
1. Pengantar
Di lab ini, Anda akan mempelajari cara membuat pipeline penyesuaian lengkap dan siap produksi untuk Llama 2, model bahasa open source yang populer, menggunakan Google Kubernetes Engine (GKE). Anda akan mempelajari keputusan arsitektur, pertimbangan umum, dan komponen yang mencerminkan alur kerja Operasi Machine Learning (MLOps) di dunia nyata.
Anda akan menyediakan cluster GKE, membangun pipeline pelatihan dalam container menggunakan LoRA (Low-Rank Adaptation), dan menjalankan tugas pelatihan di GKE.
Ringkasan Arsitektur
Berikut yang akan kita buat hari ini:
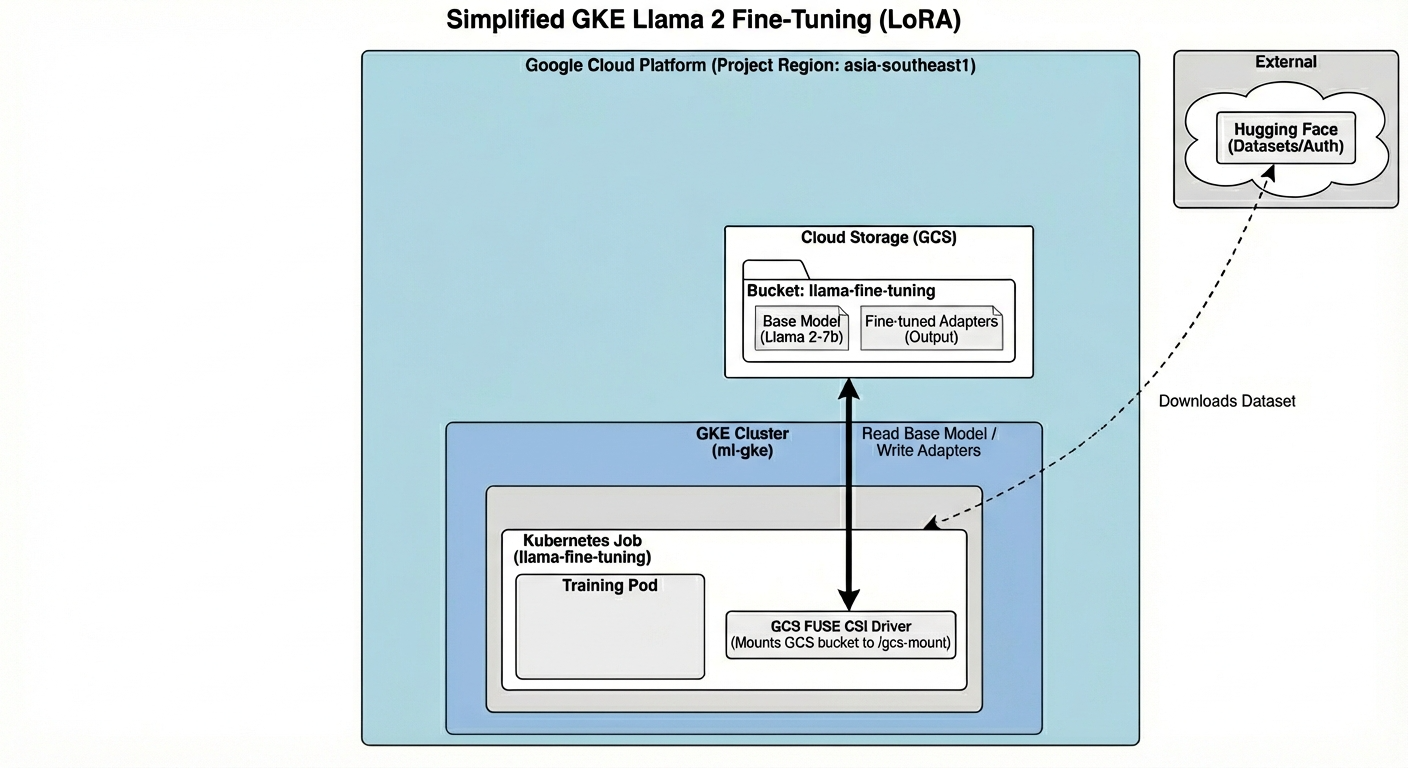
Arsitektur ini mencakup:
- Cluster GKE: Mengelola resource komputasi kami
- GPU Node Pool: 1x GPU L4 (Spot) untuk pelatihan
- Bucket GCS: Menyimpan model dan set data
- Workload Identity: Akses aman antara K8s dan GCS
Yang akan Anda pelajari
- Menyediakan dan mengonfigurasi cluster GKE dengan fitur yang dioptimalkan untuk beban kerja ML.
- Menerapkan akses tanpa kunci yang aman dari GKE ke layanan Google Cloud lainnya menggunakan Workload Identity.
- Bangun pipeline pelatihan dalam container menggunakan Docker.
- Menyesuaikan model open source secara efisien menggunakan Parameter-Efficient Fine-Tuning (PEFT) dengan LoRA.
2. Penyiapan project
Akun Google
Jika belum memiliki Akun Google pribadi, Anda harus membuat Akun Google.
Gunakan akun pribadi, bukan akun kantor atau sekolah.
Login ke Konsol Google Cloud
Login ke Konsol Google Cloud menggunakan Akun Google pribadi.
Membuat project (opsional)
Jika Anda tidak memiliki project saat ini yang ingin digunakan untuk lab ini, buat project baru di sini.
3. Buka Cloud Shell Editor
- Klik link ini untuk langsung membuka Cloud Shell Editor
- Jika diminta untuk memberikan otorisasi kapan saja hari ini, klik Authorize untuk melanjutkan.
- Jika terminal tidak muncul di bagian bawah layar, buka terminal:
- Klik Lihat
- Klik Terminal
- Di terminal, tetapkan project Anda dengan perintah ini:
gcloud config set project [PROJECT_ID]- Contoh:
gcloud config set project lab-project-id-example - Jika tidak ingat project ID, Anda dapat mencantumkan semua project ID dengan:
gcloud projects list
- Contoh:
- Anda akan melihat pesan ini:
Updated property [core/project].
4. Mengaktifkan API
Untuk menggunakan GKE dan layanan lainnya, Anda harus mengaktifkan API yang diperlukan di project Google Cloud Anda.
- Di terminal, aktifkan API:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
Memperkenalkan API
- Google Kubernetes Engine API (
container.googleapis.com) memungkinkan Anda membuat dan mengelola cluster GKE yang menjalankan aplikasi Anda. - Artifact Registry API (
artifactregistry.googleapis.com) menyediakan repositori pribadi yang aman untuk menyimpan image container Anda. - Cloud Build API (
cloudbuild.googleapis.com) digunakan oleh perintahgcloud builds submituntuk membangun image container Anda di cloud. - IAM API (
iam.googleapis.com) memungkinkan Anda mengelola kontrol akses dan identitas untuk resource Google Cloud Anda. - Compute Engine API (
compute.googleapis.com) menyediakan virtual machine yang aman dan dapat disesuaikan yang berjalan di infrastruktur Google. - IAM Service Account Credentials API (
iamcredentials.googleapis.com) memungkinkan pembuatan kredensial berjangka pendek untuk akun layanan. - Cloud Storage API (
storage.googleapis.com) memungkinkan Anda menyimpan dan mengambil data di cloud, yang digunakan di sini untuk penyimpanan model dan set data.
5. Menyiapkan lingkungan project
Buat direktori kerja
- Di terminal, buat direktori untuk project Anda dan buka direktori tersebut.
mkdir llama-finetuning cd llama-finetuning
Menyiapkan variabel lingkungan
- Di terminal, buat file bernama
env.shuntuk menyimpan variabel lingkungan Anda. Hal ini memastikan Anda dapat memuat ulang dengan mudah jika sesi Anda terputus.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - Lakukan sourcing file untuk memuat variabel ke sesi Anda saat ini:
source env.sh
6. Menyediakan Cluster GKE
- Di terminal, buat cluster GKE dengan node pool default. Proses ini akan memerlukan waktu sekitar 5 menit.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - Selanjutnya, tambahkan node pool GPU ke cluster. Kumpulan node ini akan digunakan untuk melatih model.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - Terakhir, dapatkan kredensial untuk cluster baru Anda dan verifikasi bahwa Anda dapat terhubung ke cluster tersebut.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Mengonfigurasi akses Hugging Face
Setelah infrastruktur siap, Anda kini perlu memberikan kredensial yang diperlukan ke project untuk mengakses model dan data Anda. Dalam tugas ini, Anda akan mendapatkan token Hugging Face terlebih dahulu.
Mendapatkan Token Hugging Face
- Jika Anda tidak memiliki akun Hugging Face, buka huggingface.co/join di tab browser baru dan selesaikan proses pendaftaran.
- Setelah terdaftar dan login, buka huggingface.co/meta-llama/Llama-2-7b-hf.
- Baca persyaratan lisensi, lalu klik tombol untuk menyetujuinya.
- Buka halaman token akses Hugging Face Anda di huggingface.co/settings/tokens.
- Klik Token baru.
- Untuk Peran, pilih Baca.
- Untuk Name, masukkan nama deskriptif (misalnya, finetuning-lab).
- Klik Buat token.
- Salin token yang dihasilkan ke papan klip Anda. Anda akan membutuhkan alamat itu pada langkah berikutnya.
Memperbarui Variabel Lingkungan
Sekarang, mari tambahkan token Hugging Face dan nama bucket GCS Anda ke file env.sh. Ganti [your-hf-token] dengan token yang baru saja Anda salin.
- Di terminal, tambahkan variabel baru ke
env.shdan muat ulang:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. Mengonfigurasi Workload Identity
Selanjutnya, Anda akan menyiapkan Workload Identity, yang merupakan cara yang direkomendasikan untuk mengizinkan aplikasi yang berjalan di GKE mengakses layanan Google Cloud tanpa perlu mengelola kunci akun layanan statis. Anda dapat mempelajari lebih lanjut di dokumentasi Workload Identity.
- Pertama, buat Akun Layanan Google (GSA). Di terminal, jalankan:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - Selanjutnya, buat bucket GCS dan berikan izin GSA untuk mengaksesnya:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - Sekarang, buat Akun Layanan Kubernetes (KSA):
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - Terakhir, buat binding kebijakan IAM antara GSA dan KSA:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. Menyiapkan model dasar
Dalam pipeline ML produksi, model besar seperti Llama 2 (~13 GB) biasanya dipersiapkan terlebih dahulu di Cloud Storage, bukan didownload selama pelatihan. Pendekatan ini memberikan keandalan yang lebih baik, akses yang lebih cepat, dan menghindari masalah jaringan. Google Cloud menyediakan versi model populer yang telah didownload di bucket GCS publik, yang akan Anda gunakan untuk lab ini.
- Pertama, mari kita verifikasi bahwa Anda dapat mengakses model Llama 2 yang disediakan Google:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - Salin model Llama 2 dari bucket publik ini ke bucket project Anda sendiri menggunakan perintah
gcloud storage. Transfer ini menggunakan jaringan internal berkecepatan tinggi Google dan hanya memerlukan waktu satu atau dua menit.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - Pastikan file model disalin dengan benar dengan mencantumkan konten bucket Anda.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. Menyiapkan kode pelatihan
Sekarang Anda akan membangun aplikasi dalam container yang menyetel model. Tugas ini menggunakan LoRA (Low-Rank Adaptation), teknik fine-tuning yang efisien parameter (PEFT) yang secara drastis mengurangi persyaratan memori dengan hanya melatih lapisan "adaptor" kecil, bukan seluruh model.
Sekarang, buat skrip Python untuk pipeline pelatihan.
- Di terminal, jalankan perintah berikut untuk membuka file
train.py:cloudshell edit train.py - Tempelkan kode berikut ke dalam file
train.py:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. Memahami kode pelatihan
Skrip train.py mengorkestrasi proses fine-tuning. Mari kita uraikan komponen utamanya.
Konfigurasi
Skrip menggunakan LoraConfig untuk menentukan setelan Adaptasi Peringkat Rendah. LoRA secara signifikan mengurangi jumlah parameter yang dapat dilatih, sehingga Anda dapat melakukan fine-tuning model besar pada GPU yang lebih kecil.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
Siapkan Set Data
Fungsi prepare_dataset memuat set data "American Stories" dan memprosesnya menjadi potongan yang ditokenkan. Model ini menggunakan SimpleTextDataset kustom untuk menangani tensor input secara efisien.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
Kereta
Fungsi train_model menyiapkan Trainer dengan argumen spesifik yang dioptimalkan untuk beban kerja ini. Parameter utama meliputi:
gradient_accumulation_steps: Membantu menyimulasikan ukuran batch yang lebih besar tanpa meningkatkan penggunaan memori.fp16=True: Menggunakan pelatihan presisi campuran untuk mengurangi memori dan meningkatkan kecepatan.gradient_checkpointing=True: Menghemat memori dengan menghitung ulang aktivasi selama backward pass, bukan menyimpannya.optim="adamw_torch": Menggunakan implementasi pengoptimal AdamW standar dari PyTorch.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
Inferensi
Fungsi run_inference melakukan pengujian cepat model yang di-fine-tune menggunakan perintah contoh. Hal ini memastikan model berada dalam mode evaluasi dan menghasilkan teks untuk memverifikasi bahwa adaptor berfungsi dengan benar.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. Membuat container aplikasi
Sekarang, bangun image container pelatihan menggunakan Docker dan kirimkan ke Google Artifact Registry.
- Di terminal, jalankan perintah berikut untuk membuka file
Dockerfile:cloudshell edit Dockerfile - Tempelkan kode berikut ke dalam file
Dockerfile:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
Membuat dan mengirim container
- Buat repositori Artifact Registry:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Bangun dan kirim image menggunakan Cloud Build:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. Deploy tugas penyesuaian
- Buat manifes tugas Kubernetes untuk memulai tugas penyesuaian. Di terminal, jalankan:
cloudshell edit training_job.yaml - Tempelkan kode berikut ke dalam file
training_job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- Terakhir, terapkan manifes tugas Kubernetes untuk memulai tugas penyesuaian pada cluster GKE Anda.
envsubst < training_job.yaml | kubectl apply -f -
14. Memantau tugas pelatihan
Anda dapat memantau progres tugas pelatihan di Konsol Google Cloud.
- Buka halaman Kubernetes Engine > Workloads.
Melihat Beban Kerja GKE - Klik tugas
llama-fine-tuninguntuk melihat detailnya. - Tab Detail ditampilkan secara default. Anda dapat melihat metrik pemanfaatan GPU di bagian Resources.
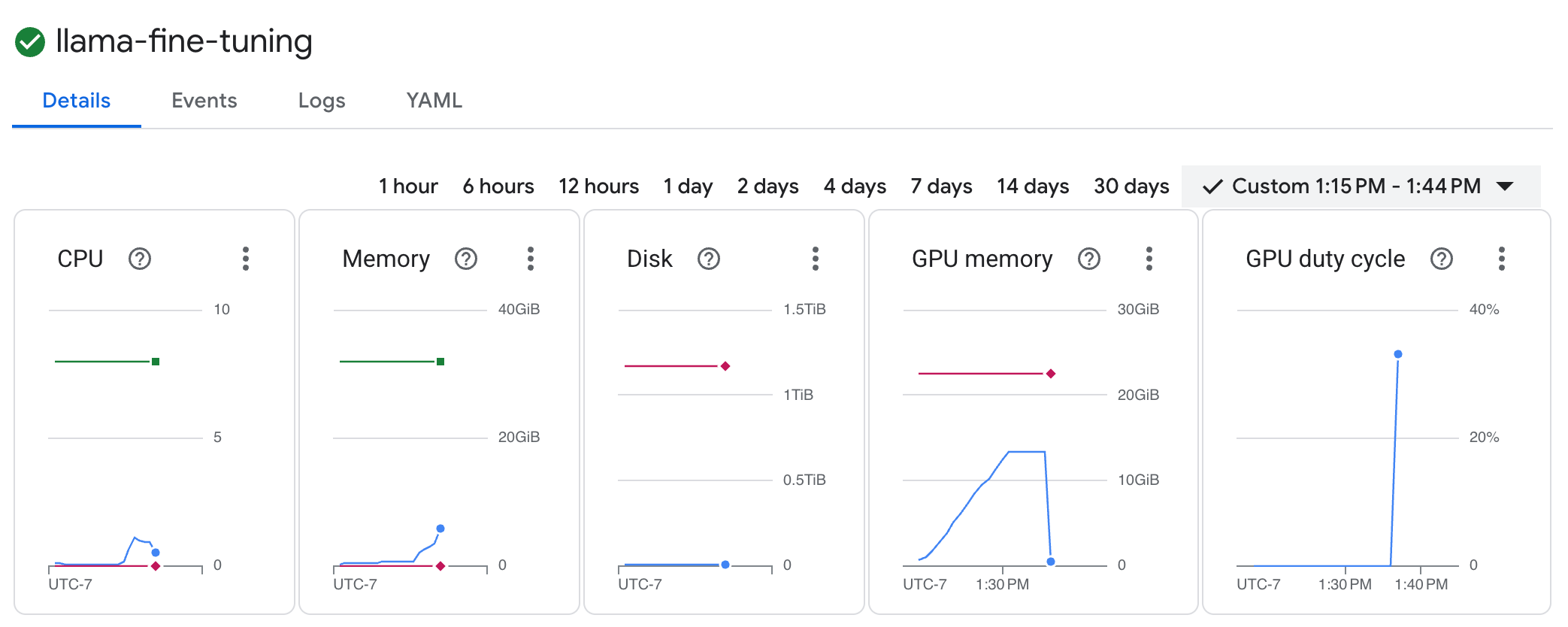
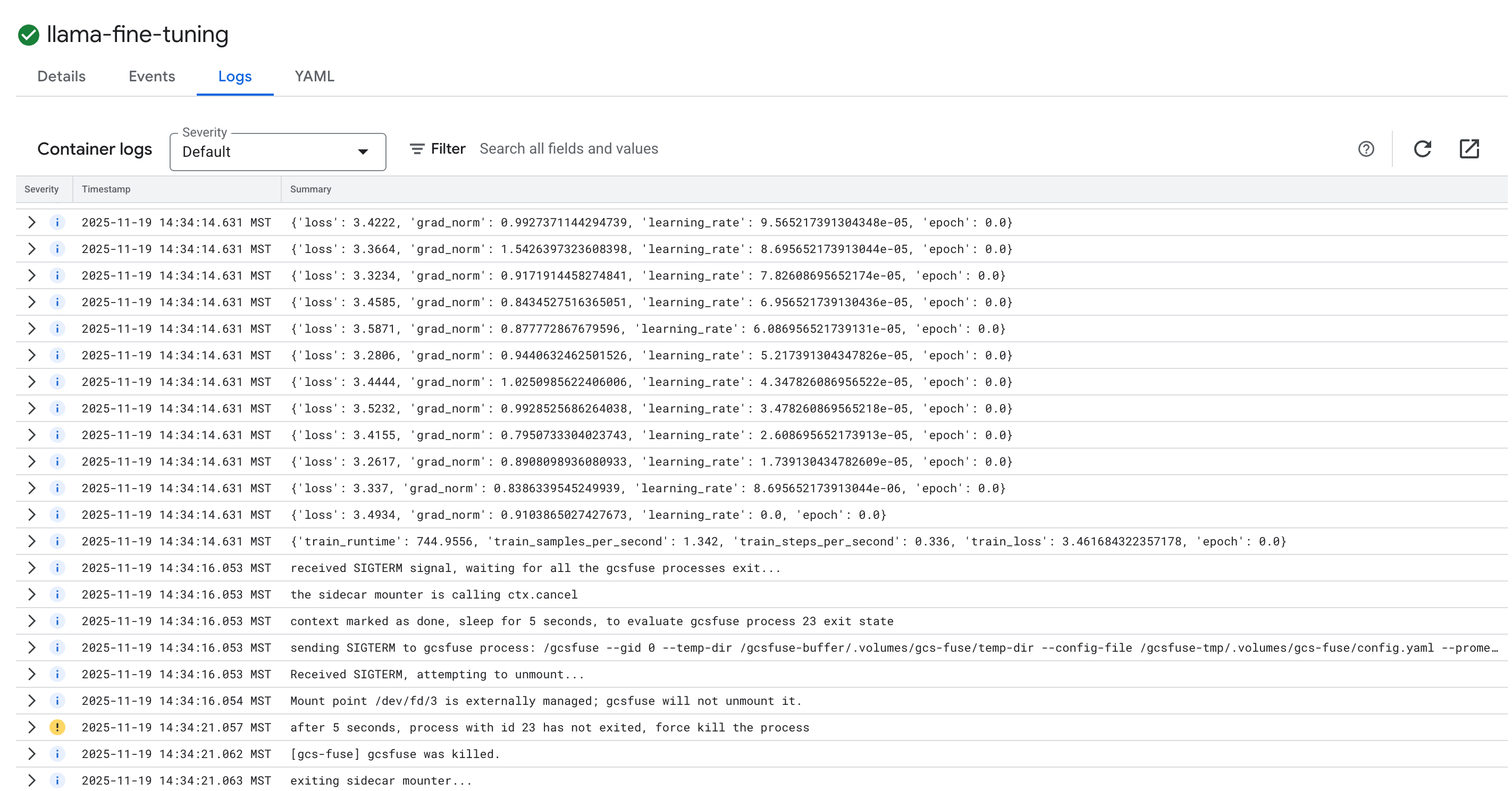
- Klik tab Logs untuk melihat log pelatihan. Anda akan melihat progres pelatihan, termasuk kerugian dan kecepatan pembelajaran.
15. Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus setiap resource.
Menghapus cluster GKE
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Hapus repositori Artifact Registry
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
Hapus bucket GCS
gcloud storage rm -r gs://${BUCKET_NAME}
16. Selamat!
Anda telah berhasil melakukan penyesuaian LLM open source di GKE.
Rangkuman
Di lab ini, Anda akan:
- Menyediakan cluster GKE dengan akselerasi GPU.
- Mengonfigurasi Workload Identity untuk akses yang aman ke layanan Google Cloud.
- Membuat container untuk tugas pelatihan PyTorch menggunakan Docker dan Artifact Registry.
- Men-deploy tugas penyesuaian menggunakan LoRA untuk mengadaptasi Llama 2 ke set data baru.
Langkah berikutnya
- Pelajari lebih lanjut AI di GKE.
- Jelajahi Vertex AI Model Garden.
- Bergabunglah dengan Komunitas Google Cloud untuk terhubung dengan developer lain.
Alur Pembelajaran Google Cloud
Lab ini merupakan bagian dari Jalur Pembelajaran AI Siap Produksi dengan Google Cloud. Jelajahi kurikulum lengkap untuk menjembatani kesenjangan dari prototipe hingga produksi.
Bagikan progres Anda dengan hashtag #ProductionReadyAI.