
1. Introdução
Neste laboratório, você vai aprender a criar um pipeline de ajuste completo e de nível de produção para o Llama 2, um modelo de linguagem de código aberto conhecido, usando o Google Kubernetes Engine (GKE). Você vai aprender sobre decisões de arquitetura, compensações comuns e componentes que refletem fluxos de trabalho de operações de machine learning (MLOps) do mundo real.
Você vai provisionar um cluster do GKE, criar um pipeline de treinamento conteinerizado usando LoRA (adaptação de classificação baixa) e executar o job de treinamento no GKE.
Visão geral da arquitetura
Confira o que vamos criar hoje:
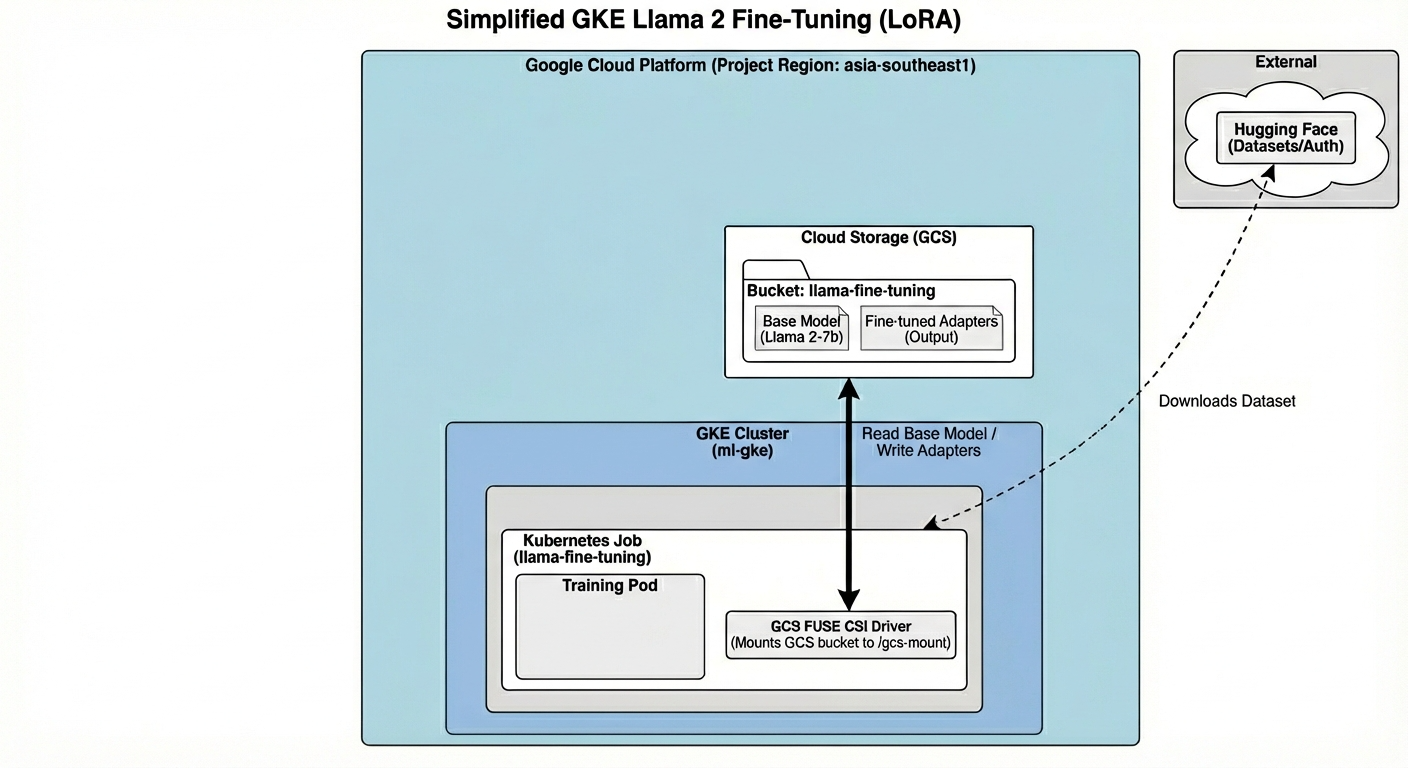
A arquitetura inclui:
- Cluster do GKE: gerencia nossos recursos de computação.
- Pool de nós de GPU: 1 GPU L4 (Spot) para treinamento
- Bucket do GCS: armazena modelos e conjuntos de dados.
- Identidade da carga de trabalho: acesso seguro entre o K8s e o GCS
O que você vai aprender
- Provisione e configure um cluster do GKE com recursos otimizados para cargas de trabalho de ML.
- Implemente o acesso seguro e sem chaves do GKE a outros serviços do Google Cloud usando a Identidade da carga de trabalho.
- Crie um pipeline de treinamento em contêineres usando o Docker.
- Ajuste um modelo de código aberto com eficiência usando o ajuste fino com eficiência de parâmetros (PEFT) com LoRA.
2. Configurar o projeto
Conta do Google
Se você ainda não tiver uma Conta do Google pessoal, crie uma.
Use uma conta pessoal em vez de uma conta escolar ou de trabalho.
Fazer login no console do Google Cloud
Faça login no console do Google Cloud usando uma Conta do Google pessoal.
Criar um projeto (opcional)
Se você não tiver um projeto atual que gostaria de usar neste laboratório, crie um novo aqui.
3. Abrir editor do Cloud Shell
- Clique neste link para navegar diretamente até o editor do Cloud Shell.
- Se for preciso autorizar em algum momento, clique em Autorizar para continuar.
- Se o terminal não aparecer na parte de baixo da tela, abra-o:
- Clique em Visualizar.
- Clique em Terminal
 .
.
- No terminal, defina o projeto com este comando:
gcloud config set project [PROJECT_ID]- Exemplo:
gcloud config set project lab-project-id-example - Se você não se lembrar do ID do projeto, liste todos os IDs com:
gcloud projects list
- Exemplo:
- Você vai receber esta mensagem:
Updated property [core/project].
4. Ativar APIs
Para usar o GKE e outros serviços, é necessário ativar as APIs necessárias no projeto do Google Cloud.
- No terminal, ative as APIs:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
Apresentação das APIs
- A API do Google Kubernetes Engine (
container.googleapis.com) permite criar e gerenciar o cluster do GKE que executa seu aplicativo. - A API Artifact Registry (
artifactregistry.googleapis.com) oferece um repositório seguro e particular para armazenar suas imagens de contêiner. - A API Cloud Build (
cloudbuild.googleapis.com) é usada pelo comandogcloud builds submitpara criar sua imagem de contêiner na nuvem. - A API IAM (
iam.googleapis.com) permite gerenciar o controle de acesso e a identidade dos recursos do Google Cloud. - A API Compute Engine (
compute.googleapis.com) oferece máquinas virtuais seguras e personalizáveis que são executadas na infraestrutura do Google. - A API Service Account Credentials (
iamcredentials.googleapis.com) permite criar credenciais de curta duração para contas de serviço. - A API do Cloud Storage (
storage.googleapis.com) permite armazenar e recuperar dados na nuvem, usada aqui para armazenamento de modelos e conjuntos de dados.
5. configurar o ambiente do projeto
Criar um diretório de trabalho
- No terminal, crie um diretório para seu projeto e navegue até ele.
mkdir llama-finetuning cd llama-finetuning
Configurar variáveis de ambiente
- No terminal, crie um arquivo chamado
env.shpara armazenar suas variáveis de ambiente. Isso garante que você possa recarregá-los facilmente se a sessão for desconectada.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - Crie o arquivo para carregar as variáveis na sessão atual:
source env.sh
6. Provisionar o cluster do GKE
- No terminal, crie o cluster do GKE com um pool de nós padrão. Isso vai levar cerca de 5 minutos.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - Em seguida, adicione um pool de nós de GPU ao cluster. Esse pool de nós será usado para treinar o modelo.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - Por fim, receba as credenciais do novo cluster e verifique se é possível se conectar a ele.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Configurar o acesso ao Hugging Face
Com a infraestrutura pronta, agora você precisa fornecer ao projeto as credenciais necessárias para acessar o modelo e os dados. Nesta tarefa, você vai primeiro receber um token do Hugging Face.
Receber um token do Hugging Face
- Se você não tiver uma conta do Hugging Face, acesse huggingface.co/join em uma nova guia do navegador e conclua o processo de registro.
- Depois de se registrar e fazer login, acesse huggingface.co/meta-llama/Llama-2-7b-hf.
- Leia os termos de licença e clique no botão para aceitá-los.
- Acesse a página de tokens de acesso do Hugging Face em huggingface.co/settings/tokens.
- Clique em Novo token.
- Em Papel, selecione Leitura.
- Em Nome, insira um nome descritivo (por exemplo, finetuning-lab).
- Clique em Criar um token.
- Copie o token gerado para a área de transferência. Você precisará dele na próxima etapa.
Atualizar variáveis de ambiente
Agora, vamos adicionar seu token do Hugging Face e um nome para seu bucket do GCS ao arquivo env.sh. Substitua [your-hf-token] pelo token que você acabou de copiar.
- No Terminal, adicione as novas variáveis a
env.she recarregue-as:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. Configurar a Identidade da carga de trabalho
Em seguida, você vai configurar a Identidade da carga de trabalho, que é a maneira recomendada de permitir que aplicativos em execução no GKE acessem os serviços do Google Cloud sem precisar gerenciar chaves estáticas da conta de serviço. Saiba mais na documentação da Identidade da carga de trabalho.
- Primeiro, crie uma conta de serviço do Google (GSA). No terminal, execute:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - Em seguida, crie o bucket do GCS e conceda à GSA permissões para acessá-lo:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - Agora, crie uma conta de serviço do Kubernetes (KSA):
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - Por fim, crie a vinculação de política do IAM entre a GSA e a KSA:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. Fazer o estágio do modelo de base
Em pipelines de ML de produção, modelos grandes como o Llama 2 (~13 GB) geralmente são pré-armazenados no Cloud Storage em vez de baixados durante o treinamento. Essa abordagem oferece mais confiabilidade, acesso mais rápido e evita problemas de rede. O Google Cloud oferece versões pré-baixadas de modelos conhecidos em buckets públicos do GCS, que você vai usar neste laboratório.
- Primeiro, verifique se você pode acessar o modelo Llama 2 fornecido pelo Google:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - Copie o modelo Llama 2 deste bucket público para o bucket do seu projeto usando o comando
gcloud storage. Essa transferência usa a rede interna de alta velocidade do Google e leva apenas um ou dois minutos.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - Verifique se os arquivos do modelo foram copiados corretamente listando o conteúdo do bucket.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. Preparar o código de treinamento
Agora você vai criar o aplicativo conteinerizado que ajusta o modelo. Essa tarefa usa a adaptação de classificação baixa (LoRA, na sigla em inglês), uma técnica de ajustes finos com eficiência de parâmetros (PEFT, na sigla em inglês) que reduz drasticamente os requisitos de memória treinando apenas pequenas camadas de "adaptador" em vez do modelo inteiro.
Agora, crie os scripts Python para o pipeline de treinamento.
- No terminal, execute o comando a seguir para abrir o arquivo
train.py:cloudshell edit train.py - Cole o código a seguir no arquivo
train.py:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. Entenda o código de treinamento
O script train.py orquestra o processo de ajuste. Vamos analisar os principais componentes.
Configuração
O script usa LoraConfig para definir as configurações de adaptação de classificação baixa. O LoRA reduz significativamente o número de parâmetros treináveis, permitindo ajustar modelos grandes em GPUs menores.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
Preparar conjunto de dados
A função prepare_dataset carrega o conjunto de dados "American Stories" e o processa em partes tokenizadas. Ele usa um SimpleTextDataset personalizado para processar os tensores de entrada com eficiência.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
Trem
A função train_model configura o Trainer com argumentos específicos otimizados para essa carga de trabalho. Os principais parâmetros incluem:
gradient_accumulation_steps: ajuda a simular um tamanho de lote maior sem aumentar o uso da memória.fp16=True: usa treinamento de precisão mista para reduzir a memória e aumentar a velocidade.gradient_checkpointing=True: economiza memória ao recalcular as ativações durante a transmissão para trás em vez de armazená-las.optim="adamw_torch": usa a implementação padrão do otimizador AdamW do PyTorch.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
Inferência
A função run_inference realiza um teste rápido do modelo ajustado usando um comando de amostra. Ele garante que o modelo esteja no modo de avaliação e gera texto para verificar se os adaptadores estão funcionando corretamente.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. Colocar o aplicativo em um contêiner
Agora, crie a imagem do contêiner de treinamento usando o Docker e envie-a para o Google Artifact Registry.
- No terminal, execute o comando a seguir para abrir o arquivo
Dockerfile:cloudshell edit Dockerfile - Cole o código a seguir no arquivo
Dockerfile:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
Construir e enviar o contêiner
- Criar o repositório do Artifact Registry:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Crie e envie a imagem usando o Cloud Build:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. Implantar o job de ajuste
- Crie o manifesto do job do Kubernetes para iniciar o job de ajuste. No terminal, execute:
cloudshell edit training_job.yaml - Cole o código a seguir no arquivo
training_job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- Por fim, aplique o manifesto de job do Kubernetes para iniciar o job de ajuste fino no cluster do GKE.
envsubst < training_job.yaml | kubectl apply -f -
14. Monitorar o job de treinamento
É possível monitorar o progresso do job de treinamento no console do Google Cloud.
- Acesse a página Kubernetes Engine > Cargas de trabalho.
Ver cargas de trabalho do GKE - Clique no job
llama-fine-tuningpara ver os detalhes. - A guia Detalhes é exibida por padrão. É possível conferir as métricas de utilização da GPU na seção Recursos.
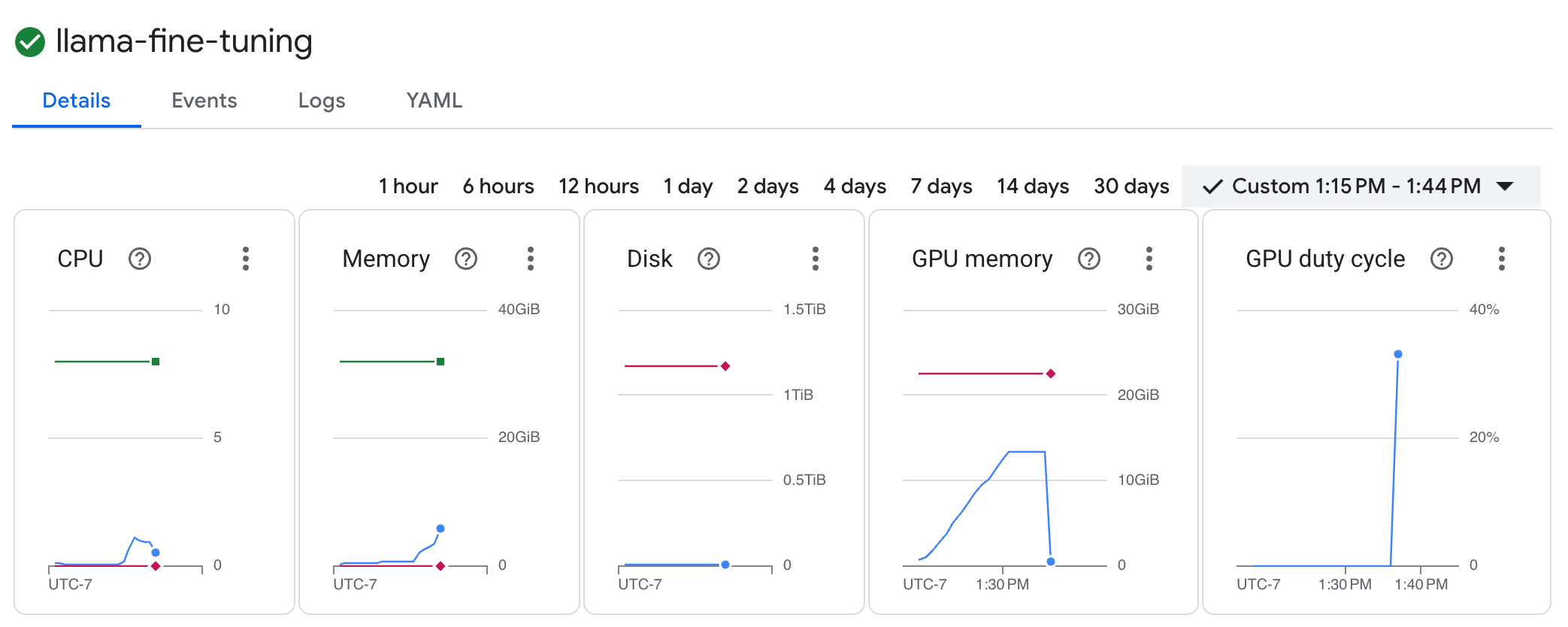
- Clique na guia Registros para conferir os registros de treinamento. Você vai ver o progresso do treinamento, incluindo a perda e a taxa de aprendizado.
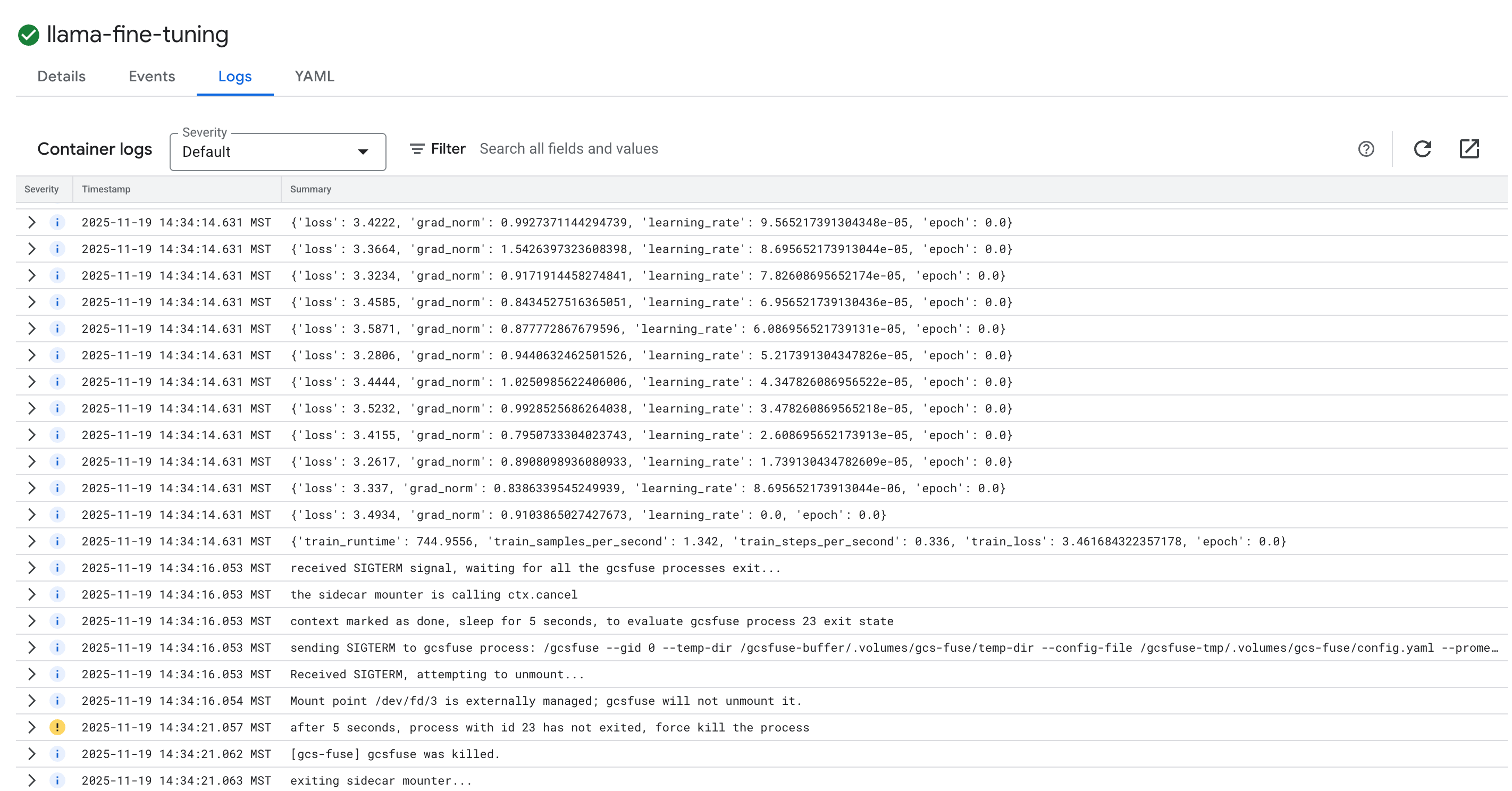
15. Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto ou mantenha o projeto e exclua cada um dos recursos.
Excluir o cluster do GKE
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Exclua o repositório do Artifact Registry.
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
Excluir o bucket do GCS
gcloud storage rm -r gs://${BUCKET_NAME}
16. Parabéns!
Você ajustou um LLM de código aberto no GKE.
Recapitulação
Neste laboratório, você vai:
- Provisionou um cluster do GKE com aceleração de GPU.
- Configurou a Identidade da carga de trabalho para acesso seguro aos serviços do Google Cloud.
- Conteinerizou um job de treinamento do PyTorch usando o Docker e o Artifact Registry.
- Implantou um job de ajuste refinado usando LoRA para adaptar o Llama 2 a um novo conjunto de dados.
A seguir
- Saiba mais sobre a IA no GKE.
- Conheça o Model Garden da Vertex AI.
- Participe da comunidade do Google Cloud para se conectar com outros desenvolvedores.
Programa de aprendizado do Google Cloud
Este laboratório faz parte do programa de aprendizado IA pronta para produção com o Google Cloud. Confira o currículo completo para diminuir a distância entre o protótipo e a produção.
Compartilhe seu progresso com a hashtag #ProductionReadyAI.