
1. はじめに
このラボでは、Google Kubernetes Engine(GKE)を使用して、一般的なオープンソース言語モデルである Llama 2 の完全な本番環境グレードのファインチューニング パイプラインを構築する方法を学びます。アーキテクチャの決定、一般的なトレードオフ、実際の ML オペレーション(MLOps)ワークフローを反映したコンポーネントについて学習します。
GKE クラスタをプロビジョニングし、LoRA(Low-Rank Adaptation)を使用してコンテナ化されたトレーニング パイプラインを構築し、GKE でトレーニング ジョブを実行します。
アーキテクチャの概要
本日作成する内容は次のとおりです。
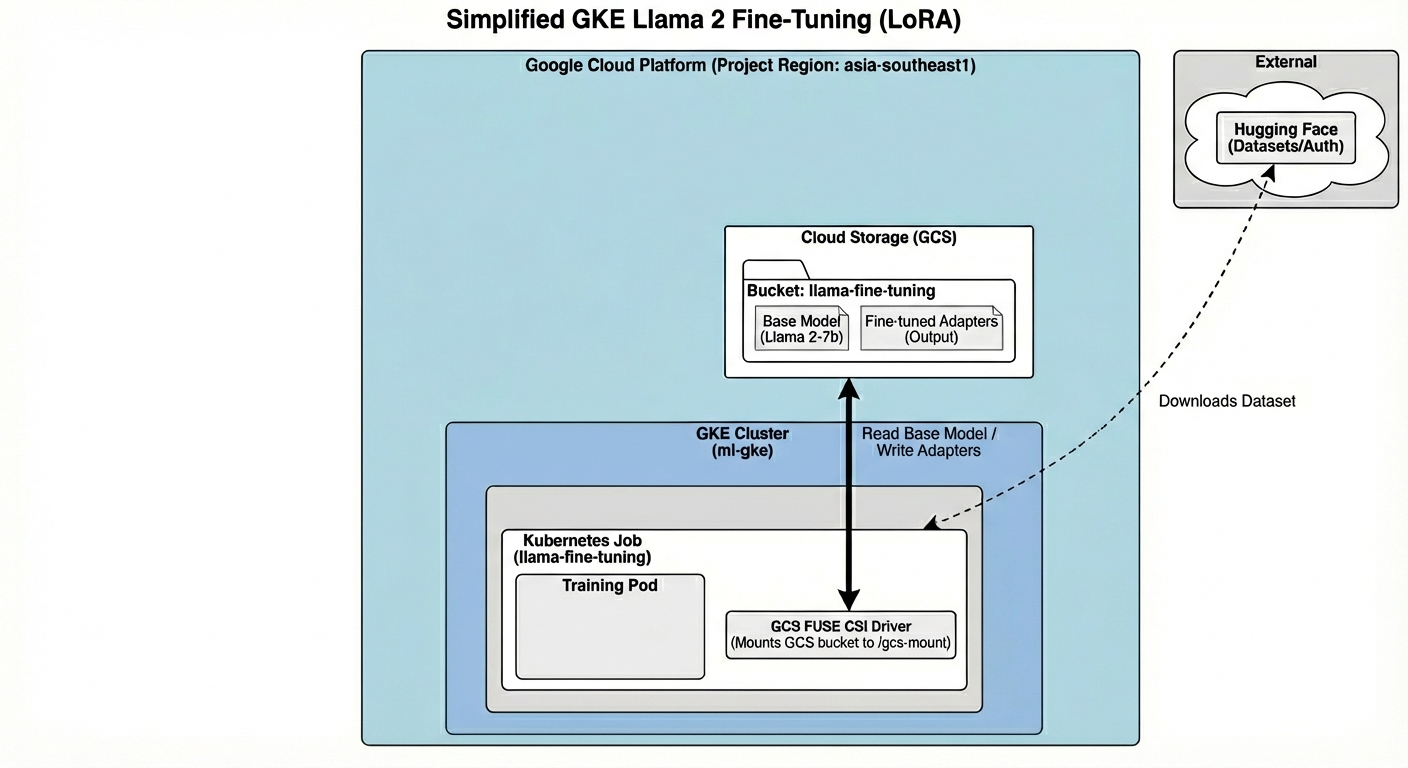
このアーキテクチャには次のものが含まれます。
- GKE クラスタ: コンピューティング リソースを管理します。
- GPU ノードプール: トレーニング用の 1 個の L4 GPU(スポット)
- GCS バケット: モデルとデータセットを保存します。
- Workload Identity: K8s と GCS 間の安全なアクセス
学習内容
- ML ワークロード用に最適化された機能を備えた GKE クラスタをプロビジョニングして構成します。
- Workload Identity を使用して、GKE から他の Google Cloud サービスへの安全なキーなしアクセスを実装します。
- Docker を使用してコンテナ化されたトレーニング パイプラインをビルドします。
- LoRA を使用したパラメータ エフィシエント ファインチューニング(PEFT)を使用して、オープンソース モデルを効率的にファインチューニングします。
2. プロジェクトの設定
Google アカウント
個人の Google アカウントをお持ちでない場合は、Google アカウントを作成する必要があります。
仕事用または学校用アカウントではなく、個人アカウントを使用します。
Google Cloud コンソールにログインする
個人の Google アカウントを使用して Google Cloud コンソールにログインします。
プロジェクトの作成(省略可)
このラボで使用する現在のプロジェクトがない場合は、こちらで新しいプロジェクトを作成します。
3. Cloud Shell エディタを開く
- このリンクをクリックすると、Cloud Shell エディタに直接移動します。
- 本日、承認を求めるメッセージがどこかの時点で表示された場合は、[承認] をクリックして続行します。
- ターミナルが画面の下部に表示されない場合は、ターミナルを開きます。
- [表示] をクリックします。
- [ターミナル] をクリックします。
- ターミナルで、次のコマンドを使用してプロジェクトを設定します。
gcloud config set project [PROJECT_ID]- 例:
gcloud config set project lab-project-id-example - プロジェクト ID が思い出せない場合は、次のコマンドでプロジェクト ID をすべて一覧表示できます。
gcloud projects list
- 例:
- 次のようなメッセージが表示されます。
Updated property [core/project].
4. API を有効にする
GKE やその他のサービスを使用するには、Google Cloud プロジェクトで必要な API を有効にする必要があります。
- ターミナルで API を有効にします。
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
API の概要
- Google Kubernetes Engine API(
container.googleapis.com)を使用すると、アプリケーションを実行する GKE クラスタを作成して管理できます。 - Artifact Registry API(
artifactregistry.googleapis.com)は、コンテナ イメージを保存するための安全なプライベート リポジトリを提供します。 - Cloud Build API(
cloudbuild.googleapis.com)は、gcloud builds submitコマンドによってクラウドでコンテナ イメージをビルドするために使用されます。 - IAM API(
iam.googleapis.com)を使用すると、Google Cloud リソースのアクセス制御と ID を管理できます。 - Compute Engine API(
compute.googleapis.com)は、Google のインフラストラクチャで実行される安全でカスタマイズ可能な仮想マシンを提供します。 - IAM Service Account Credentials API(
iamcredentials.googleapis.com)を使用すると、サービス アカウントの有効期間の短い認証情報を作成できます。 - Cloud Storage API(
storage.googleapis.com)を使用すると、クラウドにデータを保存して取得できます。ここでは、モデルとデータセットの保存に使用されます。
5. プロジェクト環境を設定する
作業ディレクトリを作成する
- ターミナルで、プロジェクトのディレクトリを作成して移動します。
mkdir llama-finetuning cd llama-finetuning
環境変数を設定する
- ターミナルで、環境変数を保存する
env.shという名前のファイルを作成します。これにより、セッションが切断された場合に簡単に再読み込みできます。cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - ファイルを読み込んで、現在のセッションに変数を読み込みます。
source env.sh
6. GKE クラスタをプロビジョニングする
- ターミナルで、デフォルトのノードプールを使用して GKE クラスタを作成します。所要時間は約 5 分です。
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - 次に、GPU ノードプールをクラスタに追加します。このノードプールは、モデルのトレーニングに使用されます。
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - 最後に、新しいクラスタの認証情報を取得し、接続できることを確認します。
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Hugging Face へのアクセスを構成する
インフラストラクチャの準備ができたら、モデルとデータにアクセスするために必要な認証情報をプロジェクトに提供する必要があります。このタスクでは、まず Hugging Face トークンを取得します。
Hugging Face トークンを取得する
- Hugging Face アカウントをお持ちでない場合は、新しいブラウザタブで huggingface.co/join に移動し、登録プロセスを完了します。
- 登録してログインしたら、huggingface.co/meta-llama/Llama-2-7b-hf に移動します。
- ライセンス条項を読み、ボタンをクリックして同意します。
- huggingface.co/settings/tokens にある Hugging Face アクセス トークンのページに移動します。
- [新しいトークン] をクリックします。
- [ロール] で [読み取り] を選択します。
- [名前] に、わかりやすい名前(例: finetuning-lab)を入力します。
- [トークンを作成] をクリックします。
- 生成されたトークンをクリップボードにコピーします。次のステップでこれが必要になります。
環境変数を更新する
次に、Hugging Face トークンと GCS バケットの名前を env.sh ファイルに追加します。[your-hf-token] は、コピーしたトークンに置き換えます。
- ターミナルで、新しい変数を
env.shに追加して再読み込みします。cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. Workload Identity を構成する
次に、Workload Identity を設定します。これは、静的サービス アカウント キーを管理することなく、GKE で実行されているアプリケーションが Google Cloud サービスにアクセスできるようにする推奨の方法です。詳細については、Workload Identity のドキュメントをご覧ください。
- まず、Google サービス アカウント(GSA)を作成します。ターミナルで、次のコマンドを実行します。
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - 次に、GCS バケットを作成し、GSA にアクセス権限を付与します。
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - 次に、Kubernetes サービス アカウント(KSA)を作成します。
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - 最後に、GSA と KSA の間に IAM ポリシー バインディングを作成します。
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. ベースモデルをステージングする
本番環境の ML パイプラインでは、Llama 2(約 13 GB)などの大規模なモデルは、通常、トレーニング中にダウンロードされるのではなく、Cloud Storage に事前にステージングされます。このアプローチにより、信頼性が向上し、アクセスが高速化され、ネットワークの問題を回避できます。Google Cloud では、一般的なモデルの事前ダウンロード バージョンがパブリック GCS バケットに用意されています。このラボでは、これらのモデルを使用します。
- まず、Google 提供の Llama 2 モデルにアクセスできることを確認します。
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ gcloud storageコマンドを使用して、この公開バケットから独自のプロジェクトのバケットに Llama 2 モデルをコピーします。この転送では Google の高速内部ネットワークが使用されるため、1 ~ 2 分で完了します。gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/- バケットの内容を一覧表示して、モデルファイルが正しくコピーされたことを確認します。
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. トレーニング コードを準備する
次に、モデルをファインチューニングするコンテナ化されたアプリケーションを構築します。このタスクでは、LoRA(Low-Rank Adaptation)を使用します。これは、モデル全体ではなく小さな「アダプタ」レイヤのみをトレーニングすることで、メモリ要件を大幅に削減するパラメータ エフィシエント ファインチューニング(PEFT)手法です。
次に、トレーニング パイプライン用の Python スクリプトを作成します。
- ターミナルで、次のコマンドを実行して
train.pyファイルを開きます。cloudshell edit train.py - 次のコードを
train.pyファイルに貼り付けます。
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. トレーニング コードについて
train.py スクリプトは、ファインチューニング プロセスをオーケストレートします。主なコンポーネントを詳しく見ていきましょう。
構成
スクリプトは LoraConfig を使用して、低ランク適応の設定を定義します。LoRA は、トレーニング可能なパラメータの数を大幅に削減するため、小規模な GPU で大規模モデルをファインチューニングできます。
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
データセットの準備
prepare_dataset 関数は、「American Stories」データセットを読み込み、トークン化されたチャンクに処理します。カスタム SimpleTextDataset を使用して、入力テンソルを効率的に処理します。
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
電車
train_model 関数は、このワークロード用に最適化された特定の引数を使用して Trainer を設定します。主なパラメータは次のとおりです。
gradient_accumulation_steps: メモリ使用量を増やさずに、より大きなバッチサイズをシミュレートするのに役立ちます。fp16=True: 混合精度トレーニングを使用して、メモリを削減し、速度を向上させます。gradient_checkpointing=True: アクティベーションを保存する代わりに、バックワード パス中に再計算することでメモリを節約します。optim="adamw_torch": PyTorch の標準の AdamW オプティマイザー実装を使用します。
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
推論
run_inference 関数は、サンプル プロンプトを使用してファインチューニングされたモデルの簡単なテストを実行します。これにより、モデルが評価モードになり、アダプタが正しく動作していることを確認するためのテキストが生成されます。
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. アプリケーションをコンテナ化する
次に、Docker を使用してトレーニング コンテナ イメージをビルドし、Google Artifact Registry に push します。
- ターミナルで、次のコマンドを実行して
Dockerfileファイルを開きます。cloudshell edit Dockerfile - 次のコードを
Dockerfileファイルに貼り付けます。
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
コンテナをビルドして push する
- Artifact Registry リポジトリを作成します。
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Cloud Build を使用してイメージをビルドして push します。
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. ファインチューニング ジョブをデプロイする
- ファインチューニング ジョブを開始する Kubernetes Job マニフェストを作成します。ターミナルで、次のコマンドを実行します。
cloudshell edit training_job.yaml - 次のコードを
training_job.yamlファイルに貼り付けます。
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- 最後に、Kubernetes ジョブ マニフェストを適用して、GKE クラスタでファインチューニング ジョブを開始します。
envsubst < training_job.yaml | kubectl apply -f -
14. トレーニング ジョブをモニタリングする
トレーニング ジョブの進行状況は、Google Cloud コンソールでモニタリングできます。
- [Kubernetes Engine] > [ワークロード] ページに移動します。
GKE ワークロードを表示する llama-fine-tuningジョブをクリックして、詳細を表示します。- デフォルトでは、[詳細] タブが表示されます。GPU 使用率の指標は、[リソース] セクションで確認できます。
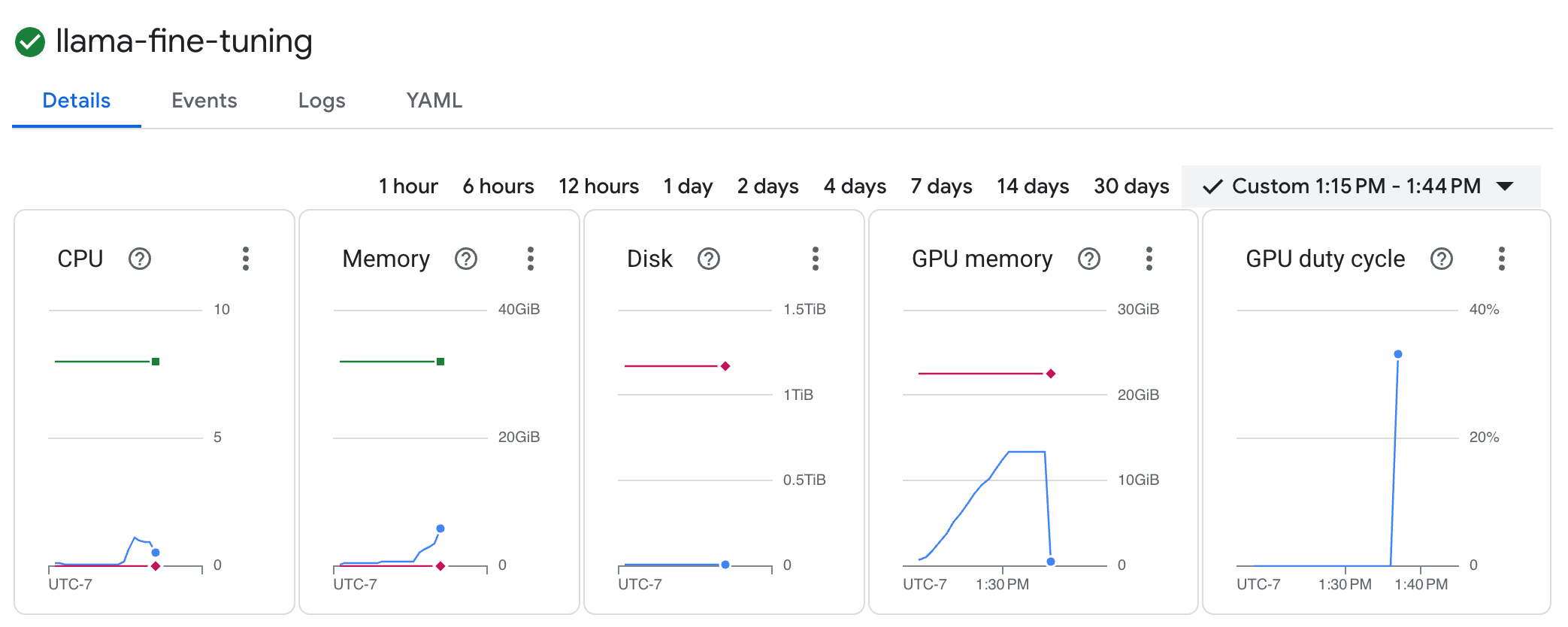
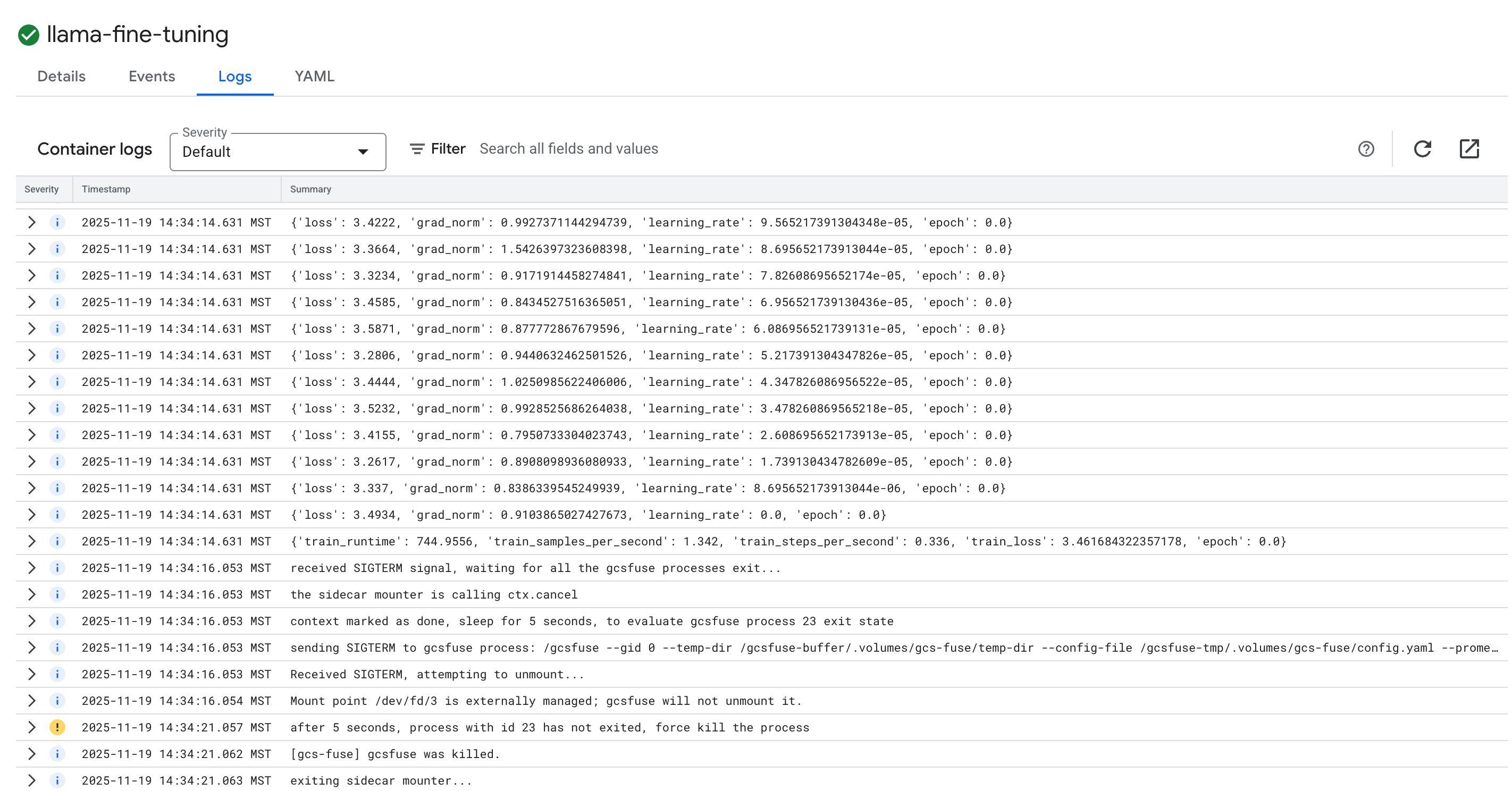
- [ログ] タブをクリックして、トレーニング ログを表示します。損失や学習率など、トレーニングの進行状況が表示されます。
15. クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
GKE クラスタの削除
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Artifact Registry リポジトリを削除する
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
GCS バケットを削除する
gcloud storage rm -r gs://${BUCKET_NAME}
16. 完了
GKE でオープンソースの LLM をファインチューニングできました。
内容のまとめ
このラボの内容:
- GPU アクセラレーションを使用して GKE クラスタをプロビジョニングした。
- Google Cloud サービスへの安全なアクセス用に Workload Identity を構成しました。
- Docker と Artifact Registry を使用して PyTorch トレーニング ジョブをコンテナ化しました。
- LoRA を使用してファインチューニング ジョブをデプロイし、Llama 2 を新しいデータセットに適応させました。
次のステップ
- GKE での AI の詳細を確認する。
- Vertex AI Model Garden を確認する。
- Google Cloud コミュニティに参加して、他のデベロッパーと交流しましょう。
Google Cloud 学習プログラム
このラボは、「Google Cloud でのプロダクション レディな AI」学習プログラムの一部です。カリキュラム全体を確認して、プロトタイプから本番環境への移行をスムーズに進めましょう。
ハッシュタグ #ProductionReadyAI を使用して、進捗状況を共有しましょう。