
1. Introduzione
In questo lab imparerai a creare una pipeline di fine tuning completa e di livello di produzione per Llama 2, un modello linguistico open source molto diffuso, utilizzando Google Kubernetes Engine (GKE). Scoprirai le decisioni architetturali, i compromessi comuni e i componenti che rispecchiano i flussi di lavoro di Machine Learning Operations (MLOps) del mondo reale.
Provisionerai un cluster GKE, creerai una pipeline di addestramento containerizzata utilizzando LoRA (Low-Rank Adaptation) ed eseguirai il job di addestramento su GKE.
Panoramica dell'architettura
Ecco cosa creeremo oggi:
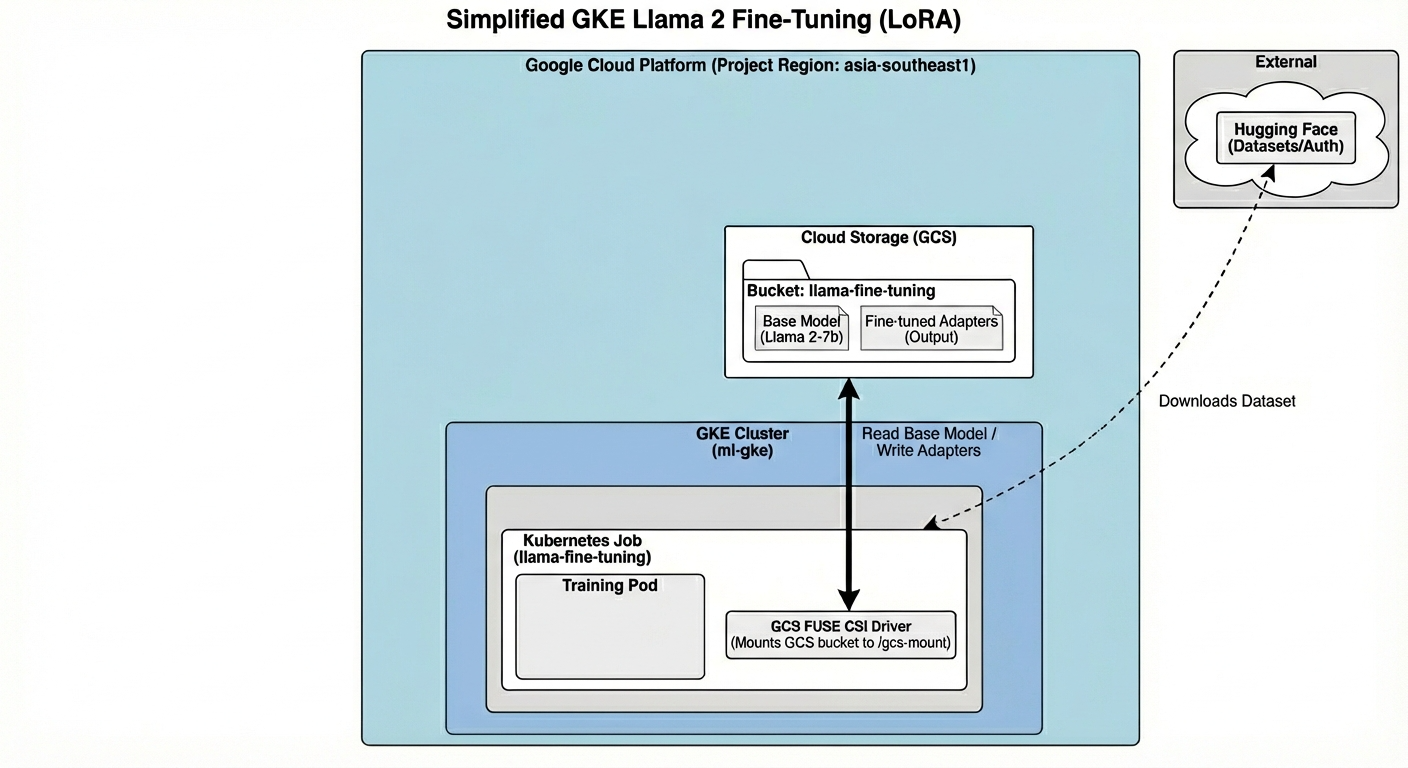
L'architettura include:
- Cluster GKE: gestisce le nostre risorse di calcolo
- Pool di nodi GPU: 1 GPU L4 (Spot) per l'addestramento
- Bucket GCS: archivia modelli e set di dati
- Workload Identity: accesso sicuro tra K8s e GCS
Obiettivi didattici
- Esegui il provisioning e configura un cluster GKE con funzionalità ottimizzate per i workload di ML.
- Implementa l'accesso sicuro e senza chiavi da GKE ad altri servizi Google Cloud utilizzando Workload Identity.
- Crea una pipeline di addestramento containerizzata utilizzando Docker.
- Ottimizza in modo efficiente un modello open source utilizzando Parameter-Efficient Fine-Tuning (PEFT) con LoRA.
2. Configurazione del progetto
Account Google
Se non hai ancora un Account Google personale, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
Accedi alla console Google Cloud
Accedi a Google Cloud Console utilizzando un Account Google personale.
Creare un progetto (facoltativo)
Se non hai un progetto attuale che vuoi utilizzare per questo lab, creane uno nuovo qui.
3. Apri editor di Cloud Shell
- Fai clic su questo link per andare direttamente all'editor di Cloud Shell.
- Se ti viene richiesto di concedere l'autorizzazione in qualsiasi momento della giornata, fai clic su Autorizza per continuare.
- Se il terminale non viene visualizzato nella parte inferiore dello schermo, aprilo:
- Fai clic su Visualizza.
- Fai clic su Terminale
 .
.
- Nel terminale, imposta il progetto con questo comando:
gcloud config set project [PROJECT_ID]- Esempio:
gcloud config set project lab-project-id-example - Se non ricordi l'ID progetto, puoi elencare tutti i tuoi ID progetto con:
gcloud projects list
- Esempio:
- Dovresti visualizzare questo messaggio:
Updated property [core/project].
4. Abilita API
Per utilizzare GKE e altri servizi, devi abilitare le API necessarie nel tuo progetto Google Cloud.
- Nel terminale, abilita le API:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
Presentazione delle API
- L'API Google Kubernetes Engine (
container.googleapis.com) ti consente di creare e gestire il cluster GKE che esegue la tua applicazione. - L'API Artifact Registry (
artifactregistry.googleapis.com) fornisce un repository sicuro e privato per archiviare le immagini container. - L'API Cloud Build (
cloudbuild.googleapis.com) viene utilizzata dal comandogcloud builds submitper creare l'immagine container nel cloud. - L'API IAM (
iam.googleapis.com) ti consente di gestire il controllo dell'accesso e l'identità per le tue risorse Google Cloud. - L'API Compute Engine (
compute.googleapis.com) fornisce macchine virtuali sicure e personalizzabili che vengono eseguite sull'infrastruttura di Google. - L'API IAM Service Account Credentials (
iamcredentials.googleapis.com) consente di creare credenziali di breve durata per i service account. - L'API Cloud Storage (
storage.googleapis.com) consente di archiviare e recuperare i dati nel cloud, utilizzati qui per l'archiviazione di modelli e set di dati.
5. Configurare l'ambiente del progetto
Crea una directory di lavoro
- Nel terminale, crea una directory per il tuo progetto e accedi alla directory.
mkdir llama-finetuning cd llama-finetuning
Imposta le variabili di ambiente
- Nel terminale, crea un file denominato
env.shper archiviare le variabili di ambiente. In questo modo, potrai ricaricarli facilmente in caso di disconnessione della sessione.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - Carica il file per caricare le variabili nella sessione corrente:
source env.sh
6. Esegui il provisioning del cluster GKE
- Nel terminale, crea il cluster GKE con un node pool predefinito. L'operazione richiederà circa 5 minuti.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - Successivamente, aggiungi un node pool GPU al cluster. Questo node pool verrà utilizzato per l'addestramento del modello.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - Infine, recupera le credenziali per il nuovo cluster e verifica di poterti connettere.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Configurare l'accesso a Hugging Face
Ora che l'infrastruttura è pronta, devi fornire al progetto le credenziali necessarie per accedere al modello e ai dati. In questa attività, otterrai prima un token Hugging Face.
Ottenere un token Hugging Face
- Se non hai un account Hugging Face, vai alla pagina huggingface.co/join in una nuova scheda del browser e completa la procedura di registrazione.
- Una volta registrato e effettuato l'accesso, vai alla pagina huggingface.co/meta-llama/Llama-2-7b-hf.
- Leggi i termini della licenza e fai clic sul pulsante per accettarli.
- Vai alla pagina dei token di accesso a Hugging Face all'indirizzo huggingface.co/settings/tokens.
- Fai clic su Nuovo token.
- In Ruolo, seleziona Lettura.
- In Nome, inserisci un nome descrittivo (ad es. finetuning-lab).
- Fai clic su Crea un token.
- Copia il token generato negli appunti. Ti servirà nel passaggio successivo.
Aggiorna le variabili di ambiente
Ora aggiungi il token Hugging Face e un nome per il bucket GCS al file env.sh. Sostituisci [your-hf-token] con il token che hai appena copiato.
- Nel terminale, aggiungi le nuove variabili a
env.she ricaricale:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. Configurazione di Workload Identity
Successivamente, configurerai Workload Identity, il modo consigliato per consentire alle applicazioni in esecuzione su GKE di accedere ai servizi Google Cloud senza dover gestire le chiavi statiche dell'account di servizio. Per saperne di più, consulta la documentazione di Workload Identity.
- Per prima cosa, crea un service account Google (GSA). Nel terminale, esegui:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - Dopodiché, crea il bucket GCS e concedi all'account di servizio Google le autorizzazioni per accedervi:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - Ora crea un service account Kubernetes (KSA):
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - Infine, crea l'associazione dei criteri IAM tra il GSA e il KSA:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. Organizza il modello di base
Nelle pipeline ML di produzione, i modelli di grandi dimensioni come Llama 2 (~13 GB) vengono in genere pre-organizzati in Cloud Storage anziché scaricati durante l'addestramento. Questo approccio offre una maggiore affidabilità, un accesso più rapido ed evita problemi di rete. Google Cloud fornisce versioni pre-scaricate di modelli popolari nei bucket GCS pubblici, che utilizzerai per questo lab.
- Innanzitutto, verifichiamo che tu possa accedere al modello Llama 2 fornito da Google:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - Copia il modello Llama 2 da questo bucket pubblico nel bucket del tuo progetto utilizzando il comando
gcloud storage. Questo trasferimento utilizza la rete interna ad alta velocità di Google e dovrebbe richiedere solo un paio di minuti.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - Verifica che i file del modello siano stati copiati correttamente elencando i contenuti del bucket.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. Preparare il codice di addestramento
Ora creerai l'applicazione containerizzata che ottimizza il modello. Questo compito utilizza LoRA (Low-Rank Adaptation), una tecnica di ottimizzazione efficiente dei parametri (PEFT) che riduce drasticamente i requisiti di memoria addestrando solo piccoli livelli "adattatori" anziché l'intero modello.
Ora crea gli script Python per la pipeline di addestramento.
- Nel terminale, esegui questo comando per aprire il file
train.py:cloudshell edit train.py - Incolla il seguente codice nel file
train.py:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. Informazioni sul codice di addestramento
Lo script train.py orchestra il processo di ottimizzazione. Analizziamo i suoi componenti chiave.
Configurazione
Lo script utilizza LoraConfig per definire le impostazioni di adattamento per i contenuti con ranking basso. LoRA riduce significativamente il numero di parametri addestrabili, consentendoti di ottimizzare i modelli di grandi dimensioni su GPU più piccole.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
Prepara il set di dati
La funzione prepare_dataset carica il set di dati "American Stories" e lo elabora in blocchi tokenizzati. Utilizza un SimpleTextDataset personalizzato per gestire in modo efficiente i tensori di input.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
Treno
La funzione train_model configura Trainer con argomenti specifici ottimizzati per questo carico di lavoro. I parametri chiave includono:
gradient_accumulation_steps: consente di simulare una dimensione batch maggiore senza aumentare l'utilizzo della memoria.fp16=True: utilizza l'addestramento a precisione mista per ridurre la memoria e aumentare la velocità.gradient_checkpointing=True: consente di risparmiare memoria ricalcolando le attivazioni durante il passaggio all'indietro anziché memorizzarle.optim="adamw_torch": utilizza l'implementazione standard dell'ottimizzatore AdamW di PyTorch.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
Inferenza
La funzione run_inference esegue un test rapido del modello ottimizzato utilizzando un prompt di esempio. Assicura che il modello sia in modalità di valutazione e genera testo per verificare che gli adattatori funzionino correttamente.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. Containerizza l'applicazione
Ora crea l'immagine container di addestramento utilizzando Docker ed eseguine il push su Google Artifact Registry.
- Nel terminale, esegui questo comando per aprire il file
Dockerfile:cloudshell edit Dockerfile - Incolla il seguente codice nel file
Dockerfile:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
Creare ed eseguire il push del container
- Crea il repository Artifact Registry:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Crea ed esegui il push dell'immagine utilizzando Cloud Build:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. Esegui il deployment del job di ottimizzazione
- Crea il manifest del job Kubernetes per avviare il job di perfezionamento. Nel terminale, esegui:
cloudshell edit training_job.yaml - Incolla il seguente codice nel file
training_job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- Infine, applica il manifest del job Kubernetes per avviare il job di perfezionamento sul cluster GKE.
envsubst < training_job.yaml | kubectl apply -f -
14. Monitora il job di addestramento
Puoi monitorare l'avanzamento del job di addestramento nella console Google Cloud.
- Vai alla pagina Kubernetes Engine > Workload.
Visualizza i workload GKE - Fai clic sul job
llama-fine-tuningper visualizzarne i dettagli. - Per impostazione predefinita, viene visualizzata la scheda Dettagli. Puoi visualizzare le metriche di utilizzo della GPU nella sezione Risorse.
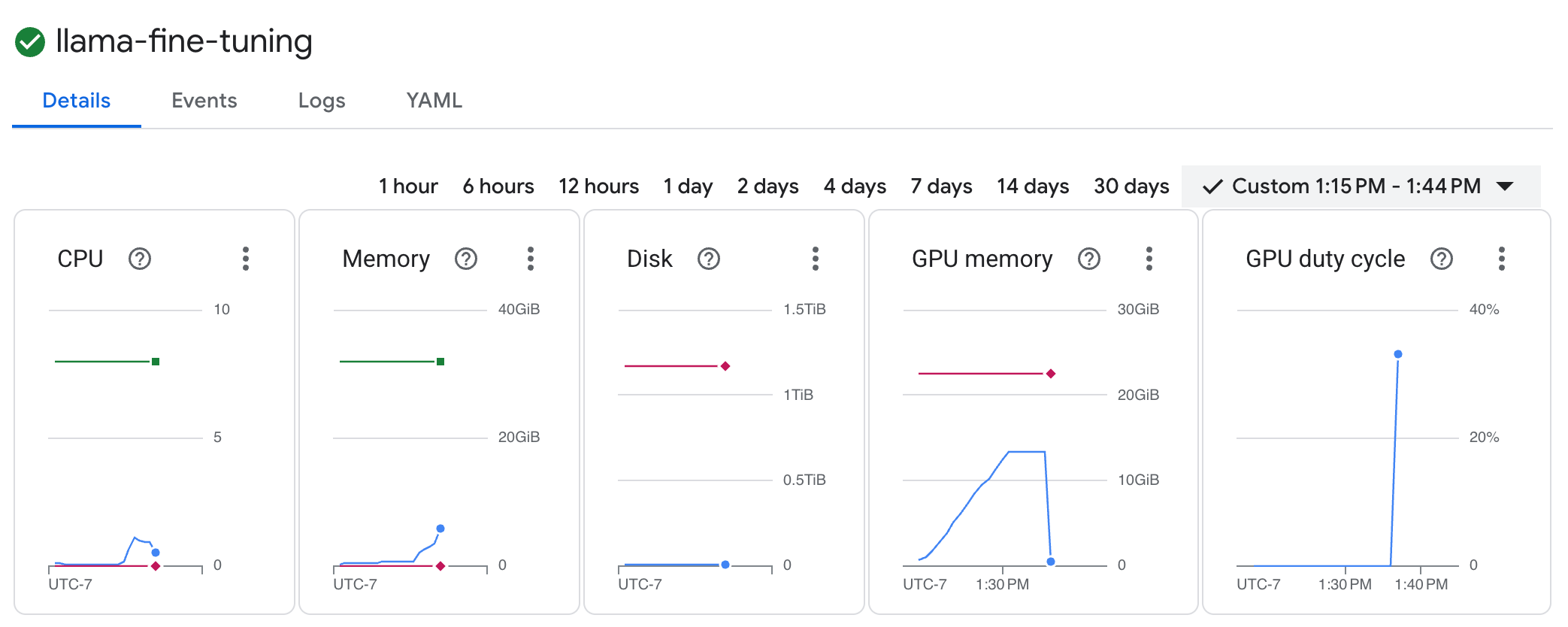
- Fai clic sulla scheda Log per visualizzare i log di addestramento. Dovresti visualizzare l'avanzamento dell'addestramento, inclusi la perdita e il tasso di apprendimento.
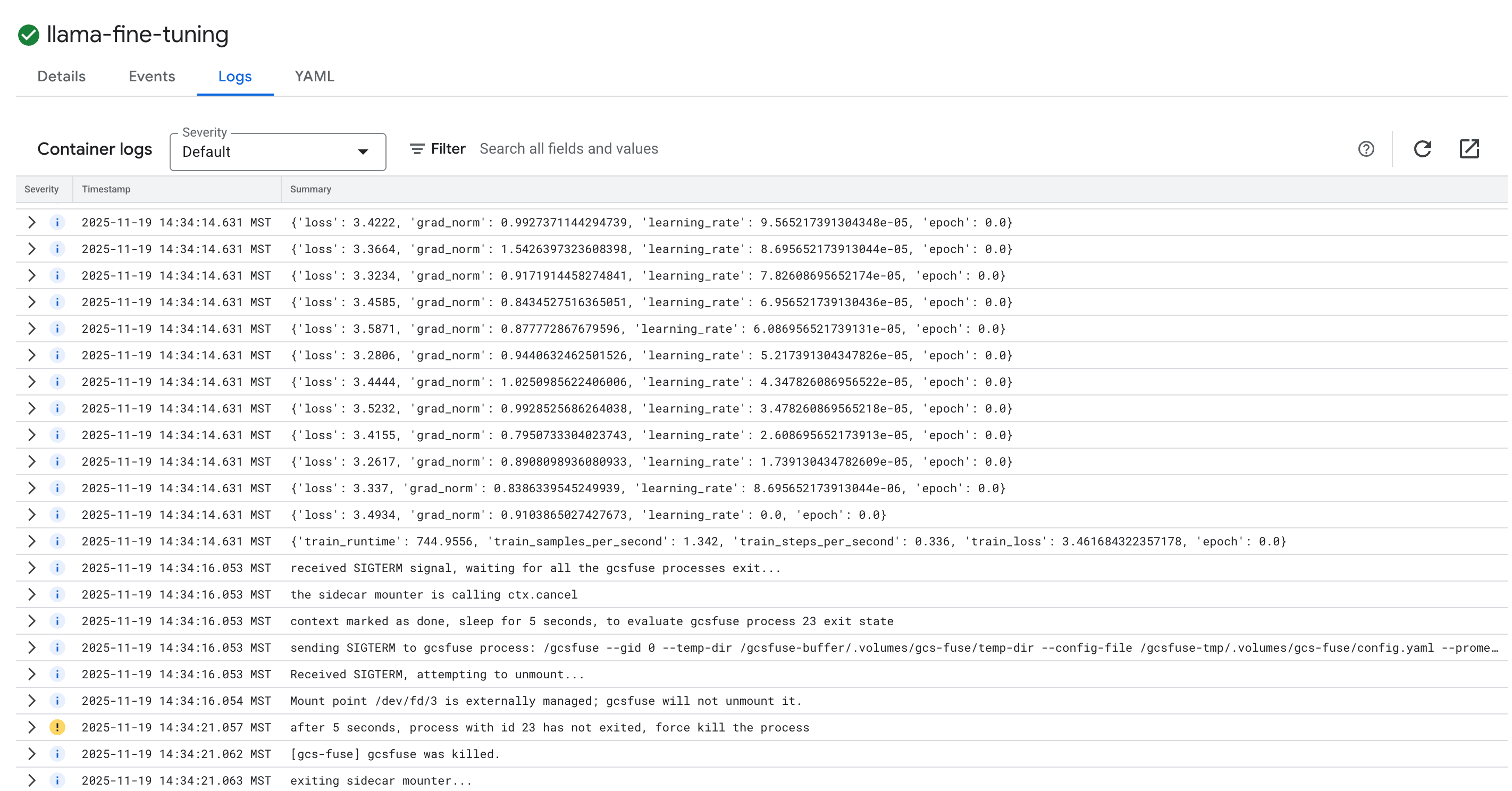
15. Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il cluster GKE
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Elimina il repository Artifact Registry
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
Elimina il bucket GCS
gcloud storage rm -r gs://${BUCKET_NAME}
16. Complimenti!
Hai eseguito il fine-tuning di un LLM open source su GKE.
Riepilogo
In questo lab imparerai a:
- È stato eseguito il provisioning di un cluster GKE con accelerazione GPU.
- Configurato Workload Identity per l'accesso sicuro ai servizi Google Cloud.
- Containerizzato un job di addestramento PyTorch utilizzando Docker e Artifact Registry.
- È stato eseguito il deployment di un job di perfezionamento utilizzando LoRA per adattare Llama 2 a un nuovo set di dati.
Passaggi successivi
- Scopri di più sull'IA su GKE.
- Esplora Vertex AI Model Garden.
- Entra nella community Google Cloud per entrare in contatto con altri sviluppatori.
Percorso di apprendimento Google Cloud
Questo lab fa parte del percorso di apprendimento AI pronta per la produzione con Google Cloud. Esplora il curriculum completo per colmare il divario tra prototipo e produzione.
Condividi i tuoi progressi con l'hashtag #ProductionReadyAI.