
1. परिचय
इस लैब में, आपको Google Kubernetes Engine (GKE) का इस्तेमाल करके, Llama 2 के लिए प्रोडक्शन-ग्रेड फ़ाइन-ट्यूनिंग पाइपलाइन बनाने का तरीका सिखाया जाएगा. Llama 2, एक लोकप्रिय ओपन-सोर्स भाषा मॉडल है. आपको आर्किटेक्चर से जुड़े फ़ैसलों, सामान्य ट्रेड-ऑफ़, और ऐसे कॉम्पोनेंट के बारे में जानकारी मिलेगी जो असल दुनिया के मशीन लर्निंग ऑपरेशंस (एमएलऑप्स) वर्कफ़्लो को दिखाते हैं.
आपको GKE क्लस्टर उपलब्ध कराया जाएगा. साथ ही, LoRA (लो-रैंक अडैप्टेशन) का इस्तेमाल करके, कंटेनर वाली ट्रेनिंग पाइपलाइन बनाई जाएगी. इसके बाद, GKE पर ट्रेनिंग का काम पूरा किया जाएगा.
आर्किटेक्चर के बारे में खास जानकारी
आज हम यह बनाएंगे:
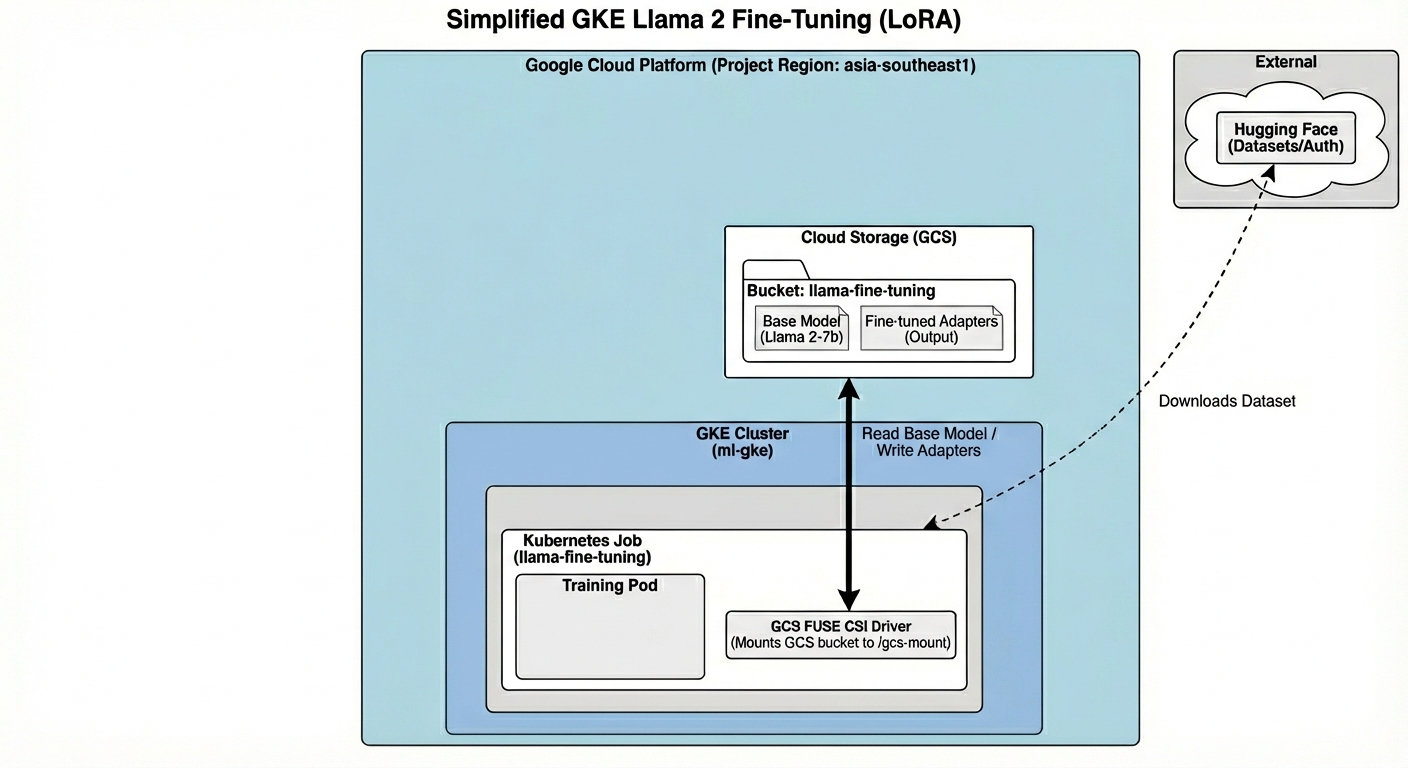
आर्किटेक्चर में ये शामिल हैं:
- GKE क्लस्टर: यह हमारे कंप्यूट संसाधनों को मैनेज करता है
- जीपीयू नोड पूल: ट्रेनिंग के लिए 1x L4 जीपीयू (स्पॉट)
- GCS बकेट: इसमें मॉडल और डेटासेट सेव किए जाते हैं
- Workload Identity: K8s और GCS के बीच सुरक्षित ऐक्सेस
आपको क्या सीखने को मिलेगा
- मशीन लर्निंग वर्कलोड के लिए ऑप्टिमाइज़ की गई सुविधाओं के साथ, GKE क्लस्टर को प्रोविज़न और कॉन्फ़िगर करें.
- Workload Identity का इस्तेमाल करके, GKE से Google Cloud की अन्य सेवाओं को सुरक्षित तरीके से ऐक्सेस करें. इसके लिए, आपको किसी कुंजी की ज़रूरत नहीं होगी.
- Docker का इस्तेमाल करके, कंटेनर वाली ट्रेनिंग पाइपलाइन बनाएं.
- LoRA के साथ पैरामीटर-इफ़िशिएंट फ़ाइन-ट्यूनिंग (पीईएफ़टी) का इस्तेमाल करके, ओपन-सोर्स मॉडल को बेहतर तरीके से फ़ाइन-ट्यून करें.
2. प्रोजेक्ट सेटअप करना
Google खाता
अगर आपके पास पहले से कोई निजी Google खाता नहीं है, तो आपको Google खाता बनाना होगा.
ऑफ़िस या स्कूल वाले खाते के बजाय, निजी खाते का इस्तेमाल करें.
Google Cloud Console में साइन इन करना
किसी निजी Google खाते का इस्तेमाल करके, Google Cloud Console में साइन इन करें.
कोई प्रोजेक्ट बनाएं (ज़रूरी नहीं)
अगर आपके पास कोई ऐसा मौजूदा प्रोजेक्ट नहीं है जिसका इस्तेमाल आपको इस लैब के लिए करना है, तो यहां नया प्रोजेक्ट बनाएं.
3. Cloud Shell Editor खोलें
- सीधे Cloud Shell Editor पर जाने के लिए, इस लिंक पर क्लिक करें
- अगर आज किसी भी समय अनुमति देने के लिए कहा जाता है, तो जारी रखने के लिए अनुमति दें पर क्लिक करें.
- अगर टर्मिनल स्क्रीन पर सबसे नीचे नहीं दिखता है, तो इसे खोलें:
- देखें पर क्लिक करें
- टर्मिनल
 पर क्लिक करें
पर क्लिक करें
- टर्मिनल में, इस कमांड का इस्तेमाल करके अपना प्रोजेक्ट सेट करें:
gcloud config set project [PROJECT_ID]- उदाहरण:
gcloud config set project lab-project-id-example - अगर आपको अपना प्रोजेक्ट आईडी याद नहीं है, तो इन कमांड का इस्तेमाल करके अपने सभी प्रोजेक्ट आईडी की सूची देखी जा सकती है:
gcloud projects list
- उदाहरण:
- आपको यह मैसेज दिखेगा:
Updated property [core/project].
4. एपीआई चालू करें
GKE और अन्य सेवाओं का इस्तेमाल करने के लिए, आपको अपने Google Cloud प्रोजेक्ट में ज़रूरी एपीआई चालू करने होंगे.
- टर्मिनल में, इन एपीआई को चालू करें:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
एपीआई के बारे में जानकारी
- Google Kubernetes Engine API (
container.googleapis.com) की मदद से, GKE क्लस्टर बनाया और मैनेज किया जा सकता है. यह क्लस्टर आपके ऐप्लिकेशन को चलाता है. - Artifact Registry API (
artifactregistry.googleapis.com) आपकी कंटेनर इमेज को सेव करने के लिए, सुरक्षित और निजी रिपॉज़िटरी उपलब्ध कराता है. - Cloud Build API (
cloudbuild.googleapis.com) का इस्तेमाल,gcloud builds submitकमांड करता है. इससे क्लाउड में आपकी कंटेनर इमेज बनाई जाती है. - IAM API (
iam.googleapis.com) की मदद से, Google Cloud संसाधनों के लिए ऐक्सेस कंट्रोल और पहचान मैनेज की जा सकती है. - Compute Engine API (
compute.googleapis.com) की मदद से, सुरक्षित और पसंद के मुताबिक बनाई जा सकने वाली वर्चुअल मशीनें मिलती हैं. ये मशीनें Google के इन्फ़्रास्ट्रक्चर पर काम करती हैं. - IAM सर्विस अकाउंट क्रेडेंशियल एपीआई (
iamcredentials.googleapis.com) की मदद से, सेवा खातों के लिए कम समय तक इस्तेमाल किए जा सकने वाले क्रेडेंशियल बनाए जा सकते हैं. - Cloud Storage API (
storage.googleapis.com) की मदद से, क्लाउड में डेटा को सेव और वापस पाया जा सकता है. इसका इस्तेमाल मॉडल और डेटासेट को सेव करने के लिए किया जाता है.
5. प्रोजेक्ट एनवायरमेंट सेट अप करना
वर्किंग डायरेक्ट्री बनाना
- टर्मिनल में, अपने प्रोजेक्ट के लिए एक डायरेक्ट्री बनाएं और उसमें नेविगेट करें.
mkdir llama-finetuning cd llama-finetuning
एनवायरमेंट वैरिएबल सेट अप करना
- एनवायरमेंट वैरिएबल सेव करने के लिए, टर्मिनल में
env.shनाम की फ़ाइल बनाएं. इससे यह पक्का होता है कि सेशन बंद होने पर, उन्हें आसानी से फिर से लोड किया जा सकता है.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - अपने मौजूदा सेशन में वैरिएबल लोड करने के लिए, फ़ाइल को सोर्स करें:
source env.sh
6. GKE क्लस्टर को प्रोविज़न करना
- टर्मिनल में, डिफ़ॉल्ट नोड पूल के साथ GKE क्लस्टर बनाएं. इसमें करीब पांच मिनट लगेंगे.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - इसके बाद, क्लस्टर में एक जीपीयू नोड पूल जोड़ें. इस नोड पूल का इस्तेमाल मॉडल को ट्रेनिंग देने के लिए किया जाएगा.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - आखिर में, अपने नए क्लस्टर के क्रेडेंशियल पाएं और पुष्टि करें कि इससे कनेक्ट किया जा सकता है.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Hugging Face का ऐक्सेस कॉन्फ़िगर करना
इंफ़्रास्ट्रक्चर तैयार होने के बाद, अब आपको अपने प्रोजेक्ट को ज़रूरी क्रेडेंशियल देने होंगे, ताकि वह आपके मॉडल और डेटा को ऐक्सेस कर सके. इस टास्क में, आपको सबसे पहले Hugging Face टोकन मिलेगा.
Hugging Face टोकन पाना
- अगर आपके पास Hugging Face खाता नहीं है, तो नई ब्राउज़र टैब में huggingface.co/join पर जाएं और रजिस्ट्रेशन की प्रोसेस पूरी करें.
- रजिस्टर करने और लॉग इन करने के बाद, huggingface.co/meta-llama/Llama-2-7b-hf पर जाएं.
- लाइसेंस की शर्तें पढ़ें और उन्हें स्वीकार करने के लिए, बटन पर क्लिक करें.
- huggingface.co/settings/tokens पर जाकर, Hugging Face के ऐक्सेस टोकन वाले पेज पर जाएं.
- नया टोकन पर क्लिक करें.
- भूमिका के लिए, पढ़ें चुनें.
- नाम के लिए, ज़्यादा जानकारी देने वाला नाम डालें. उदाहरण के लिए, finetuning-lab.
- टोकन बनाएं पर क्लिक करें.
- जनरेट किए गए टोकन को अपने क्लिपबोर्ड पर कॉपी करें. आपको इसकी ज़रूरत अगले चरण में पड़ेगी.
एनवायरमेंट वैरिएबल अपडेट करना
अब अपनी env.sh फ़ाइल में, Hugging Face टोकन और GCS बकेट का नाम जोड़ें. [your-hf-token] को उस टोकन से बदलें जिसे आपने अभी कॉपी किया है.
- टर्मिनल में, नए वैरिएबल को
env.shमें जोड़ें और उन्हें फिर से लोड करें:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. Workload Identity को कॉन्फ़िगर करना
इसके बाद, आपको वर्कलोड आइडेंटिटी सेट अप करनी होगी. यह GKE पर चल रहे ऐप्लिकेशन को Google Cloud की सेवाओं को ऐक्सेस करने की अनुमति देने का सबसे सही तरीका है. इससे आपको स्टैटिक सेवा खाते की कुंजियों को मैनेज करने की ज़रूरत नहीं पड़ती. ज़्यादा जानने के लिए, Workload Identity से जुड़ा दस्तावेज़ पढ़ें.
- सबसे पहले, Google सेवा खाता (जीएसए) बनाएं. टर्मिनल में, यह कमांड चलाएं:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - इसके बाद, GCS बकेट बनाएं और GSA को इसे ऐक्सेस करने की अनुमतियां दें:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - अब, Kubernetes सेवा खाता (केएसए) बनाएं:
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - आखिर में, GSA और KSA के बीच IAM नीति बाइंडिंग बनाएं:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. बेस मॉडल को स्टेज करना
प्रोडक्शन एमएल पाइपलाइन में, Llama 2 (~13 जीबी) जैसे बड़े मॉडल को आम तौर पर ट्रेनिंग के दौरान डाउनलोड करने के बजाय, Cloud Storage में पहले से ही स्टेज किया जाता है. इस तरीके से, बेहतर भरोसेमंद डेटा मिलता है. साथ ही, डेटा को तेज़ी से ऐक्सेस किया जा सकता है और नेटवर्क से जुड़ी समस्याओं से बचा जा सकता है. Google Cloud, सार्वजनिक GCS बकेट में लोकप्रिय मॉडल के पहले से डाउनलोड किए गए वर्शन उपलब्ध कराता है. इस लैब के लिए, आपको इनका इस्तेमाल करना होगा.
- सबसे पहले, आइए पुष्टि करें कि आपके पास Google की ओर से उपलब्ध कराए गए Llama 2 मॉडल को ऐक्सेस करने की अनुमति है या नहीं:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ gcloud storageकमांड का इस्तेमाल करके, इस सार्वजनिक बकेट से Llama 2 मॉडल को अपने प्रोजेक्ट की बकेट में कॉपी करें. इस ट्रांसफ़र के लिए, Google के तेज़ स्पीड वाले इंटरनल नेटवर्क का इस्तेमाल किया जाता है. इसमें सिर्फ़ एक या दो मिनट लगते हैं.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/- पुष्टि करें कि मॉडल फ़ाइलें सही तरीके से कॉपी की गई हैं. इसके लिए, अपनी बकेट का कॉन्टेंट देखें.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. ट्रेनिंग कोड तैयार करना
अब आपको कंटेनर वाला ऐसा ऐप्लिकेशन बनाना होगा जो मॉडल को बेहतर बनाएगा. इस टास्क में LoRA (लो-रैंक अडैप्टेशन) का इस्तेमाल किया जाता है. यह पैरामीटर-इफ़िशिएंट फ़ाइन-ट्यूनिंग (पीईएफ़टी) की एक ऐसी तकनीक है जो पूरे मॉडल के बजाय सिर्फ़ छोटी "अडैप्टर" लेयर को ट्रेन करके, मेमोरी की ज़रूरत को काफ़ी कम कर देती है.
अब ट्रेनिंग पाइपलाइन के लिए Python स्क्रिप्ट बनाएं.
train.pyफ़ाइल खोलने के लिए, टर्मिनल में यह कमांड चलाएं:cloudshell edit train.py- नीचे दिए गए कोड को
train.pyफ़ाइल में चिपकाएं:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. ट्रेनिंग कोड के बारे में जानकारी
train.py स्क्रिप्ट, फ़ाइन-ट्यूनिंग की प्रोसेस को मैनेज करती है. आइए, इसके मुख्य कॉम्पोनेंट के बारे में जानते हैं.
कॉन्फ़िगरेशन
स्क्रिप्ट में, LoraConfig का इस्तेमाल Low-Rank Adaptation की सेटिंग तय करने के लिए किया जाता है. LoRA, ट्रेनिंग के लिए इस्तेमाल किए जाने वाले पैरामीटर की संख्या को काफ़ी कम कर देता है. इससे छोटे जीपीयू पर बड़े मॉडल को फ़ाइन-ट्यून किया जा सकता है.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
डेटासेट तैयार करना
prepare_dataset फ़ंक्शन, "अमेरिकन स्टोरीज़" डेटासेट को लोड करता है और उसे टोकन वाले हिस्सों में प्रोसेस करता है. यह इनपुट टेंसर को असरदार तरीके से हैंडल करने के लिए, कस्टम SimpleTextDataset का इस्तेमाल करता है.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
ट्रेन
train_model फ़ंक्शन, इस वर्कलोड के लिए ऑप्टिमाइज़ किए गए खास आर्ग्युमेंट के साथ Trainer को सेट अप करता है. मुख्य पैरामीटर में ये शामिल हैं:
gradient_accumulation_steps: इससे मेमोरी का इस्तेमाल बढ़ाए बिना, बड़े बैच साइज़ को सिम्युलेट करने में मदद मिलती है.fp16=True: यह मेमोरी को कम करने और स्पीड को बढ़ाने के लिए, मिक्स्ड प्रिसिशन ट्रेनिंग का इस्तेमाल करता है.gradient_checkpointing=True: यह बैकवर्ड पास के दौरान ऐक्टिवेशन को फिर से कंप्यूट करके मेमोरी को सेव करता है. इसके लिए, ऐक्टिवेशन को सेव करने के बजाय, उन्हें फिर से कंप्यूट किया जाता है.optim="adamw_torch": PyTorch से स्टैंडर्ड AdamW ऑप्टिमाइज़र का इस्तेमाल करता है.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
अनुमान
run_inference फ़ंक्शन, सैंपल प्रॉम्प्ट का इस्तेमाल करके फ़ाइन-ट्यून किए गए मॉडल की तुरंत जांच करता है. इससे यह पक्का होता है कि मॉडल, आकलन मोड में है. साथ ही, यह पुष्टि करने के लिए टेक्स्ट जनरेट करता है कि अडैप्टर सही तरीके से काम कर रहे हैं.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. ऐप्लिकेशन को कंटेनर में बदलना
अब Docker का इस्तेमाल करके, ट्रेनिंग कंटेनर इमेज बनाएं और उसे Google Artifact Registry पर पुश करें.
Dockerfileफ़ाइल खोलने के लिए, टर्मिनल में यह कमांड चलाएं:cloudshell edit Dockerfile- नीचे दिए गए कोड को
Dockerfileफ़ाइल में चिपकाएं:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
कंटेनर बनाना और उसे पुश करना
- Artifact Registry में डेटा स्टोर करने की जगह बनाएं:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Cloud Build का इस्तेमाल करके इमेज बनाएं और उसे पुश करें:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. फ़ाइन-ट्यूनिंग की प्रोसेस को लागू करना
- फ़ाइन-ट्यूनिंग की प्रोसेस शुरू करने के लिए, Kubernetes जॉब मेनिफ़ेस्ट बनाएं. टर्मिनल में, यह कमांड चलाएं:
cloudshell edit training_job.yaml - नीचे दिए गए कोड को
training_job.yamlफ़ाइल में चिपकाएं:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- आखिर में, अपने GKE क्लस्टर पर फ़ाइन-ट्यूनिंग का काम शुरू करने के लिए, Kubernetes जॉब मेनिफ़ेस्ट लागू करें.
envsubst < training_job.yaml | kubectl apply -f -
14. ट्रेनिंग जॉब की निगरानी करना
Google Cloud Console में जाकर, ट्रेनिंग जॉब की प्रोग्रेस देखी जा सकती है.
- Kubernetes Engine > वर्कलोड पेज पर जाएं.
GKE वर्कलोड देखें - नौकरी की जानकारी देखने के लिए,
llama-fine-tuningपर क्लिक करें. - जानकारी टैब डिफ़ॉल्ट रूप से दिखता है. संसाधन सेक्शन में, जीपीयू के इस्तेमाल से जुड़ी मेट्रिक देखी जा सकती हैं.
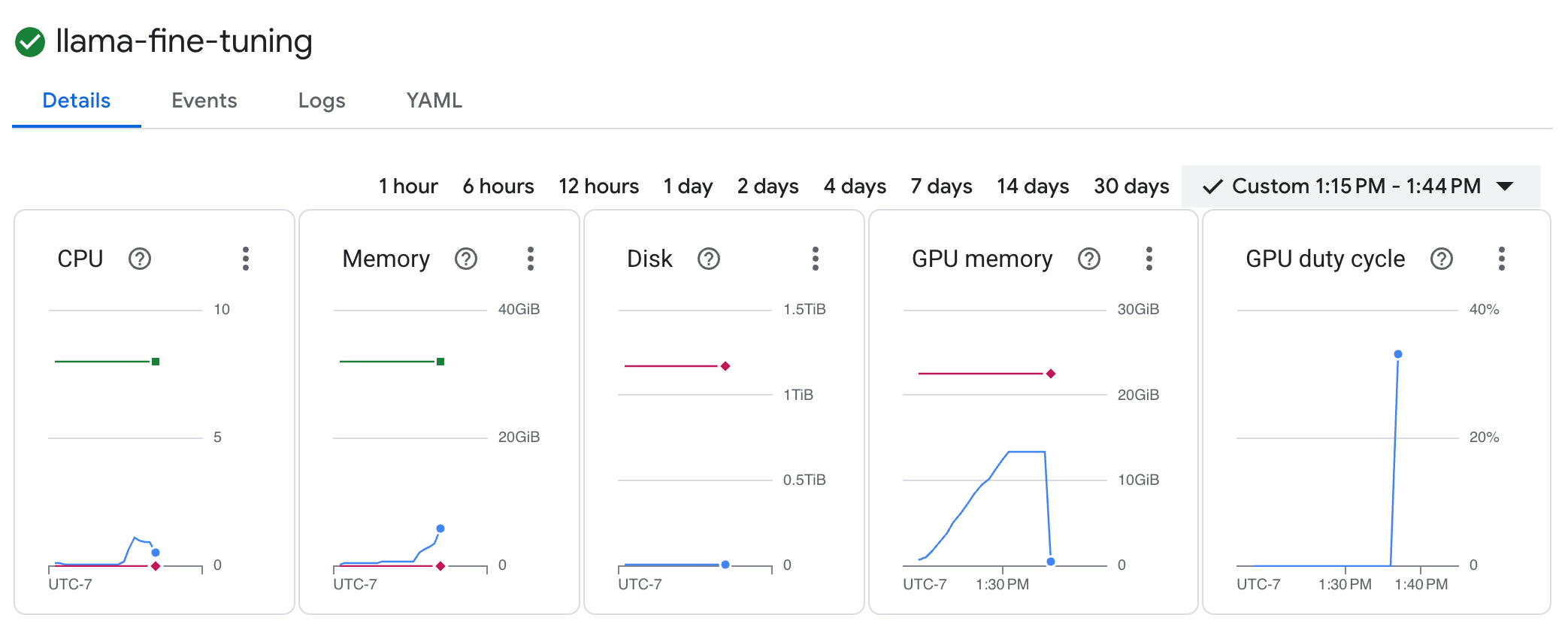
- ट्रेनिंग के लॉग देखने के लिए, लॉग टैब पर क्लिक करें. आपको ट्रेनिंग की प्रोग्रेस दिखनी चाहिए. इसमें लॉस और लर्निंग रेट शामिल है.
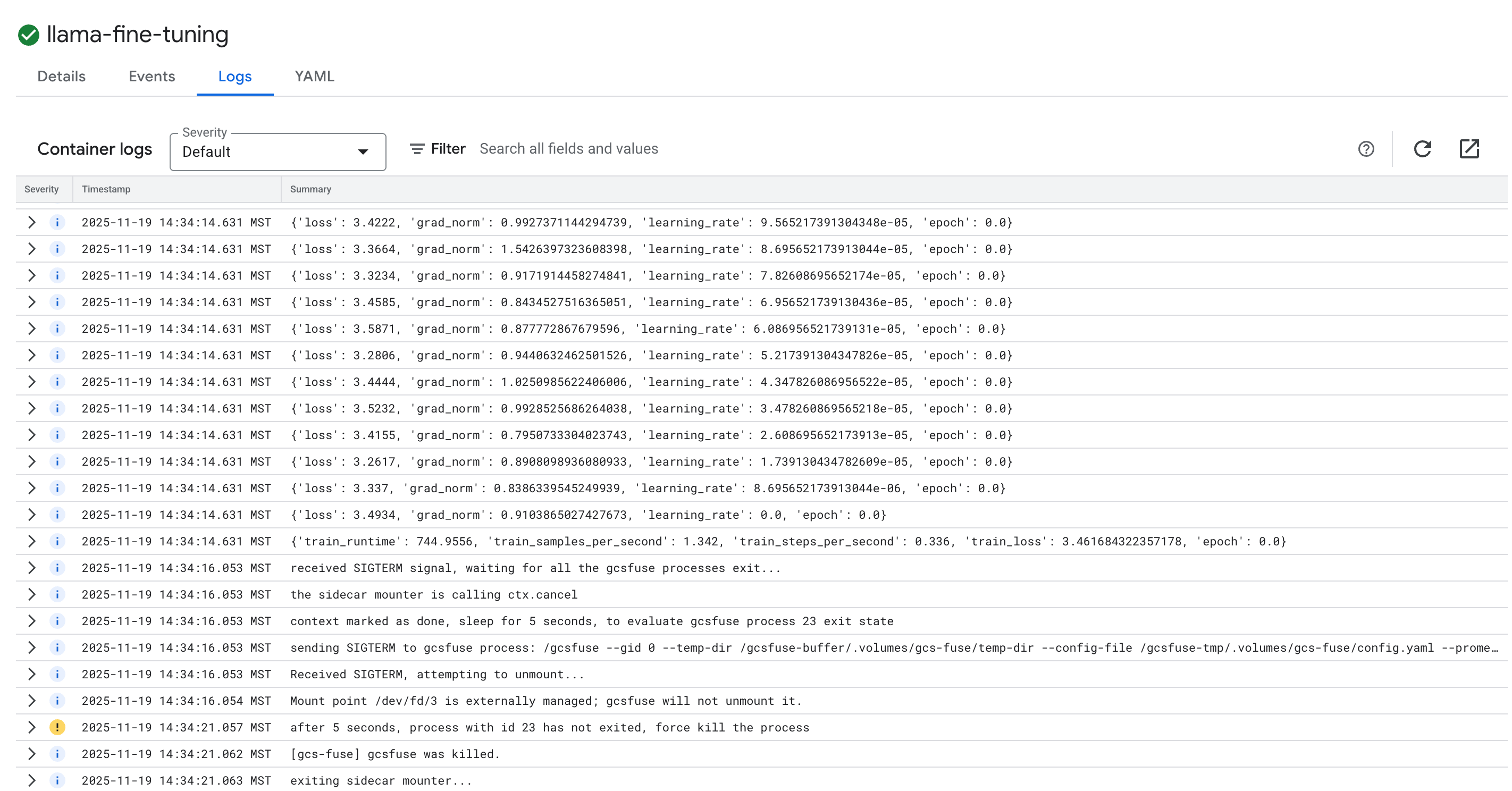
15. व्यवस्थित करें
इस ट्यूटोरियल में इस्तेमाल किए गए संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, संसाधनों वाला प्रोजेक्ट मिटाएं. इसके अलावा, प्रोजेक्ट को बनाए रखने और अलग-अलग संसाधनों को मिटाने का विकल्प भी है.
GKE क्लस्टर मिटाना
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Artifact Registry की रिपॉज़िटरी मिटाना
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
GCS बकेट मिटाएं
gcloud storage rm -r gs://${BUCKET_NAME}
16. बधाई हो!
आपने GKE पर ओपन-सोर्स एलएलएम को फ़ाइन-ट्यून कर लिया है!
रीकैप
इस लैब में, आपको:
- जीपीयू ऐक्सेलरेटेड GKE क्लस्टर को प्रोविज़न किया गया हो.
- Google Cloud सेवाओं को सुरक्षित तरीके से ऐक्सेस करने के लिए, Workload Identity कॉन्फ़िगर की गई हो.
- Docker और Artifact Registry का इस्तेमाल करके, PyTorch ट्रेनिंग जॉब को कंटेनर में रखा गया है.
- LoRA का इस्तेमाल करके, फ़ाइन-ट्यूनिंग का काम डिप्लॉय किया गया है, ताकि Llama 2 को नए डेटासेट के हिसाब से बनाया जा सके.
आगे क्या करना है
- GKE पर एआई के बारे में ज़्यादा जानें.
- Vertex AI Model Garden देखें.
- अन्य डेवलपर से जुड़ने के लिए, Google Cloud कम्यूनिटी में शामिल हों.
Google Cloud लर्निंग पाथ
यह लैब, Google Cloud के साथ प्रोडक्शन-रेडी एआई लर्निंग पाथ का हिस्सा है. प्रोटोटाइप से प्रोडक्शन तक के अंतर को कम करने के लिए, पूरा पाठ्यक्रम देखें.
अपनी प्रोग्रेस को #ProductionReadyAI हैशटैग के साथ शेयर करें.