
1. מבוא
במעבדה הזו תלמדו איך ליצור צינור עיבוד נתונים מלא ומתאים לסביבת ייצור לצורך כוונון עדין של Llama 2, מודל שפה פופולרי בקוד פתוח, באמצעות Google Kubernetes Engine (GKE). תלמדו על החלטות ארכיטקטוניות, על פשרות נפוצות ועל רכיבים שמשקפים תהליכי עבודה של Machine Learning Operations (MLOps) בעולם האמיתי.
תקצו אשכול GKE, תבנו צינור עיבוד נתונים לאימון בקונטיינרים באמצעות LoRA (Low-Rank Adaptation) ותריצו את משימת האימון ב-GKE.
סקירה כללית של הארכיטקטורה
זה מה שנבנה היום:
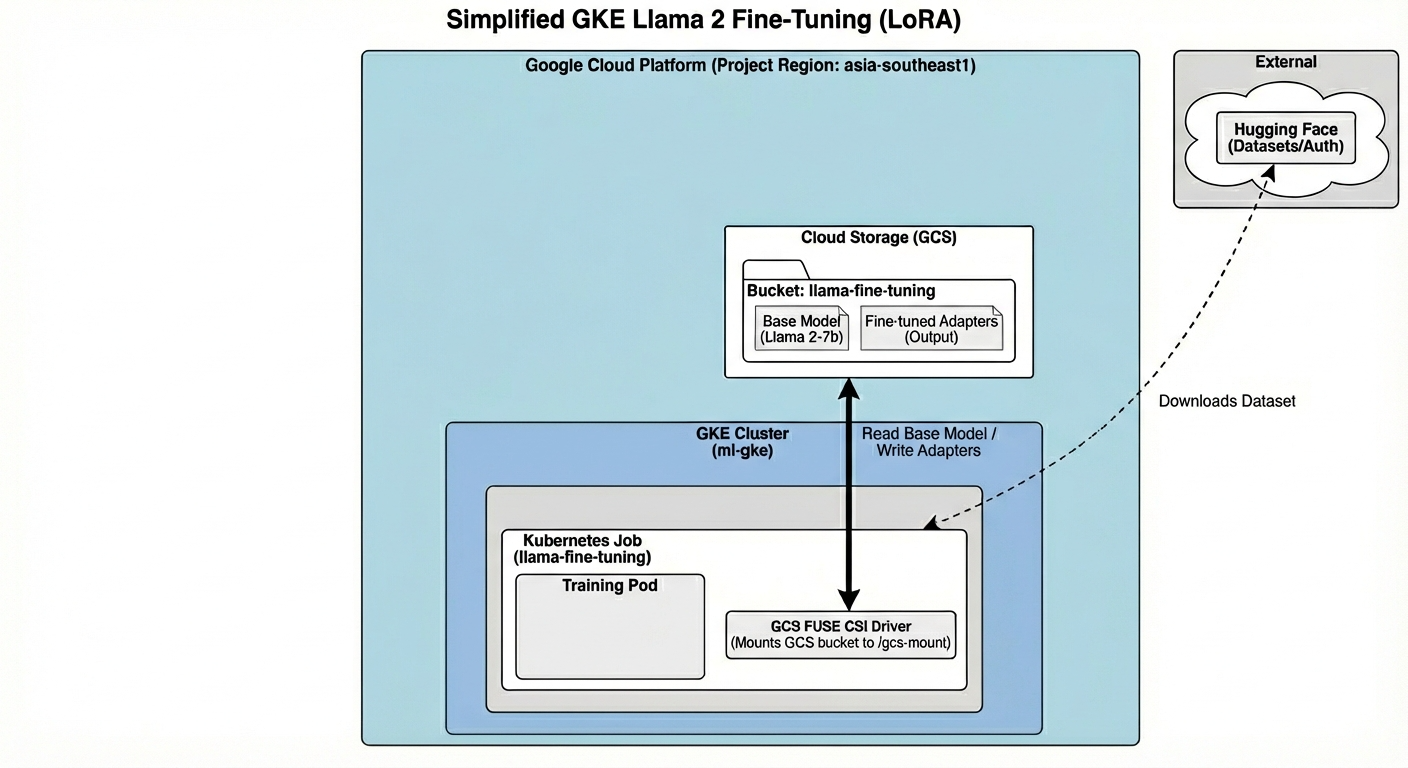
הארכיטקטורה כוללת:
- אשכול GKE: ניהול משאבי המחשוב
- מאגר צמתים של GPU: יחידת GPU אחת מסוג L4 (Spot) לאימון
- GCS Bucket: אחסון של מודלים ומערכי נתונים
- Workload Identity: גישה מאובטחת בין K8s ל-GCS
מה תלמדו
- הקצאה והגדרה של אשכול GKE עם תכונות שעברו אופטימיזציה לעומסי עבודה של למידת מכונה.
- הטמעה של גישה מאובטחת ללא מפתח מ-GKE לשירותים אחרים של Google Cloud באמצעות Workload Identity.
- פיתוח צינור עיבוד נתונים לאימון בקונטיינר באמצעות Docker.
- אפשר לבצע כוונון עדין של מודל קוד פתוח ביעילות באמצעות כוונון יעיל בפרמטרים (PEFT) עם LoRA.
2. הגדרת הפרויקט
חשבון Google
אם אין לכם חשבון Google אישי, אתם צריכים ליצור חשבון Google.
משתמשים בחשבון לשימוש אישי במקום בחשבון לצורכי עבודה או בחשבון בית ספרי.
כניסה למסוף Google Cloud
נכנסים למסוף Google Cloud באמצעות חשבון Google אישי.
יצירת פרויקט (אופציונלי)
אם אין לכם פרויקט שאתם רוצים להשתמש בו בסדנה הזו, אתם יכולים ליצור פרויקט חדש כאן.
3. פתיחת Cloud Shell Editor
- כדי לעבור ישירות אל Cloud Shell Editor, לוחצים על הקישור הזה.
- אם תתבקשו לאשר בשלב כלשהו היום, תצטרכו ללחוץ על אישור כדי להמשיך.
- אם הטרמינל לא מופיע בתחתית המסך, פותחים אותו:
- לוחצים על הצגה.
- לוחצים על Terminal (מסוף)
 .
.
- בטרמינל, מגדירים את הפרויקט באמצעות הפקודה הבאה:
gcloud config set project [PROJECT_ID]- דוגמה:
gcloud config set project lab-project-id-example - אם אתם לא זוכרים את מזהה הפרויקט, אתם יכולים להציג רשימה של כל מזהי הפרויקטים באמצעות הפקודה:
gcloud projects list
- דוגמה:
- תוצג ההודעה הבאה:
Updated property [core/project].
4. הפעלת ממשקי ה-API
כדי להשתמש ב-GKE ובשירותים אחרים, צריך להפעיל את ממשקי ה-API הנדרשים בפרויקט בענן של Google.
- בטרמינל, מפעילים את ממשקי ה-API:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
מבוא לממשקי ה-API
- Google Kubernetes Engine API (
container.googleapis.com) מאפשר ליצור ולנהל את אשכול GKE שמריץ את האפליקציה. - Artifact Registry API (
artifactregistry.googleapis.com) מספק מאגר פרטי ומאובטח לאחסון תמונות של קונטיינרים. - Cloud Build API (
cloudbuild.googleapis.com) משמש את הפקודהgcloud builds submitכדי ליצור את קובץ אימג' של קונטיינר בענן. - IAM API (
iam.googleapis.com) מאפשר לכם לנהל את בקרת הגישה והזהות של המשאבים ב-Google Cloud. - Compute Engine API (
compute.googleapis.com) מספק מכונות וירטואליות מאובטחות שניתנות להתאמה אישית ופועלות בתשתית של Google. - IAM Service Account Credentials API (
iamcredentials.googleapis.com) מאפשר ליצור פרטי כניסה לטווח קצר לחשבונות שירות. - Cloud Storage API (
storage.googleapis.com) מאפשר לכם לאחסן ולאחזר נתונים בענן. כאן הוא משמש לאחסון של מודלים ושל מערכי נתונים.
5. הגדרת סביבת הפרויקט
יצירת ספריית עבודה
- בטרמינל, יוצרים ספרייה לפרויקט ועוברים אליה.
mkdir llama-finetuning cd llama-finetuning
הגדרה של משתני סביבה
- בטרמינל, יוצרים קובץ בשם
env.shכדי לאחסן את משתני הסביבה. כך תוכלו לטעון אותם מחדש בקלות אם הסשן יתנתק.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - מריצים את הקובץ כדי לטעון את המשתנים לסשן הנוכחי:
source env.sh
6. הקצאת אשכול GKE
- בטרמינל, יוצרים את אשכול ה-GKE עם מאגר צמתים שמוגדר כברירת מחדל. התהליך יימשך כ-5 דקות.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - בשלב הבא, מוסיפים מאגר צמתים של GPU לאשכול. מאגר הצמתים הזה ישמש לאימון המודל.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - לבסוף, מקבלים את פרטי הכניסה לאשכול החדש ומוודאים שאפשר להתחבר אליו.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. הגדרת הגישה ל-Hugging Face
אחרי שהתשתית מוכנה, צריך לספק לפרויקט את פרטי הכניסה הנדרשים כדי לגשת למודל ולנתונים. במשימה הזו, קודם תקבלו טוקן של Hugging Face.
קבלת טוקן של Hugging Face
- אם אין לכם חשבון Hugging Face, עוברים אל huggingface.co/join בכרטיסייה חדשה בדפדפן ומשלימים את תהליך ההרשמה.
- אחרי שנרשמים ונכנסים לחשבון, עוברים אל huggingface.co/meta-llama/Llama-2-7b-hf.
- קוראים את תנאי הרישיון ולוחצים על הכפתור כדי לאשר אותם.
- עוברים לדף של טוקני הגישה של Hugging Face בכתובת huggingface.co/settings/tokens.
- לוחצים על טוקן חדש.
- בשדה תפקיד, בוחרים באפשרות קריאה.
- בשדה שם, מזינים שם תיאורי (למשל, finetuning-lab).
- לוחצים על יצירת טוקן.
- מעתיקים את הטוקן שנוצר ללוח. תצטרכו אותו בשלב הבא.
עדכון משתני סביבה
עכשיו מוסיפים את הטוקן של Hugging Face ואת השם של קטגוריית ה-GCS לקובץ env.sh. מחליפים את [your-hf-token] באסימון שהעתקתם.
- בטרמינל, מוסיפים את המשתנים החדשים ל-
env.shוטוענים אותם מחדש:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. הגדרת Workload Identity
בשלב הבא תגדירו את Workload Identity, שהיא הדרך המומלצת לאפשר לאפליקציות שפועלות ב-GKE לגשת לשירותי Google Cloud בלי לנהל מפתחות סטטיים של חשבונות שירות. מידע נוסף זמין במסמכים בנושא Workload Identity.
- קודם יוצרים חשבון שירות של Google (GSA). בטרמינל, מריצים את הפקודה:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - לאחר מכן, יוצרים את קטגוריית GCS ומעניקים ל-GSA הרשאות גישה אליה:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - עכשיו יוצרים חשבון שירות ב-Kubernetes (KSA):
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - לבסוף, יוצרים את הקישור של מדיניות IAM בין GSA ל-KSA:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. הכנת מודל הבסיס
בצינורות ML לייצור, מודלים גדולים כמו Llama 2 (~13GB) בדרך כלל מועלים מראש ל-Cloud Storage במקום להוריד אותם במהלך האימון. הגישה הזו מספקת מהימנות טובה יותר, גישה מהירה יותר ומונעת בעיות ברשת. Google Cloud מספקת גרסאות של מודלים פופולריים שהורדו מראש בדלי GCS ציבוריים, ותשתמשו בהם בשיעור ה-Lab הזה.
- קודם כול, צריך לוודא שיש לכם גישה למודל Llama 2 שסופק על ידי Google:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - מעתיקים את מודל Llama 2 מהקטגוריה הציבורית הזו לקטגוריה של הפרויקט שלכם באמצעות הפקודה
gcloud storage. ההעברה הזו מתבצעת באמצעות הרשת הפנימית המהירה של Google, והיא אמורה להימשך רק דקה או שתיים.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - כדי לוודא שקבצי המודל הועתקו בצורה נכונה, מציגים את התוכן של הדלי.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. הכנת קוד האימון
עכשיו תיצרו את האפליקציה שמופעלת בקונטיינר ומבצעת כוונון עדין של המודל. במשימה הזו נעשה שימוש ב-LoRA (Low-Rank Adaptation), טכניקה של כוונון יעיל בפרמטרים (PEFT) שמפחיתה באופן משמעותי את דרישות הזיכרון על ידי אימון רק של שכבות קטנות של 'מתאמים' במקום המודל כולו.
עכשיו יוצרים את סקריפטים של Python לפייפליין של האימון.
- בטרמינל, מריצים את הפקודה הבאה כדי לפתוח את הקובץ
train.py:cloudshell edit train.py - מדביקים את הקוד הבא לקובץ
train.py:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. הסבר על קוד האימון
הסקריפט train.py מתזמן את תהליך הכוונון העדין. נפרט את הרכיבים העיקריים שלו.
הגדרות אישיות
הסקריפט משתמש ב-LoraConfig כדי להגדיר את ההגדרות של Low-Rank Adaptation. LoRA מקטין באופן משמעותי את מספר הפרמטרים שאפשר לאמן, וכך מאפשר לכם לבצע התאמה עדינה של מודלים גדולים במעבדי GPU קטנים יותר.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
הכנת מערך נתונים
הפונקציה prepare_dataset טוענת את מערך הנתונים American Stories ומעבדת אותו למקטעים עם טוקנים. הוא משתמש ב-SimpleTextDataset בהתאמה אישית כדי לטפל בטנסורים של הקלט בצורה יעילה.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
רכבת
הפונקציה train_model מגדירה את Trainer עם ארגומנטים ספציפיים שעברו אופטימיזציה לעומס העבודה הזה. הפרמטרים העיקריים כוללים:
-
gradient_accumulation_steps: עוזר לדמות גודל אצווה גדול יותר בלי להגדיל את השימוש בזיכרון. -
fp16=True: משתמש באימון עם דיוק מעורב כדי לצמצם את השימוש בזיכרון ולהגביר את המהירות. -
gradient_checkpointing=True: חוסך זיכרון על ידי חישוב מחדש של ההפעלות במהלך המעבר לאחור במקום לשמור אותן. -
optim="adamw_torch": נעשה שימוש בהטמעה הרגילה של אופטימיזציית AdamW מ-PyTorch.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
הסקת מסקנות
הפונקציה run_inference מבצעת בדיקה מהירה של המודל שעבר התאמה עדינה באמצעות הנחיה לדוגמה. היא מוודאת שהמודל נמצא במצב הערכה ומפיקה טקסט כדי לוודא שהמתאמים פועלים בצורה תקינה.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. העברת האפליקציה לקונטיינר
עכשיו יוצרים את קובץ האימג' של קונטיינר האימון באמצעות Docker ומעבירים אותו בדחיפה אל Google Artifact Registry.
- בטרמינל, מריצים את הפקודה הבאה כדי לפתוח את הקובץ
Dockerfile:cloudshell edit Dockerfile - מדביקים את הקוד הבא לקובץ
Dockerfile:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
יצירה של קונטיינר ושליחתו
- יוצרים את מאגר Artifact Registry:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - יוצרים את קובץ האימג' ומעבירים אותו בדחיפה באמצעות Cloud Build:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. פריסת משימת הכוונון העדין
- יוצרים את מניפסט המשימה של Kubernetes כדי להתחיל את משימת הכוונון העדין. בטרמינל, מריצים את הפקודה:
cloudshell edit training_job.yaml - מדביקים את הקוד הבא לקובץ
training_job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- לבסוף, מפעילים את מניפסט המשימה של Kubernetes כדי להתחיל את משימת הכוונון העדין באשכול GKE.
envsubst < training_job.yaml | kubectl apply -f -
14. מעקב אחרי משימת האימון
אפשר לעקוב אחרי ההתקדמות של משימת האימון במסוף Google Cloud.
- עוברים לדף Kubernetes Engine > Workloads.
צפייה בעומסי עבודה ב-GKE - לוחצים על המשימה
llama-fine-tuningכדי לראות את הפרטים שלה. - הכרטיסייה פרטים מוצגת כברירת מחדל. אפשר לראות את מדדי ניצול ה-GPU בקטע Resources (משאבים).
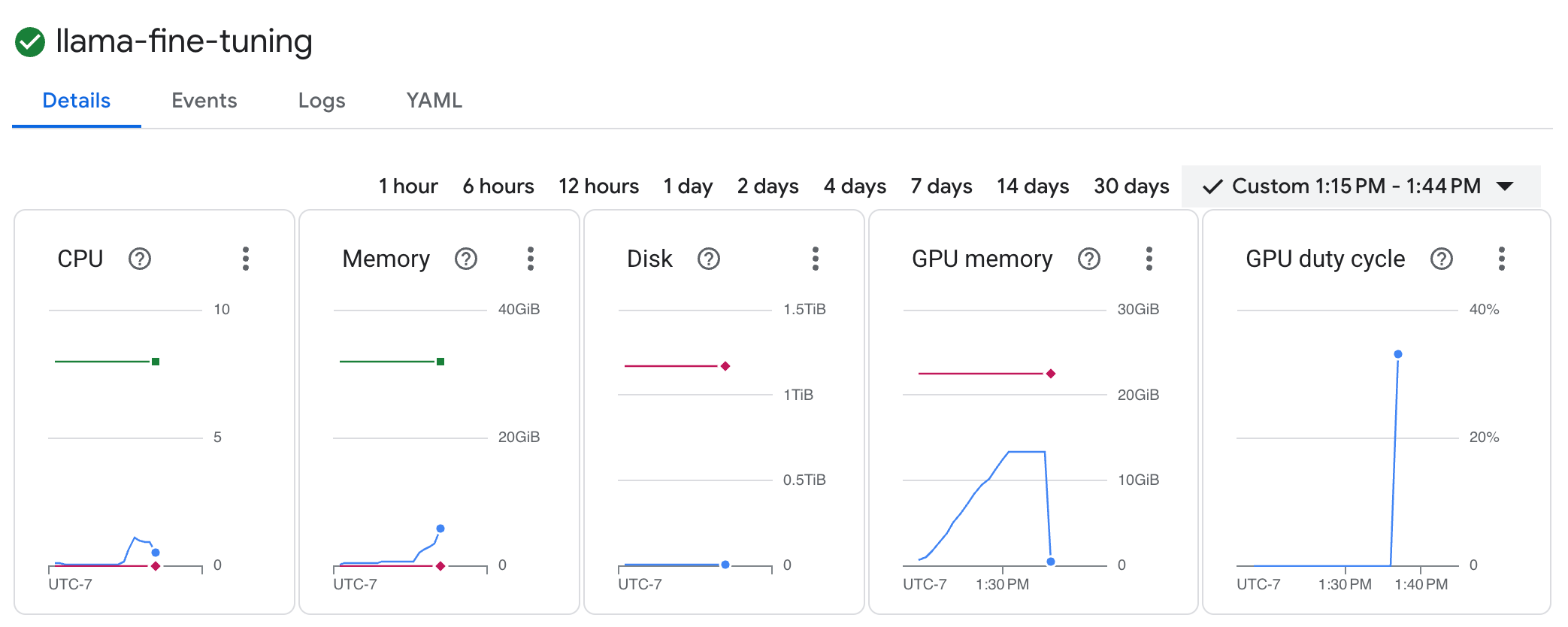
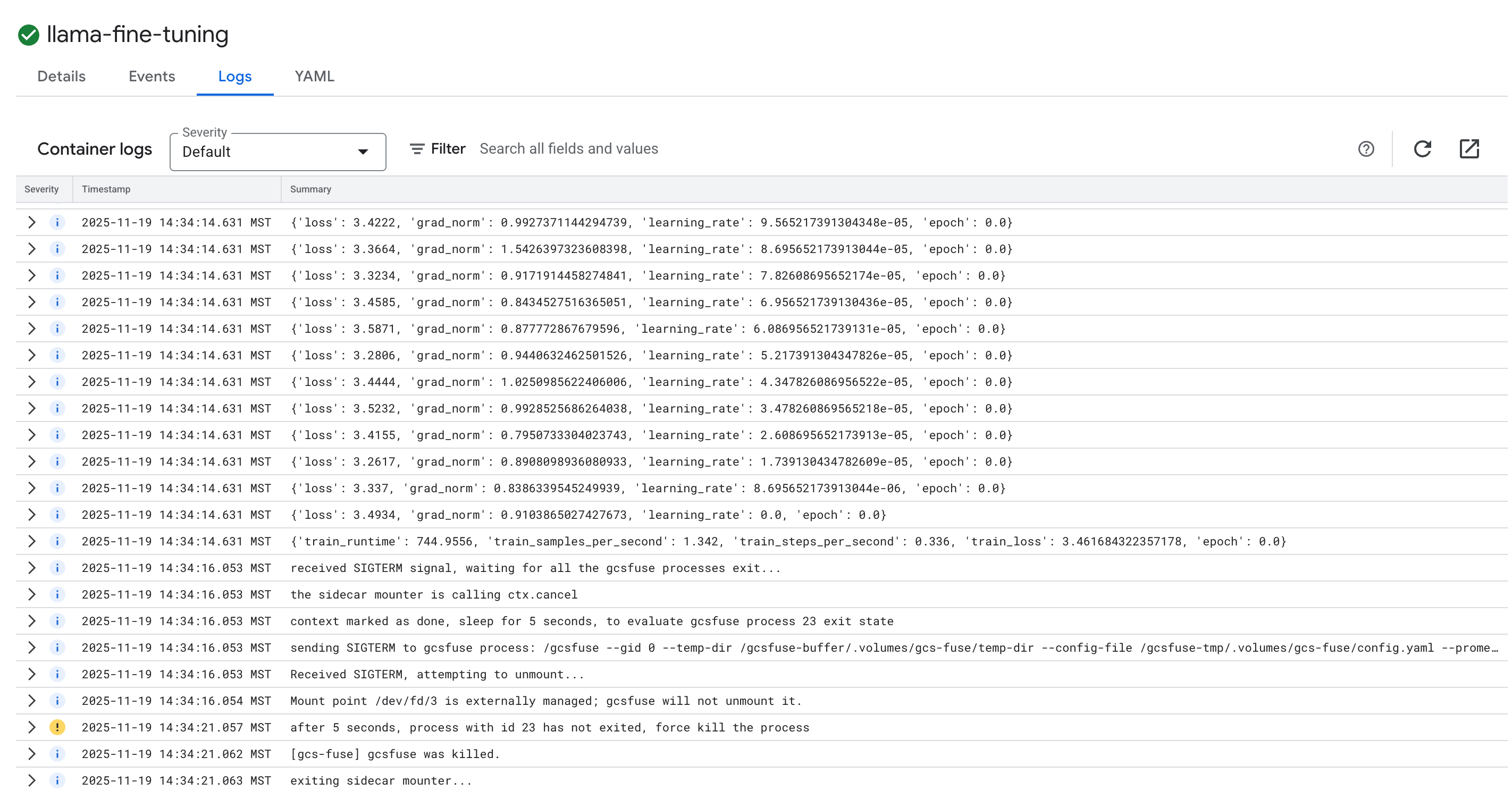
- לוחצים על הכרטיסייה יומנים כדי לראות את יומני האימון. אפשר לראות את התקדמות האימון, כולל ההפסד וקצב הלמידה.
15. הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה, אפשר למחוק את הפרויקט שמכיל את המשאבים, או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
מחיקת אשכול GKE
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
מחיקת מאגר Artifact Registry
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
מחיקת קטגוריית GCS
gcloud storage rm -r gs://${BUCKET_NAME}
16. מעולה!
הצלחתם לבצע כוונון עדין של מודל שפה גדול (LLM) בקוד פתוח ב-GKE.
Recap
בשיעור ה-Lab הזה:
- הקצאת אשכול GKE עם האצת GPU.
- הגדרת Workload Identity לגישה מאובטחת לשירותי Google Cloud.
- הפעלתם קונטיינר של משימת אימון של PyTorch באמצעות Docker ו-Artifact Registry.
- הפעלתם משימת כוונון עדין באמצעות LoRA כדי להתאים את Llama 2 למערך נתונים חדש.
המאמרים הבאים
- מידע נוסף על AI ב-GKE
- כדאי לעיין ב-Vertex AI Model Garden.
- כדי ליצור קשר עם מפתחים אחרים, אפשר להצטרף לקהילת Google Cloud.
Google Cloud Learning Path
ה-Lab הזה הוא חלק מתוכנית הלימודים Production-Ready AI with Google Cloud. כדי לגשר על הפער בין אב-טיפוס לבין מוצר מוכן, מומלץ לעיין בתוכנית הלימודים המלאה.
שתפו את ההתקדמות שלכם באמצעות ההאשטאג #ProductionReadyAI.