
1. 소개
이 실습에서는 Google Kubernetes Engine (GKE)를 사용하여 인기 있는 오픈소스 언어 모델인 Llama 2를 위한 완전한 프로덕션 등급 미세 조정 파이프라인을 빌드하는 방법을 알아봅니다. 실제 머신러닝 운영 (MLOps) 워크플로를 반영하는 아키텍처 결정, 일반적인 절충안, 구성요소에 대해 알아봅니다.
GKE 클러스터를 프로비저닝하고, LoRA (Low-Rank Adaptation)를 사용하여 컨테이너화된 학습 파이프라인을 빌드하고, GKE에서 학습 작업을 실행합니다.
아키텍처 개요
오늘 빌드할 항목은 다음과 같습니다.
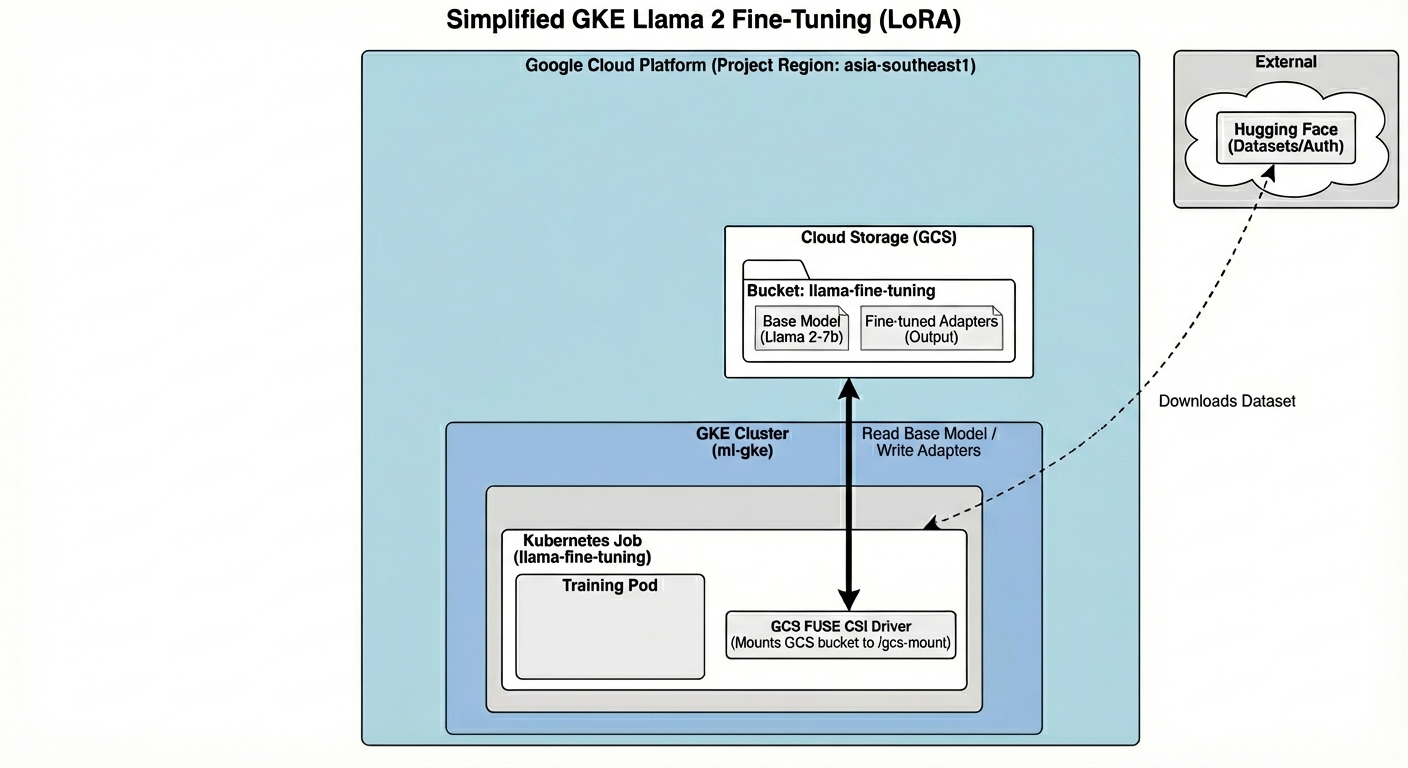
아키텍처에는 다음이 포함됩니다.
- GKE 클러스터: 컴퓨팅 리소스를 관리합니다.
- GPU 노드 풀: 학습용 L4 GPU 1개 (스팟)
- GCS 버킷: 모델 및 데이터 세트를 저장합니다.
- 워크로드 아이덴티티: K8s와 GCS 간의 보안 액세스
학습할 내용
- ML 워크로드에 최적화된 기능으로 GKE 클러스터를 프로비저닝하고 구성합니다.
- 워크로드 아이덴티티를 사용하여 GKE에서 다른 Google Cloud 서비스로의 안전한 키리스 액세스를 구현합니다.
- Docker를 사용하여 컨테이너화된 학습 파이프라인을 빌드합니다.
- LoRA를 사용한 Parameter-Efficient Fine-Tuning (PEFT)을 사용하여 오픈소스 모델을 효율적으로 미세 조정합니다.
2. 프로젝트 설정
Google 계정
아직 개인 Google 계정이 없다면 Google 계정을 만들어야 합니다.
직장 또는 학교 계정 대신 개인 계정을 사용합니다.
Google Cloud 콘솔에 로그인
개인 Google 계정을 사용하여 Google Cloud 콘솔에 로그인합니다.
프로젝트 만들기(선택사항)
이 실습에 사용할 현재 프로젝트가 없는 경우 여기에서 새 프로젝트를 만드세요.
3. Cloud Shell 편집기 열기
- 이 링크를 클릭하여 Cloud Shell 편집기로 바로 이동합니다.
- 오늘 언제든지 승인하라는 메시지가 표시되면 승인을 클릭하여 계속합니다.
- 터미널이 화면 하단에 표시되지 않으면 다음 단계에 따라 엽니다.
- 보기를 클릭합니다.
- 터미널을 클릭합니다.
- 터미널에서 다음 명령어를 사용하여 프로젝트를 설정합니다.
gcloud config set project [PROJECT_ID]- 예:
gcloud config set project lab-project-id-example - 프로젝트 ID가 기억나지 않는 경우 다음을 사용하여 모든 프로젝트 ID를 나열할 수 있습니다.
gcloud projects list
- 예:
- 다음 메시지가 표시되어야 합니다.
Updated property [core/project].
4. API 사용 설정
GKE 및 기타 서비스를 사용하려면 Google Cloud 프로젝트에서 필요한 API를 사용 설정해야 합니다.
- 터미널에서 API를 사용 설정합니다.
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
API 소개
- Google Kubernetes Engine API (
container.googleapis.com)를 사용하면 애플리케이션을 실행하는 GKE 클러스터를 만들고 관리할 수 있습니다. - Artifact Registry API (
artifactregistry.googleapis.com)는 컨테이너 이미지를 저장할 수 있는 안전한 비공개 저장소를 제공합니다. - Cloud Build API (
cloudbuild.googleapis.com)는gcloud builds submit명령어가 클라우드에서 컨테이너 이미지를 빌드하는 데 사용됩니다. - IAM API (
iam.googleapis.com)를 사용하면 Google Cloud 리소스의 액세스 제어 및 ID를 관리할 수 있습니다. - Compute Engine API (
compute.googleapis.com)는 Google 인프라에서 실행되는 안전하고 맞춤설정 가능한 가상 머신을 제공합니다. - IAM Service Account Credentials API (
iamcredentials.googleapis.com)를 사용하면 서비스 계정에 대한 단기 사용자 인증 정보를 만들 수 있습니다. - Cloud Storage API (
storage.googleapis.com)를 사용하면 클라우드에 데이터를 저장하고 검색할 수 있으며, 여기서는 모델 및 데이터 세트 저장에 사용됩니다.
5. 프로젝트 환경 설정
작업 디렉터리 만들기
- 터미널에서 프로젝트의 디렉터리를 만들고 해당 디렉터리로 이동합니다.
mkdir llama-finetuning cd llama-finetuning
환경 변수 설정
- 터미널에서 환경 변수를 저장할
env.sh파일을 만듭니다. 이렇게 하면 세션 연결이 끊어지더라도 쉽게 다시 로드할 수 있습니다.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - 파일을 소싱하여 현재 세션에 변수를 로드합니다.
source env.sh
6. GKE 클러스터 프로비저닝
- 터미널에서 기본 노드 풀을 사용하여 GKE 클러스터를 만듭니다. 5분 정도 걸립니다.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - 그런 다음 클러스터에 GPU 노드 풀을 추가합니다. 이 노드 풀은 모델을 학습시키는 데 사용됩니다.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - 마지막으로 새 클러스터의 사용자 인증 정보를 가져와서 연결할 수 있는지 확인합니다.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Hugging Face 액세스 구성
인프라가 준비되었으므로 이제 모델과 데이터에 액세스하는 데 필요한 사용자 인증 정보를 프로젝트에 제공해야 합니다. 이 작업에서는 먼저 Hugging Face 토큰을 가져옵니다.
Hugging Face 토큰 가져오기
- Hugging Face 계정이 없는 경우 새 브라우저 탭에서 huggingface.co/join으로 이동하여 등록 절차를 완료합니다.
- 등록하고 로그인한 후 huggingface.co/meta-llama/Llama-2-7b-hf로 이동합니다.
- 라이선스 약관을 읽고 버튼을 클릭하여 동의합니다.
- huggingface.co/settings/tokens에서 Hugging Face 액세스 토큰 페이지로 이동합니다.
- 새 토큰을 클릭합니다.
- 역할에서 읽기를 선택합니다.
- 이름에 설명이 포함된 이름을 입력합니다 (예: finetuning-lab).
- 토큰 만들기를 클릭합니다.
- 클립보드에 생성된 토큰을 복사합니다. 다음 단계에 이 항목이 필요합니다.
환경 변수 업데이트
이제 env.sh 파일에 Hugging Face 토큰과 GCS 버킷 이름을 추가해 보겠습니다. [your-hf-token]을 방금 복사한 토큰으로 바꿉니다.
- 터미널에서 새 변수를
env.sh에 추가하고 다시 로드합니다.cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. 워크로드 아이덴티티 구성
다음으로, 정적 서비스 계정 키를 관리할 필요 없이 GKE에서 실행되는 애플리케이션이 Google Cloud 서비스에 액세스할 수 있도록 권장되는 방법인 워크로드 아이덴티티를 설정합니다. 자세한 내용은 워크로드 아이덴티티 문서를 참고하세요.
- 먼저 Google 서비스 계정 (GSA)을 만듭니다. 터미널에서 다음을 실행합니다.
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - 다음으로 GCS 버킷을 만들고 GSA에 액세스 권한을 부여합니다.
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - 이제 Kubernetes 서비스 계정 (KSA)을 만듭니다.
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - 마지막으로 GSA와 KSA 간에 IAM 정책 바인딩을 만듭니다.
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. 기본 모델 스테이징
프로덕션 ML 파이프라인에서는 일반적으로 학습 중에 다운로드하는 대신 Llama 2 (~13GB)와 같은 대규모 모델이 Cloud Storage에 사전 스테이징됩니다. 이 접근 방식은 안정성을 높이고 액세스 속도를 높이며 네트워크 문제를 방지합니다. Google Cloud는 이 실습에 사용할 인기 모델의 사전 다운로드된 버전을 공개 GCS 버킷에 제공합니다.
- 먼저 Google에서 제공하는 Llama 2 모델에 액세스할 수 있는지 확인합니다.
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ gcloud storage명령어를 사용하여 이 공개 버킷에서 자체 프로젝트의 버킷으로 Llama 2 모델을 복사합니다. 이 전송은 Google의 고속 내부 네트워크를 사용하며 1~2분 정도면 완료됩니다.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/- 버킷의 콘텐츠를 나열하여 모델 파일이 올바르게 복사되었는지 확인합니다.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. 학습 코드 준비
이제 모델을 미세 조정하는 컨테이너화된 애플리케이션을 빌드합니다. 이 작업에서는 전체 모델 대신 작은 '어댑터' 레이어만 학습하여 메모리 요구사항을 크게 줄이는 파라미터 효율적 세부 조정 (PEFT) 기법인 LoRA (Low-Rank Adaptation)를 사용합니다.
이제 학습 파이프라인의 Python 스크립트를 만듭니다.
- 터미널에서 다음 명령어를 실행하여
train.py파일을 엽니다.cloudshell edit train.py - 다음 코드를
train.py파일에 붙여 넣습니다.
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. 학습 코드 이해
train.py 스크립트는 미세 조정 프로세스를 조정합니다. 주요 구성요소를 살펴보겠습니다.
구성
스크립트는 LoraConfig를 사용하여 하위 순위 적응 설정을 정의합니다. LoRA는 학습 가능한 파라미터 수를 크게 줄여 더 작은 GPU에서 대규모 모델을 미세 조정할 수 있습니다.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
데이터 세트 준비
prepare_dataset 함수는 'American Stories' 데이터 세트를 로드하고 토큰화된 청크로 처리합니다. 입력 텐서를 효율적으로 처리하기 위해 맞춤 SimpleTextDataset를 사용합니다.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
기차
train_model 함수는 이 워크로드에 최적화된 특정 인수로 Trainer을 설정합니다. 주요 매개변수는 다음과 같습니다.
gradient_accumulation_steps: 메모리 사용량을 늘리지 않고 더 큰 배치 크기를 시뮬레이션하는 데 도움이 됩니다.fp16=True: 혼합 정밀도 학습을 사용하여 메모리를 줄이고 속도를 높입니다.gradient_checkpointing=True: 활성화를 저장하는 대신 역방향 전달 중에 다시 계산하여 메모리를 절약합니다.optim="adamw_torch": PyTorch의 표준 AdamW 옵티마이저 구현을 사용합니다.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
추론
run_inference 함수는 샘플 프롬프트를 사용하여 미세 조정된 모델을 빠르게 테스트합니다. 모델이 평가 모드에 있는지 확인하고 어댑터가 올바르게 작동하는지 확인하기 위해 텍스트를 생성합니다.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. 애플리케이션 컨테이너화
이제 Docker를 사용하여 학습 컨테이너 이미지를 빌드하고 Google Artifact Registry로 푸시합니다.
- 터미널에서 다음 명령어를 실행하여
Dockerfile파일을 엽니다.cloudshell edit Dockerfile - 다음 코드를
Dockerfile파일에 붙여 넣습니다.
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
컨테이너 빌드 및 푸시
- Artifact Registry 저장소를 만듭니다.
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Cloud Build를 사용하여 이미지를 빌드하고 푸시합니다.
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. 미세 조정 작업 배포
- 파인 튜닝 작업을 시작하는 Kubernetes 작업 매니페스트를 만듭니다. 터미널에서 다음을 실행합니다.
cloudshell edit training_job.yaml - 다음 코드를
training_job.yaml파일에 붙여 넣습니다.
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- 마지막으로 Kubernetes 작업 매니페스트를 적용하여 GKE 클러스터에서 파인 튜닝 작업을 시작합니다.
envsubst < training_job.yaml | kubectl apply -f -
14. 학습 작업 모니터링
Google Cloud 콘솔에서 학습 작업의 진행 상황을 모니터링할 수 있습니다.
- Kubernetes Engine > 워크로드 페이지로 이동합니다.
GKE 워크로드 보기 llama-fine-tuning작업을 클릭하여 세부정보를 확인합니다.- 세부정보 탭이 기본적으로 표시됩니다. 리소스 섹션에서 GPU 사용률 측정항목을 확인할 수 있습니다.
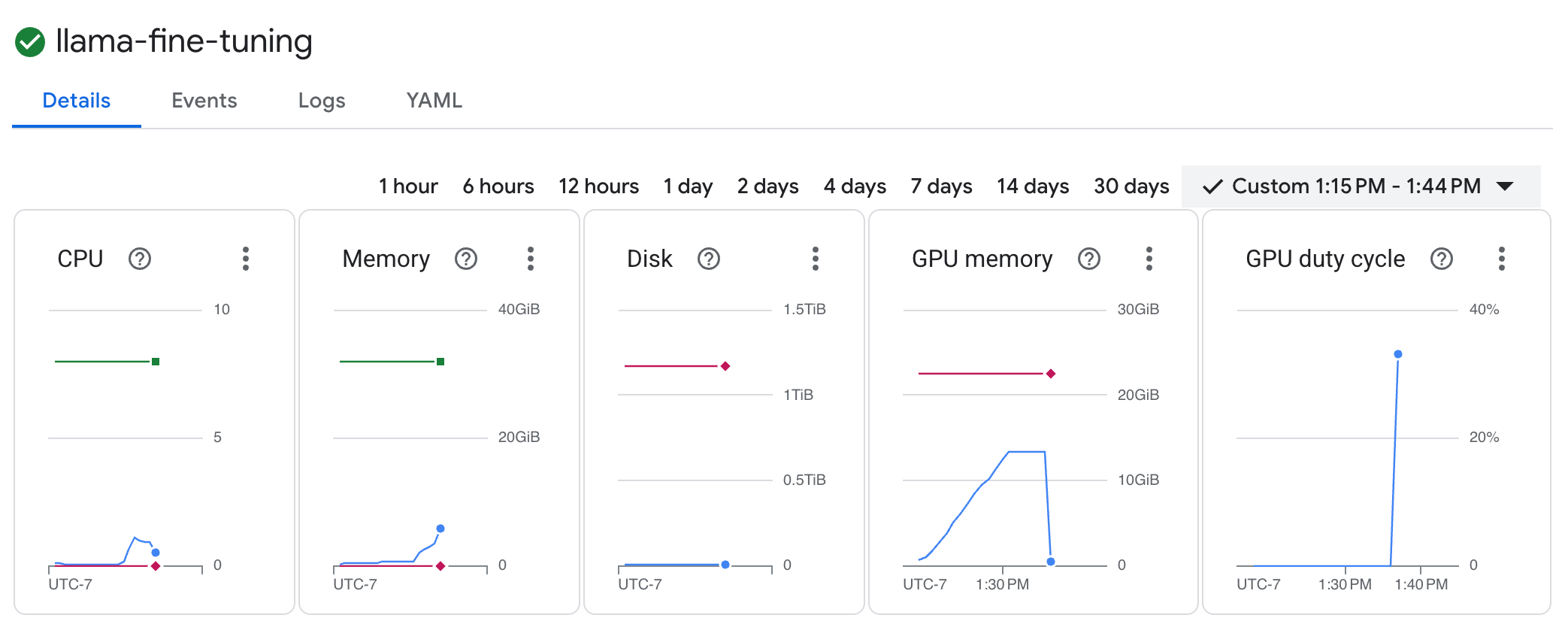
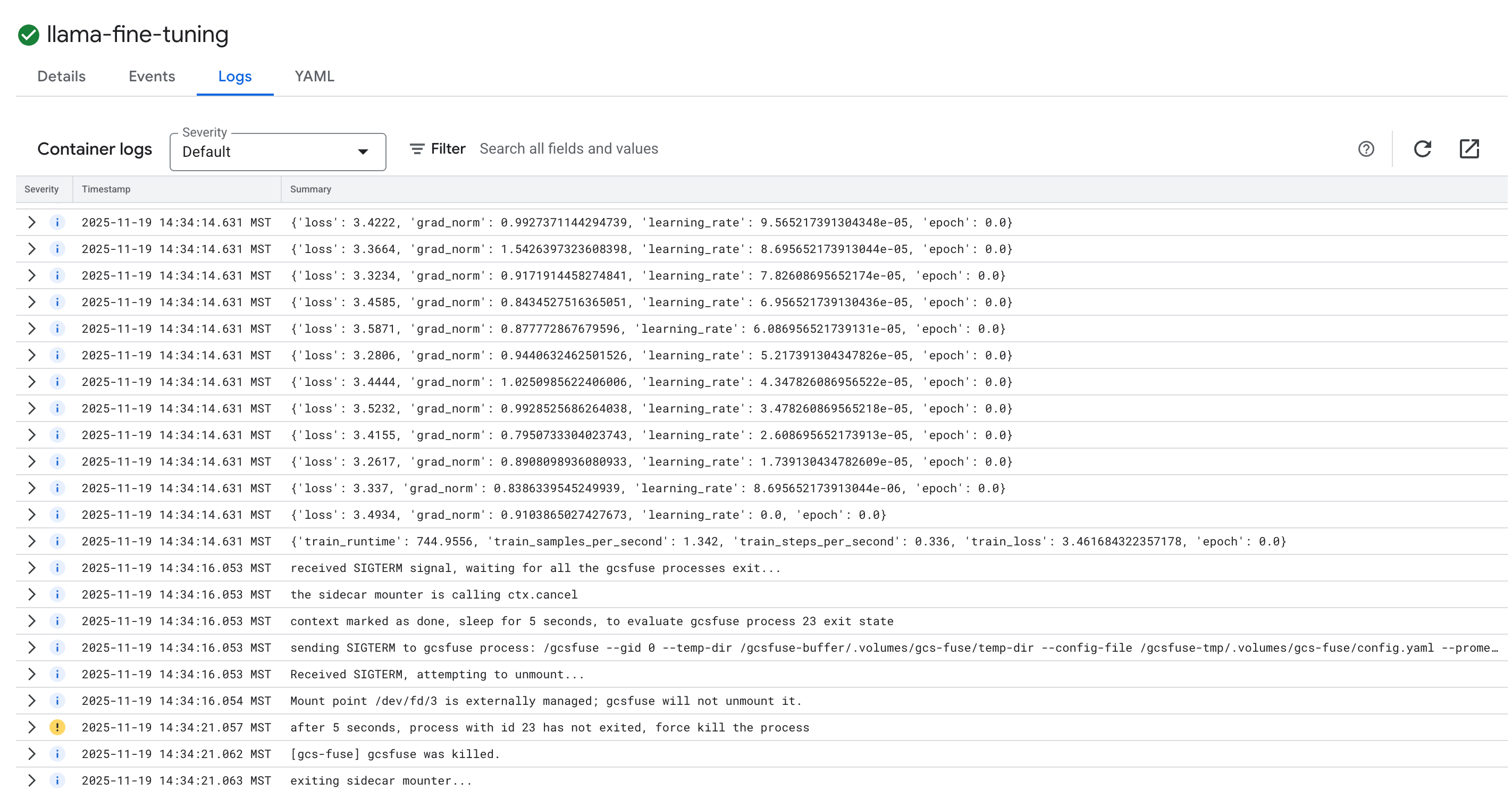
- 로그 탭을 클릭하여 학습 로그를 확인합니다. 손실 및 학습률을 비롯한 학습 진행 상황이 표시됩니다.
15. 삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
GKE 클러스터 삭제
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Artifact Registry 저장소 삭제
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
GCS 버킷 삭제
gcloud storage rm -r gs://${BUCKET_NAME}
16. 축하합니다.
GKE에서 오픈소스 LLM을 미세 조정했습니다.
요약
이 실습에서 학습할 내용은 다음과 같습니다.
- GPU 가속을 사용하여 GKE 클러스터를 프로비저닝했습니다.
- Google Cloud 서비스에 안전하게 액세스할 수 있도록 워크로드 아이덴티티를 구성했습니다.
- Docker 및 Artifact Registry를 사용하여 PyTorch 학습 작업을 컨테이너화했습니다.
- LoRA를 사용하여 Llama 2를 새 데이터 세트에 적응시키기 위한 미세 조정 작업을 배포했습니다.
다음 단계
- GKE의 AI 자세히 알아보기
- Vertex AI Model Garden을 살펴봅니다.
- Google Cloud 커뮤니티에 가입하여 다른 개발자와 소통하세요.
Google Cloud 학습 과정
이 실습은 Google Cloud를 사용한 프로덕션 레디 AI 학습 과정의 일부입니다. 전체 커리큘럼을 살펴보고 프로토타입에서 프로덕션으로 전환하세요.
#ProductionReadyAI 해시태그를 사용하여 진행 상황을 공유하세요.