
1. Введение
В этой лабораторной работе вы научитесь создавать полноценный, готовый к использованию в производственной среде конвейер тонкой настройки для Llama 2, популярной модели языка программирования с открытым исходным кодом, используя Google Kubernetes Engine (GKE) . Вы узнаете об архитектурных решениях, распространенных компромиссах и компонентах, которые отражают реальные рабочие процессы машинного обучения (MLOps).
Вам потребуется развернуть кластер GKE, создать контейнеризированный конвейер обучения с использованием LoRA (Low-Rank Adaptation) и запустить задачу обучения в GKE.
Обзор архитектуры
Вот что мы сегодня построим:
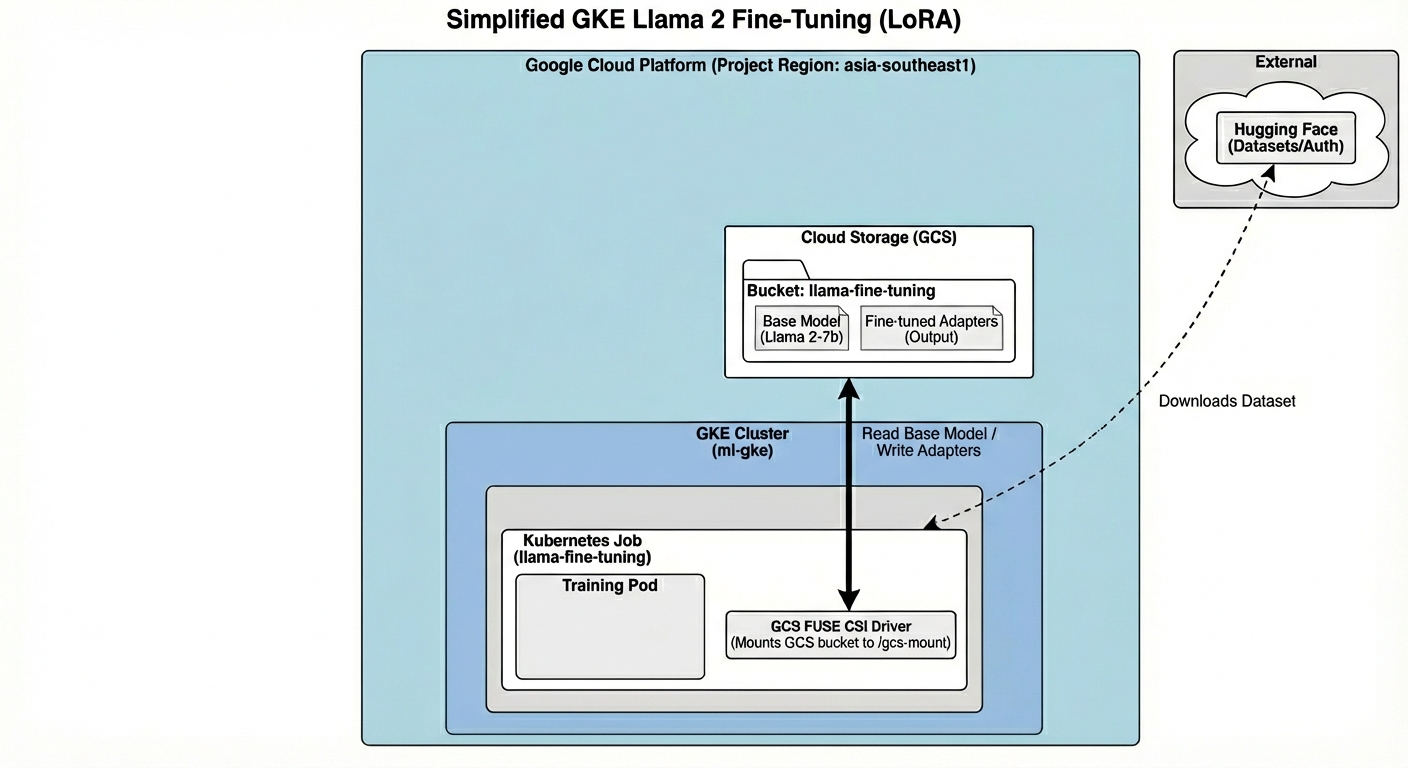
Архитектура включает в себя:
- Кластер GKE : управляет нашими вычислительными ресурсами.
- Пул узлов GPU : 1x GPU L4 ( Spot ) для обучения
- GCS Bucket : хранилище моделей и наборов данных.
- Идентификация рабочей нагрузки : Безопасный доступ между Kubernetes и GCS.
Что вы узнаете
- Создайте и настройте кластер GKE с функциями, оптимизированными для рабочих нагрузок машинного обучения.
- Внедрите безопасный доступ без использования ключей из GKE к другим сервисам Google Cloud с помощью Workload Identity.
- Создайте контейнеризированный конвейер обучения с использованием Docker.
- Эффективная тонкая настройка модели с открытым исходным кодом с использованием параметрически эффективной тонкой настройки (PEFT) с помощью LoRA.
2. Настройка проекта
Аккаунт Google
Если у вас еще нет личного аккаунта Google, вам необходимо его создать .
Используйте личный аккаунт вместо рабочего или учебного.
Войдите в консоль Google Cloud.
Войдите в консоль Google Cloud, используя личную учетную запись Google.
Создать проект (необязательно)
Если у вас нет текущего проекта, который вы хотели бы использовать для этой лабораторной работы, создайте новый проект здесь .
3. Откройте редактор Cloud Shell.
- Нажмите на эту ссылку, чтобы перейти непосредственно в редактор Cloud Shell.
- Если сегодня вам будет предложено авторизоваться, нажмите «Авторизовать» , чтобы продолжить.
- Если терминал не отображается внизу экрана, откройте его:
- Нажмите «Просмотреть».
- Нажмите «Терминал»
- В терминале настройте свой проект с помощью этой команды:
gcloud config set project [PROJECT_ID]- Пример:
gcloud config set project lab-project-id-example - Если вы не помните идентификатор своего проекта, вы можете перечислить все идентификаторы своих проектов с помощью следующей команды:
gcloud projects list
- Пример:
- Вы должны увидеть следующее сообщение:
Updated property [core/project].
4. Включите API.
Для использования GKE и других сервисов необходимо включить необходимые API в вашем проекте Google Cloud.
- В терминале включите API:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
Представляем API.
- API Google Kubernetes Engine (
container.googleapis.com) позволяет создавать и управлять кластером GKE, в котором работает ваше приложение. - API реестра артефактов (
artifactregistry.googleapis.com) предоставляет безопасное, закрытое хранилище для ваших образов контейнеров. - API Cloud Build (
cloudbuild.googleapis.com) используется командойgcloud builds submitдля сборки образа контейнера в облаке. - API IAM (
iam.googleapis.com) позволяет управлять контролем доступа и идентификацией для ваших ресурсов Google Cloud. - API Compute Engine (
compute.googleapis.com) предоставляет безопасные и настраиваемые виртуальные машины, работающие на инфраструктуре Google. - API учетных данных служебных учетных записей IAM (
iamcredentials.googleapis.com) позволяет создавать кратковременные учетные данные для служебных учетных записей. - API облачного хранилища (
storage.googleapis.com) позволяет хранить и извлекать данные в облаке, в данном случае используется для хранения моделей и наборов данных.
5. Настройка среды проекта
Создайте рабочую директорию
- В терминале создайте директорию для вашего проекта и перейдите в неё.
mkdir llama-finetuning cd llama-finetuning
Настройте переменные среды
- В терминале создайте файл с именем
env.shдля хранения переменных окружения. Это позволит легко перезагрузить их в случае разрыва сессии.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - Подключите файл, чтобы загрузить переменные в текущую сессию:
source env.sh
6. Настройка кластера GKE
- В терминале создайте кластер GKE с пулом узлов по умолчанию. Это займет около 5 минут.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - Далее добавьте в кластер пул узлов с графическими процессорами. Этот пул узлов будет использоваться для обучения модели.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - Наконец, получите учетные данные для вашего нового кластера и убедитесь, что вы можете к нему подключиться.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Настройка доступа по функции «Объятия по лицу».
После подготовки инфраструктуры вам необходимо предоставить вашему проекту необходимые учетные данные для доступа к вашей модели и данным. В этом задании вы сначала получите токен Hugging Face.
Получите жетон "Обнимающее лицо"
- Если у вас нет учетной записи Hugging Face, перейдите по ссылке huggingface.co/join в новой вкладке браузера и завершите процесс регистрации.
- После регистрации и входа в систему перейдите по ссылке huggingface.co/meta-llama/Llama-2-7b-hf .
- Ознакомьтесь с условиями лицензии и нажмите кнопку, чтобы принять их.
- Перейдите на страницу с токенами доступа Hugging Face по адресу huggingface.co/settings/tokens .
- Нажмите «Создать токен» .
- В поле «Роль» выберите «Чтение» .
- В поле «Имя» введите описательное название (например, finetuning-lab).
- Нажмите «Создать токен» .
- Скопируйте сгенерированный токен в буфер обмена. Он понадобится вам на следующем шаге.
Обновление переменных среды
Теперь добавим ваш токен Hugging Face и имя для вашего хранилища GCS в файл env.sh Замените [your-hf-token] на скопированный вами токен.
- В терминале добавьте новые переменные в
env.shи перезагрузите их:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. Настройка идентификации рабочей нагрузки
Далее вам потребуется настроить Workload Identity, что является рекомендуемым способом предоставления приложениям, работающим в GKE, доступа к сервисам Google Cloud без необходимости управления статическими ключами учетных записей сервисов. Подробнее об этом можно узнать в документации по Workload Identity .
- Сначала создайте учетную запись службы Google (GSA). В терминале выполните следующую команду:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - Далее создайте хранилище GCS и предоставьте GSA разрешения на доступ к нему:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - Теперь создайте учетную запись службы Kubernetes (KSA):
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - Наконец, создайте привязку политики IAM между GSA и KSA:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. Поэтапное создание базовой модели.
В производственных конвейерах машинного обучения большие модели, такие как Llama 2 (~13 ГБ), обычно предварительно размещаются в Cloud Storage, а не загружаются во время обучения. Такой подход обеспечивает более высокую надежность, более быстрый доступ и позволяет избежать проблем с сетью. Google Cloud предоставляет предварительно загруженные версии популярных моделей в общедоступных хранилищах GCS, которые вы будете использовать в этой лабораторной работе.
- Для начала давайте убедимся, что у вас есть доступ к предоставленной Google модели Llama 2:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - Скопируйте модель Llama 2 из этого общедоступного хранилища в хранилище вашего проекта, используя команду
gcloud storage. Эта передача осуществляется через высокоскоростную внутреннюю сеть Google и займет всего одну-две минуты.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - Убедитесь, что файлы модели скопированы правильно, выведя список содержимого вашего хранилища.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. Подготовьте код для обучения.
Теперь вам предстоит создать контейнеризированное приложение, которое будет выполнять тонкую настройку модели. В этой задаче используется LoRA (Low-Rank Adaptation), метод параметрически эффективной тонкой настройки (PEFT), который значительно сокращает требования к памяти, обучая только небольшие «адаптерные» слои вместо всей модели.
Теперь создайте скрипты на Python для конвейера обучения.
- В терминале выполните следующую команду, чтобы открыть файл
train.py:cloudshell edit train.py - Вставьте следующий код в файл
train.py:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. Разберитесь в коде обучения.
Скрипт train.py управляет процессом тонкой настройки. Давайте разберем его ключевые компоненты.
Конфигурация
В скрипте используется LoraConfig для определения параметров адаптации к низкому рангу (Low-Rank Adaptation). LoRA значительно сокращает количество обучаемых параметров, позволяя точно настраивать большие модели на менее мощных графических процессорах.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
Подготовка набора данных
Функция prepare_dataset загружает набор данных "American Stories" и обрабатывает его, разделяя на токенизированные фрагменты. Для эффективной обработки входных тензоров она использует пользовательский объект SimpleTextDataset .
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
Тренироваться
Функция train_model настраивает Trainer с заданными аргументами, оптимизированными для данной рабочей нагрузки. Ключевые параметры включают:
-
gradient_accumulation_steps: Helps simulate a larger batch size without increasing memory usage. -
fp16=True: Использует обучение с разной точностью для уменьшения объема памяти и повышения скорости. -
gradient_checkpointing=True: Экономит память, пересчитывая активации во время обратного прохода вместо их сохранения. -
optim="adamw_torch": Использует стандартную реализацию оптимизатора AdamW из PyTorch.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
Вывод
Функция run_inference выполняет быструю проверку доработанной модели с помощью примера запроса. Она гарантирует, что модель находится в режиме оценки, и генерирует текст для проверки корректной работы адаптеров.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. Контейнеризуйте приложение.
Теперь создайте образ контейнера для обучения с помощью Docker и загрузите его в реестр артефактов Google .
- В терминале выполните следующую команду, чтобы открыть файл
Dockerfile:cloudshell edit Dockerfile - Вставьте следующий код в файл
Dockerfile:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
Соберите и отправьте контейнер.
- Create the Artifact Registry repository:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Создайте и загрузите образ с помощью Cloud Build :
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. Запустите задачу тонкой настройки.
- Создайте манифест задания Kubernetes для запуска процесса тонкой настройки. В терминале выполните следующую команду:
cloudshell edit training_job.yaml - Вставьте следующий код в файл
training_job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- Наконец, примените манифест задания Kubernetes, чтобы запустить задачу тонкой настройки в вашем кластере GKE.
envsubst < training_job.yaml | kubectl apply -f -
14. Контроль за выполнением учебной работы.
Вы можете отслеживать ход выполнения задания по обучению в консоли Google Cloud.
- Перейдите на страницу Kubernetes Engine > Workloads .
Просмотр рабочих нагрузок GKE - Нажмите на объявление о задании
llama-fine-tuningчтобы просмотреть его подробности. - Вкладка «Подробности» отображается по умолчанию. Показатели использования графического процессора можно посмотреть в разделе «Ресурсы» .
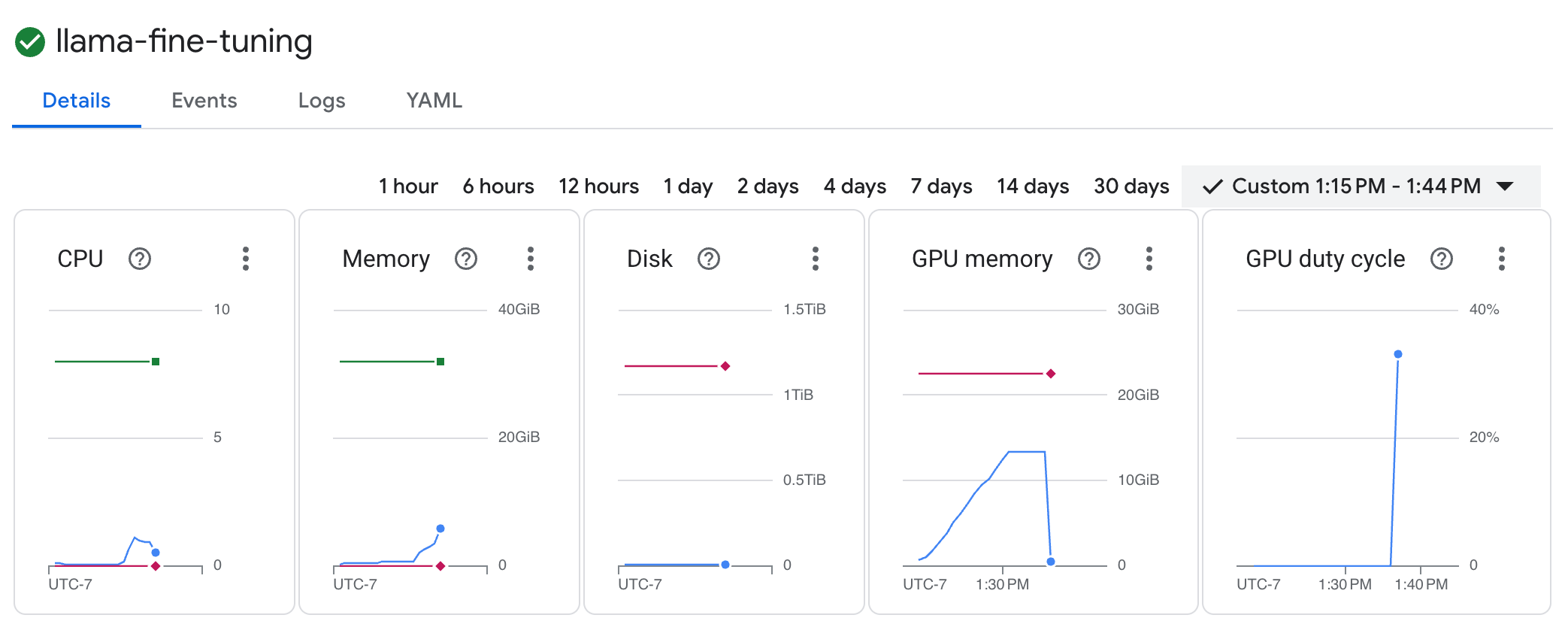
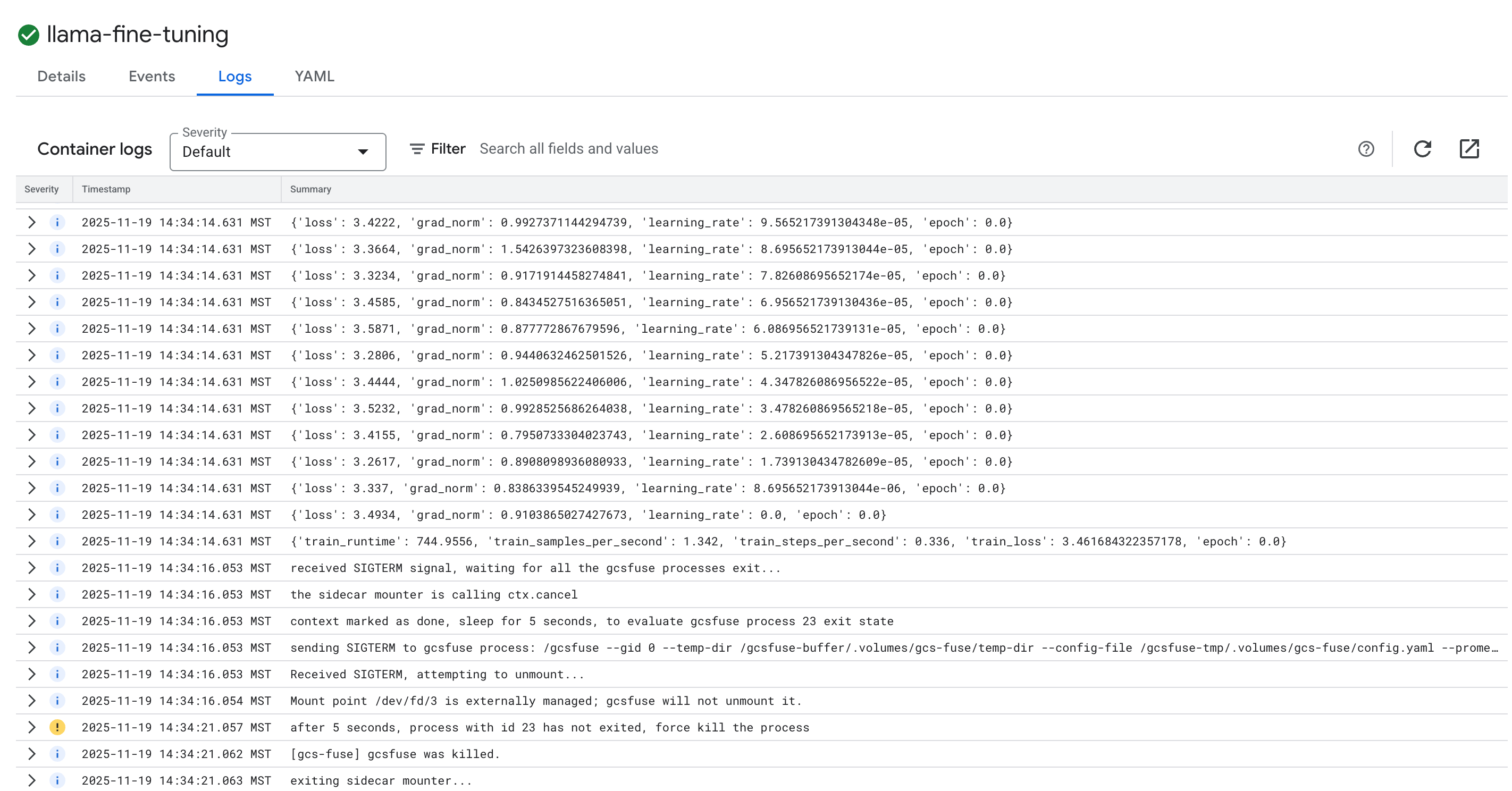
- Чтобы просмотреть журналы обучения, нажмите на вкладку «Журналы» . Вы увидите ход обучения, включая потери и скорость обучения.
15. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, используемые в этом руководстве, либо удалите проект, содержащий эти ресурсы, либо сохраните проект и удалите отдельные ресурсы.
Удалите кластер GKE.
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Удалите репозиторий Реестра артефактов.
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
Удалите корзину GCS.
gcloud storage rm -r gs://${BUCKET_NAME}
16. Поздравляем!
Вы успешно доработали модуль LLM с открытым исходным кодом на платформе GKE!
Краткий обзор
В этой лаборатории вы:
- Создан кластер GKE с ускорением на графическом процессоре.
- Настроена идентификация рабочей нагрузки для безопасного доступа к сервисам Google Cloud.
- Создан контейнер для задачи обучения PyTorch с использованием Docker и Artifact Registry.
- Запущена задача тонкой настройки с использованием LoRA для адаптации Llama 2 к новому набору данных.
Что дальше?
- Узнайте больше об искусственном интеллекте на GKE .
- Изучите модель сада Vertex AI .
- Присоединяйтесь к сообществу Google Cloud , чтобы общаться с другими разработчиками.
Программа обучения Google Cloud
Эта лабораторная работа является частью учебного курса "Имму, готовую к внедрению в производство" от Google Cloud . Изучите полный учебный план , чтобы преодолеть разрыв между прототипом и производством.
Делитесь своими успехами, используя хэштег #ProductionReadyAI .