
1. Giới thiệu
Trong phòng thí nghiệm này, bạn sẽ tìm hiểu cách xây dựng một quy trình tinh chỉnh hoàn chỉnh, cấp sản xuất cho Llama 2 (một mô hình ngôn ngữ nguồn mở phổ biến) bằng Google Kubernetes Engine (GKE). Bạn sẽ tìm hiểu về các quyết định liên quan đến cấu trúc, những điểm đánh đổi thường gặp và các thành phần phản ánh quy trình hoạt động của Học máy (MLOps) trong thế giới thực.
Bạn sẽ cung cấp một cụm GKE, tạo một quy trình huấn luyện trong vùng chứa bằng cách sử dụng LoRA (Thích ứng cấp thấp) và chạy công việc huấn luyện trên GKE.
Tổng quan về Cấu trúc (Architecture)
Sau đây là những gì chúng ta sẽ xây dựng hôm nay:
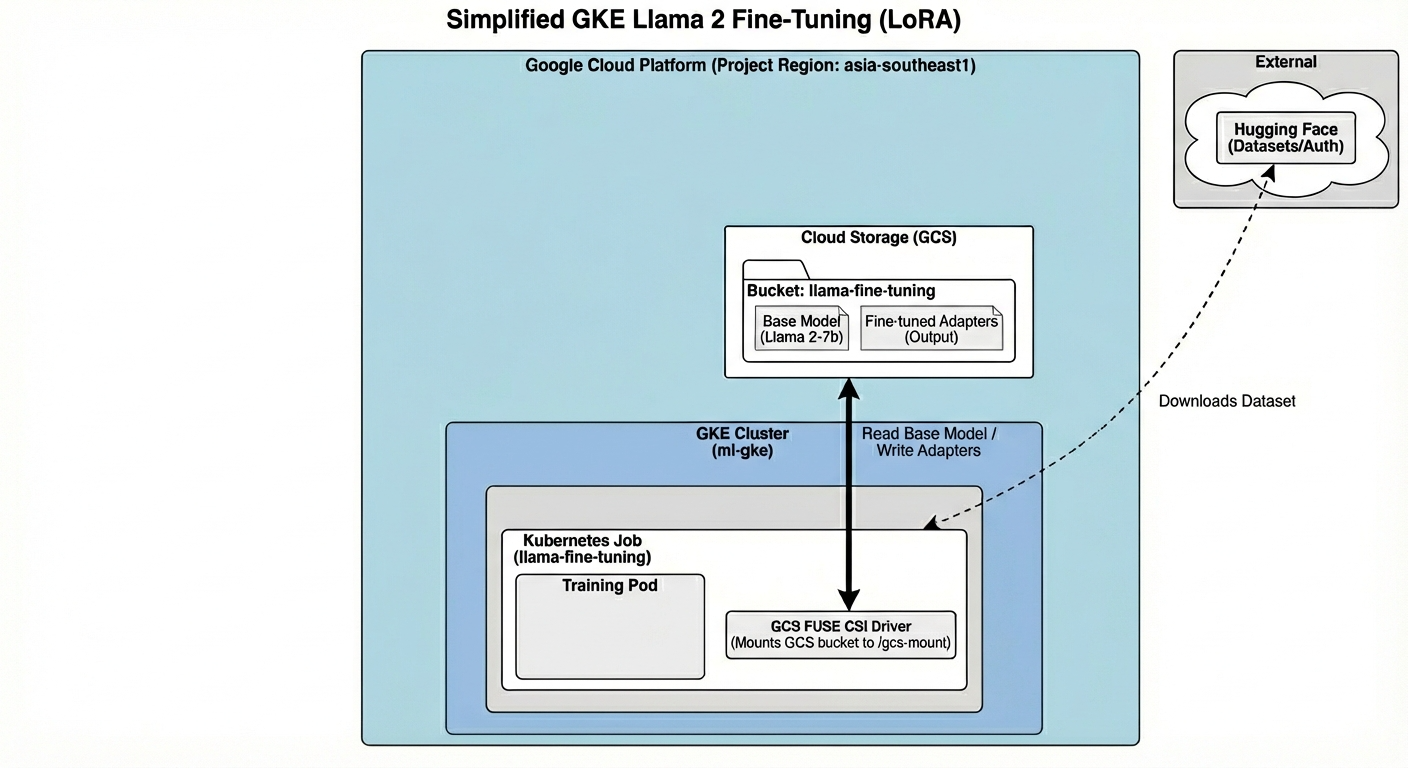
Cấu trúc này bao gồm:
- Cụm GKE: Quản lý tài nguyên điện toán của chúng tôi
- Nhóm nút GPU: 1 GPU L4 (Spot) để huấn luyện
- Bộ chứa GCS: Lưu trữ các mô hình và tập dữ liệu
- Workload Identity: Quyền truy cập an toàn giữa K8s và GCS
Kiến thức bạn sẽ học được
- Cung cấp và định cấu hình một cụm GKE có các tính năng được tối ưu hoá cho khối lượng công việc học máy.
- Triển khai quyền truy cập an toàn, không cần khoá từ GKE vào các dịch vụ khác của Google Cloud bằng Workload Identity.
- Tạo một quy trình huấn luyện được chứa trong vùng chứa bằng Docker.
- Tinh chỉnh một mô hình nguồn mở một cách hiệu quả bằng cách sử dụng phương pháp Tinh chỉnh hiệu quả về tham số (PEFT) với LoRA.
2. Thiết lập dự án
Tài khoản Google
Nếu chưa có Tài khoản Google cá nhân, bạn phải tạo một Tài khoản Google.
Sử dụng tài khoản cá nhân thay vì tài khoản trường học hoặc cơ quan.
Đăng nhập vào Google Cloud Console
Đăng nhập vào Google Cloud Console bằng Tài khoản Google cá nhân.
Tạo dự án (không bắt buộc)
Nếu bạn không có dự án hiện tại nào muốn sử dụng cho lớp học này, hãy tạo một dự án mới tại đây.
3. Mở Trình chỉnh sửa Cloud Shell
- Nhấp vào đường liên kết này để chuyển trực tiếp đến Cloud Shell Editor
- Nếu được nhắc uỷ quyền vào bất kỳ thời điểm nào trong ngày hôm nay, hãy nhấp vào Uỷ quyền để tiếp tục.
- Nếu thiết bị đầu cuối không xuất hiện ở cuối màn hình, hãy mở thiết bị đầu cuối:
- Nhấp vào Xem
- Nhấp vào Terminal (Thiết bị đầu cuối)
- Trong cửa sổ dòng lệnh, hãy thiết lập dự án bằng lệnh sau:
gcloud config set project [PROJECT_ID]- Ví dụ:
gcloud config set project lab-project-id-example - Nếu không nhớ mã dự án, bạn có thể liệt kê tất cả mã dự án bằng cách dùng lệnh:
gcloud projects list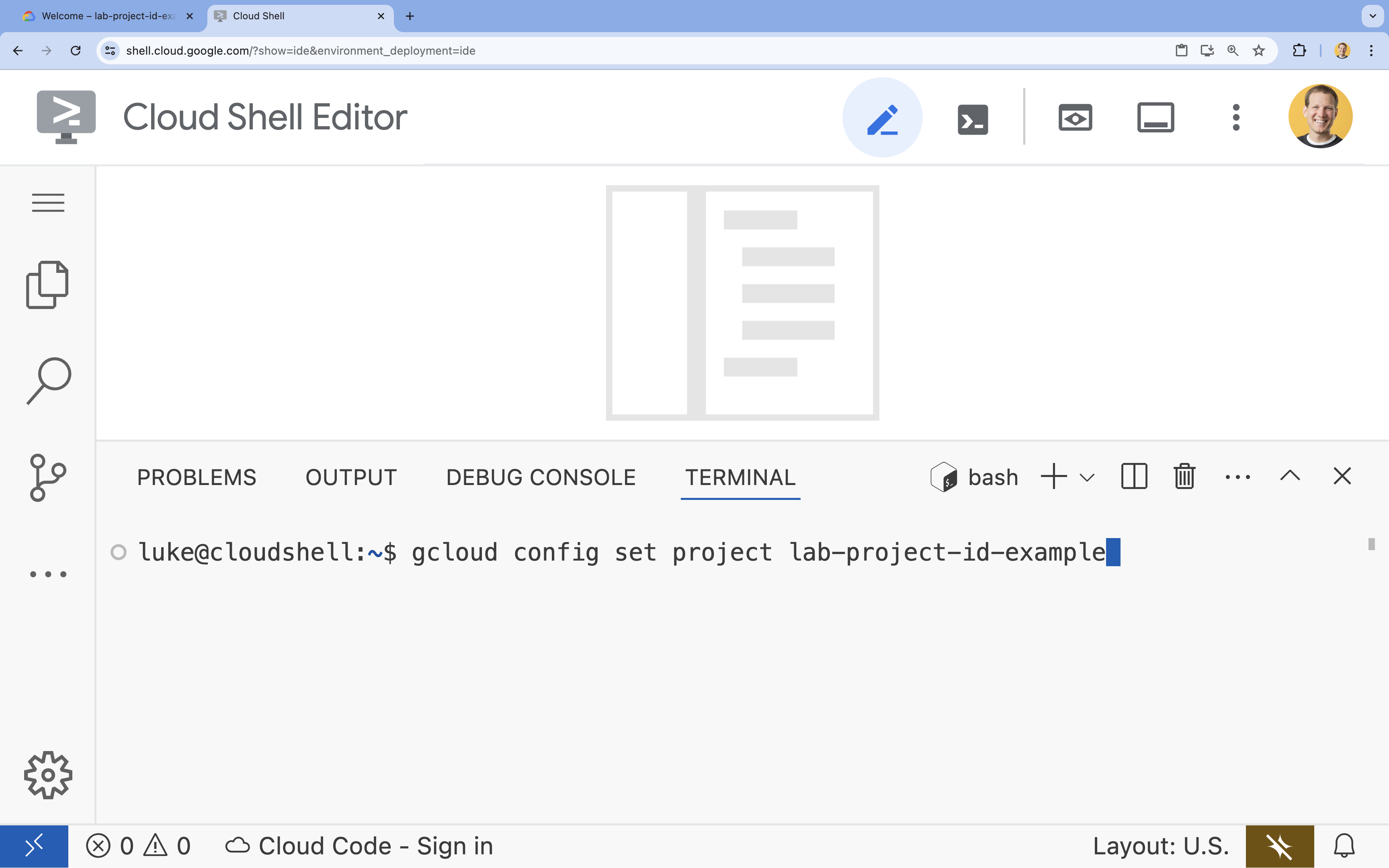
- Ví dụ:
- Bạn sẽ thấy thông báo sau:
Updated property [core/project].
4. Bật API
Để sử dụng GKE và các dịch vụ khác, bạn cần bật các API cần thiết trong dự án Google Cloud của mình.
- Trong dòng lệnh, hãy bật các API:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
Giới thiệu về các API
- Google Kubernetes Engine API (
container.googleapis.com) cho phép bạn tạo và quản lý cụm GKE chạy ứng dụng của bạn. - Artifact Registry API (
artifactregistry.googleapis.com) cung cấp một kho lưu trữ riêng tư và an toàn để lưu trữ hình ảnh vùng chứa. - Cloud Build API (
cloudbuild.googleapis.com) được lệnhgcloud builds submitdùng để tạo hình ảnh vùng chứa trên đám mây. - IAM API (
iam.googleapis.com) cho phép bạn quản lý quyền kiểm soát truy cập và danh tính cho các tài nguyên trên Google Cloud. - Compute Engine API (
compute.googleapis.com) cung cấp các máy ảo có thể tuỳ chỉnh và bảo mật, chạy trên cơ sở hạ tầng của Google. - IAM Service Account Credentials API (
iamcredentials.googleapis.com) cho phép tạo thông tin đăng nhập có thời hạn ngắn cho tài khoản dịch vụ. - Cloud Storage API (
storage.googleapis.com) cho phép bạn lưu trữ và truy xuất dữ liệu trên đám mây, được dùng ở đây để lưu trữ mô hình và tập dữ liệu.
5. Thiết lập môi trường dự án
Tạo thư mục làm việc
- Trong thiết bị đầu cuối, hãy tạo một thư mục cho dự án của bạn rồi chuyển đến thư mục đó.
mkdir llama-finetuning cd llama-finetuning
Thiết lập các biến môi trường
- Trong thiết bị đầu cuối, hãy tạo một tệp có tên là
env.shđể lưu trữ các biến môi trường. Nhờ đó, bạn có thể dễ dàng tải lại các trang này nếu phiên của bạn bị ngắt kết nối.cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - Nguồn tệp để tải các biến vào phiên hiện tại:
source env.sh
6. Cung cấp Cụm GKE
- Trong thiết bị đầu cuối, hãy tạo cụm GKE bằng một nhóm nút mặc định. Quá trình này sẽ mất khoảng 5 phút.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - Tiếp theo, hãy thêm một bộ nút GPU vào cụm. Bộ nút này sẽ được dùng để huấn luyện mô hình.
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - Cuối cùng, hãy lấy thông tin đăng nhập cho cụm mới và xác minh rằng bạn có thể kết nối với cụm đó.
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. Định cấu hình quyền truy cập vào Hugging Face
Khi cơ sở hạ tầng đã sẵn sàng, bạn cần cung cấp cho dự án của mình thông tin đăng nhập cần thiết để truy cập vào mô hình và dữ liệu. Trong nhiệm vụ này, trước tiên bạn sẽ nhận được một mã thông báo Hugging Face.
Nhận mã thông báo Hugging Face
- Nếu bạn chưa có tài khoản Hugging Face, hãy chuyển đến huggingface.co/join trong một thẻ trình duyệt mới rồi hoàn tất quy trình đăng ký.
- Sau khi đăng ký và đăng nhập, hãy chuyển đến huggingface.co/meta-llama/Llama-2-7b-hf.
- Đọc các điều khoản cấp phép rồi nhấp vào nút để chấp nhận.
- Chuyển đến trang mã truy cập Hugging Face tại huggingface.co/settings/tokens.
- Nhấp vào Mã thông báo mới.
- Đối với Vai trò, hãy chọn Đọc.
- Đối với Tên, hãy nhập một tên mô tả (ví dụ: finetuning-lab).
- Nhấp vào Tạo mã thông báo.
- Sao chép mã thông báo đã tạo vào bảng nhớ tạm. Bạn sẽ cần mã này trong bước tiếp theo.
Cập nhật các biến môi trường
Bây giờ, hãy thêm mã thông báo Hugging Face và tên cho nhóm GCS vào tệp env.sh của bạn. Thay thế [your-hf-token] bằng mã thông báo mà bạn vừa sao chép.
- Trong thiết bị đầu cuối, hãy thêm các biến mới vào
env.shrồi tải lại các biến đó:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. Định cấu hình Workload Identity
Tiếp theo, bạn sẽ thiết lập Workload Identity. Đây là cách được đề xuất để cho phép các ứng dụng chạy trên GKE truy cập vào các dịch vụ của Google Cloud mà không cần quản lý các khoá tài khoản dịch vụ tĩnh. Bạn có thể tìm hiểu thêm trong tài liệu về Workload Identity.
- Trước tiên, hãy tạo một Tài khoản dịch vụ Google (GSA). Trong thiết bị đầu cuối, hãy chạy:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - Tiếp theo, hãy tạo bộ chứa GCS và cấp cho GSA quyền truy cập vào bộ chứa đó:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - Bây giờ, hãy tạo một Tài khoản dịch vụ Kubernetes (KSA):
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - Cuối cùng, hãy tạo mối liên kết chính sách IAM giữa GSA và KSA:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. Giai đoạn mô hình cơ sở
Trong các quy trình học máy sản xuất, các mô hình lớn như Llama 2 (~13 GB) thường được chuẩn bị trước trong Cloud Storage thay vì được tải xuống trong quá trình huấn luyện. Phương pháp này mang lại độ tin cậy cao hơn, khả năng truy cập nhanh hơn và tránh được các vấn đề về mạng. Google Cloud cung cấp các phiên bản đã tải sẵn của các mô hình phổ biến trong các bộ chứa GCS công khai. Bạn sẽ sử dụng các phiên bản này cho phòng thí nghiệm này.
- Trước tiên, hãy xác minh rằng bạn có thể truy cập vào mô hình Llama 2 do Google cung cấp:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - Sao chép mô hình Llama 2 từ nhóm công khai này vào nhóm của dự án bằng lệnh
gcloud storage. Quá trình chuyển này sử dụng mạng nội bộ tốc độ cao của Google và chỉ mất một hoặc hai phút.gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - Xác minh rằng các tệp mô hình đã được sao chép đúng cách bằng cách liệt kê nội dung của nhóm.
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. Chuẩn bị mã huấn luyện
Bây giờ, bạn sẽ tạo ứng dụng trong vùng chứa để tinh chỉnh mô hình. Tác vụ này sử dụng LoRA (Thích ứng cấp thấp), một kỹ thuật tinh chỉnh hiệu quả về tham số (PEFT) giúp giảm đáng kể yêu cầu về bộ nhớ bằng cách chỉ huấn luyện các lớp "bộ điều hợp" nhỏ thay vì toàn bộ mô hình.
Bây giờ, hãy tạo tập lệnh Python cho quy trình huấn luyện.
- Trong dòng lệnh, hãy chạy lệnh sau để mở tệp
train.py:cloudshell edit train.py - Dán mã sau đây vào tệp
train.py:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. Tìm hiểu về mã huấn luyện
Tập lệnh train.py điều phối quy trình tinh chỉnh. Hãy phân tích các thành phần chính của nó.
Cấu hình
Tập lệnh này sử dụng LoraConfig để xác định chế độ cài đặt Thích ứng cấp thấp. LoRA giảm đáng kể số lượng tham số có thể huấn luyện, cho phép bạn tinh chỉnh các mô hình lớn trên các GPU nhỏ hơn.
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
Chuẩn bị tập dữ liệu
Hàm prepare_dataset tải tập dữ liệu "American Stories" và xử lý tập dữ liệu đó thành các đoạn được mã hoá. Thư viện này sử dụng một SimpleTextDataset tuỳ chỉnh để xử lý hiệu quả các tensor đầu vào.
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
Tàu hoả
Hàm train_model thiết lập Trainer bằng các đối số cụ thể được tối ưu hoá cho khối lượng công việc này. Các thông số chính bao gồm:
gradient_accumulation_steps: Giúp mô phỏng kích thước lô lớn hơn mà không làm tăng mức sử dụng bộ nhớ.fp16=True: Sử dụng chế độ huấn luyện độ chính xác hỗn hợp để giảm mức sử dụng bộ nhớ và tăng tốc độ.gradient_checkpointing=True: Tiết kiệm bộ nhớ bằng cách tính toán lại các lượt kích hoạt trong quá trình truyền ngược thay vì lưu trữ chúng.optim="adamw_torch": Sử dụng chế độ triển khai trình tối ưu hoá AdamW tiêu chuẩn từ PyTorch.
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
Suy luận
Hàm run_inference thực hiện một quy trình kiểm thử nhanh mô hình được tinh chỉnh bằng cách sử dụng một câu lệnh mẫu. Thao tác này đảm bảo mô hình ở chế độ đánh giá và tạo văn bản để xác minh rằng các bộ điều hợp đang hoạt động đúng cách.
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. Đóng gói ứng dụng vào vùng chứa
Bây giờ, hãy tạo hình ảnh vùng chứa huấn luyện bằng Docker và đẩy hình ảnh đó vào Google Artifact Registry.
- Trong dòng lệnh, hãy chạy lệnh sau để mở tệp
Dockerfile:cloudshell edit Dockerfile - Dán mã sau đây vào tệp
Dockerfile:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
Tạo và đẩy vùng chứa
- Tạo kho lưu trữ Artifact Registry:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - Tạo và đẩy hình ảnh bằng Cloud Build:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. Triển khai quy trình tinh chỉnh
- Tạo tệp kê khai công việc Kubernetes để bắt đầu công việc tinh chỉnh. Trong thiết bị đầu cuối, hãy chạy:
cloudshell edit training_job.yaml - Dán mã sau đây vào tệp
training_job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- Cuối cùng, hãy áp dụng tệp kê khai công việc Kubernetes để bắt đầu công việc tinh chỉnh trên cụm GKE.
envsubst < training_job.yaml | kubectl apply -f -
14. Theo dõi công việc huấn luyện
Bạn có thể theo dõi tiến trình của quy trình huấn luyện trong Bảng điều khiển Google Cloud.
- Chuyển đến trang Kubernetes Engine > Workloads (Kubernetes Engine > Tải).
Xem khối lượng công việc GKE - Nhấp vào công việc
llama-fine-tuningđể xem thông tin chi tiết. - Thẻ Chi tiết sẽ xuất hiện theo mặc định. Bạn có thể xem các chỉ số về mức sử dụng GPU trong phần Tài nguyên.
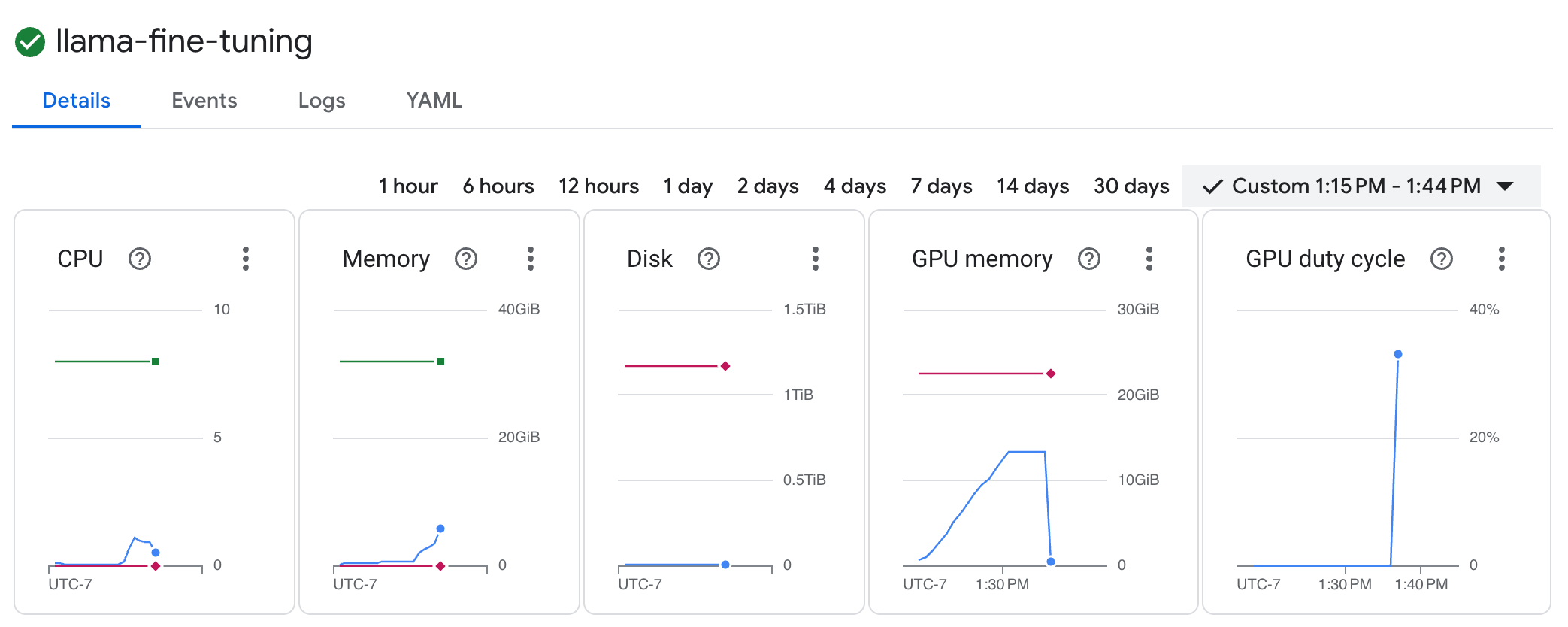
- Nhấp vào thẻ Nhật ký để xem nhật ký huấn luyện. Bạn sẽ thấy tiến trình huấn luyện, bao gồm cả mức độ tổn thất và tốc độ học.
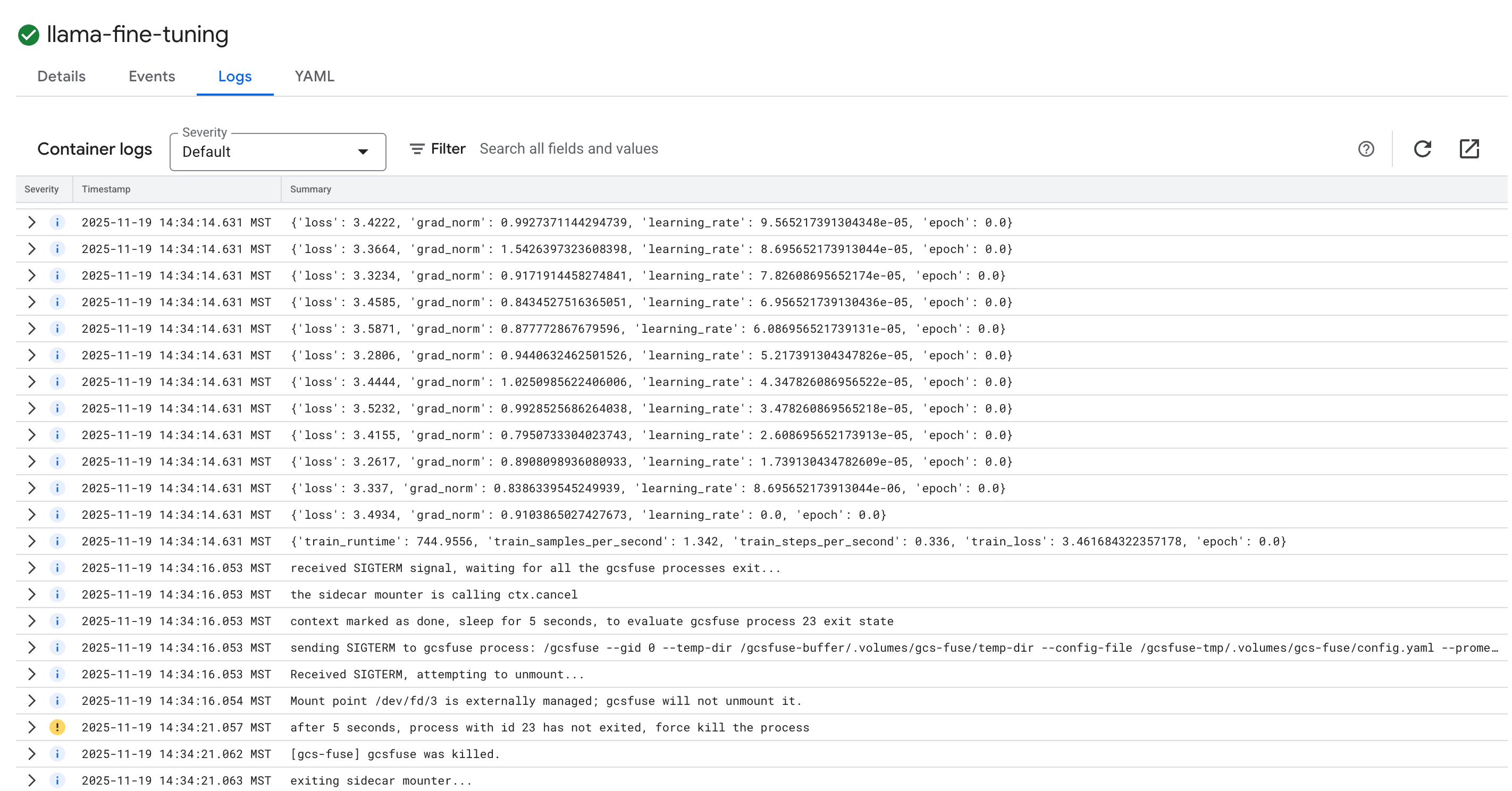
15. Dọn dẹp
Để tránh bị tính phí vào tài khoản Google Cloud của bạn cho các tài nguyên được dùng trong hướng dẫn này, hãy xoá dự án chứa các tài nguyên đó hoặc giữ lại dự án rồi xoá từng tài nguyên.
Xoá cụm GKE
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
Xoá kho lưu trữ Artifact Registry
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
Xoá bộ chứa GCS
gcloud storage rm -r gs://${BUCKET_NAME}
16. Xin chúc mừng!
Bạn đã tinh chỉnh thành công một LLM mã nguồn mở trên GKE!
Tóm tắt
Trong lớp học lập trình này, bạn sẽ:
- Cung cấp một cụm GKE có tính năng tăng tốc GPU.
- Đã định cấu hình Workload Identity để truy cập an toàn vào các dịch vụ của Google Cloud.
- Tạo vùng chứa cho một công việc huấn luyện PyTorch bằng Docker và Artifact Registry.
- Triển khai một công việc tinh chỉnh bằng LoRA để điều chỉnh Llama 2 cho phù hợp với một tập dữ liệu mới.
Bước tiếp theo
- Tìm hiểu thêm về AI trên GKE.
- Khám phá Vertex AI Model Garden.
- Tham gia Cộng đồng Google Cloud để kết nối với các nhà phát triển khác.
Lộ trình học tập của Google Cloud
Phòng thí nghiệm này thuộc Lộ trình học tập AI sẵn sàng cho sản xuất bằng Google Cloud. Khám phá toàn bộ chương trình học để thu hẹp khoảng cách từ nguyên mẫu đến sản xuất.
Chia sẻ tiến trình của bạn bằng hashtag #ProductionReadyAI.