
1. Wprowadzenie
W tym module nauczysz się tworzyć kompletny potok dostrajania w wersji produkcyjnej dla Lamy 2, popularnego modelu językowego open source, przy użyciu Google Kubernetes Engine (GKE). Dowiesz się więcej o decyzjach architektonicznych, typowych kompromisach i komponentach, które odzwierciedlają rzeczywiste przepływy pracy związane z MLOps.
Utworzysz klaster GKE, zbudujesz skonteneryzowany potok trenowania za pomocą adaptacji o niskim rzędzie (LoRA) i uruchomisz zadanie trenowania w GKE.
Omówienie architektury
Oto co dziś stworzymy:
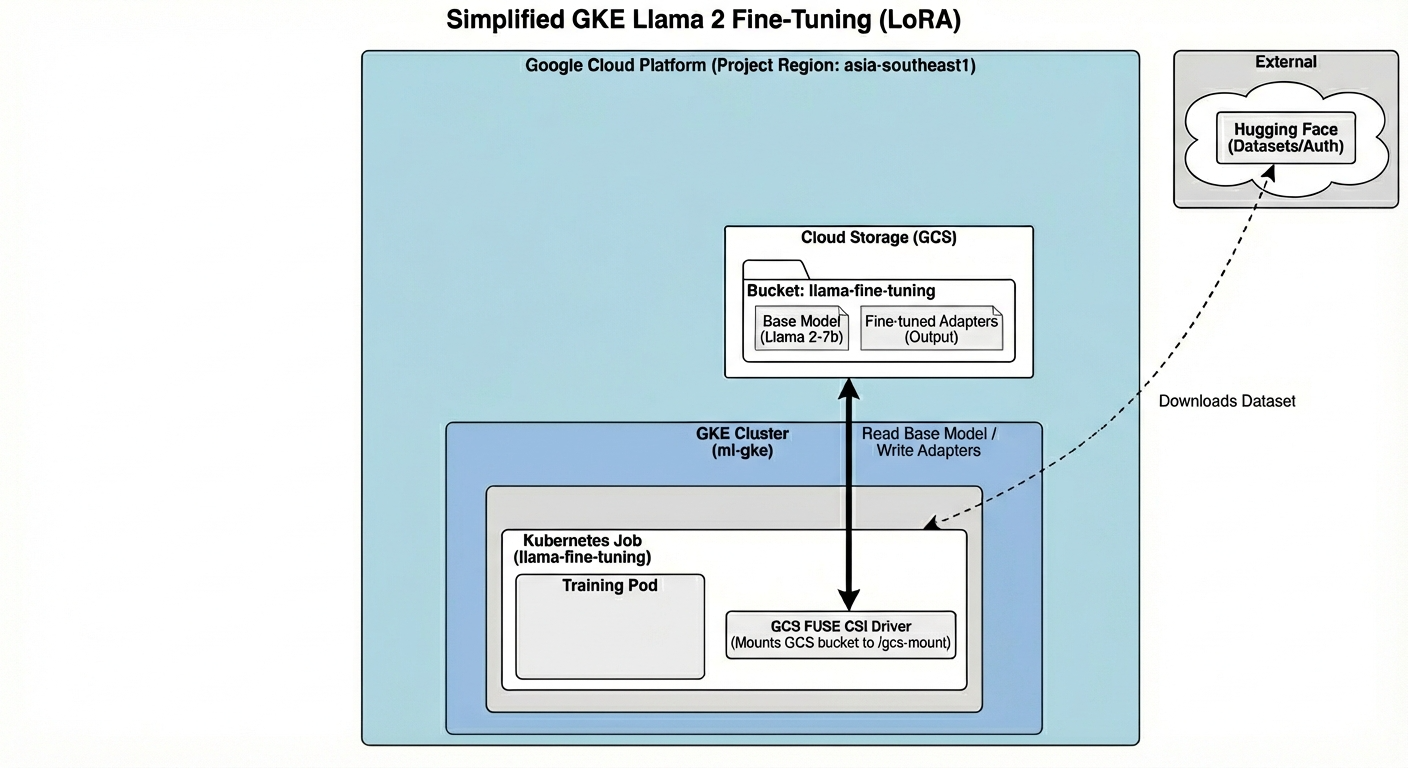
Architektura obejmuje:
- Klaster GKE: zarządza zasobami obliczeniowymi.
- Pula węzłów GPU: 1 procesor graficzny L4 (Spot) do trenowania
- Zasobnik GCS: przechowuje modele i zbiory danych.
- Workload Identity: bezpieczny dostęp między K8s a GCS
Czego się nauczysz
- Aprowizuj i konfiguruj klaster GKE z funkcjami zoptymalizowanymi pod kątem zbiorów zadań ML.
- Wdrażanie bezpiecznego, bezkluczowego dostępu z GKE do innych usług Google Cloud za pomocą Workload Identity.
- Utwórz skonteneryzowany potok trenowania za pomocą Dockera.
- Wydajnie dostrajaj model open source za pomocą metody PEFT (dostrajanie konkretnych parametrów) z użyciem LoRA.
2. Konfigurowanie projektu
Konto Google
Jeśli nie masz jeszcze osobistego konta Google, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
Logowanie się w konsoli Google Cloud
Zaloguj się w konsoli Google Cloud, korzystając z osobistego konta Google.
Tworzenie projektu (opcjonalnie)
Jeśli nie masz bieżącego projektu, którego chcesz użyć w tym ćwiczeniu, utwórz nowy projekt.
3. Otwórz edytor Cloud Shell
- Kliknij ten link, aby przejść bezpośrednio do edytora Cloud Shell
- Jeśli w dowolnym momencie pojawi się prośba o autoryzację, kliknij Autoryzuj, aby kontynuować.
- Jeśli terminal nie pojawi się u dołu ekranu, otwórz go:
- Kliknij Wyświetl.
- Kliknij Terminal
 .
.
- W terminalu ustaw projekt za pomocą tego polecenia:
gcloud config set project [PROJECT_ID]- Przykład:
gcloud config set project lab-project-id-example - Jeśli nie pamiętasz identyfikatora projektu, możesz wyświetlić listę wszystkich identyfikatorów projektów za pomocą tego polecenia:
gcloud projects list
- Przykład:
- Powinien wyświetlić się ten komunikat:
Updated property [core/project].
4. Włącz interfejsy API
Aby korzystać z GKE i innych usług, musisz włączyć w projekcie Google Cloud niezbędne interfejsy API.
- W terminalu włącz interfejsy API:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
Przedstawiamy interfejsy API
- Google Kubernetes Engine API (
container.googleapis.com) umożliwia tworzenie klastra GKE, w którym działa aplikacja, i zarządzanie nim. - Artifact Registry API (
artifactregistry.googleapis.com) udostępnia bezpieczne, prywatne repozytorium do przechowywania obrazów kontenerów. - Cloud Build API (
cloudbuild.googleapis.com) jest używany przez poleceniegcloud builds submitdo tworzenia obrazu kontenera w chmurze. - IAM API (
iam.googleapis.com) umożliwia zarządzanie kontrolą dostępu i tożsamością w przypadku zasobów Google Cloud. - Interfejs Compute Engine API (
compute.googleapis.com) udostępnia bezpieczne i konfigurowalne maszyny wirtualne działające w infrastrukturze Google. - IAM Service Account Credentials API (
iamcredentials.googleapis.com) umożliwia tworzenie krótkotrwałych danych logowania do kont usługi. - Cloud Storage API (
storage.googleapis.com) umożliwia przechowywanie i pobieranie danych w chmurze. W tym przypadku służy do przechowywania modeli i zbiorów danych.
5. Konfigurowanie środowiska projektu
Tworzenie katalogu roboczego
- W terminalu utwórz katalog dla swojego projektu i przejdź do niego.
mkdir llama-finetuning cd llama-finetuning
Konfigurowanie zmiennych środowiskowych
- W terminalu utwórz plik o nazwie
env.sh, w którym będą przechowywane zmienne środowiskowe. Dzięki temu możesz je łatwo ponownie wczytać, jeśli sesja zostanie przerwana.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - Wczytaj plik, aby załadować zmienne do bieżącej sesji:
source env.sh
6. Udostępnianie klastra GKE
- W terminalu utwórz klaster GKE z domyślną pulą węzłów. Potrwa to około 5 minut.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - Następnie dodaj do klastra pulę węzłów GPU. Ta pula węzłów będzie używana do trenowania modelu.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - Na koniec uzyskaj dane logowania do nowego klastra i sprawdź, czy możesz się z nim połączyć.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Konfigurowanie dostępu do Hugging Face
Gdy infrastruktura będzie gotowa, musisz podać w projekcie niezbędne dane logowania, aby uzyskać dostęp do modelu i danych. W tym zadaniu najpierw uzyskasz token Hugging Face.
Pobieranie tokena Hugging Face
- Jeśli nie masz konta Hugging Face, otwórz huggingface.co/join w nowej karcie przeglądarki i zarejestruj się.
- Po zarejestrowaniu się i zalogowaniu otwórz stronę huggingface.co/meta-llama/Llama-2-7b-hf.
- Przeczytaj warunki licencji i kliknij przycisk, aby je zaakceptować.
- Otwórz stronę tokenów dostępu Hugging Face na huggingface.co/settings/tokens.
- Kliknij Nowy token.
- W polu Rola wybierz Odczyt.
- W polu Name (Nazwa) wpisz nazwę opisową (np. finetuning-lab).
- Kliknij Utwórz token.
- Skopiuj wygenerowany token do schowka. Będzie on potrzebny w następnym kroku.
Aktualizowanie zmiennych środowiskowych
Teraz dodaj token Hugging Face i nazwę zasobnika GCS do pliku env.sh. Zastąp [your-hf-token] skopiowanym właśnie tokenem.
- W terminalu dodaj nowe zmienne do
env.shi załaduj je ponownie:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. Konfigurowanie Workload Identity
Następnie skonfigurujesz Workload Identity, czyli zalecany sposób umożliwiający aplikacjom działającym w GKE dostęp do usług Google Cloud bez konieczności zarządzania statycznymi kluczami konta usługi. Więcej informacji znajdziesz w dokumentacji Workload Identity.
- Najpierw utwórz konto usługi Google (GSA). W terminalu uruchom:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - Następnie utwórz zasobnik GCS i przyznaj GSA uprawnienia dostępu do niego:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - Teraz utwórz konto usługi Kubernetes (KSA):
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - Na koniec utwórz powiązanie zasad uprawnień między kontem usługi Google a kontem usługi Kubernetes:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. Przygotuj model podstawowy
W produkcyjnych potokach uczenia maszynowego duże modele, takie jak Llama 2 (ok. 13 GB), są zwykle wstępnie przygotowywane w Cloud Storage, a nie pobierane podczas trenowania. Takie podejście zapewnia większą niezawodność, szybszy dostęp i pozwala uniknąć problemów z siecią. Google Cloud udostępnia wstępnie pobrane wersje popularnych modeli w publicznych zasobnikach GCS, z których będziesz korzystać w tym module.
- Najpierw sprawdźmy, czy masz dostęp do modelu Llama 2 udostępnionego przez Google:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - Skopiuj model Llama 2 z tego publicznego zasobnika do zasobnika w swoim projekcie za pomocą polecenia
gcloud storage. Przenoszenie odbywa się w szybkiej sieci wewnętrznej Google i powinno zająć tylko minutę lub dwie.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - Sprawdź, czy pliki modelu zostały prawidłowo skopiowane, wyświetlając zawartość zasobnika.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. Przygotowanie kodu trenowania
Teraz utworzysz aplikację w kontenerze, która dostroi model. To zadanie wykorzystuje LoRA (adaptacja o niskim rzędzie), czyli technikę dostrajania konkretnych parametrów (PEFT), która znacznie zmniejsza wymagania dotyczące pamięci, ponieważ trenuje tylko małe warstwy „adaptera” zamiast całego modelu.
Teraz utwórz skrypty w Pythonie dla potoku trenowania.
- W terminalu uruchom to polecenie, aby otworzyć plik
train.py:cloudshell edit train.py - Wklej do pliku
train.pyten kod:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. Omówienie kodu trenowania
Skrypt train.py koordynuje proces dostrajania. Przyjrzyjmy się jego kluczowym komponentom.
Konfiguracja
Skrypt używa parametru LoraConfig do zdefiniowania ustawień adaptacji o niskim rzędzie. LoRA znacznie zmniejsza liczbę parametrów, które można trenować, co pozwala dostrajać duże modele na mniejszych procesorach graficznych.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
Przygotowywanie zbioru danych
Funkcja prepare_dataset wczytuje zbiór danych „American Stories” i przetwarza go na podzielone na tokeny fragmenty. Wykorzystuje niestandardowy SimpleTextDataset do wydajnego obsługiwania tensorów wejściowych.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
Pociąg
Funkcja train_model konfiguruje Trainer za pomocą określonych argumentów zoptymalizowanych pod kątem tego zadania. Kluczowe parametry to:
gradient_accumulation_steps: pomaga symulować większą wielkość wsadu bez zwiększania wykorzystania pamięci.fp16=True: wykorzystuje trening z użyciem mieszanej precyzji, aby zmniejszyć zużycie pamięci i zwiększyć szybkość.gradient_checkpointing=True: oszczędza pamięć, ponownie obliczając aktywacje podczas przejścia wstecznego zamiast je przechowywać.optim="adamw_torch": używa standardowej implementacji optymalizatora AdamW z biblioteki PyTorch.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
Wnioskowanie
Funkcja run_inference przeprowadza szybki test dostrojonego modelu za pomocą przykładowego prompta. Dzięki temu model jest w trybie oceny i generuje tekst, aby sprawdzić, czy adaptery działają prawidłowo.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. Konteneryzacja aplikacji
Teraz za pomocą Dockera utwórz obraz kontenera trenowania i prześlij go do Google Artifact Registry.
- W terminalu uruchom to polecenie, aby otworzyć plik
Dockerfile:cloudshell edit Dockerfile - Wklej do pliku
Dockerfileten kod:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
Tworzenie i wypychanie kontenera
- Utwórz repozytorium Artifact Registry:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Utwórz i prześlij obraz za pomocą Cloud Build:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. Wdróż zadanie dostrajania
- Utwórz plik manifestu zadania Kubernetes, aby rozpocząć dostrajanie. W terminalu uruchom:
cloudshell edit training_job.yaml - Wklej do pliku
training_job.yamlten kod:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- Na koniec zastosuj plik manifestu zadania Kubernetes, aby rozpocząć zadanie dostrajania w klastrze GKE.
envsubst < training_job.yaml | kubectl apply -f -
14. Monitorowanie zadania trenowania
Postęp zadania trenowania możesz monitorować w konsoli Google Cloud.
- Otwórz stronę Kubernetes Engine > Zadania.
Wyświetlanie zbiorów zadań GKE - Kliknij zadanie
llama-fine-tuning, aby wyświetlić jego szczegóły. - Domyślnie wyświetla się karta Szczegóły. Dane o wykorzystaniu procesora graficznego znajdziesz w sekcji Zasoby.
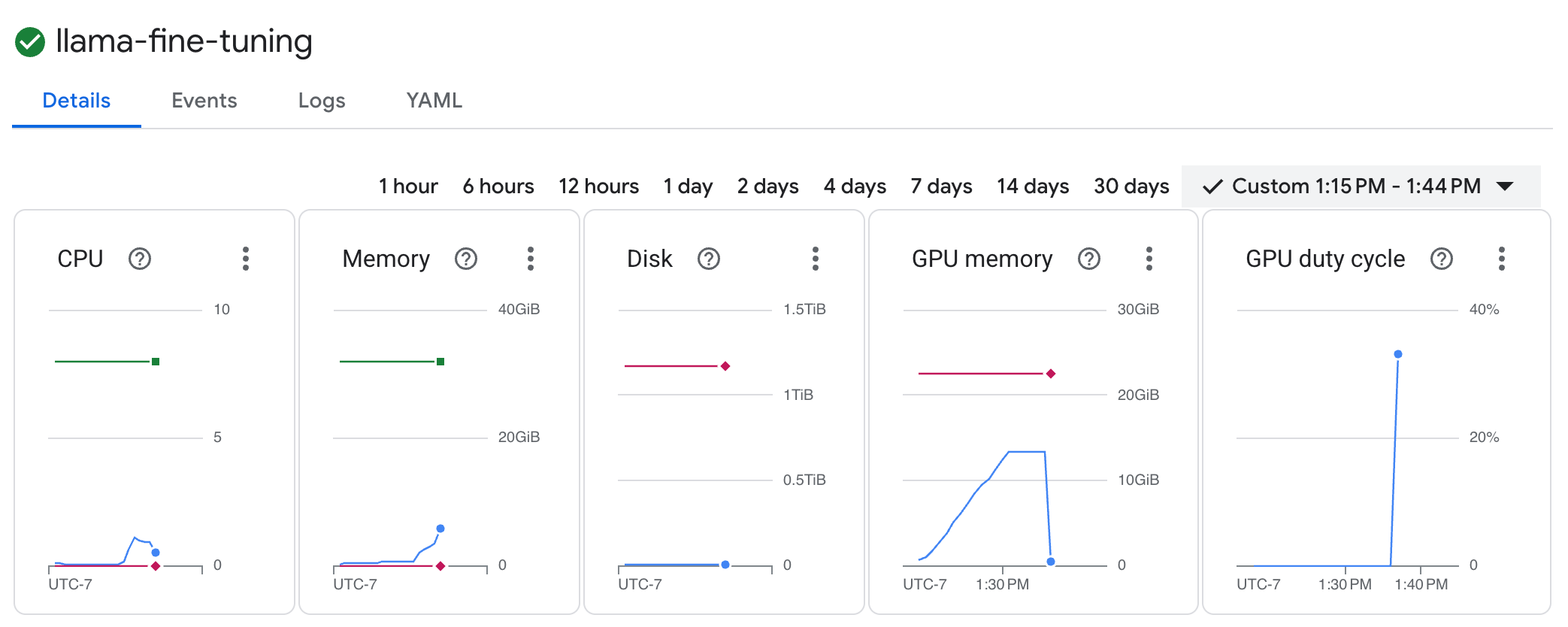
- Aby wyświetlić logi trenowania, kliknij kartę Logi. Powinny się wyświetlić postępy trenowania, w tym strata i tempo uczenia się.
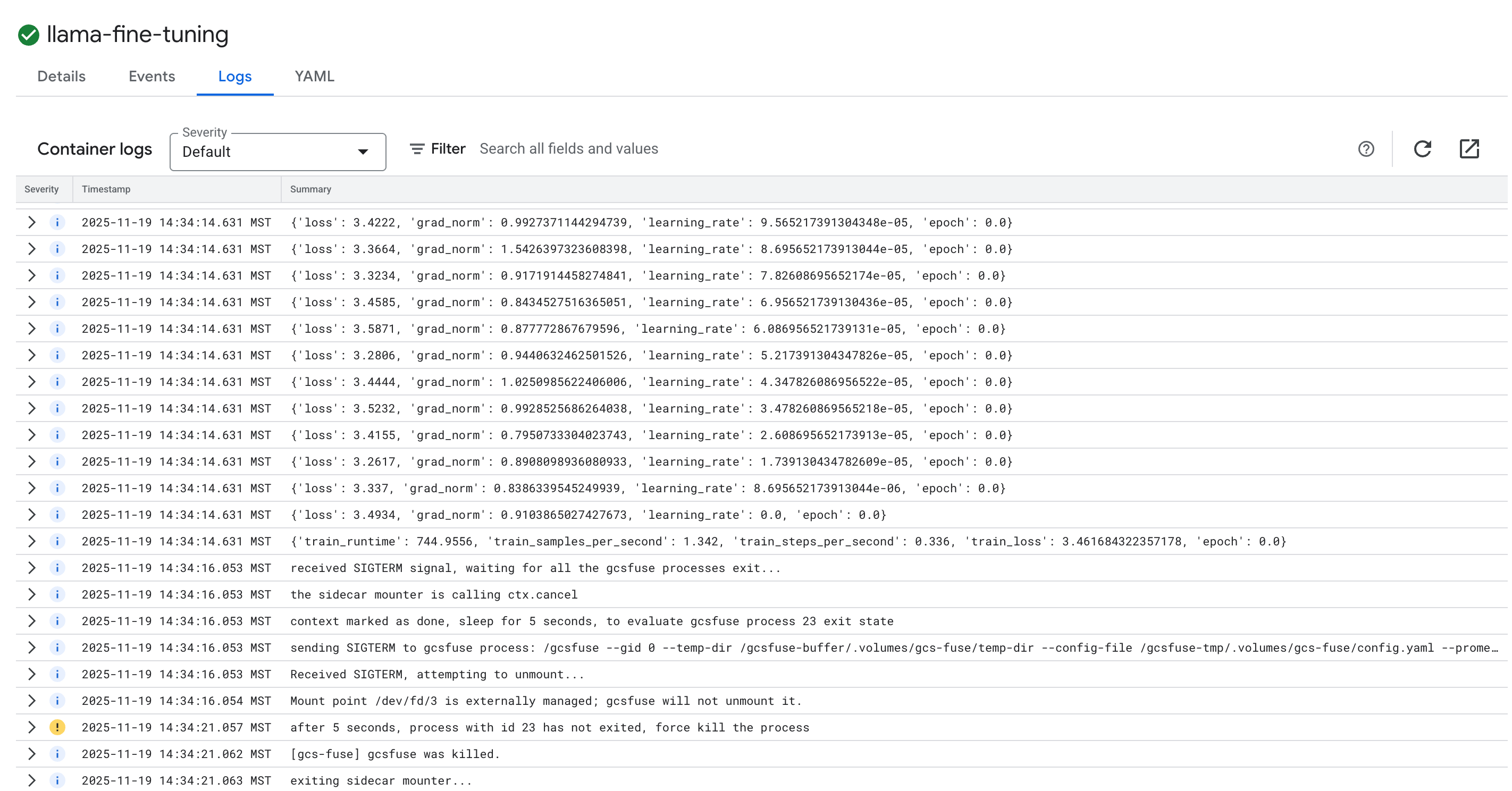
15. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby zużyte w tym samouczku, możesz usunąć projekt zawierający te zasoby lub zachować projekt i usunąć poszczególne zasoby.
Usuń klaster GKE.
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Usuwanie repozytorium Artifact Registry
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
Usuwanie zasobnika GCS
gcloud storage rm -r gs://${BUCKET_NAME}
16. Gratulacje!
Udało Ci się dostroić model LLM typu open source w GKE.
Podsumowanie
W tym module omówimy następujące zagadnienia:
- utworzyć klaster GKE z akceleracją GPU;
- Skonfigurowano Workload Identity, aby zapewnić bezpieczny dostęp do usług Google Cloud.
- Skonteneryzowano zadanie trenowania PyTorch przy użyciu Dockera i Artifact Registry.
- Wdrożono zadanie dostrajania z użyciem LoRA, aby dostosować model Llama 2 do nowego zbioru danych.
Co dalej?
- Dowiedz się więcej o AI w GKE.
- Zapoznaj się z bazą modeli Vertex AI.
- Dołącz do społeczności Google Cloud, aby nawiązać kontakt z innymi programistami.
Ścieżka szkoleniowa Google Cloud
Ten moduł jest częścią ścieżki szkoleniowej AI gotowa do wdrożenia w Google Cloud. Poznaj pełny program nauczania, aby przejść od prototypu do produkcji.
Udostępnij swoje postępy, używając hashtaga #ProductionReadyAI.