
1. Giriş
Bu laboratuvarda, popüler bir açık kaynaklı dil modeli olan Llama 2 için Google Kubernetes Engine (GKE) kullanarak eksiksiz ve üretime hazır bir ince ayar ardışık düzeni oluşturmayı öğreneceksiniz. Mimari kararlar, yaygın değişimler ve gerçek dünyadaki makine öğrenimi operasyonları (MLOps) iş akışlarını yansıtan bileşenler hakkında bilgi edineceksiniz.
GKE kümesi sağlayacak, LoRA (Low-Rank Adaptation) kullanarak kapsayıcılı bir eğitim ardışık düzeni oluşturacak ve eğitim işinizi GKE'de çalıştıracaksınız.
Mimarisine Genel Bakış
Bugün oluşturacağımız öğeler:
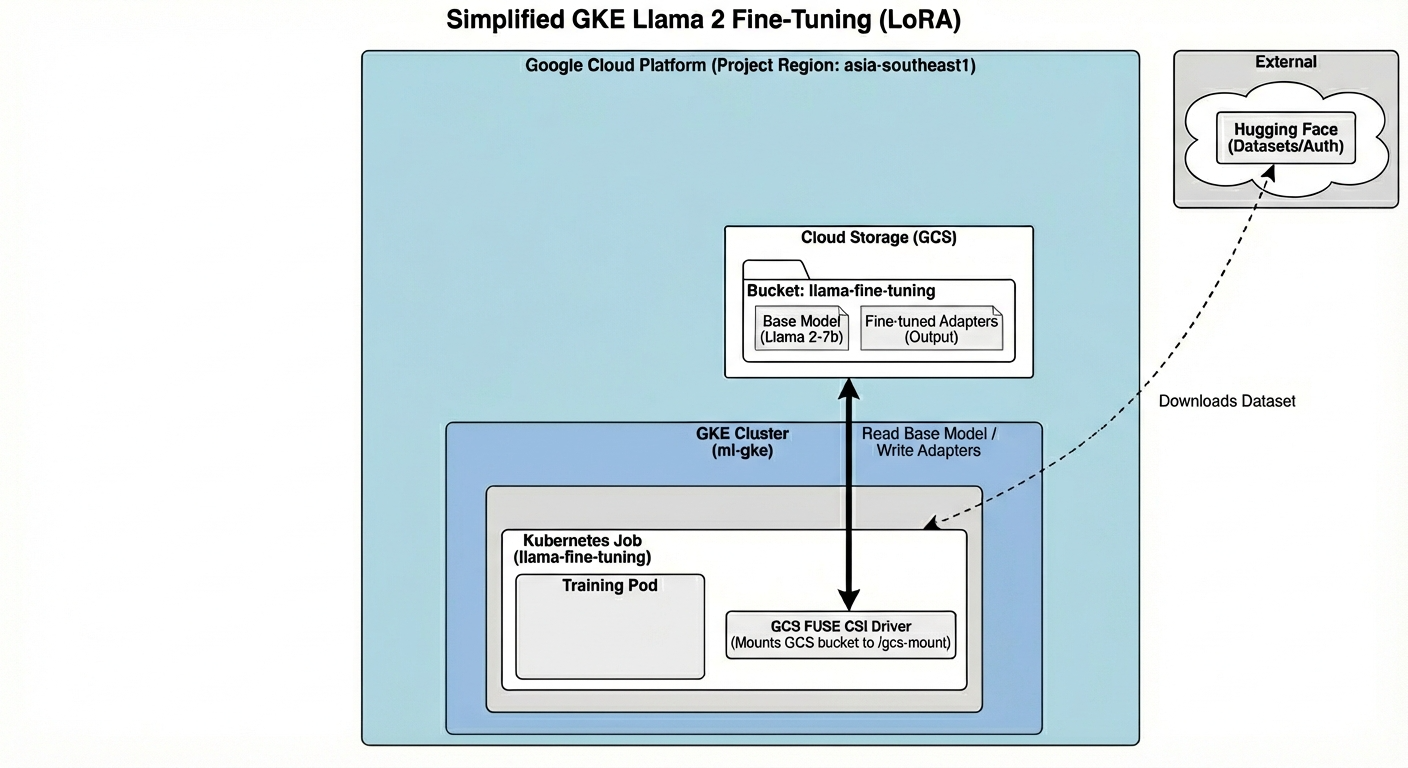
Mimari şunları içerir:
- GKE kümesi: İşlem kaynaklarımızı yönetir.
- GPU düğümü havuzu: Eğitim için 1x L4 GPU (Spot)
- GCS paketi: Modelleri ve veri kümelerini depolar.
- Workload Identity: K8s ve GCS arasında güvenli erişim
Neler öğreneceksiniz?
- Makine öğrenimi iş yükleri için optimize edilmiş özelliklere sahip bir GKE kümesi sağlayın ve yapılandırın.
- Workload Identity'yi kullanarak GKE'den diğer Google Cloud hizmetlerine güvenli ve anahtarsız erişim uygulayın.
- Docker kullanarak container'a alınmış bir eğitim işlem hattı oluşturun.
- LoRA ile parametreleri verimli şekilde kullanma (PEFT) sayesinde açık kaynaklı bir modeli verimli bir şekilde ince ayarlayın.
2. Proje ayarlama
Google Hesabı
Kişisel Google Hesabınız yoksa Google Hesabı oluşturmanız gerekir.
İş veya okul hesabı yerine kişisel hesap kullanın.
Google Cloud Console'da oturum açma
Kişisel bir Google Hesabı kullanarak Google Cloud Console'da oturum açın.
Proje oluşturma (isteğe bağlı)
Bu laboratuvarda kullanmak istediğiniz mevcut bir projeniz yoksa buradan yeni bir proje oluşturun.
3. Cloud Shell Düzenleyici'yi açma
- Doğrudan Cloud Shell Düzenleyici'ye gitmek için bu bağlantıyı tıklayın.
- Bugün herhangi bir noktada yetkilendirmeniz istenirse devam etmek için Yetkilendir'i tıklayın.
- Terminal ekranın alt kısmında görünmüyorsa açın:
- Görünüm'ü tıklayın.
- Terminal'i tıklayın.
- Terminalde şu komutla projenizi ayarlayın:
gcloud config set project [PROJECT_ID]- Örnek:
gcloud config set project lab-project-id-example - Proje kimliğinizi hatırlamıyorsanız tüm proje kimliklerinizi şu komutla listeleyebilirsiniz:
gcloud projects list
- Örnek:
- Şu mesajı görmeniz gerekir:
Updated property [core/project].
4. API'leri etkinleştir
GKE ve diğer hizmetleri kullanmak için Google Cloud projenizde gerekli API'leri etkinleştirmeniz gerekir.
- Terminalde API'leri etkinleştirin:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
API'lerle tanışın
- Google Kubernetes Engine API (
container.googleapis.com), uygulamanızı çalıştıran GKE kümesini oluşturmanıza ve yönetmenize olanak tanır. - Artifact Registry API (
artifactregistry.googleapis.com), kapsayıcı resimlerinizi depolamak için güvenli ve özel bir depo sağlar. - Cloud Build API (
cloudbuild.googleapis.com), kapsayıcı resminizi bulutta oluşturmak içingcloud builds submitkomutu tarafından kullanılır. - IAM API (
iam.googleapis.com), Google Cloud kaynaklarınız için erişim denetimini ve kimliği yönetmenize olanak tanır. - Compute Engine API (
compute.googleapis.com), Google'ın altyapısında çalışan güvenli ve özelleştirilebilir sanal makineler sağlar. - IAM Service Account Credentials API (
iamcredentials.googleapis.com), hizmet hesapları için kısa ömürlü kimlik bilgilerinin oluşturulmasına olanak tanır. - Cloud Storage API (
storage.googleapis.com), bulutta veri depolamanıza ve almanıza olanak tanır. Burada model ve veri kümesi depolama için kullanılır.
5. Proje ortamını ayarlama
Çalışma dizini oluşturma
- Terminalde projeniz için bir dizin oluşturun ve bu dizine gidin.
mkdir llama-finetuning cd llama-finetuning
Ortam değişkenlerini ayarlama
- Terminalde, ortam değişkenlerinizi depolamak için
env.shadlı bir dosya oluşturun. Bu sayede, oturumunuzun bağlantısı kesilirse bunları kolayca yeniden yükleyebilirsiniz.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - Değişkenleri mevcut oturumunuza yüklemek için dosyayı kaynaklayın:
source env.sh
6. GKE kümesini sağlama
- Terminalde, varsayılan düğüm havuzuna sahip GKE kümesini oluşturun. Bu işlem yaklaşık 5 dakika sürer.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - Ardından kümeye bir GPU düğüm havuzu ekleyin. Bu düğüm havuzu, modeli eğitmek için kullanılır.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - Son olarak, yeni kümenizin kimlik bilgilerini alın ve kümeye bağlanabildiğinizi doğrulayın.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Hugging Face erişimini yapılandırma
Altyapınız hazır olduğunda, projenize modelinize ve verilerinize erişmek için gerekli kimlik bilgilerini sağlamanız gerekir. Bu görevde ilk olarak bir Hugging Face jetonu alacaksınız.
Hugging Face jetonu edinme
- Hugging Face hesabınız yoksa yeni bir tarayıcı sekmesinde huggingface.co/join adresine gidin ve kayıt işlemini tamamlayın.
- Kaydolup giriş yaptıktan sonra huggingface.co/meta-llama/Llama-2-7b-hf adresine gidin.
- Lisans şartlarını okuyun ve kabul etmek için düğmeyi tıklayın.
- huggingface.co/settings/tokens adresinden Hugging Face erişim jetonları sayfanıza gidin.
- Yeni jeton'u tıklayın.
- Role (Rol) için Read'i (Okuma) seçin.
- Name (Ad) alanına açıklayıcı bir ad girin (ör. finetuning-lab).
- Jeton oluştur'u tıklayın.
- Oluşturulan jetonu panonuza kopyalayın. Bu bilgiye bir sonraki adımda ihtiyacınız olacak.
Ortam değişkenlerini güncelleme
Şimdi env.sh dosyanıza Hugging Face jetonunuzu ve GCS paketinize bir ad ekleyelim. [your-hf-token] kısmını az önce kopyaladığınız jetonla değiştirin.
- Terminalde, yeni değişkenleri
env.sh'ye ekleyin ve yeniden yükleyin:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. Workload Identity'yi yapılandırma
Ardından, GKE'de çalışan uygulamaların statik hizmet hesabı anahtarlarını yönetmeye gerek kalmadan Google Cloud hizmetlerine erişmesine izin vermek için önerilen yöntem olan Workload Identity'yi ayarlayacaksınız. Daha fazla bilgiyi Workload Identity belgelerinde bulabilirsiniz.
- Öncelikle bir Google hizmet hesabı (GSA) oluşturun. Terminalde şunu çalıştırın:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - Ardından, GCS paketini oluşturun ve GSA'ya pakete erişim izni verin:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - Şimdi bir Kubernetes hizmet hesabı (KSA) oluşturun:
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - Son olarak, GSA ile KSA arasında IAM politika bağlaması oluşturun:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. Temel modeli hazırlama
Üretim ML işlem hatlarında, Llama 2 (~13 GB) gibi büyük modeller genellikle eğitim sırasında indirilmek yerine Cloud Storage'da önceden hazırlanır. Bu yaklaşım daha iyi güvenilirlik ve daha hızlı erişim sağlar ve ağ sorunlarını önler. Google Cloud, bu laboratuvarda kullanacağınız popüler modellerin önceden indirilmiş sürümlerini herkese açık GCS paketlerinde sunar.
- Öncelikle, Google tarafından sağlanan Llama 2 modeline erişebildiğinizi doğrulayalım:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ gcloud storagekomutunu kullanarak bu herkese açık paketteki Llama 2 modelini kendi projenizin paketine kopyalayın. Bu aktarımda Google'ın yüksek hızlı dahili ağı kullanılır ve işlem yalnızca bir veya iki dakika sürer.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/- Bucket'ınızın içeriğini listeleyerek model dosyalarının doğru şekilde kopyalandığını doğrulayın.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. Eğitim kodunu hazırlama
Şimdi modeli ince ayar yapacak container mimarisine alınmış uygulamayı oluşturacaksınız. Bu görevde, tüm modeli eğitmek yerine yalnızca küçük "adaptör" katmanlarını eğiterek bellek gereksinimlerini önemli ölçüde azaltan, parametre açısından verimli bir ince ayar (PEFT) tekniği olan LoRA (Low-Rank Adaptation) kullanılır.
Şimdi eğitim ardışık düzeni için Python komut dosyalarını oluşturun.
- Terminalde,
train.pydosyasını açmak için aşağıdaki komutu çalıştırın:cloudshell edit train.py - Aşağıdaki kodu
train.pydosyasına yapıştırın:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. Eğitim kodunu anlama
train.py komut dosyası, ince ayar sürecini düzenler. Temel bileşenlerini inceleyelim.
Yapılandırma
Komut dosyası, düşük sıralı uyarlama ayarlarını tanımlamak için LoraConfig kullanır. LoRA, eğitilebilir parametrelerin sayısını önemli ölçüde azaltır ve daha küçük GPU'larda büyük modelleri ince ayarlamanıza olanak tanır.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
Veri kümesini hazırlama
prepare_dataset işlevi, "American Stories" veri kümesini yükler ve jetonlaştırılmış parçalar halinde işler. Giriş tensörlerini verimli bir şekilde işlemek için özel bir SimpleTextDataset kullanır.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
Tren
train_model işlevi, Trainer işlevini bu iş yükü için optimize edilmiş belirli bağımsız değişkenlerle ayarlar. Temel parametreler şunlardır:
gradient_accumulation_steps: Bellek kullanımını artırmadan daha büyük bir grup boyutu simüle etmeye yardımcı olur.fp16=True: Belleği azaltmak ve hızı artırmak için karma duyarlıklı eğitim kullanır.gradient_checkpointing=True: Etkinleştirmeleri saklamak yerine geriye doğru geçiş sırasında yeniden hesaplayarak bellekten tasarruf sağlar.optim="adamw_torch": PyTorch'taki standart AdamW optimizer uygulamasını kullanır.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
Çıkarım
run_inference işlevi, örnek bir istem kullanarak ince ayarlı modelin hızlı bir testini gerçekleştirir. Modelin değerlendirme modunda olmasını sağlar ve bağdaştırıcıların doğru şekilde çalıştığını doğrulamak için metin oluşturur.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. Uygulamayı kapsayıcıya alma
Şimdi Docker'ı kullanarak eğitim container görüntüsünü oluşturun ve Google Artifact Registry'ye aktarın.
- Terminalde,
Dockerfiledosyasını açmak için aşağıdaki komutu çalıştırın:cloudshell edit Dockerfile - Aşağıdaki kodu
Dockerfiledosyasına yapıştırın:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
Container'ı oluşturun ve aktarın
- Artifact Registry deposunu oluşturun:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Cloud Build'i kullanarak görüntüyü oluşturun ve aktarın:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. İnce ayar işini dağıtma
- İnce ayar işini başlatmak için Kubernetes iş manifestini oluşturun. Terminalde şunu çalıştırın:
cloudshell edit training_job.yaml - Aşağıdaki kodu
training_job.yamldosyasına yapıştırın:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- Son olarak, GKE kümenizde ince ayar işini başlatmak için Kubernetes iş manifestini uygulayın.
envsubst < training_job.yaml | kubectl apply -f -
14. Eğitim işini izleme
Eğitim işinizin ilerleme durumunu Google Cloud Console'da izleyebilirsiniz.
- Kubernetes Engine > İş Yükleri sayfasına gidin.
GKE iş yüklerini görüntüleme - Ayrıntılarını görmek için
llama-fine-tuningişini tıklayın. - Ayrıntılar sekmesi varsayılan olarak gösterilir. GPU kullanım metriklerini Kaynaklar bölümünde görebilirsiniz.
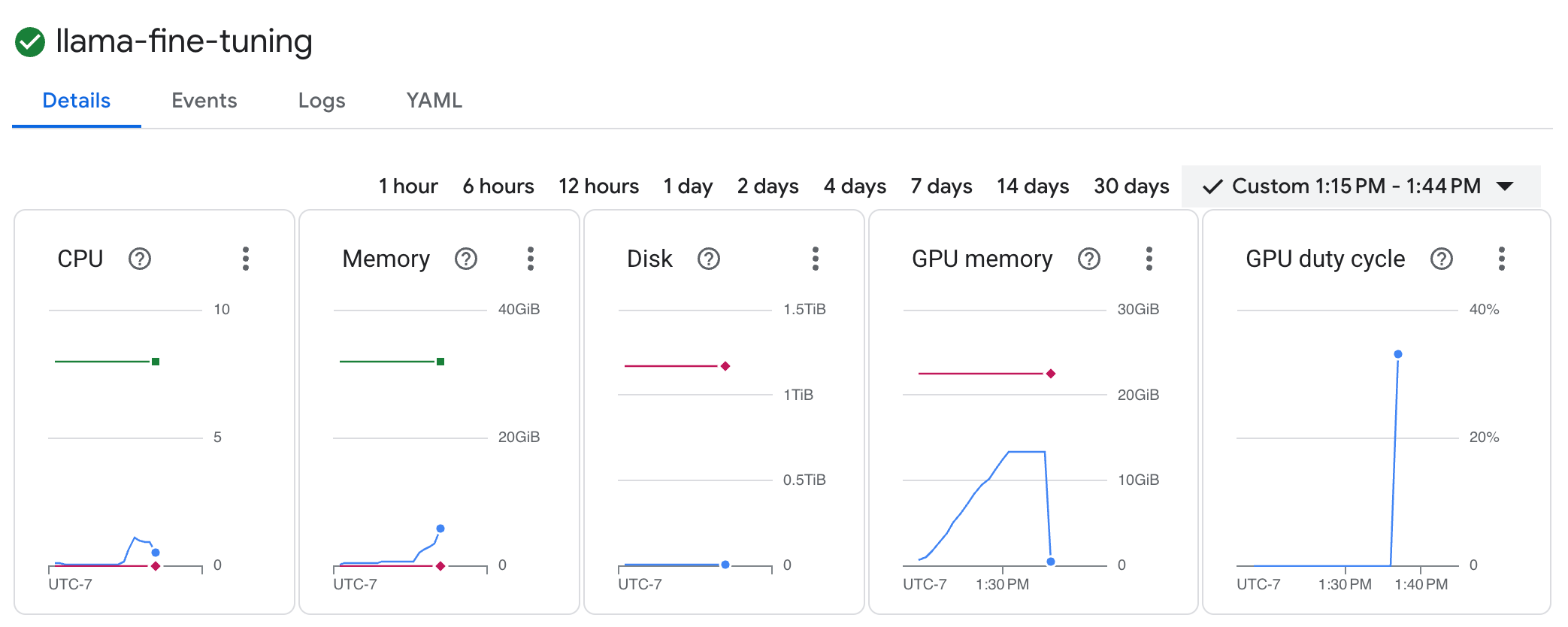
- Eğitim günlüklerini görüntülemek için Günlükler sekmesini tıklayın. Kaybı ve öğrenme hızını içeren eğitim ilerlemesini görürsünüz.
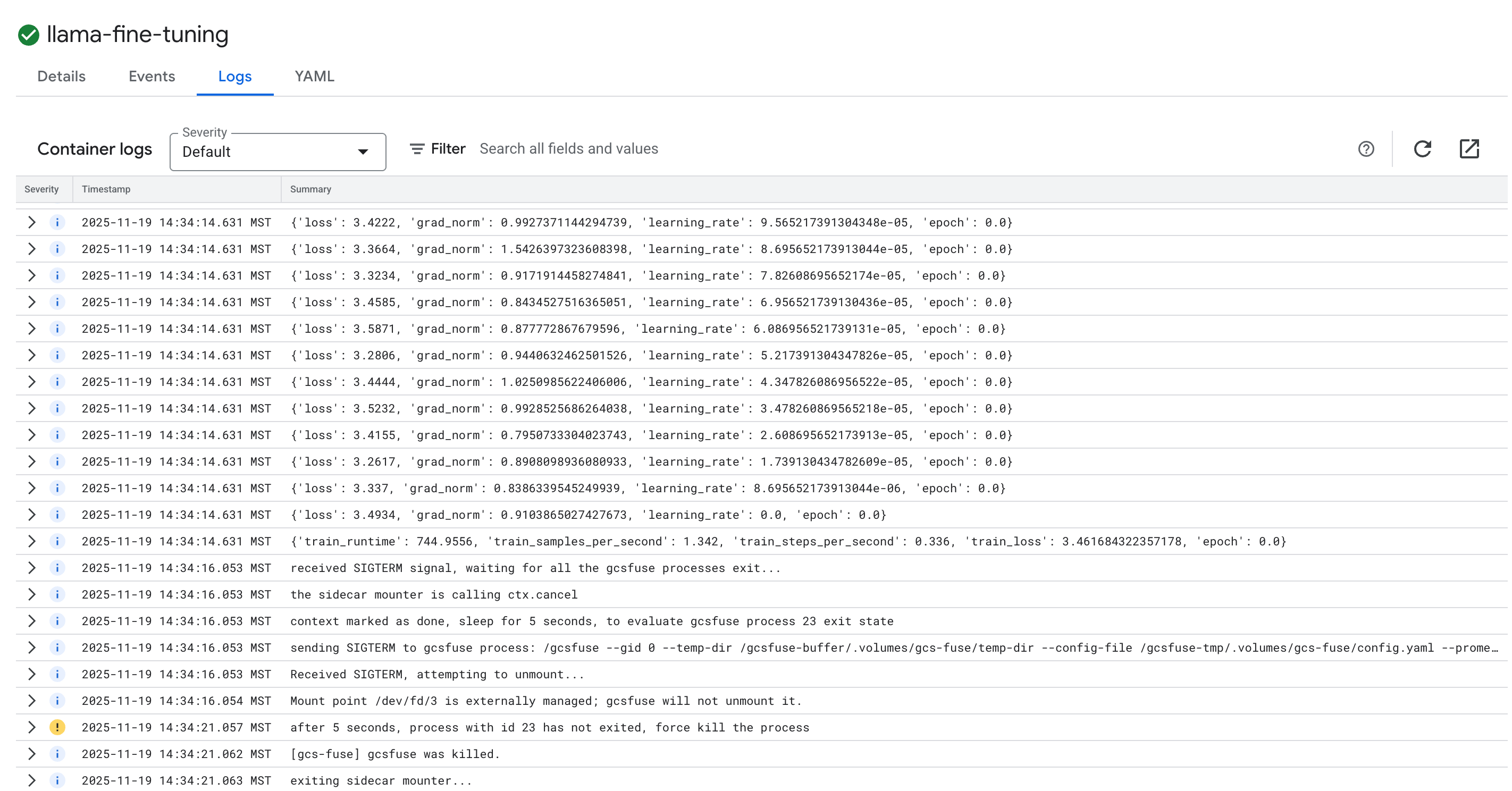
15. Temizleme
Bu eğitimde kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini önlemek amacıyla kaynakları içeren projeyi silin veya projeyi koruyup tek tek kaynakları silin.
GKE kümesini silme
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Artifact Registry deposunu silme
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
GCS paketini silin
gcloud storage rm -r gs://${BUCKET_NAME}
16. Tebrikler!
GKE'de açık kaynaklı bir LLM'yi başarıyla ince ayarladınız.
Özet
Bu laboratuvarda şunları öğreneceksiniz:
- GPU hızlandırmalı bir GKE kümesi sağlandı.
- Google Cloud hizmetlerine güvenli erişim için Workload Identity'yi yapılandırmış olmanız gerekir.
- Docker ve Artifact Registry kullanarak bir PyTorch eğitim işini kapsayıcıya dönüştürdü.
- Llama 2'yi yeni bir veri kümesine uyarlamak için LoRA kullanarak bir ince ayar işi dağıttı.
Sırada ne var?
- GKE'de yapay zeka hakkında daha fazla bilgi edinin.
- Vertex AI Model Garden'ı keşfedin.
- Diğer geliştiricilerle bağlantı kurmak için Google Cloud Topluluğu'na katılın.
Google Cloud Öğrenme Rotası
Bu laboratuvar, Google Cloud ile Üretime Hazır Yapay Zeka öğrenme rotasının bir parçasıdır. Prototip aşamasından üretim aşamasına geçiş yapmak için tüm müfredatı inceleyin.
İlerlemenizi #ProductionReadyAI hashtag'iyle paylaşın.