processus de réglage fin. Examinons ses principaux composants.
Configuration
Le script utilise LoraConfig pour définir les paramètres d'adaptation de faible rang. LoRA réduit considérablement le nombre de paramètres entraînables, ce qui vous permet d'affiner de grands modèles sur des GPU plus petits.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
Préparer l'ensemble de données
La fonction prepare_dataset charge l'ensemble de données "American Stories" et le traite en blocs tokenisés. Il utilise un SimpleTextDataset personnalisé pour gérer efficacement les Tensors d'entrée.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
Train
La fonction train_model configure Trainer avec des arguments spécifiques optimisés pour cette charge de travail. Voici quelques-uns des principaux paramètres :
gradient_accumulation_steps: permet de simuler une taille de lot plus importante sans augmenter l'utilisation de la mémoire.fp16=True: utilise l'entraînement de précision mixte pour réduire la mémoire et augmenter la vitesse.gradient_checkpointing=True: économise de la mémoire en recalculant les activations lors de la rétropropagation au lieu de les stocker.optim="adamw_torch": utilise l'implémentation standard de l'optimiseur AdamW de PyTorch.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
Inférence
La fonction run_inference effectue un test rapide du modèle affiné à l'aide d'un exemple de requête. Il s'assure que le modèle est en mode évaluation et génère du texte pour vérifier que les adaptateurs fonctionnent correctement.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. Conteneuriser l'application
Créez maintenant l'image de conteneur d'entraînement à l'aide de Docker et transmettez-la à Google Artifact Registry.
- Dans le terminal, exécutez la commande suivante pour ouvrir le fichier
Dockerfile:cloudshell edit Dockerfile - Collez le code suivant dans le fichier
Dockerfile:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
Créer et transférer le conteneur
- Créez le dépôt Artifact Registry :
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Créez et transférez l'image à l'aide de Cloud Build :
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. Déployer le job d'affinage
- Créez le fichier manifeste du job Kubernetes pour démarrer le job d'affinage. Dans le terminal, exécutez la commande suivante :
cloudshell edit training_job.yaml - Collez le code suivant dans le fichier
training_job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- Enfin, appliquez le fichier manifeste du job Kubernetes pour démarrer le job d'affinage sur votre cluster GKE.
envsubst < training_job.yaml | kubectl apply -f -
14. Surveiller la tâche d'entraînement
Vous pouvez surveiller la progression de votre job d'entraînement dans la console Google Cloud.
- Accédez à la page Kubernetes Engine > Charges de travail.
Afficher les charges de travail GKE - Cliquez sur le job
llama-fine-tuningpour afficher ses détails. - L'onglet Détails s'affiche par défaut. Vous pouvez consulter les métriques d'utilisation du GPU dans la section Ressources.
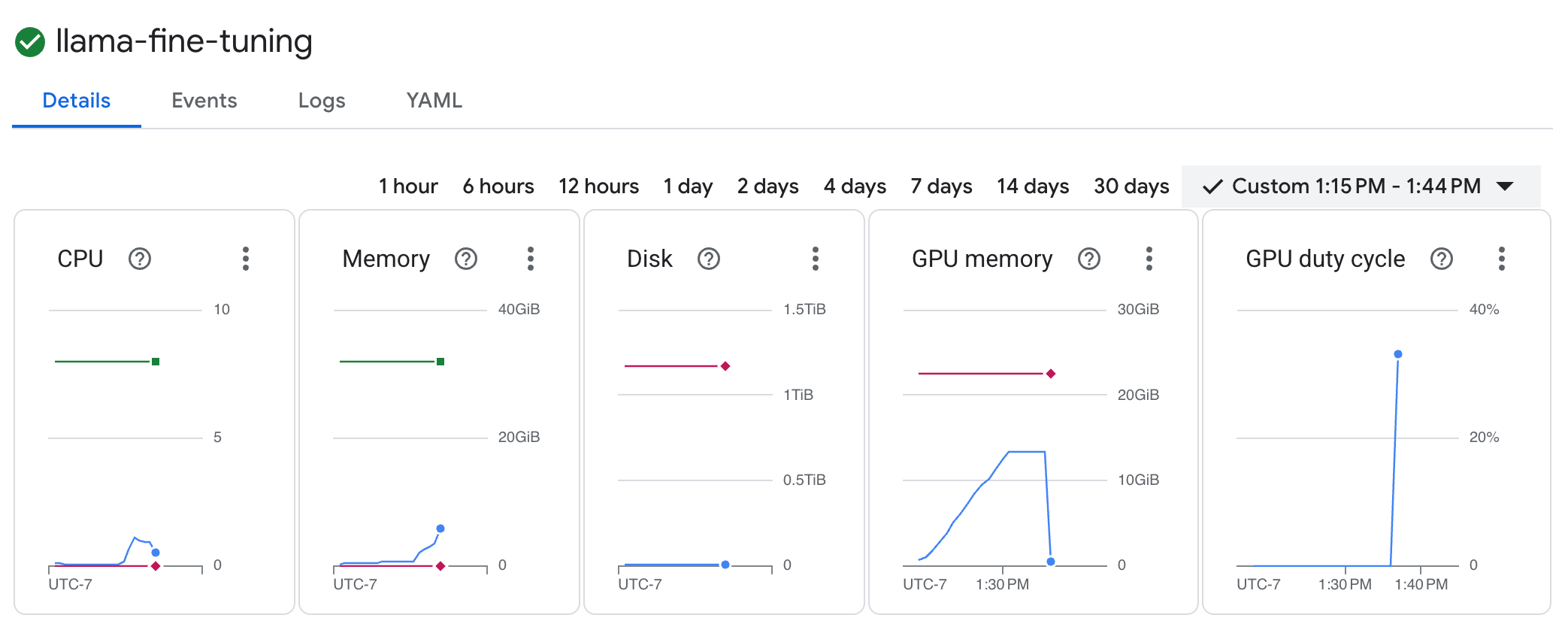
- Cliquez sur l'onglet Journaux pour afficher les journaux d'entraînement. Vous devriez voir la progression de l'entraînement, y compris la perte et le taux d'apprentissage.
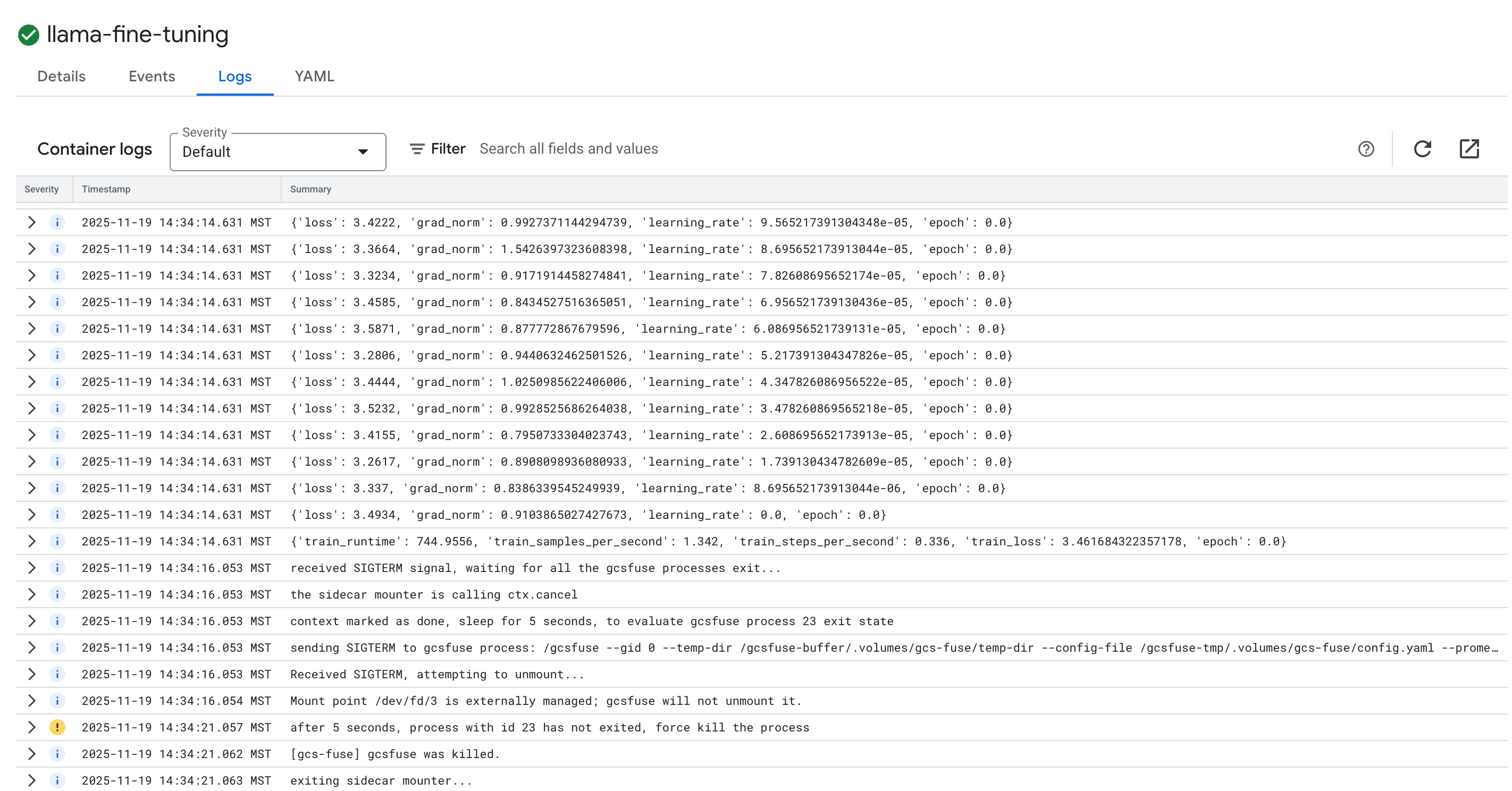
15. Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez chaque ressource individuellement.
Supprimer le cluster GKE
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Supprimer le dépôt Artifact Registry
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
Supprimer le bucket GCS
gcloud storage rm -r gs://${BUCKET_NAME}
16. Félicitations !
Vous avez réussi à affiner un LLM Open Source sur GKE.
Récapitulatif
Au cours de cet atelier, vous allez :
- Vous avez provisionné un cluster GKE avec accélération GPU.
- Vous avez configuré Workload Identity pour accéder de manière sécurisée aux services Google Cloud.
- Conteneurisation d'un job d'entraînement PyTorch à l'aide de Docker et d'Artifact Registry.
- Déployé un job de réglage fin à l'aide de LoRA pour adapter Llama 2 à un nouvel ensemble de données.
Étape suivante
- En savoir plus sur l'IA sur GKE
- Explorez Vertex AI Model Garden.
- Rejoignez la communauté Google Cloud pour échanger avec d'autres développeurs.
Parcours de formation Google Cloud
Cet atelier fait partie du parcours de formation L'IA prête pour la production avec Google Cloud. Découvrez le programme complet pour passer du prototype à la production.
Partagez votre progression avec le hashtag #ProductionReadyAI.