
程式碼研究室簡介
2. 建立 AI Platform Notebooks 執行個體
您需要已啟用計費功能的 Google Cloud Platform 專案,才能執行這個程式碼研究室。如要建立專案,請按照這裡的操作說明進行。
步驟 2:啟用 Compute Engine API
前往「Compute Engine」,並選取「啟用」 (如果尚未啟用)。建立筆記本執行個體時會用到。
步驟 3:建立筆記本執行個體
前往 Cloud 控制台的 AI 平台筆記本專區,然後按一下「新增執行個體」。接著選取最新的 TensorFlow 2 Enterprise 執行個體類型 (不含 GPU):
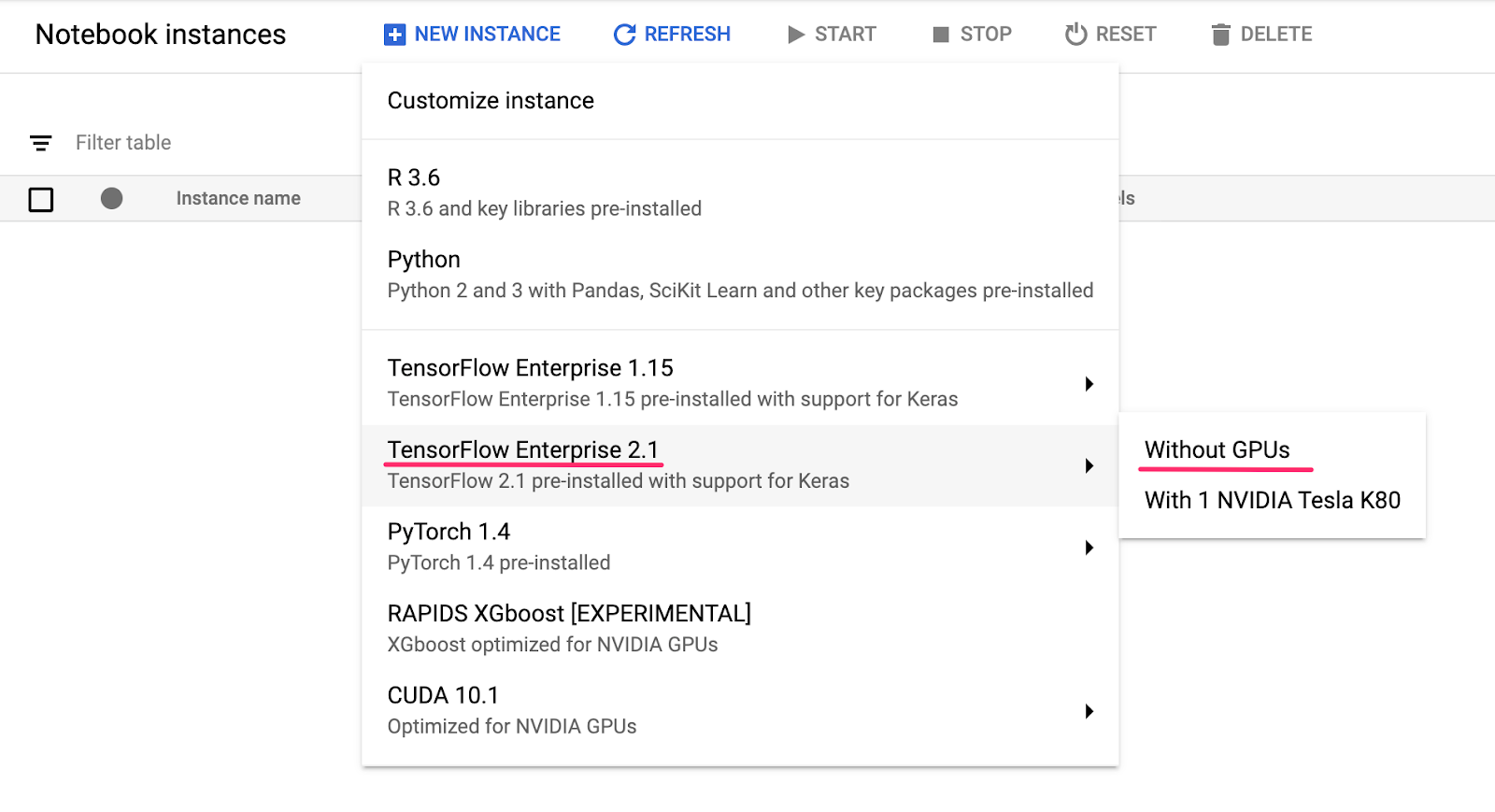
為執行個體命名,或使用預設值。然後探討自訂選項。按一下「自訂」按鈕:
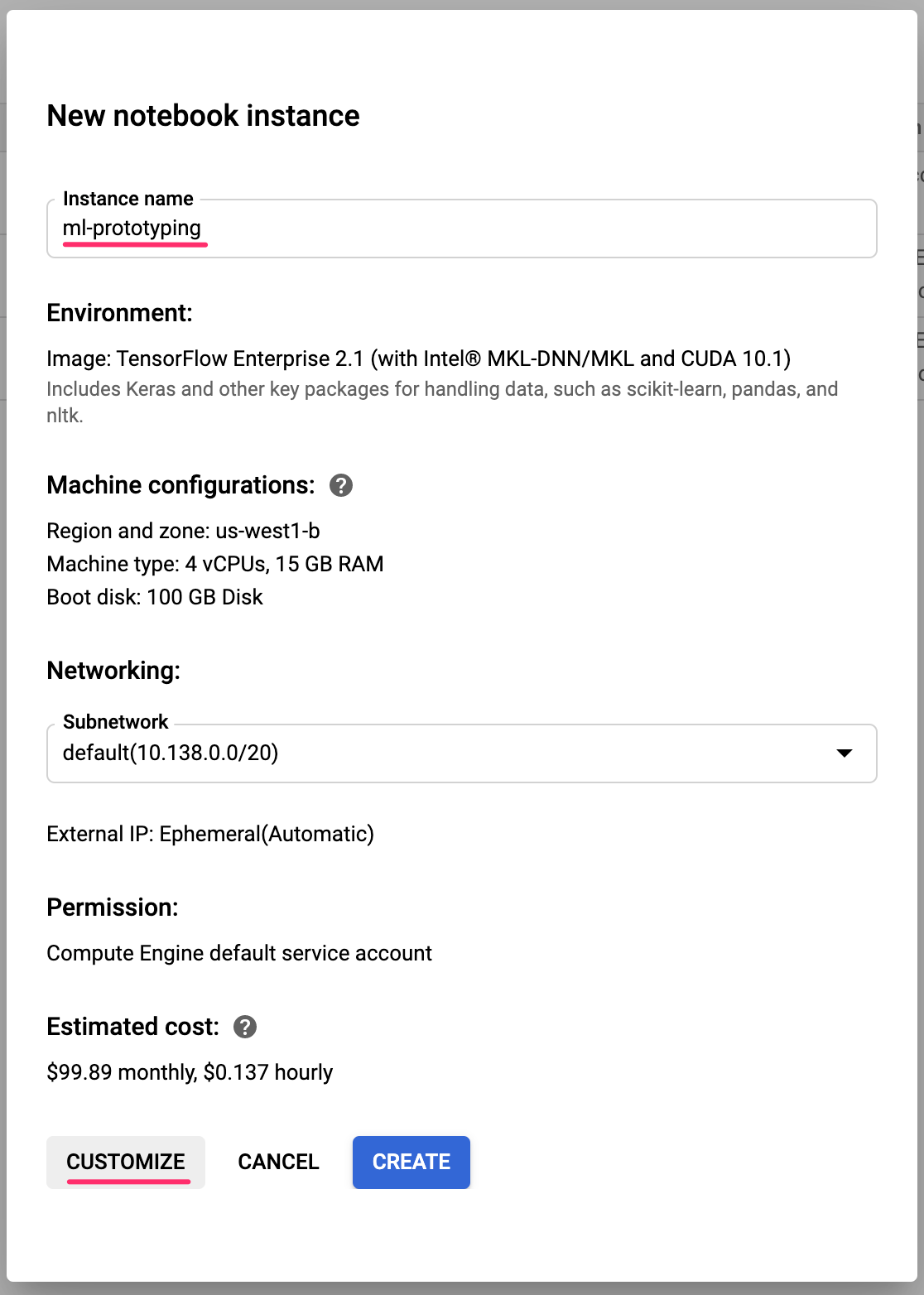
AI 平台筆記本提供許多不同的自訂選項,包括執行個體部署的區域、映像檔類型、機器類型、GPU 數量等。我們會使用區域和環境的預設值。針對機器設定,我們將使用 n1-standard-8 機器:
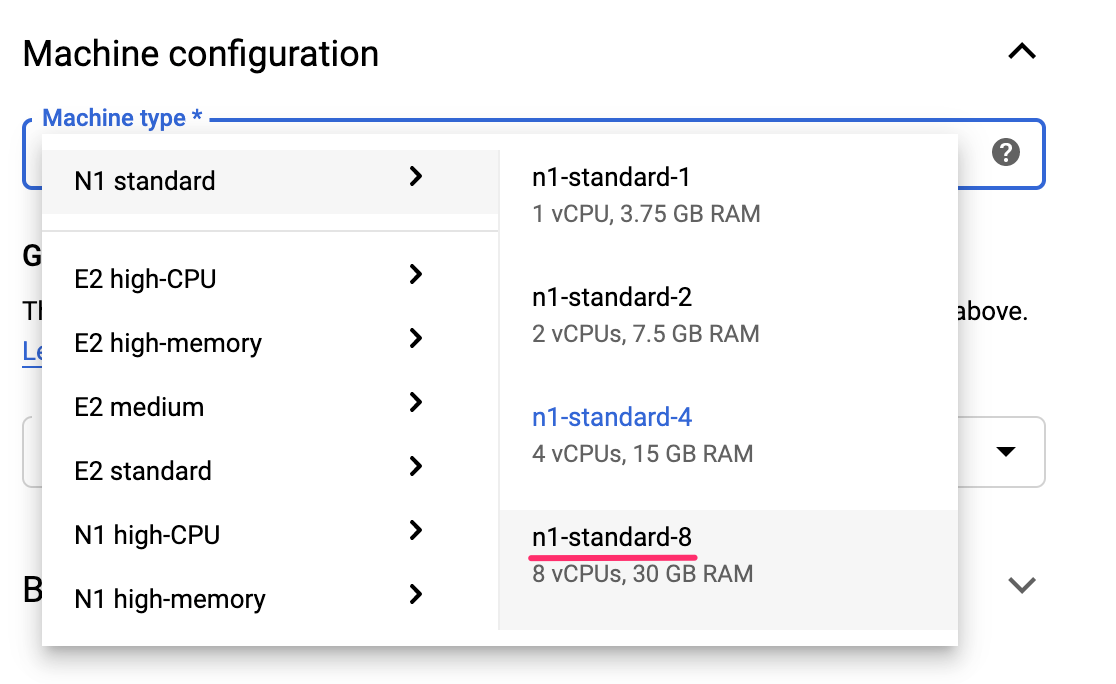
我們不會新增任何 GPU,而會使用開機磁碟、網路和權限的預設值。選取「建立」來建立執行個體。這項作業需要幾分鐘才能完成。
建立執行個體後,在 Notebooks UI 中,執行個體旁邊會顯示綠色勾號。選取「Open JupyterLab」,開啟執行個體並開始設計原型:

開啟執行個體時,請建立一個名為 Codelab 的新目錄。本研究室全程都會處理這個目錄:
點選進入剛剛建立的 codelab 目錄,方法是按兩下該目錄,然後在啟動器中選取 Python 3 筆記本:
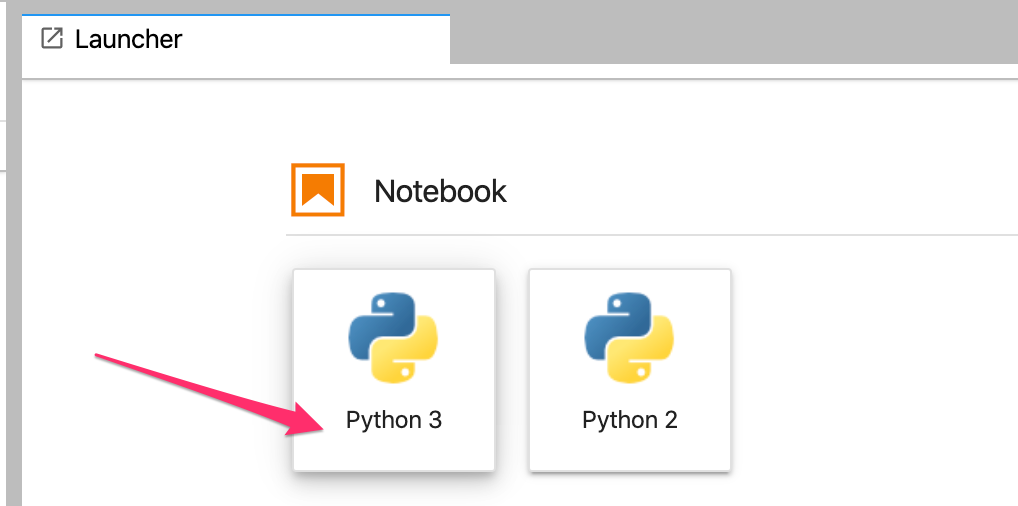
將筆記本重新命名為 demo.ipynb,或是您想命名的名稱。
步驟 4:匯入 Python 套件
在筆記本中建立新的儲存格,並匯入本程式碼研究室將要使用的程式庫:
import pandas as pd
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
import json
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from google.cloud import bigquery
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
3. 將 BigQuery 資料連結至筆記本
BigQuery 是 Google Cloud 的大數據資料倉儲,已公開提供許多資料集供您探索。AI 平台筆記本支援直接整合 BigQuery,因此無須進行驗證。
在這個研究室中,我們將使用出生率資料集。這項數據包含 40 年期間內,幾乎所有美國出生的相關資料,包括孩子的出生體重,以及嬰兒父母的人口統計資訊。我們會使用部分功能來預測嬰兒的出生體重。
步驟 1:將 BigQuery 資料下載至筆記本
我們會使用 BigQuery 適用的 Python 用戶端程式庫,將資料下載到 Pandas DataFrame。原始資料集有 21 GB,含有 1.23 億列。為求簡單,我們只會使用資料集中的 10,000 列資料。
建構查詢,並使用下列程式碼預覽產生的 DataFrame。我們從原始資料集取得 4 個特徵,以及嬰兒體重 (我們的模型預測的事物)。資料集倒數多年後,我們只會使用 2000 年以後的資料:
query="""
SELECT
weight_pounds,
is_male,
mother_age,
plurality,
gestation_weeks
FROM
publicdata.samples.natality
WHERE year > 2000
LIMIT 10000
"""
df = bigquery.Client().query(query).to_dataframe()
df.head()
如要取得資料集中的數值特徵摘要,請執行以下指令:
df.describe()
這是指數字欄的平均值、標準差、最小值和其他指標。最後,讓我們取得布林值資料欄的部分資料,指出嬰兒的性別。我們可以利用 Pandas value_counts 方法完成這項操作:
df['is_male'].value_counts()
看來資料集的性別差異幾乎是 50/50。
步驟 2:為訓練作業準備資料集
現已以 Pandas DataFrame 的形式將資料集下載到筆記本中,我們可以進行預先處理,並拆分為訓練集和測試集。
首先,讓我們從資料集中捨棄含有空值的資料列並重組資料:
df = df.dropna()
df = shuffle(df, random_state=2)
接著,將標籤欄擷取到獨立的變數中,然後建立只包含我們的特徵的 DataFrame。由於 is_male 是布林值,我們會將其轉換為整數,讓模型的所有輸入內容都是數字:
labels = df['weight_pounds']
data = df.drop(columns=['weight_pounds'])
data['is_male'] = data['is_male'].astype(int)
現在如果您透過執行 data.head() 預覽資料集,應該會看到我們將用於訓練的四個特徵。
4. 初始化 Git
AI 平台筆記本與 Git 直接整合,讓您可以直接在筆記本環境中進行版本管控。這項操作支援直接在筆記本 UI 中提交程式碼,或是透過 JupyterLab 提供的終端機修訂程式碼。在本節中,我們會在筆記本中初始化 Git 存放區,並透過使用者介面建立第一個修訂版本。
步驟 1:初始化 Git 存放區
在程式碼研究室目錄中,選取 JupyterLab 頂端選單列中的「Git」和「Init」:
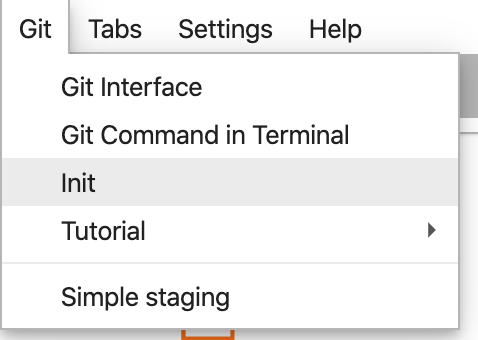
當系統詢問您是否要將此目錄設為 Git 存放區時,請選取「Yes」。接著選取左側欄中的 Git 圖示,即可查看檔案狀態和修訂版本:

步驟 2:建立第一個修訂版本
在這個使用者介面中,您可以新增檔案至修訂版本、查看檔案差異 (稍後會說明),以及提交變更。首先,提交剛剛新增的筆記本檔案。
勾選 demo.ipynb 筆記本檔案旁的方塊,以便暫存該檔案用於修訂版本 (您可以忽略 .ipynb_checkpoints/ 目錄)。在文字方塊中輸入修訂訊息,然後按一下勾號以提交變更:
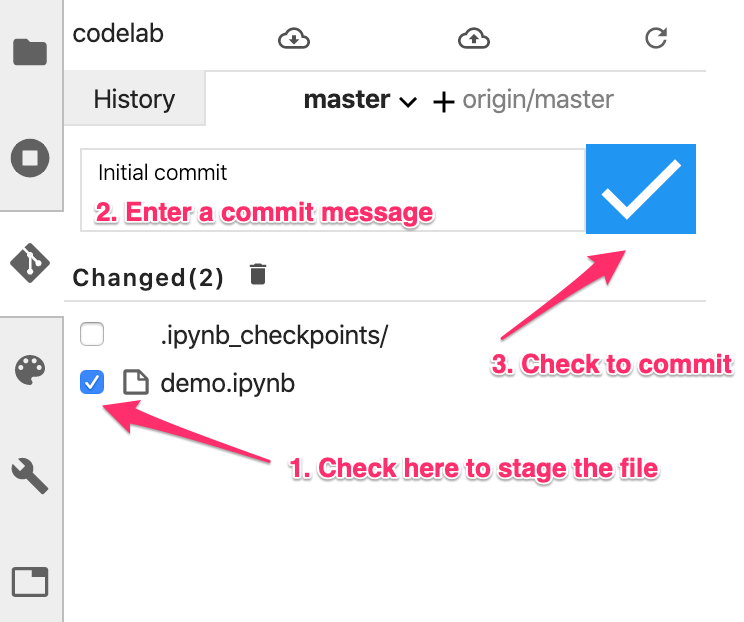
按照系統提示輸入名稱和電子郵件。然後,返回「History」(記錄) 分頁,查看您首次修訂版本:
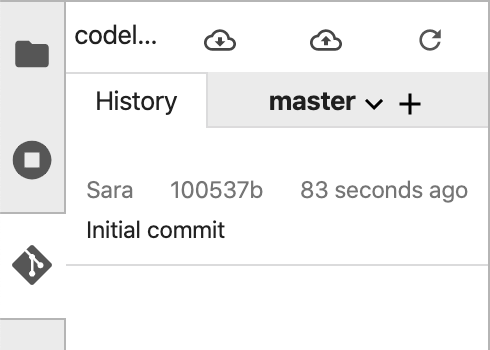
請注意,本研究室發布後已更新,因此螢幕截圖可能與您的 UI 實際畫面不同。
5. 建構及訓練 TensorFlow 模型
我們會使用已下載的 BigQuery 出生率資料集來建構預測寶寶體重的模型。本研究室將著重說明筆記本工具,而非模型本身的準確度。
步驟 1:將資料拆分為訓練集和測試集
我們使用 Scikit Learn train_test_split 公用程式來劃分資料,再建構模型:
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
我們現在可以開始建構 TensorFlow 模型了!
步驟 2:建構及訓練 TensorFlow 模型
我們會使用 tf.keras Sequential 模型 API 建構這個模型,這個模型可讓我們將模型定義為多層堆疊。建構模型所需的所有程式碼都在這裡:
model = Sequential([
Dense(64, activation='relu', input_shape=(len(x_train.iloc[0]),)),
Dense(32, activation='relu'),
Dense(1)]
)
接著,我們會編譯模型以便訓練。我們要在這裡選擇模型的最佳化工具、損失函式,以及訓練期間要記錄的指標。由於這是迴歸模型 (預測數值),因此我們使用均方誤差而非準確率做為指標:
model.compile(optimizer=tf.keras.optimizers.RMSprop(),
loss=tf.keras.losses.MeanSquaredError(),
metrics=['mae', 'mse'])
您可以使用 Keras 的實用 model.summary() 函式,查看各個圖層的模型形狀和數量。
現在,我們可以開始訓練模型了。我們只需呼叫 fit() 方法,並將訓練資料和標籤傳遞給該方法。本例中,我們會使用選用的 verification_split 參數,以便我們在每個步驟中保留部分訓練資料來驗證模型。在理想的情況下,訓練和驗證損失會「同時」降低。但請注意,在此範例中,我們比較的是模型和筆記本工具,而非模型品質:
model.fit(x_train, y_train, epochs=10, validation_split=0.1)
步驟 3:根據測試範例產生預測結果
為了瞭解模型成效,讓我們根據測試資料集的前 10 個範例,產生一些測試預測。
num_examples = 10
predictions = model.predict(x_test[:num_examples])
接著,我們會反覆處理模型的預測結果,並與實際值進行比較:
for i in range(num_examples):
print('Predicted val: ', predictions[i][0])
print('Actual val: ',y_test.iloc[i])
print()
步驟 4:使用 Git diff 提交變更
您已對筆記本進行一些變更,現在可以試用 Notebooks Git 使用者介面中的 Git 差異比較功能。demo.ipynb 筆記本現在應位於「已變更」下方新的部分將滑鼠遊標懸停在檔案名稱上,然後按一下「差異比較」圖示:
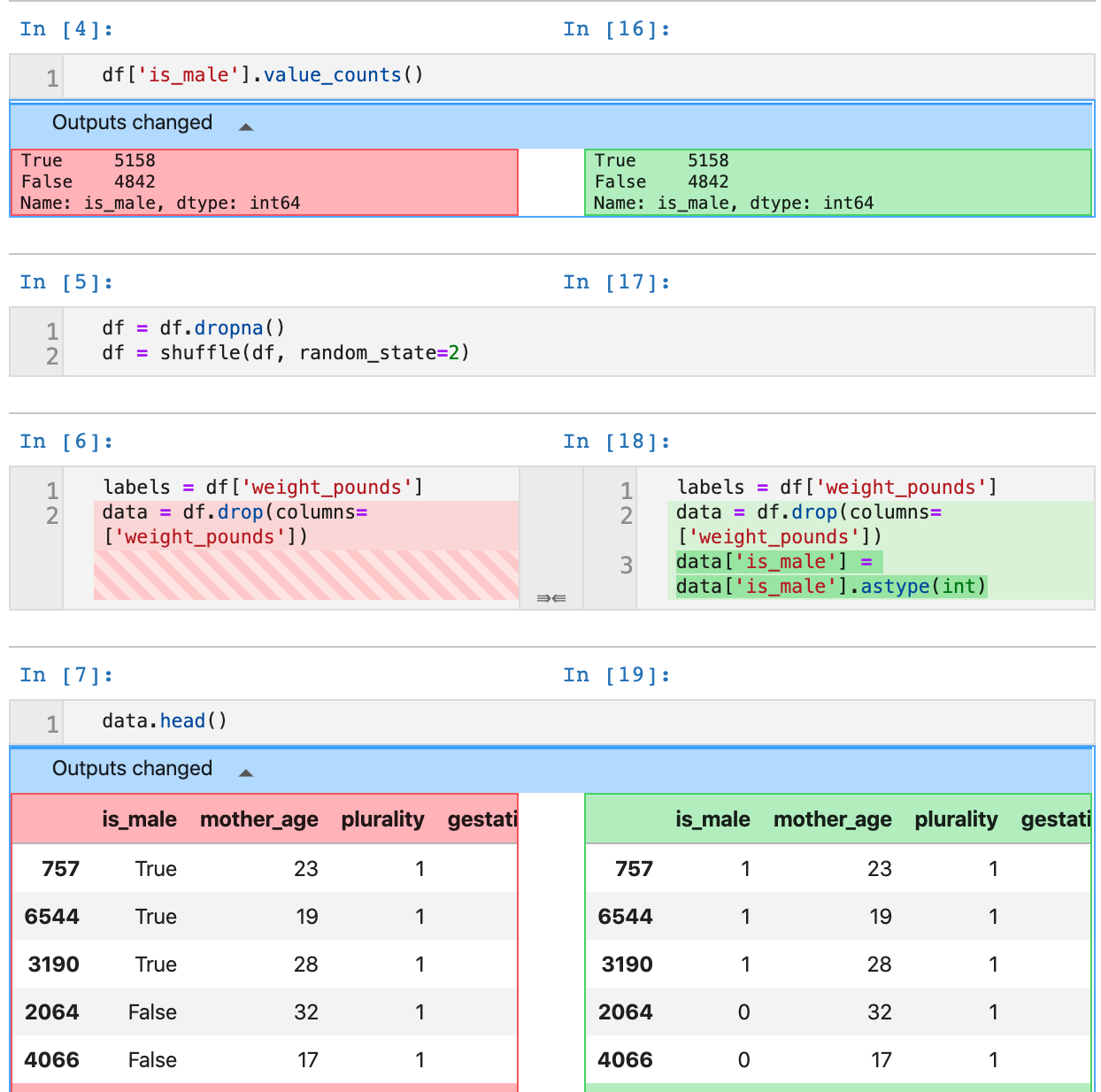
如此一來,您應該就能查看變更內容的差異,如下所示:
這次我們要使用終端機透過指令列提交變更。從 JupyterLab 頂端選單列的「Git」選單,選取「Git Command in Terminal」。執行下方指令時,如果左側欄的「git」分頁已開啟,您就會在 Git UI 中看到所做的變更。
在新終端機執行個體中,執行下列指令來暫存筆記本檔案以進行修訂:
git add demo.ipynb
接著執行下列指令,提交變更 (您可以使用任何想要的修訂訊息):
git commit -m "Build and train TF model"
您應該會在記錄中看到最新的修訂版本:
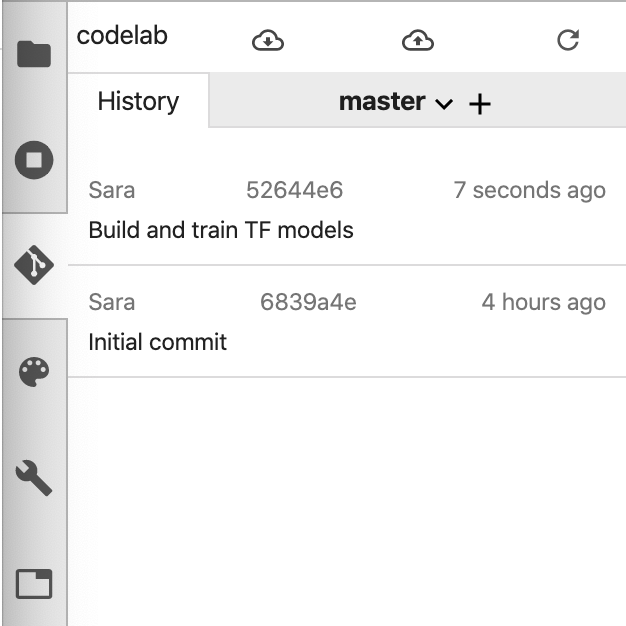
6. 直接從筆記本使用 What-If Tool
What-If Tool 是互動式視覺化介面,旨在以視覺化方式呈現資料集,協助您進一步瞭解機器學習模型的輸出內容。這是由 Google 的 PAIR 團隊打造的開放原始碼工具。雖然適用於所有類型的模型,但有一些專為 Cloud AI 平台打造的功能。
What-If Tool 已預先安裝在具有 TensorFlow 的 Cloud AI Platform Notebooks 執行個體中。這裡將使用這些資料來查看模型的整體成效,並從測試集的資料點上檢查模型行為。
步驟 1:為 What-If Tool 準備資料
為了充分運用 What-If Tool,我們將從測試集提供範例,以及這些範例的真值標籤 (y_test)。如此一來,我們就能比較模型預測到的真值。請執行以下這行程式碼,以我們的測試範例及其標籤建立新的 DataFrame:
wit_data = pd.concat([x_test, y_test], axis=1)
在本研究室中,我們會將 What-If Tool 連結至剛剛在筆記本中訓練的模型。為此,我們必須編寫一個函式,用於執行模型的測試資料點:
def custom_predict(examples_to_infer):
preds = model.predict(examples_to_infer)
return preds
步驟 2:將 What-If Tool 執行個體化
我們會將我們剛建立的串連測試資料集和實際資料標籤中的 500 個範例傳送給該工具,藉此將 What-If Tool 化。我們會建立 WitConfigBuilder 的執行個體來設定工具,並向該例項傳送資料、上方定義的自訂預測函式、目標 (我們預測的內容),以及模型類型:
config_builder = (WitConfigBuilder(wit_data[:500].values.tolist(), data.columns.tolist() + ['weight_pounds'])
.set_custom_predict_fn(custom_predict)
.set_target_feature('weight_pounds')
.set_model_type('regression'))
WitWidget(config_builder, height=800)
當「What-If Tool」載入時,畫面應如下所示:
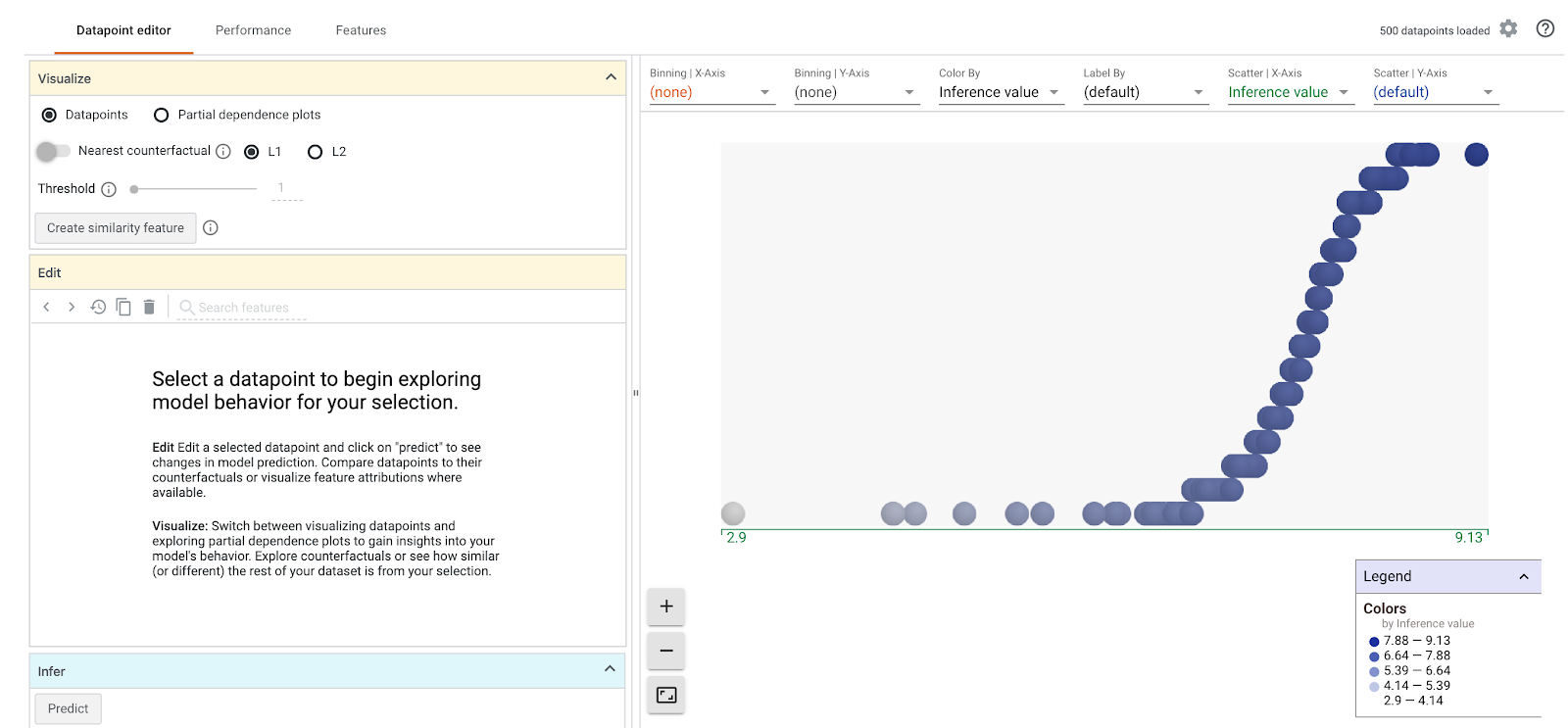
X 軸會顯示測試資料點,並按模型的預測權重值 weight_pounds 進行分配。
步驟 3:使用 What-If Tool 探索模型行為
What-If Tool 有許多有趣的功能。以下僅列舉其中幾個例子。首先來看看資料點編輯器您可以選取任何資料點查看其特徵,以及變更特徵值。請先點選任一資料點:
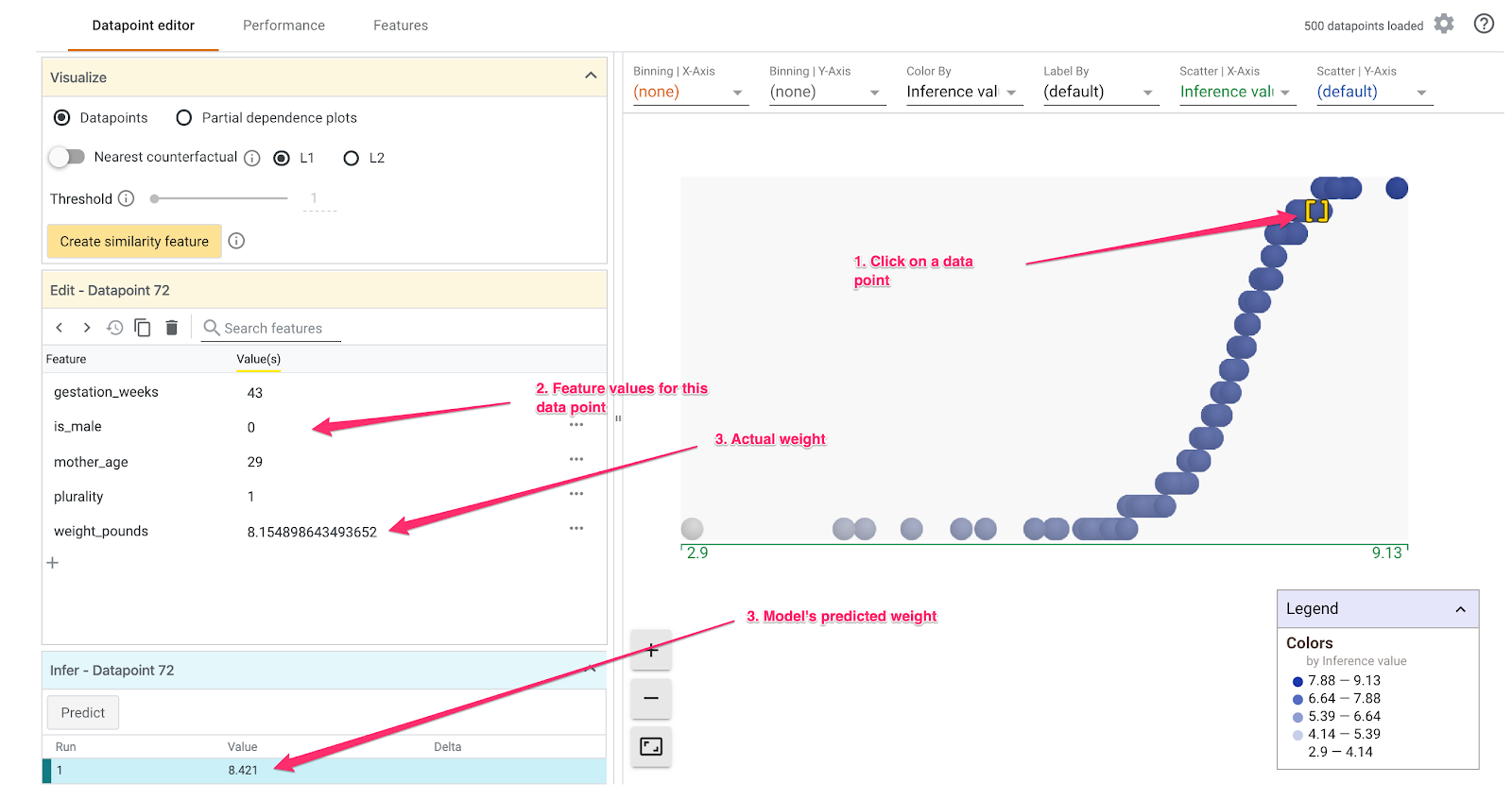
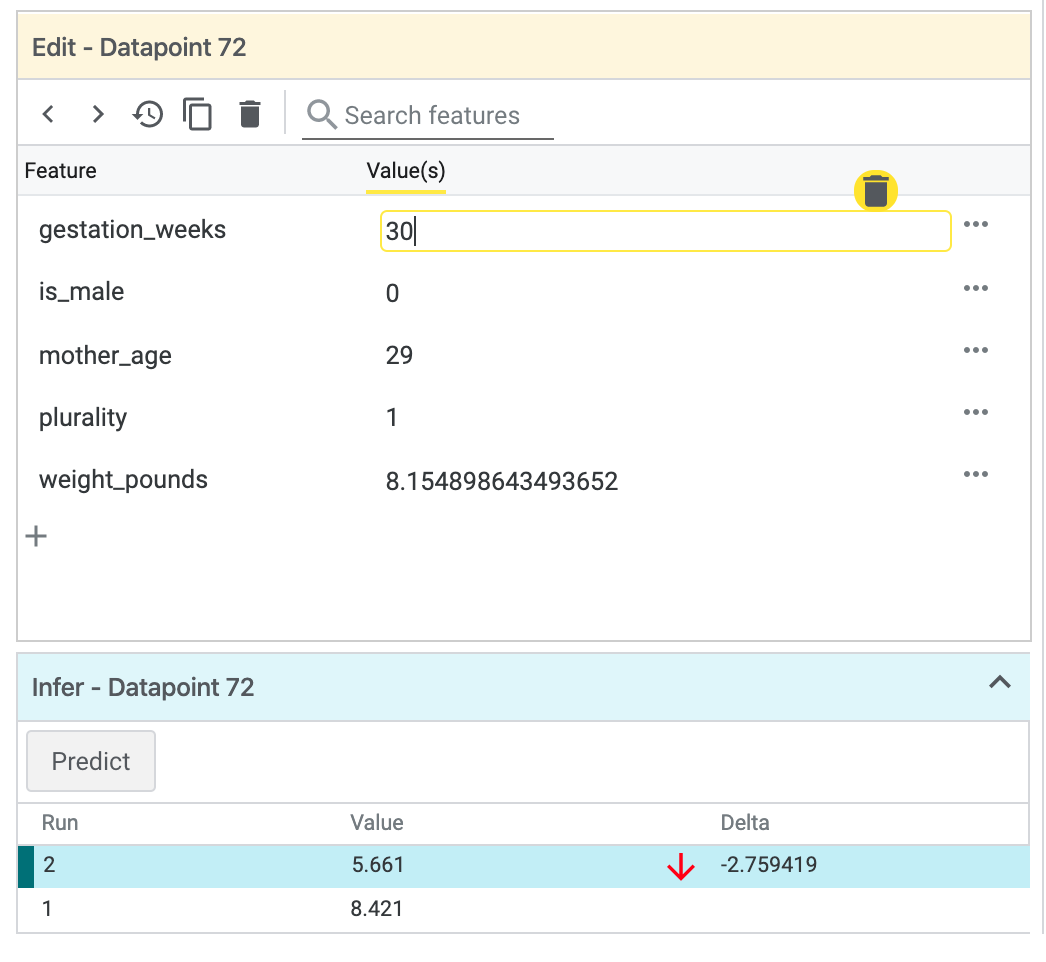
左側會顯示所選資料點的特徵值。此外,您還可以將該資料點的真值標籤與模型預測的值進行比較。在左側欄中,您也可以變更特徵值並重新執行模型預測,查看這項變更對模型的影響。舉例來說,我們可以針對這個資料點按兩下,再次進行預測,即可將這個資料點的 gestation_weeks 變更為 30:
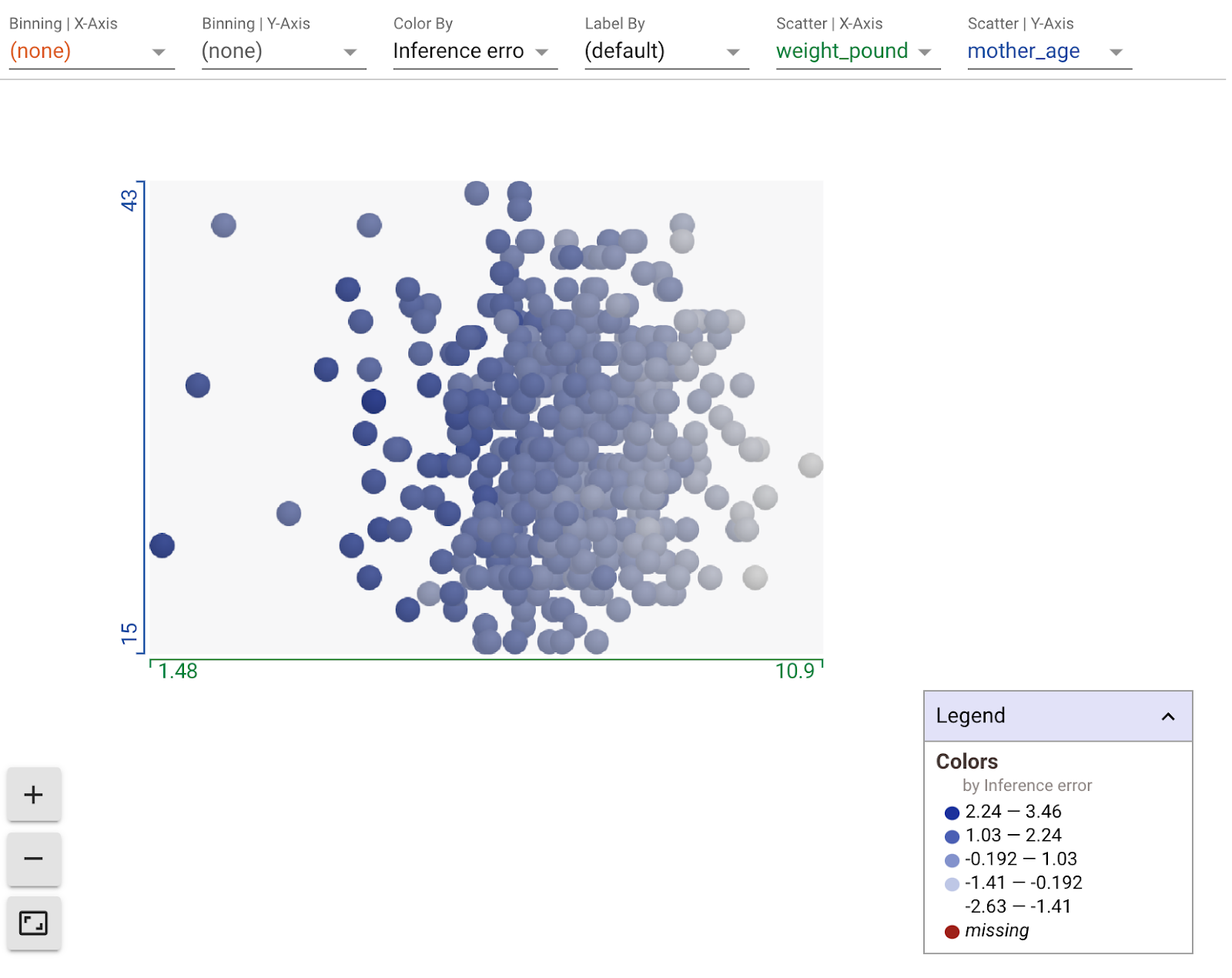
您可以使用 What-If Tool 的圖解部分中的下拉式選單,建立各種自訂圖表。舉例來說,下方是列出模型分類圖表X 軸預測權重、母親在 y 軸上的年齡,以及根據推論誤差而顏色的點 (顏色越深,表示預測與實際權重之間的差異越高)。看起來在權重減少時,模型的錯誤度會稍微增加:
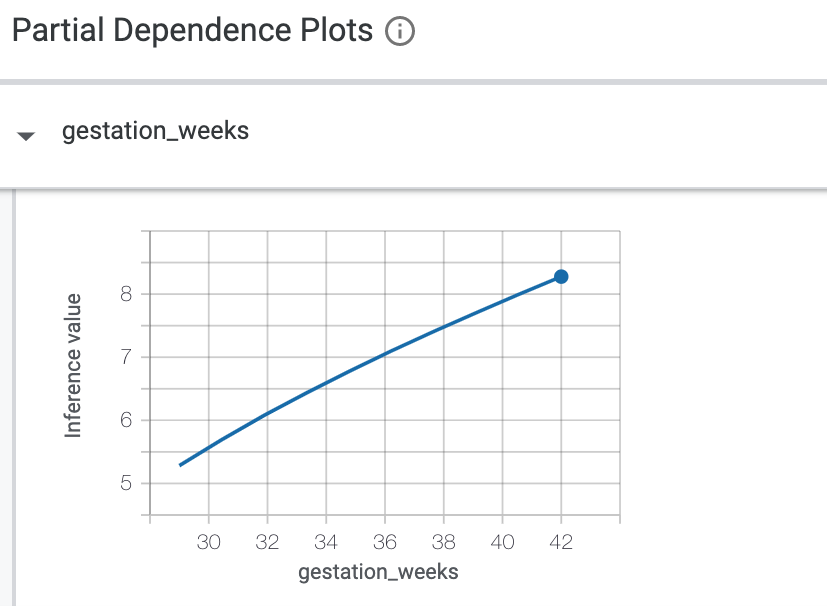
接著,勾選左側的「Partial Deence Graphs」按鈕。說明各項特徵對模型預測結果的影響。舉例來說,隨著懷孕時間增加,模型的預測嬰兒體重也會增加:
如需更多「What-If Tool」的探索提案,請查看本節開頭的連結。
7. 選用:將本機 Git 存放區連結至 GitHub
最後,我們會說明如何將筆記本執行個體中的 Git 存放區連結至 GitHub 帳戶中的存放區。如果您想執行這個步驟,您必須擁有 GitHub 帳戶。
步驟 1:在 GitHub 上建立新的存放區
在 GitHub 帳戶中建立新的存放區。輸入名稱和說明,並決定是否要公開存放區,然後選取「Create repository」(建立存放區) (不需要使用 README 進行初始化)。在下一頁中,您將按照指示透過指令列推送現有存放區。
開啟終端機視窗,並將新的存放區新增為遠端存放區。將下方存放區網址中的 username 替換為您的 GitHub 使用者名稱,並將 your-repo 替換為您剛剛建立的帳戶名稱:
git remote add origin git@github.com:username/your-repo.git
步驟 2:在筆記本執行個體中向 GitHub 進行驗證
接下來,您必須在筆記本執行個體中向 GitHub 進行驗證。這個程序會因您是否在 GitHub 上啟用雙重驗證功能而有所不同。
如果您不確定要從何處著手,請按照 GitHub 說明文件中的步驟建立安全殼層金鑰,然後將新金鑰新增至 GitHub。
步驟 3:確認您已正確連結 GitHub 存放區
為確保各項設定正確無誤,請在終端機中執行 git remote -v。您應該會將新的存放區列為遠端存放區。看見 GitHub 存放區的網址,並已從筆記本通過 GitHub 驗證後,您就能從筆記本執行個體直接推送至 GitHub。
如要將本機筆記本 Git 存放區與新建立的 GitHub 存放區保持同步,請按一下 Git 側欄頂端的 Cloud 上傳按鈕:

重新整理 GitHub 存放區,您應該會看到與先前修訂版本中的筆記本程式碼。如果其他使用者可以存取您的 GitHub 存放區,而您想將最新變更提取至筆記本,請點選雲端下載圖示來同步處理這些變更。
在 Notebooks Git 使用者介面的「History」(歷史記錄) 分頁中,您可以查看本機修訂版本是否已與 GitHub 保持同步。在這個範例中,origin/master 與 GitHub 上的存放區對應:
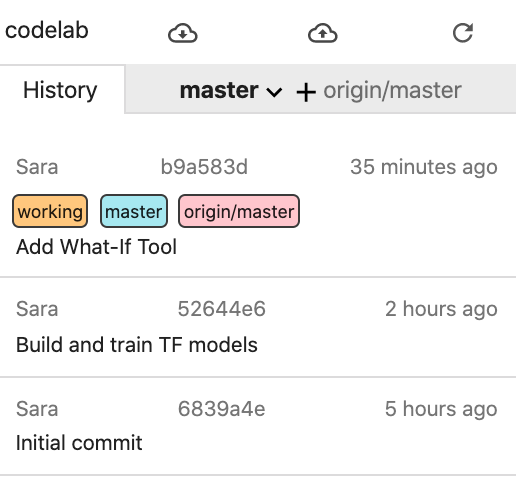
每次建立新的修訂版本時,只要再按一下雲端上傳按鈕,即可將這些變更推送至 GitHub 存放區。
8. 恭喜!
你在這個研究室中完成了很多事 👏?👏?
總結來說,您已瞭解如何:
- 建立自訂 AI 平台筆記本執行個體
- 在該執行個體中初始化本機 Git 存放區、透過 Git UI 或指令列新增修訂版本、在筆記本 Git 使用者介面查看 Git 差異
- 建構並訓練簡單的 TensorFlow 2 模型
- 在筆記本執行個體中使用 What-If Tool
- 將筆記本 Git 存放區連結至 GitHub 上的外部存放區
9. 清除所用資源
如要繼續使用這個筆記本,建議您在未使用時將其關閉。在 Cloud 控制台的「Notebooks」(筆記本) UI 中,依序選取筆記本和「Stop」(停止):

如要刪除在本研究室中建立的所有資源,只要刪除筆記本執行個體即可,不必停止執行個體。
使用 Cloud 控制台中的導覽選單前往「儲存空間」,然後刪除您為了儲存模型資產而建立的兩個值區。