
1. 簡介
在本實驗室中,您將瞭解如何使用 Google Kubernetes Engine (GKE),為熱門的開放原始碼語言模型 Llama 2 建構完整的正式環境微調管道。您將瞭解架構決策、常見的取捨,以及反映真實世界機器學習作業 (MLOps) 工作流程的元件。
您將佈建 GKE 叢集、使用 LoRA (低秩適應) 建構容器化訓練管道,並在 GKE 上執行訓練工作。
架構總覽
以下是我們今天將建構的內容:
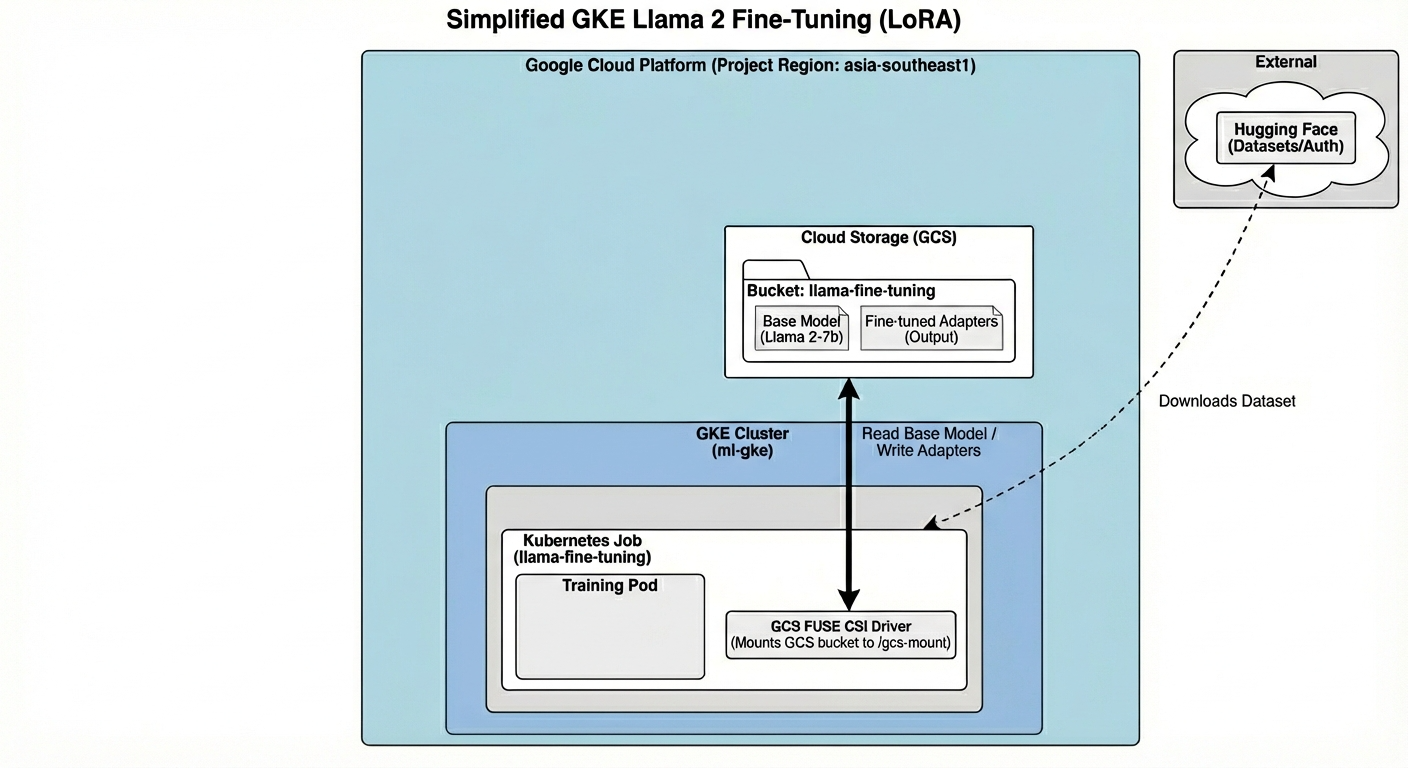
此架構包含:
- GKE 叢集:管理運算資源
- GPU 節點集區:1 個 L4 GPU (Spot),用於訓練
- GCS bucket:儲存模型和資料集
- Workload Identity:在 K8s 和 GCS 之間安全存取
課程內容
- 佈建及設定 GKE 叢集,並使用專為機器學習工作負載最佳化的功能。
- 使用 Workload Identity,從 GKE 實作安全無金鑰存取其他 Google Cloud 服務。
- 使用 Docker 建構容器化訓練管道。
- 使用 LoRA 搭配參數高效微調 (PEFT),有效微調開放原始碼模型。
2. 專案設定
Google 帳戶
如果沒有個人 Google 帳戶,請建立 Google 帳戶。
請使用個人帳戶,而非公司或學校帳戶。
登入 Google Cloud 控制台
使用個人 Google 帳戶登入 Google Cloud 控制台。
建立專案 (選用)
如果沒有要用於本實驗室的現有專案,請在這裡建立新專案。
3. 開啟 Cloud Shell 編輯器
- 按一下這個連結,直接前往 Cloud Shell 編輯器
- 如果系統在今天任何時間提示您授權,請點選「授權」繼續操作。
- 如果畫面底部未顯示終端機,請開啟終端機:
- 按一下「查看」
- 按一下「終端機」
- 在終端機中,使用下列指令設定專案:
gcloud config set project [PROJECT_ID]- 範例:
gcloud config set project lab-project-id-example - 如果忘記專案 ID,可以使用下列指令列出所有專案 ID:
gcloud projects list
- 範例:
- 您應會看到下列訊息:
Updated property [core/project].
4. 啟用 API
如要使用 GKE 和其他服務,您需要在 Google Cloud 專案中啟用必要的 API。
- 在終端機中啟用 API:
gcloud services enable container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ iam.googleapis.com \ compute.googleapis.com \ iamcredentials.googleapis.com \ storage.googleapis.com
API 簡介
- Google Kubernetes Engine API (
container.googleapis.com) 可讓您建立及管理執行應用程式的 GKE 叢集。 - Artifact Registry API (
artifactregistry.googleapis.com) 提供安全無虞的私人存放區,可儲存容器映像檔。 - Cloud Build API (
cloudbuild.googleapis.com) 用於透過gcloud builds submit指令在雲端建構容器映像檔。 - IAM API (
iam.googleapis.com) 可讓您管理 Google Cloud 資源的存取權控管和身分。 - Compute Engine API (
compute.googleapis.com) 提供安全可靠且可自訂的虛擬機器,可在 Google 基礎架構上執行。 - IAM Service Account Credentials API (
iamcredentials.googleapis.com) 可為服務帳戶建立短期憑證。 - Cloud Storage API (
storage.googleapis.com) 可讓您在雲端儲存及擷取資料,這裡用於儲存模型和資料集。
5. 設定專案環境
建立工作目錄
- 在終端機中,為專案建立目錄並前往該目錄。
mkdir llama-finetuning cd llama-finetuning
設定環境變數
- 在終端機中,建立名為
env.sh的檔案,用於儲存環境變數。這樣一來,即使工作階段中斷,你也能輕鬆重新載入這些分頁。cat <<EOF > env.sh export PROJECT_ID=$(gcloud config get-value project) export CLUSTER_NAME="ml-gke" export GPU_NODE_POOL_NAME="gpu-pool" export MACHINE_TYPE="e2-standard-4" export GPU_MACHINE_TYPE="g2-standard-16" export GPU_TYPE="nvidia-l4" export GPU_COUNT=1 export REGION="asia-southeast1" export NODE_LOCATIONS="asia-southeast1-a,asia-southeast1-b" EOF - 載入檔案,將變數載入目前的工作階段:
source env.sh
6. 佈建 GKE 叢集
- 在終端機中,使用預設節點集區建立 GKE 叢集。整個流程大約需要 5 分鐘。
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --region=$REGION \ --release-channel=rapid \ --machine-type=$MACHINE_TYPE \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons=GcsFuseCsiDriver,HttpLoadBalancing \ --enable-image-streaming \ --enable-ip-alias \ --num-nodes=1 \ --enable-autoscaling \ --min-nodes=1 \ --max-nodes=3 - 接著,將 GPU 節點集區新增至叢集。這個節點集區將用於訓練模型。
gcloud container node-pools create $GPU_NODE_POOL_NAME \ --project=$PROJECT_ID \ --cluster=$CLUSTER_NAME \ --region=$REGION \ --machine-type=$GPU_MACHINE_TYPE \ --accelerator type=$GPU_TYPE,count=$GPU_COUNT,gpu-driver-version=latest \ --ephemeral-storage-local-ssd=count=1 \ --enable-autoscaling \ --enable-image-streaming \ --num-nodes=0 \ --min-nodes=0 \ --max-nodes=1 \ --location-policy=ANY \ --node-taints=nvidia.com/gpu=present:NoSchedule \ --node-locations=$NODE_LOCATIONS \ --spot - 最後,取得新叢集的憑證,並確認您可以連線至該叢集。
gcloud container clusters get-credentials $CLUSTER_NAME --region=$REGION kubectl get nodes
7. 設定 Hugging Face 存取權
基礎架構準備就緒後,您現在需要為專案提供必要的憑證,才能存取模型和資料。在這項工作中,您會先取得 Hugging Face 權杖。
取得 Hugging Face 權杖
- 如果沒有 Hugging Face 帳戶,請在新瀏覽器分頁中前往 huggingface.co/join,然後完成註冊程序。
- 註冊並登入後,請前往 huggingface.co/meta-llama/Llama-2-7b-hf。
- 閱讀授權條款,然後按一下按鈕接受條款。
- 前往 huggingface.co/settings/tokens 的 Hugging Face 存取權杖頁面。
- 按一下「New token」。
- 在「角色」部分,選取「讀取」。
- 在「Name」部分輸入描述性名稱 (例如 finetuning-lab)。
- 按一下「建立權杖」。
- 將產生的權杖複製到剪貼簿。下一個步驟會用到。
更新環境變數
現在,請將 Hugging Face 權杖和 GCS bucket 名稱新增至 env.sh 檔案。將 [your-hf-token] 替換成您剛才複製的權杖。
- 在終端機中,將新變數附加至
env.sh並重新載入:cat <<EOF >> env.sh export HF_TOKEN="[your-hf-token]" export BUCKET_NAME="\${PROJECT_ID}-llama-fine-tuning" EOF source env.sh
8. 設定 Workload Identity
接著,您將設定 Workload Identity。建議您使用這種方式,允許在 GKE 上執行的應用程式存取 Google Cloud 服務,不必管理靜態服務帳戶金鑰。詳情請參閱 Workload Identity 說明文件。
- 首先,請建立 Google 服務帳戶 (GSA)。在終端機中執行:
cat <<EOF >> env.sh export GSA_NAME="llama-fine-tuning" EOF source env.sh gcloud iam service-accounts create $GSA_NAME \ --display-name="Llama Fine-tuning Service Account" - 接著,建立 GCS bucket,並授予 GSA 存取權限:
gcloud storage buckets create gs://$BUCKET_NAME --project=$PROJECT_ID --location=$REGION gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member=serviceAccount:${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role=roles/storage.admin - 現在,請建立 Kubernetes 服務帳戶 (KSA):
cat <<EOF >> env.sh export KSA_NAME="llama-workload-sa" export NAMESPACE="ml-workloads" EOF source env.sh kubectl create namespace $NAMESPACE kubectl create serviceaccount $KSA_NAME --namespace $NAMESPACE - 最後,在 GSA 與 KSA 之間建立 IAM 政策繫結:
gcloud iam service-accounts add-iam-policy-binding ${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:${PROJECT_ID}.svc.id.goog[${NAMESPACE}/${KSA_NAME}]" kubectl annotate serviceaccount $KSA_NAME --namespace $NAMESPACE \ iam.gke.io/gcp-service-account=${GSA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
9. 暫存基礎模型
在正式版機器學習管道中,通常會預先在 Cloud Storage 中準備 Llama 2 (~13 GB) 等大型模型,而不是在訓練期間下載。這種做法可提高穩定性、加快存取速度,並避免網路問題。Google Cloud 會在公開 GCS bucket 中提供熱門模型的預先下載版本,您將在實驗室中使用這些版本。
- 首先,請確認您可以存取 Google 提供的 Llama 2 模型:
gcloud storage ls gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf/ - 使用
gcloud storage指令,將這個公開 bucket 中的 Llama 2 模型複製到您專案的 bucket。這項轉移作業會使用 Google 的高速內部網路,應該只需要一到兩分鐘。gcloud storage cp -r gs://vertex-model-garden-public-us-central1/llama2/llama2-7b-hf \ gs://${BUCKET_NAME}/llama2-7b/ - 列出值區內容,確認模型檔案是否已正確複製。
gcloud storage ls --recursive --long gs://${BUCKET_NAME}/llama2-7b/llama2-7b-hf/
10. 準備訓練程式碼
現在要建構容器化應用程式,微調模型。這項工作會使用 LoRA (低秩適應),這是一種參數高效微調 (PEFT) 技術,只訓練小型「轉接器」層,而非整個模型,因此大幅降低記憶體需求。
現在,請為訓練管道建立 Python 指令碼。
- 在終端機中執行下列指令,開啟
train.py檔案:cloudshell edit train.py - 將下列程式碼貼入
train.py檔案:
#!/usr/bin/env python3
"""Fine-tune Llama 2 with LoRA on American Stories dataset """
import os
import torch
import logging
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from peft import get_peft_model, LoraConfig
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ["NCCL_DEBUG"] = "INFO"
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class SimpleTextDataset(torch.utils.data.Dataset):
def __init__(self, input_ids, attention_mask):
self.input_ids = input_ids
self.attention_mask = attention_mask
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_mask[idx],
'labels': self.input_ids[idx].clone()
}
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
def load_model_and_tokenizer(model_path):
logger.info("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
logger.info("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
use_cache=False
)
return model, tokenizer
def prepare_dataset(tokenizer, max_length=512):
logger.info("Loading American Stories dataset...")
We recommend using o
dataset = load_dataset(
"dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810", "1811", "1812", "1813", "1814", "1815"],
trust_remote_code=True
)
all_articles = []
for year_data in dataset.values():
all_articles.extend(year_data["article"])
logger.info(f"Total articles collected: {len(all_articles)}")
batch_size = 1000
all_input_ids = []
all_attention_masks = []
for i in range(0, len(all_articles), batch_size):
batch_articles = all_articles[i:i+batch_size]
logger.info(f"Processing batch {i//batch_size + 1}/{(len(all_articles) + batch_size - 1)//batch_size}")
encodings = tokenizer(
batch_articles,
padding="max_length",
truncation=True,
max_length=max_length,
return_tensors="pt"
)
all_input_ids.append(encodings['input_ids'])
all_attention_masks.append(encodings['attention_mask'])
# Concatenate all batches
input_ids = torch.cat(all_input_ids, dim=0)
attention_mask = torch.cat(all_attention_masks, dim=0)
logger.info(f"Total tokenized examples: {len(input_ids)}")
# Create simple dataset
dataset = SimpleTextDataset(input_ids, attention_mask)
return dataset
def train_model(model, tokenizer, train_dataset, output_dir):
logger.info(f"Train dataset size: {len(train_dataset)}")
n_gpus = torch.cuda.device_count()
logger.info(f"Available GPUs: {n_gpus}")
# For multi-GPU, we can increase batch size
per_device_batch_size = 2 if n_gpus > 1 else 1
gradient_accumulation_steps = 2 if n_gpus > 1 else 4
# Training for 250 steps
max_steps = 250
training_args = TrainingArguments(
output_dir=output_dir,
max_steps=max_steps,
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=2e-4,
warmup_steps=20,
fp16=True,
gradient_checkpointing=True,
logging_steps=10,
evaluation_strategy="no",
save_strategy="no",
optim="adamw_torch",
ddp_find_unused_parameters=False,
dataloader_num_workers=0,
remove_unused_columns=False,
report_to=[],
disable_tqdm=False,
logging_first_step=True,
)
# Create trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
pad_to_multiple_of=8
)
)
# Train
logger.info(f"Starting training on {n_gpus} GPU(s)...")
logger.info(f"Training for {max_steps} steps - approximately {(max_steps * 2.5 / 60):.1f} minutes")
try:
trainer.train()
logger.info("Training completed successfully!")
except Exception as e:
logger.error(f"Training error: {e}")
logger.info("Attempting to save model despite error...")
logger.info("Saving model...")
try:
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)
logger.info(f"Model saved successfully to {output_dir}!")
if not output_dir.startswith("/gcs-mount"):
logger.info("Copying artifacts to GCS bucket...")
gcs_target = "/gcs-mount/llama2-7b-american-stories"
os.makedirs(gcs_target, exist_ok=True)
return_code = os.system(f"cp -r {output_dir}/* {gcs_target}/")
if return_code != 0:
raise RuntimeError(f"Failed to copy model to GCS: cp command returned {return_code}")
logger.info(f"Copied to {gcs_target}")
except Exception as e:
logger.error(f"Error saving model or copying to GCS: {e}")
raise
def run_inference(model, tokenizer):
logger.info("Running inference test...")
prompt = "The year was 1812, and the"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
model.eval()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
logger.info("-" * 50)
logger.info(f"Input Prompt: {prompt}")
logger.info(f"Generated Text: {generated_text}")
logger.info("-" * 50)
def main():
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
model_path = os.getenv('MODEL_PATH', '/gcs-mount/llama2-7b/llama2-7b-hf')
output_path = os.getenv('OUTPUT_PATH', '/gcs-mount/llama2-7b-american-stories')
# Load model and tokenizer
model, tokenizer = load_model_and_tokenizer(model_path)
model.enable_input_require_grads()
# Apply LoRA
logger.info("Applying LoRA configuration...")
lora_config = get_lora_config()
model = get_peft_model(model, lora_config)
model.train()
# Prepare dataset
train_dataset = prepare_dataset(tokenizer)
# Train
train_model(model, tokenizer, train_dataset, output_path)
# Run Inference
run_inference(model, tokenizer)
logger.info("Training and inference complete!")
if __name__ == "__main__":
main()
11. 瞭解訓練程式碼
train.py 指令碼會協調微調程序。我們來看看主要元件。
設定
指令碼會使用 LoraConfig 定義低階適應設定。LoRA 可大幅減少可訓練的參數數量,讓您在較小的 GPU 上微調大型模型。
def get_lora_config():
config = {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj", ...],
"lora_dropout": 0.05,
"task_type": "CAUSAL_LM",
}
return LoraConfig(**config)
準備資料集
prepare_dataset 函式會載入「American Stories」資料集,並處理成權杖化區塊。並使用自訂 SimpleTextDataset 有效率地處理輸入張量。
def prepare_dataset(tokenizer, max_length=512):
dataset = load_dataset("dell-research-harvard/AmericanStories", ...)
# ... tokenization logic ...
return SimpleTextDataset(input_ids, attention_mask)
火車
train_model 函式會設定 Trainer,並使用針對這項工作負載最佳化的特定引數。重要參數包括:
gradient_accumulation_steps:有助於模擬較大的批次大小,但不會增加記憶體用量。fp16=True:使用混合精確度訓練,減少記憶體用量並提高速度。gradient_checkpointing=True:在反向傳播期間重新計算啟動,而非儲存啟動,藉此節省記憶體。optim="adamw_torch":使用 PyTorch 的標準 AdamW 最佳化工具實作。
training_args = TrainingArguments(
per_device_train_batch_size=per_device_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
fp16=True,
gradient_checkpointing=True,
optim="adamw_torch",
)
推論
run_inference 函式會使用範例提示詞,快速測試微調模型。這可確保模型處於評估模式,並產生文字來驗證轉接程式是否正常運作。
def run_inference(model, tokenizer):
prompt = "The year was 1812, and the"
# ... generation logic ...
logger.info(f"Generated Text: {generated_text}")
12. 裝載應用程式
現在,請使用 Docker 建構訓練容器映像檔,並推送至 Google Artifact Registry。
- 在終端機中執行下列指令,開啟
Dockerfile檔案:cloudshell edit Dockerfile - 將下列程式碼貼入
Dockerfile檔案:
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
WORKDIR /app
# Install required packages
RUN pip install --no-cache-dir \
transformers==4.46.0 \
datasets==3.1.0 \
pyarrow==15.0.0 \
peft==0.13.2 \
accelerate==1.1.0 \
tensorboard==2.18.0 \
nvidia-ml-py==12.535.161 \
scipy==1.13.1
# Copy training scripts
COPY train.py /app/
# Run training
CMD ["python", "train.py"]
建構及推送容器
- 建立 Artifact Registry 存放區:
gcloud artifacts repositories create gke-finetune \ --repository-format=docker \ --location=$REGION \ --description="Docker repository for Llama fine-tuning" - 使用 Cloud Build 建構及推送映像檔:
gcloud builds submit --tag ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest .
13. 部署微調工作
- 建立 Kubernetes 工作資訊清單,啟動微調工作。在終端機中執行:
cloudshell edit training_job.yaml - 將下列程式碼貼入
training_job.yaml檔案:
apiVersion: batch/v1
kind: Job
metadata:
name: llama-fine-tuning
namespace: ml-workloads
spec:
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
gke-gcsfuse/memory-limit: "4Gi"
spec:
serviceAccountName: llama-workload-sa
restartPolicy: OnFailure
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: cloud.google.com/gke-spot
operator: Exists
effect: NoSchedule
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
containers:
- name: training
image: ${REGION}-docker.pkg.dev/${PROJECT_ID}/gke-finetune/llama-trainer:latest
env:
- name: MODEL_PATH
value: "/gcs-mount/llama2-7b/llama2-7b-hf"
- name: OUTPUT_PATH
value: "/tmp/llama2-7b-american-stories"
- name: NCCL_DEBUG
value: "INFO"
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: gcs-fuse
mountPath: /gcs-mount
- name: shm
mountPath: /dev/shm
volumes:
- name: gcs-fuse
csi:
driver: gcsfuse.csi.storage.gke.io
volumeAttributes:
bucketName: ${BUCKET_NAME}
mountOptions: "implicit-dirs"
- name: shm
emptyDir:
medium: Memory
sizeLimit: 32Gi
- 最後,套用 Kubernetes 工作資訊清單,在 GKE 叢集上啟動微調工作。
envsubst < training_job.yaml | kubectl apply -f -
14. 監控訓練工作
您可以在 Google Cloud 控制台中監控訓練工作的進度。
- 前往「Kubernetes Engine」>「Workloads」(工作負載) 頁面。
查看 GKE 工作負載 - 按一下
llama-fine-tuning工作即可查看詳細資料。 - 系統預設會顯示「詳細資料」分頁。您可以在「資源」部分查看 GPU 使用率指標。
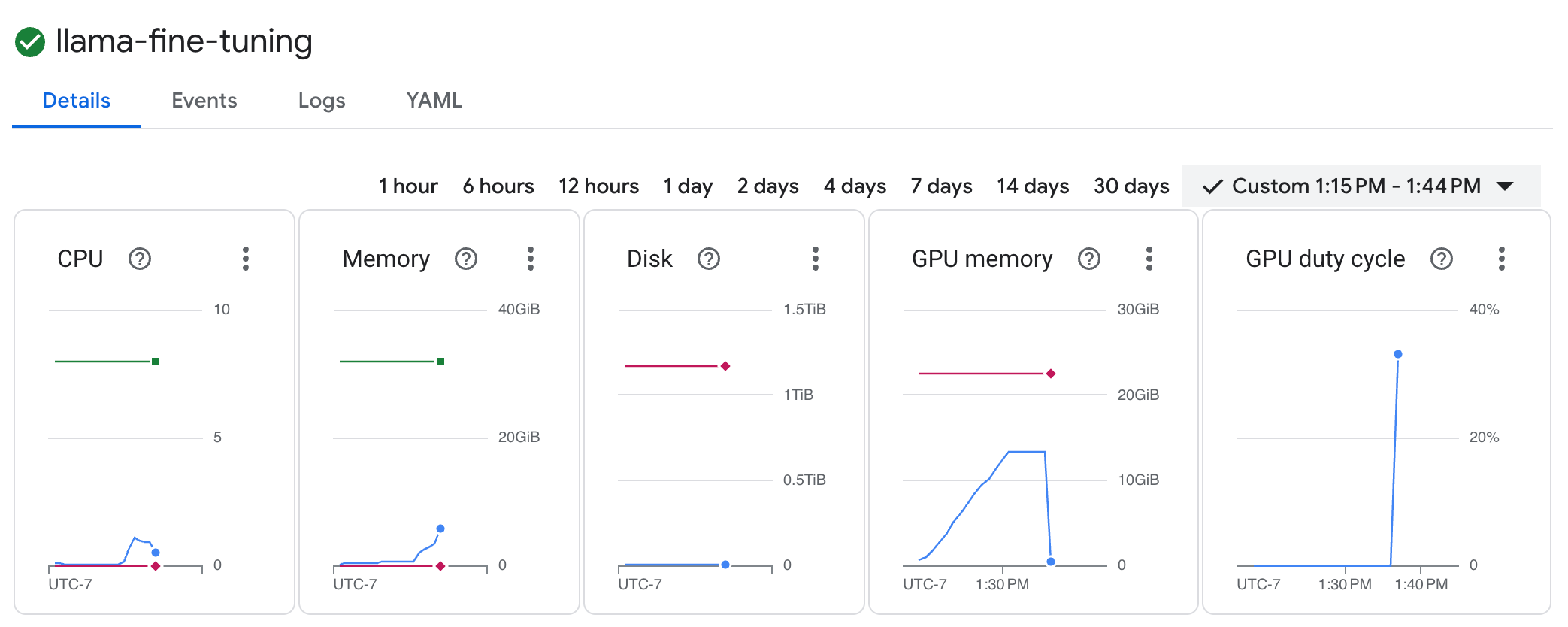
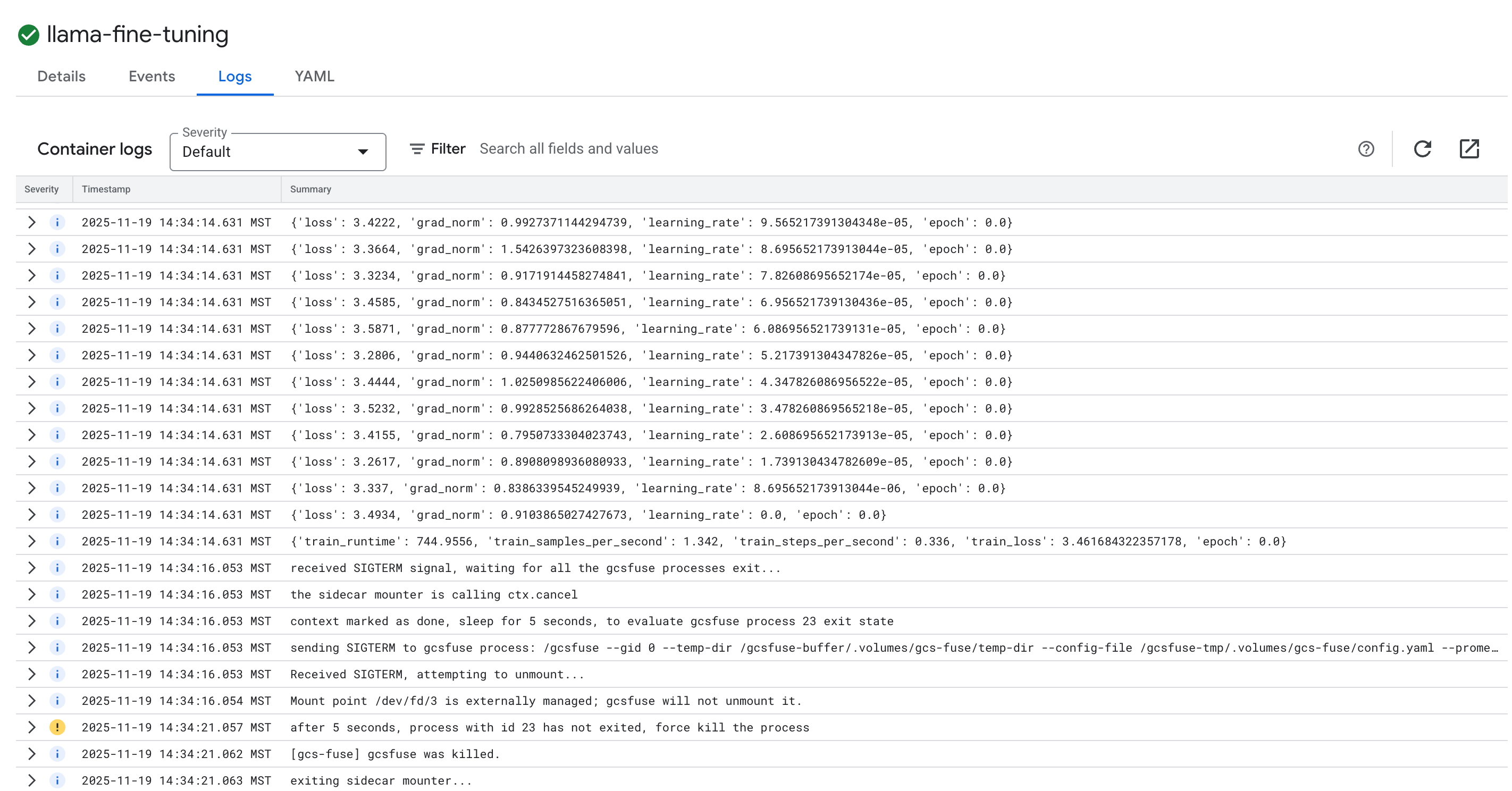
- 按一下「記錄」分頁標籤,即可查看訓練記錄。您應該會看到訓練進度,包括損失和學習率。
15. 清理
如要避免系統向您的 Google Cloud 帳戶收取本教學課程所用資源的費用,請刪除含有相關資源的專案,或者保留專案但刪除個別資源。
刪除 GKE 叢集
gcloud container clusters delete $CLUSTER_NAME --region $REGION --quiet
刪除 Artifact Registry 存放區
gcloud artifacts repositories delete gke-finetune --location $REGION --quiet
刪除 GCS bucket
gcloud storage rm -r gs://${BUCKET_NAME}
16. 恭喜!
您已成功在 GKE 上微調開放原始碼大語言模型!
重點回顧
本實驗室的學習內容如下:
- 佈建了 GPU 加速的 GKE 叢集。
- 設定 Workload Identity,安全地存取 Google Cloud 服務。
- 使用 Docker 和 Artifact Registry,將 PyTorch 訓練工作容器化。
- 使用 LoRA 部署微調作業,讓 Llama 2 適用於新資料集。
後續步驟
- 進一步瞭解 GKE 中的 AI。
- 探索 Vertex AI Model Garden。
- 加入 Google Cloud 社群,與其他開發人員交流互動。
Google Cloud 學習路徑
這個實驗室是「打造可用於正式環境的 AI - Google Cloud 學習路徑」的一部分。探索完整課程,從設計原型開始,一步步把專案投入正式環境。
使用主題標記 #ProductionReadyAI 分享進度。