
1. บทนำ
ในแล็บนี้ คุณจะได้เรียนรู้วิธีสร้างไปป์ไลน์การปรับแต่ง Llama 2 ซึ่งเป็นโมเดลภาษาโอเพนซอร์สยอดนิยมให้สมบูรณ์และพร้อมใช้งานจริงโดยใช้ Google Kubernetes Engine (GKE) คุณจะได้เรียนรู้เกี่ยวกับการตัดสินใจด้านสถาปัตยกรรม การแลกเปลี่ยนที่พบบ่อย และคอมโพเนนต์ที่สะท้อนเวิร์กโฟลว์แมชชีนเลิร์นนิงโอเปอเรชัน (MLOps) ในโลกแห่งความเป็นจริง
คุณจะจัดสรรคลัสเตอร์ GKE สร้างไปป์ไลน์การฝึกที่สร้างโดยใช้คอนเทนเนอร์โดยใช้ LoRA (Low-Rank Adaptation) และเรียกใช้ชื่องานการฝึกบน GKE
ภาพรวมสถาปัตยกรรม
สิ่งที่เราจะสร้างในวันนี้มีดังนี้
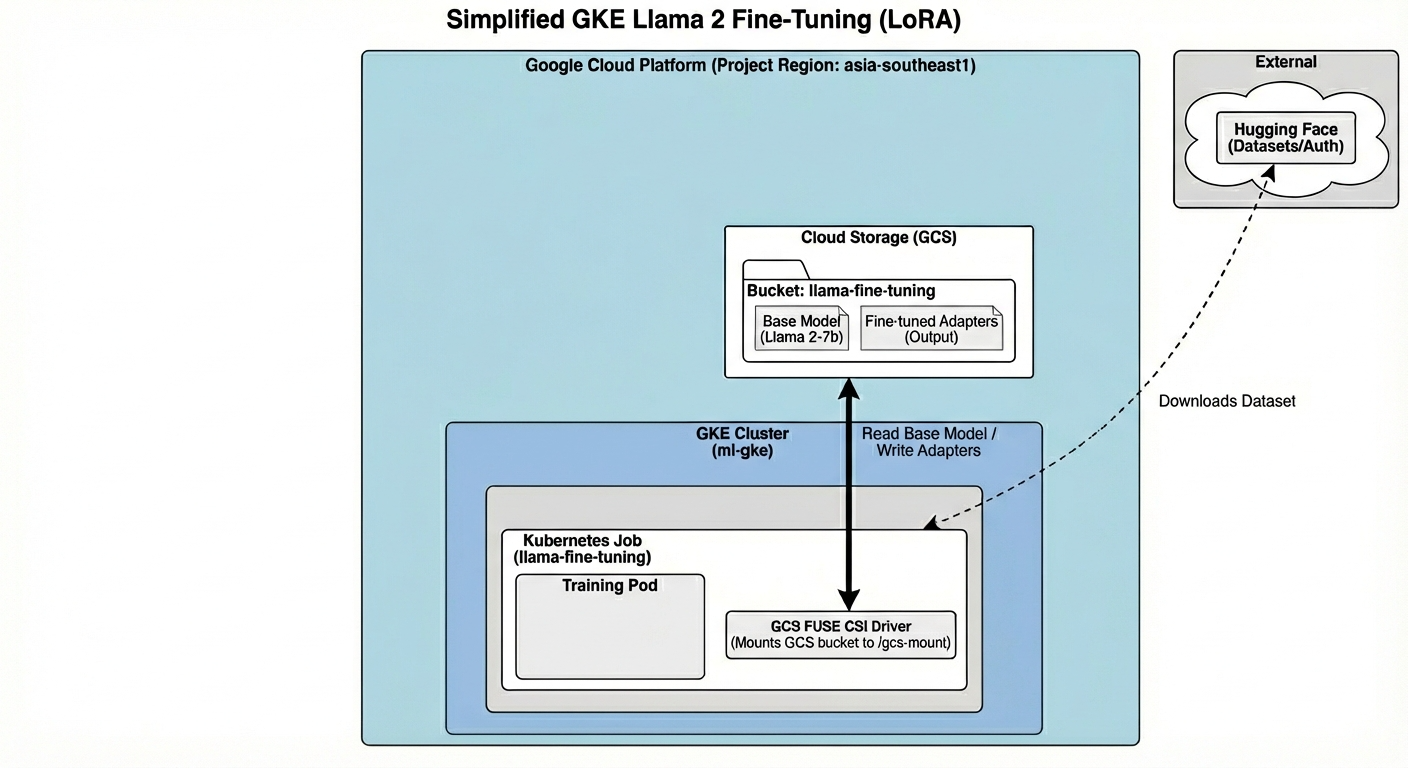
สถาปัตยกรรมประกอบด้วย
- คลัสเตอร์ GKE: จัดการทรัพยากรการประมวลผล
- กลุ่มโหนด GPU: 1x L4 GPU (Spot) สำหรับการฝึก
- Bucket ของ GCS: จัดเก็บโมเดลและชุดข้อมูล
- Workload Identity: การเข้าถึงที่ปลอดภัยระหว่าง K8s กับ GCS
สิ่งที่คุณจะได้เรียนรู้
- จัดสรรและกำหนดค่าคลัสเตอร์ GKE ด้วยฟีเจอร์ที่เพิ่มประสิทธิภาพสำหรับภาระงาน ML
- ใช้ Workload Identity เพื่อใช้การเข้าถึงแบบไม่มีคีย์ที่ปลอดภัยจาก GKE ไปยังบริการอื่นๆ ของ Google Cloud
- สร้างไปป์ไลน์การฝึกที่ใช้คอนเทนเนอร์โดยใช้ Docker
- ปรับแต่งโมเดลโอเพนซอร์สอย่างมีประสิทธิภาพโดยใช้การปรับแต่งพารามิเตอร์อย่างมีประสิทธิภาพ (PEFT) ด้วย LoRA
2. การตั้งค่าโปรเจ็กต์
บัญชี Google
หากยังไม่มีบัญชี Google ส่วนบุคคล คุณต้องสร้างบัญชี Google
ใช้บัญชีส่วนตัวแทนบัญชีของที่ทำงานหรือโรงเรียน
ลงชื่อเข้าใช้ Google Cloud Console
ลงชื่อเข้าใช้ Google Cloud Console โดยใช้บัญชี Google ส่วนตัว
สร้างโปรเจ็กต์ (ไม่บังคับ)
หากไม่มีโปรเจ็กต์ปัจจุบันที่ต้องการใช้สำหรับแล็บนี้ ให้สร้างโปรเจ็กต์ใหม่ที่นี่
3. เปิดเครื่องมือแก้ไข Cloud Shell
- คลิกลิงก์นี้เพื่อไปยัง Cloud Shell Editor โดยตรง
- หากระบบแจ้งให้ให้สิทธิ์ในวันนี้ ให้คลิกให้สิทธิ์เพื่อดำเนินการต่อ
- หากเทอร์มินัลไม่ปรากฏที่ด้านล่างของหน้าจอ ให้เปิดโดยทำดังนี้
- คลิกดู
- คลิก Terminal
- ในเทอร์มินัล ให้ตั้งค่าโปรเจ็กต์ด้วยคำสั่งนี้
gcloud config set project [PROJECT_ID]- ตัวอย่าง
gcloud config set project lab-project-id-example - หากจำรหัสโปรเจ็กต์ไม่ได้ คุณสามารถแสดงรหัสโปรเจ็กต์ทั้งหมดได้โดยใช้คำสั่งต่อไปนี้
gcloud projects list
- ตัวอย่าง
- คุณควรเห็นข้อความต่อไปนี้
Updated property [core/project].
4. เปิดใช้ API
หากต้องการใช้ GKE และบริการอื่นๆ คุณต้องเปิดใช้ API ที่จำเป็นในโปรเจ็กต์ Google Cloud
- เปิดใช้ API ในเทอร์มินัลโดยทำดังนี้
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
ขอแนะนำ API
- Google Kubernetes Engine API (
container.googleapis.com) ช่วยให้คุณสร้างและจัดการคลัสเตอร์ GKE ที่เรียกใช้แอปพลิเคชันได้ - Artifact Registry API (
artifactregistry.googleapis.com) มีที่เก็บข้อมูลส่วนตัวที่ปลอดภัยสำหรับจัดเก็บอิมเมจคอนเทนเนอร์ - Cloud Build API (
cloudbuild.googleapis.com) ใช้โดยคำสั่งgcloud builds submitเพื่อสร้างอิมเมจคอนเทนเนอร์ในระบบคลาวด์ - IAM API (
iam.googleapis.com) ช่วยให้คุณจัดการการควบคุมการเข้าถึงและข้อมูลประจำตัวสำหรับทรัพยากร Google Cloud ได้ - Compute Engine API (
compute.googleapis.com) มีเครื่องเสมือนที่ปลอดภัยและปรับแต่งได้ซึ่งทำงานบนโครงสร้างพื้นฐานของ Google - IAM Service Account Credentials API (
iamcredentials.googleapis.com) อนุญาตให้สร้างข้อมูลเข้าสู่ระบบที่มีอายุสั้นสำหรับบัญชีบริการ - Cloud Storage API (
storage.googleapis.com) ช่วยให้คุณจัดเก็บและดึงข้อมูลในระบบคลาวด์ ซึ่งใช้ที่นี่เพื่อจัดเก็บโมเดลและชุดข้อมูล
5. ตั้งค่าสภาพแวดล้อมของโปรเจ็กต์
สร้างไดเรกทอรีการทำงาน
- ในเทอร์มินัล ให้สร้างไดเรกทอรีสำหรับโปรเจ็กต์แล้วไปที่ไดเรกทอรีนั้น
mkdir llama-finetuning cd llama-finetuning
ตั้งค่าตัวแปรสภาพแวดล้อม
- ในเทอร์มินัล ให้สร้างไฟล์ชื่อ
env.shเพื่อจัดเก็บตัวแปรสภาพแวดล้อม ซึ่งจะช่วยให้คุณโหลดซ้ำได้อย่างง่ายดายหากเซสชันขาดการเชื่อมต่อcat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - เรียกใช้ไฟล์เพื่อโหลดตัวแปรลงในเซสชันปัจจุบัน
source env.sh
6. จัดสรรคลัสเตอร์ GKE
- ในเทอร์มินัล ให้สร้างคลัสเตอร์ GKE ที่มี Node Pool เริ่มต้น โดยจะใช้เวลาประมาณ 5 นาที
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - จากนั้นเพิ่ม Node Pool ของ GPU ลงในคลัสเตอร์ ระบบจะใช้ Node Pool นี้ในการฝึกโมเดล
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - สุดท้าย ให้รับข้อมูลเข้าสู่ระบบสำหรับคลัสเตอร์ใหม่และยืนยันว่าคุณเชื่อมต่อกับคลัสเตอร์ได้
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. กำหนดค่าการเข้าถึง Hugging Face
เมื่อโครงสร้างพื้นฐานพร้อมแล้ว ตอนนี้คุณต้องระบุข้อมูลเข้าสู่ระบบที่จำเป็นสำหรับโปรเจ็กต์เพื่อเข้าถึงโมเดลและข้อมูล ในงานนี้ คุณจะได้รับโทเค็น Hugging Face ก่อน
รับโทเค็น Hugging Face
- หากไม่มีบัญชี Hugging Face ให้ไปที่ huggingface.co/join ในแท็บเบราว์เซอร์ใหม่ แล้วทำกระบวนการลงทะเบียนให้เสร็จสมบูรณ์
- เมื่อลงทะเบียนและเข้าสู่ระบบแล้ว ให้ไปที่ huggingface.co/meta-llama/Llama-2-7b-hf
- อ่านข้อกำหนดของใบอนุญาต แล้วคลิกปุ่มเพื่อยอมรับ
- ไปที่หน้าโทเค็นเพื่อการเข้าถึง Hugging Face ที่ huggingface.co/settings/tokens
- คลิก New Token
- ในส่วนบทบาท ให้เลือกอ่าน
- ในส่วนชื่อ ให้ป้อนชื่อที่สื่อความหมาย (เช่น finetuning-lab)
- คลิก Create a token
- คัดลอกโทเค็นที่สร้างขึ้นไปยังคลิปบอร์ด ซึ่งจะต้องใช้ในขั้นตอนถัดไป
อัปเดตตัวแปรสภาพแวดล้อม
ตอนนี้มาเพิ่มโทเค็น Hugging Face และชื่อสำหรับ Bucket ของ GCS ลงในไฟล์ env.sh กัน แทนที่ [your-hf-token] ด้วยโทเค็นที่คุณเพิ่งคัดลอก
- ในเทอร์มินัล ให้ต่อท้ายตัวแปรใหม่กับ
env.shแล้วโหลดซ้ำcat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. กำหนดค่า Workload Identity
จากนั้นคุณจะตั้งค่า Workload Identity ซึ่งเป็นวิธีที่แนะนำในการอนุญาตให้แอปพลิเคชันที่ทำงานใน GKE เข้าถึงบริการ Google Cloud โดยไม่ต้องจัดการคีย์บัญชีบริการแบบคงที่ ดูข้อมูลเพิ่มเติมได้ในเอกสารประกอบเกี่ยวกับ Workload Identity
- ก่อนอื่น ให้สร้างบัญชีบริการของ Google (GSA) ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - จากนั้นสร้างที่เก็บข้อมูล GCS และให้สิทธิ์ GSA ในการเข้าถึงที่เก็บข้อมูลดังกล่าวโดยทำดังนี้
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - ตอนนี้ให้สร้างบัญชีบริการ Kubernetes (KSA) โดยทำดังนี้
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - สุดท้าย ให้สร้างการเชื่อมโยงนโยบาย IAM ระหว่าง GSA กับ KSA ดังนี้
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. จัดเตรียมโมเดลพื้นฐาน
ในไปป์ไลน์ ML ที่ใช้งานจริง โดยปกติแล้วโมเดลขนาดใหญ่ เช่น Llama 2 (~13 GB) จะได้รับการจัดเตรียมล่วงหน้าใน Cloud Storage แทนที่จะดาวน์โหลดระหว่างการฝึก วิธีนี้ช่วยให้มีความน่าเชื่อถือมากขึ้น เข้าถึงได้เร็วขึ้น และหลีกเลี่ยงปัญหาเกี่ยวกับเครือข่าย Google Cloud มีโมเดลยอดนิยมเวอร์ชันที่ดาวน์โหลดไว้ล่วงหน้าในที่เก็บข้อมูล GCS สาธารณะ ซึ่งคุณจะใช้ในแล็บนี้
- ก่อนอื่น มาตรวจสอบว่าคุณเข้าถึงโมเดล Llama 2 ที่ Google จัดหาให้ได้ไหม
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - คัดลอกโมเดล Llama 2 จาก Bucket สาธารณะนี้ไปยัง Bucket ของโปรเจ็กต์ของคุณเองโดยใช้คำสั่ง
gcloud storageการโอนนี้ใช้เครือข่ายภายในความเร็วสูงของ Google และจะใช้เวลาเพียง 1-2 นาทีgcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - ยืนยันว่าคัดลอกไฟล์โมเดลอย่างถูกต้องโดยแสดงเนื้อหาของที่เก็บข้อมูล
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. เตรียมโค้ดการฝึก
ตอนนี้คุณจะสร้างแอปพลิเคชันที่สร้างโดยใช้คอนเทนเนอร์ซึ่งปรับแต่งโมเดล งานนี้ใช้ LoRA (Low-Rank Adaptation) ซึ่งเป็นเทคนิคการปรับแต่งแบบละเอียดที่มีประสิทธิภาพด้านพารามิเตอร์ (PEFT) ซึ่งช่วยลดข้อกำหนดด้านหน่วยความจำได้อย่างมากด้วยการฝึกเลเยอร์ "อแดปเตอร์" ขนาดเล็กเท่านั้นแทนที่จะฝึกทั้งโมเดล
ตอนนี้ให้สร้างสคริปต์ Python สำหรับไปป์ไลน์การฝึก
- ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อเปิดไฟล์
train.pycloudshell edit train.py - วางโค้ดต่อไปนี้ลงในไฟล์
train.py
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. ทำความเข้าใจรหัสการฝึก
train.py สคริปต์จะจัดระเบียบกระบวนการปรับแต่ง มาดูองค์ประกอบหลักๆ ของแอปกัน
การกำหนดค่า
สคริปต์ใช้ LoraConfig เพื่อกำหนดการตั้งค่า Low-Rank Adaptation LoRA ช่วยลดจำนวนพารามิเตอร์ที่ฝึกได้ลงอย่างมาก ทำให้คุณปรับแต่งโมเดลขนาดใหญ่ใน GPU ขนาดเล็กได้
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
เตรียมชุดข้อมูล
ฟังก์ชัน prepare_dataset จะโหลดชุดข้อมูล "American Stories" และประมวลผลเป็นกลุ่มที่แปลงเป็นโทเค็น โดยใช้ SimpleTextDataset ที่กำหนดเองเพื่อจัดการกับเทนเซอร์อินพุตอย่างมีประสิทธิภาพ
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
รถไฟ
ฟังก์ชัน train_model จะตั้งค่า Trainer ด้วยอาร์กิวเมนต์ที่เฉพาะเจาะจงซึ่งได้รับการเพิ่มประสิทธิภาพสำหรับภาระงานนี้ พารามิเตอร์ที่สำคัญมีดังนี้
gradient_accumulation_steps: ช่วยจำลองขนาดกลุ่มที่ใหญ่ขึ้นโดยไม่เพิ่มการใช้หน่วยความจำfp16=True: ใช้การฝึกที่มีความแม่นยำแบบผสมเพื่อลดหน่วยความจำและเพิ่มความเร็วgradient_checkpointing=True: ประหยัดหน่วยความจำด้วยการคำนวณการเปิดใช้งานใหม่ในระหว่างการส่งผ่านย้อนกลับแทนการจัดเก็บoptim="adamw_torch": ใช้การติดตั้งใช้งานเครื่องมือเพิ่มประสิทธิภาพ AdamW มาตรฐานจาก PyTorch
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
การอนุมาน
ฟังก์ชัน run_inference จะทำการทดสอบโมเดลที่ปรับแต่งแล้วอย่างรวดเร็วโดยใช้พรอมต์ตัวอย่าง ซึ่งจะช่วยให้มั่นใจได้ว่าโมเดลอยู่ในโหมดการประเมินและสร้างข้อความเพื่อยืนยันว่าอแดปเตอร์ทํางานได้อย่างถูกต้อง
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. สร้างคอนเทนเนอร์ให้แอปพลิเคชัน
ตอนนี้ให้สร้างอิมเมจคอนเทนเนอร์การฝึกโดยใช้ Docker แล้วพุชไปยัง Google Artifact Registry
- ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อเปิดไฟล์
Dockerfilecloudshell edit Dockerfile - วางโค้ดต่อไปนี้ลงในไฟล์
Dockerfile
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
สร้างและพุชคอนเทนเนอร์
- สร้างที่เก็บ Artifact Registry โดยทำดังนี้
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - สร้างและพุชอิมเมจโดยใช้ Cloud Build ดังนี้
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. ทำให้งานการปรับแต่งใช้งานได้
- สร้างไฟล์ Manifest ของงาน Kubernetes เพื่อเริ่มงานการปรับแต่ง ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้
cloudshell edit training_job.yaml - วางโค้ดต่อไปนี้ลงในไฟล์
training_job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- สุดท้าย ให้ใช้ไฟล์ Manifest ของงาน Kubernetes เพื่อเริ่มงานการปรับแต่งแบบละเอียดในคลัสเตอร์ GKE
envsubst < training_job.yaml | kubectl apply -f -
14. ตรวจสอบงานการฝึก
คุณตรวจสอบความคืบหน้าของงานการฝึกได้ในคอนโซล Google Cloud
- ไปที่หน้า Kubernetes Engine > ภาระงาน
ดูภาระงาน GKE - คลิก
llama-fine-tuningงานเพื่อดูรายละเอียด - แท็บรายละเอียดจะแสดงโดยค่าเริ่มต้น คุณดูเมตริกการใช้งาน GPU ได้ในส่วนทรัพยากร
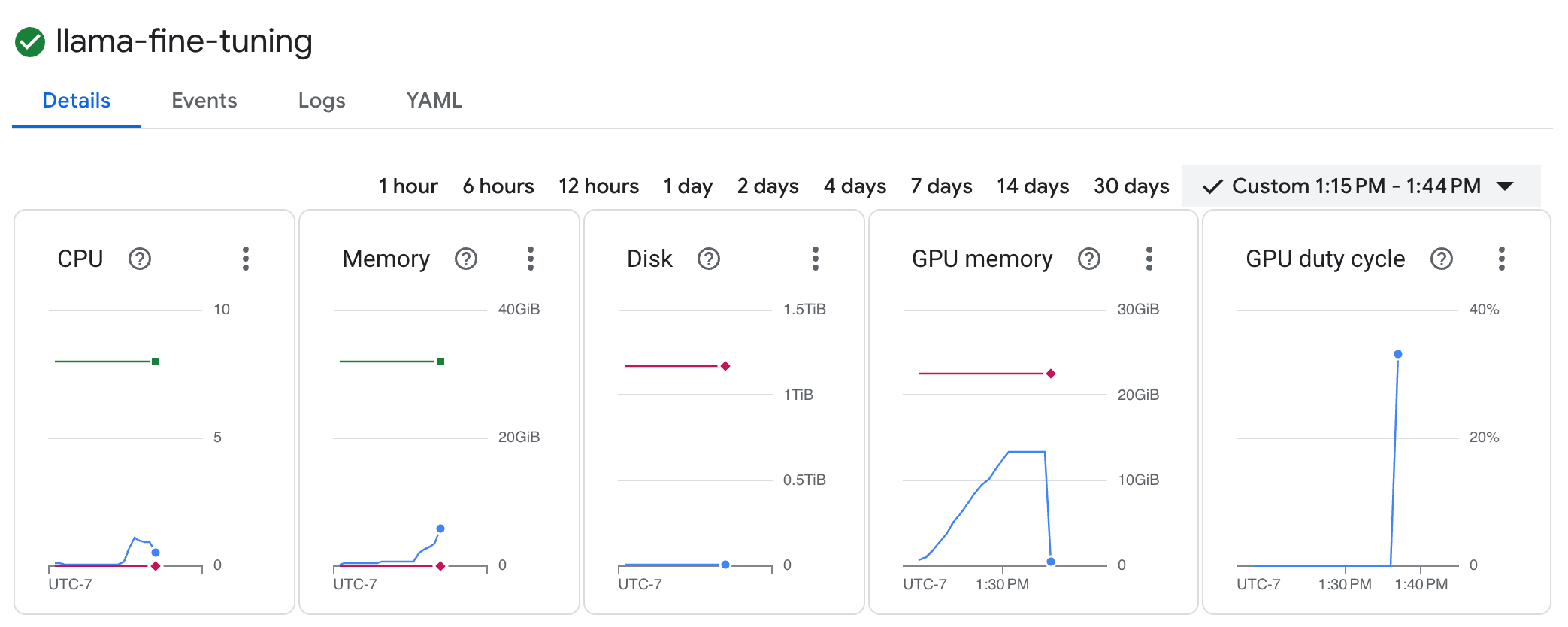
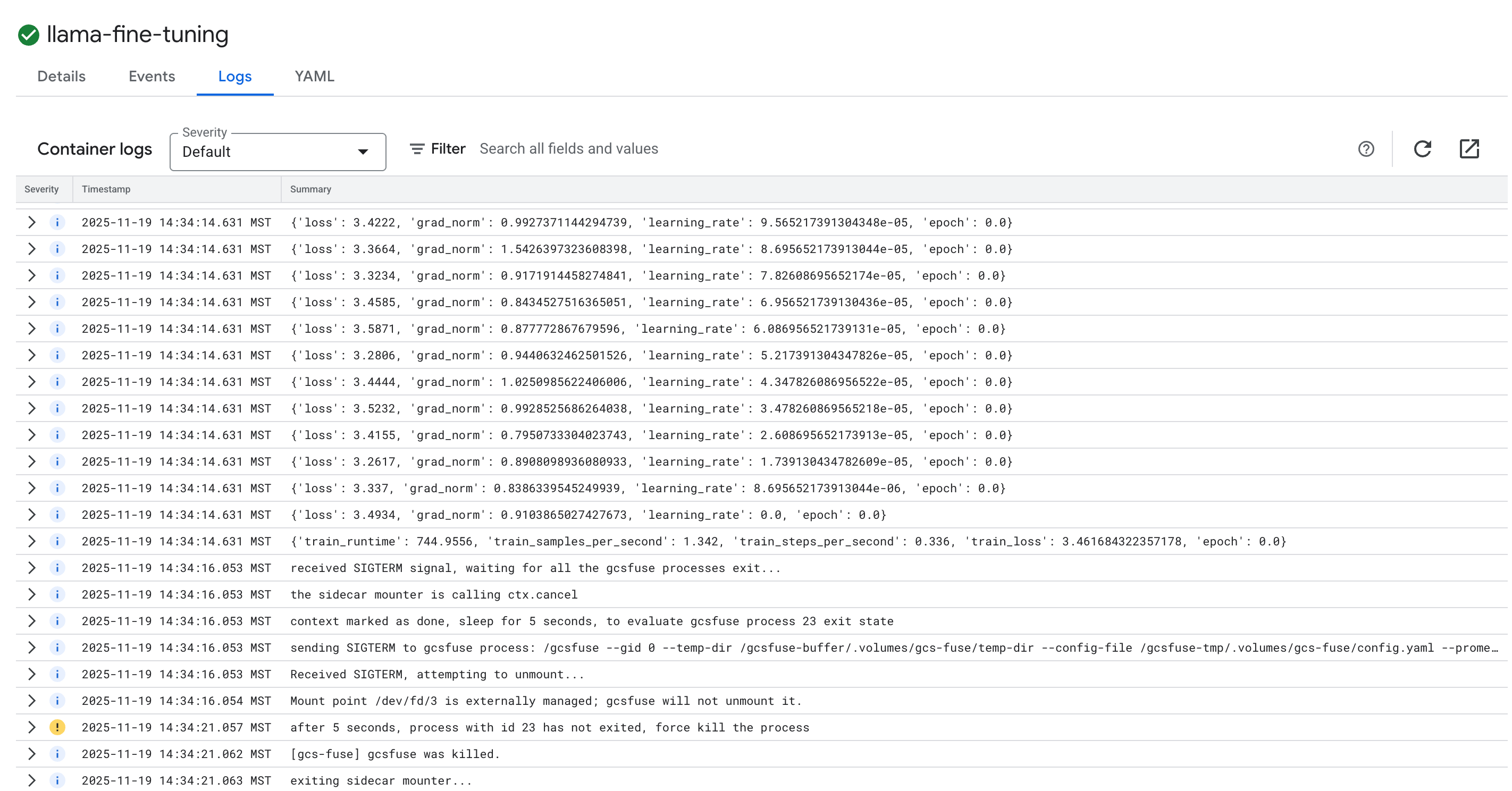
- คลิกแท็บบันทึกเพื่อดูบันทึกการฝึก คุณควรเห็นความคืบหน้าในการฝึก รวมถึงการสูญเสียและอัตราการเรียนรู้
15. ล้างข้อมูล
โปรดลบโปรเจ็กต์ที่มีทรัพยากรหรือเก็บโปรเจ็กต์ไว้และลบทรัพยากรแต่ละรายการเพื่อหลีกเลี่ยงการเรียกเก็บเงินจากบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในบทแนะนำนี้
ลบคลัสเตอร์ GKE
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
ลบที่เก็บ Artifact Registry
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
ลบ Bucket ของ GCS
gcloud storage rm -r gs://${BUCKET_NAME}
16. ยินดีด้วย
คุณปรับแต่ง LLM โอเพนซอร์สใน GKE เรียบร้อยแล้ว
สรุป
ใน Lab นี้ คุณจะได้ทำสิ่งต่อไปนี้
- จัดสรรคลัสเตอร์ GKE ที่มีการเร่งความเร็วด้วย GPU
- กำหนดค่า Workload Identity เพื่อให้เข้าถึงบริการ Google Cloud ได้อย่างปลอดภัย
- สร้างงานฝึก PyTorch ที่เป็นคอนเทนเนอร์โดยใช้ Docker และ Artifact Registry
- สร้างงานการปรับแต่งโดยใช้ LoRA เพื่อปรับ Llama 2 ให้เข้ากับชุดข้อมูลใหม่
ขั้นตอนถัดไป
- ดูข้อมูลเพิ่มเติมเกี่ยวกับ AI บน GKE
- สำรวจ Vertex AI Model Garden
- เข้าร่วมชุมชน Google Cloud เพื่อพูดคุยกับนักพัฒนาซอฟต์แวร์รายอื่นๆ
เส้นทางการเรียนรู้ของ Google Cloud
แล็บนี้เป็นส่วนหนึ่งของเส้นทางการเรียนรู้AI พร้อมใช้งานจริงด้วย Google Cloud สำรวจหลักสูตรทั้งหมดเพื่อเชื่อมช่องว่างจากต้นแบบไปสู่การผลิต
แชร์ความคืบหน้าของคุณด้วยแฮชแท็ก #ProductionReadyAI