
1. 概要
このラボでは、データを探索し、ML モデルのプロトタイプを作成するための AI Platform Notebooks のさまざまなツールについて説明します。
学習内容
次の方法を学習します。
- AI Platform Notebooks インスタンスを作成してカスタマイズする
- AI Platform Notebooks に直接統合された Git でノートブックのコードをトラッキングする
- ノートブック内で What-If ツールを使用する
このラボを Google Cloud で実行するための総費用は約 $1 です。AI Platform Notebooks の料金の詳細については、こちらをご覧ください。
2. AI Platform Notebooks インスタンスを作成する
この Codelab を実行するには、課金が有効になっている Google Cloud Platform プロジェクトが必要です。プロジェクトを作成するには、こちらの手順に沿って操作してください。
ステップ 2: Compute Engine API を有効にする
[Compute Engine] に移動し、まだ有効になっていない場合は [有効にする] を選択します。これはノートブック インスタンスを作成するために必要です。
ステップ 3: ノートブック インスタンスを作成する
Cloud Console の AI Platform Notebooks セクションに移動し、[新しいインスタンス] をクリックします。次に、最新の TensorFlow 2 Enterprise インスタンス タイプ(GPU なし )を選択します。

インスタンスに名前を付けるか、デフォルトを使用します。次に、カスタマイズ オプションについて説明します。[カスタマイズ] ボタンをクリックします。

AI Platform Notebooks には、インスタンスがデプロイされるリージョン、イメージ タイプ、マシンサイズ、GPU の数など、さまざまなカスタマイズ オプションがあります。リージョンと環境にはデフォルトを使用します。マシン構成には、n1-standard-8 マシンを使用します。

GPU は追加せず、ブートディスク、ネットワーク、権限にはデフォルトを使用します。[作成] を選択してインスタンスを作成します。完了するまでに数分かかります。
インスタンスが作成されると、Notebooks UI の横に緑色のチェックマークが表示されます。[Open JupyterLab] を選択してインスタンスを開き、プロトタイピングを開始します。

インスタンスを開いたら、codelab という新しいディレクトリを作成します。このラボでは、このディレクトリを使用します。

新しく作成した codelab ディレクトリをダブルクリックして開き、ランチャーから [Python 3] ノートブックを選択します。

ノートブックの名前を demo.ipynb に変更します。任意の名前を付けてもかまいません。
ステップ 4: Python パッケージをインポートする
ノートブックに新しいセルを作成し、この Codelab で使用するライブラリをインポートします。
import pandas as pd
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
import json
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from google.cloud import bigquery
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
3. BigQuery データをノートブックに接続する
Google Cloud のビッグデータ ウェアハウスである BigQuery では、多くのデータセットが一般公開されており、探索できます。AI Platform Notebooks は、認証を必要とせずに BigQuery と直接統合できます。
このラボでは、natality データセットを使用します。このデータセットには、40 年間の米国でのほぼすべての出産に関するデータが含まれています。これには、子供の出生体重と、赤ちゃんの両親の人口統計情報が含まれます。特徴のサブセットを使用して、赤ちゃんの出生体重を予測します。
ステップ 1: BigQuery データをノートブックにダウンロードする
BigQuery 用の Python クライアント ライブラリを使用して、データを Pandas DataFrame にダウンロードします。元のデータセットは 21 GB で、1 億 2,300 万行が含まれています。ここでは、データセットから 10,000 行のみを使用します。
次のコードを使用してクエリを作成し、結果の DataFrame をプレビューします。ここでは、元のデータセットから 4 つの特徴と、赤ちゃんの体重(モデルが予測する値)を取得します。データセットは長年にわたるものですが、このモデルでは 2000 年以降のデータのみを使用します。
query="""
SELECT
weight_pounds,
is_male,
mother_age,
plurality,
gestation_weeks
FROM
publicdata.samples.natality
WHERE year > 2000
LIMIT 10000
"""
df = bigquery.Client().query(query).to_dataframe()
df.head()
データセット内の数値特徴の概要を取得するには、次を実行します。
df.describe()
これにより、数値列の平均値、標準偏差、最小値などの指標が表示されます。最後に、赤ちゃんの性別を示すブール値列のデータを取得しましょう。これは、Pandas の value_counts メソッドを使用して行えます。
df['is_male'].value_counts()
データセットは性別でほぼ 50/50 にバランスが取れているようです。
ステップ 2: トレーニング用のデータセットを準備する
データセットを Pandas DataFrame としてノートブックにダウンロードしたので、前処理を行い、トレーニング セットとテストセットに分割できます。
まず、null 値の行をデータセットから削除し、データをシャッフルします。
df = df.dropna()
df = shuffle(df, random_state=2)
次に、ラベル列を別の変数に抽出し、特徴のみを含む DataFrame を作成します。is_male はブール値なので、モデルへのすべての入力が数値になるように整数に変換します。
labels = df['weight_pounds']
data = df.drop(columns=['weight_pounds'])
data['is_male'] = data['is_male'].astype(int)
data.head() を実行してデータセットをプレビューすると、トレーニングに使用する 4 つの特徴が表示されます。
4. Git を初期化する
AI Platform Notebooks は Git と直接統合されているため、ノートブック環境内で直接バージョン管理を行うことができます。これにより、ノートブック UI または JupyterLab で使用可能なターミナルからコードを commit できます。このセクションでは、ノートブックで Git リポジトリを初期化し、UI から最初の commit を行います。
ステップ 1: Git リポジトリを初期化する
codelab ディレクトリから、JupyterLab の上部メニューバーで [Git]、[Init] の順に選択します。

このディレクトリを Git リポジトリにするかどうかを確認するメッセージが表示されたら、[はい] を選択します。次に、左側のサイドバーで Git アイコンを選択して、ファイルと commit のステータスを確認します。

ステップ 2: 最初の commit を行う
この UI では、ファイルを commit に追加したり、ファイルの差分を確認したり(後で説明します)、変更を commit したりできます。まず、追加したノートブック ファイルを commit します。
demo.ipynb ノートブック ファイルの横にあるチェックボックスをオンにして、commit 用にステージングします(.ipynb_checkpoints/ ディレクトリは無視してかまいません)。テキスト ボックスに commit メッセージを入力し、チェックマークをクリックして変更を commit します。

プロンプトが表示されたら、名前とメールアドレスを入力します。[履歴] タブに戻って、最初の commit を確認します。

注: このラボの公開後に更新が行われたため、スクリーンショットが実際の UI と一致しない場合があります。
5. TensorFlow モデルを構築してトレーニングする
ノートブックにダウンロードした BigQuery natality データセットを使用して、赤ちゃんの体重を予測するモデルを構築します。このラボでは、モデル自体の精度ではなく、ノートブック ツールに重点を置いています。
ステップ 1: データをトレーニング セットとテストセットに分割する
Scikit Learn の train_test_split ユーティリティを使用して、モデルを構築する前にデータを分割します。
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
これで TensorFlow モデルを構築する準備が整いました。
ステップ 2: TensorFlow モデルを構築してトレーニングする
このモデルは、tf.keras Sequential モデル API を使用して構築します。これにより、モデルをレイヤのスタックとして定義できます。モデルの構築に必要なコードは次のとおりです。
model = Sequential([
Dense(64, activation='relu', input_shape=(len(x_train.iloc[0]),)),
Dense(32, activation='relu'),
Dense(1)]
)
次に、モデルをトレーニングできるようにコンパイルします。ここでは、モデルのオプティマイザー、損失関数、トレーニング中にモデルが記録する指標を選択します。これは回帰モデル(数値の予測)なので、指標として精度ではなく平均二乗誤差を使用します。
model.compile(optimizer=tf.keras.optimizers.RMSprop(),
loss=tf.keras.losses.MeanSquaredError(),
metrics=['mae', 'mse'])
Keras の便利な model.summary() 関数を使用すると、各レイヤでのモデルの形状とトレーニング可能なパラメータの数を確認できます。
これでモデルをトレーニングする準備が整いました。必要なのは、トレーニング データとラベルを渡して fit() メソッドを呼び出すことだけです。ここでは、オプションの validation_split パラメータを使用します。このパラメータは、各ステップでモデルを検証するためにトレーニング データの一部を保持します。トレーニング損失と検証損失の両方が減少していることが理想的です。 ただし、この例では、モデルの品質よりもモデルとノートブックのツールに重点を置いています。
model.fit(x_train, y_train, epochs=10, validation_split=0.1)
ステップ 3: テストサンプルで予測を生成する
モデルのパフォーマンスを確認するには、テスト データセットの最初の 10 個のサンプルでテスト予測を生成します。
num_examples = 10
predictions = model.predict(x_test[:num_examples])
次に、モデルの予測を反復処理し、実際の値と比較します。
for i in range(num_examples):
print('Predicted val: ', predictions[i][0])
print('Actual val: ',y_test.iloc[i])
print()
ステップ 4: git diff を使用して変更を commit する
ノートブックに変更を加えたので、Notebooks Git UI で使用できる git diff 機能をお試しください。demo.ipynb ノートブックが UI の [変更] セクションに表示されます。ファイル名にカーソルを合わせ、差分アイコンをクリックします。

次のように、変更の差分が表示されます。

今回は、ターミナルを使用してコマンドラインから変更を commit します。JupyterLab の上部メニューバーの [Git] メニューから、[Git Command in Terminal] を選択します。以下のコマンドを実行しているときに、左側のサイドバーの Git タブを開いている場合は、Git UI に変更が反映されます。
新しいターミナル インスタンスで、次を実行して、commit 用にノートブック ファイルをステージングします。
git add demo.ipynb
次に、次を実行して変更を commit します(任意の commit メッセージを使用できます)。
git commit -m "Build and train TF model"
履歴に最新の commit が表示されます。

6. ノートブックから直接 What-If ツールを使用する
What-If ツールは、データセットを可視化し、ML モデルの出力をより深く理解できるように設計されたインタラクティブなビジュアル インターフェースです。これは、Google の PAIR チームによって作成されたオープンソース ツールです。あらゆるタイプのモデルで動作しますが、Cloud AI Platform 専用の機能がいくつか組み込まれています。
What-If ツールは、TensorFlow を使用する Cloud AI Platform Notebooks インスタンスにプリインストールされています。ここでは、これを使用してモデルの全体的なパフォーマンスを確認し、テストセットのデータポイントでの動作を検査します。
ステップ 1: What-If ツール用のデータを準備する
What-If ツールを最大限に活用するには、テストセットのサンプルと、それらのサンプルの正解ラベル(y_test)を送信します。これにより、モデルの予測と正解を比較できます。次のコード行を実行して、テストサンプルとそのラベルを含む新しい DataFrame を作成します。
wit_data = pd.concat([x_test, y_test], axis=1)
このラボでは、What-If ツールをノートブックでトレーニングしたモデルに接続します。そのためには、ツールがこれらのテストデータポイントをモデルに実行するために使用する関数を作成する必要があります。
def custom_predict(examples_to_infer):
preds = model.predict(examples_to_infer)
return preds
ステップ 2: What-If ツールをインスタンス化する
連結されたテスト データセットと、作成した正解ラベルから 500 個のサンプルを渡して、What-If ツールをインスタンス化します。WitConfigBuilder のインスタンスを作成してツールを設定し、データ、上記で定義したカスタム予測関数、ターゲット(予測対象)、モデルタイプを渡します。
config_builder = (WitConfigBuilder(wit_data[:500].values.tolist(), data.columns.tolist() + ['weight_pounds'])
.set_custom_predict_fn(custom_predict)
.set_target_feature('weight_pounds')
.set_model_type('regression'))
WitWidget(config_builder, height=800)
What-If ツールが読み込まれると、次のように表示されます。

x 軸には、モデルの予測体重値 weight_pounds で分散されたテストデータポイントが表示されます。
ステップ 3: What-If ツールでモデルの動作を調べる
What-If ツールでは、さまざまなことができます。ここでは、その一部を紹介します。まず、データポイント エディタを見てみましょう。データポイントを選択して特徴を確認し、特徴値を変更できます。データポイントをクリックします。
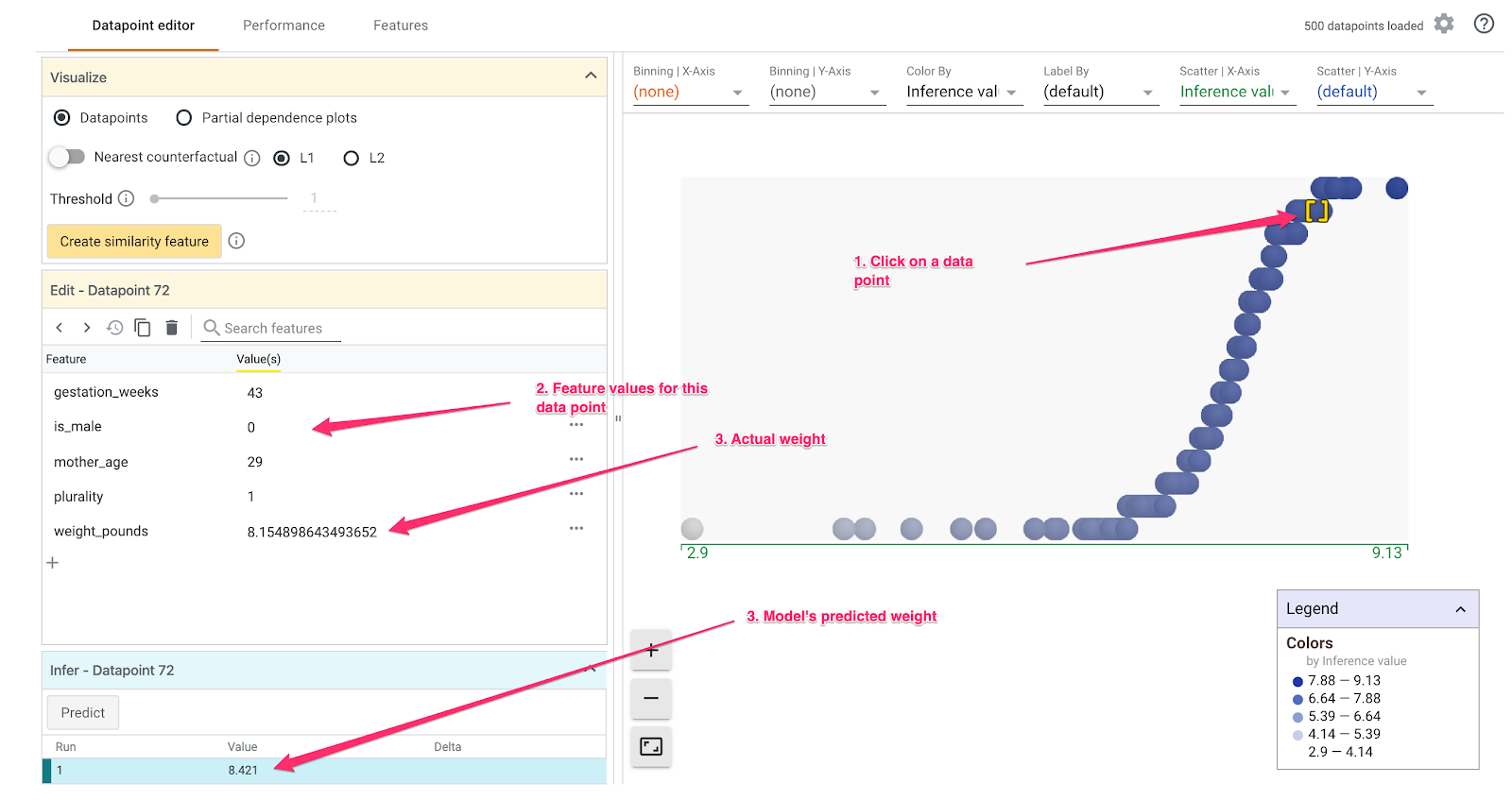
左側に、選択したデータポイントの特徴値が表示されます。また、そのデータポイントの正解ラベルとモデルが予測した値を比較することもできます。左側のサイドバーで、特徴値を変更してモデルの予測を再実行し、この変更がモデルに与えた影響を確認することもできます。 たとえば、このデータポイントの gestation_weeks を 30 に変更するには、ダブルクリックして予測を再実行します。

What-If ツールのプロット セクションのプルダウン メニューを使用すると、さまざまなカスタム ビジュアライゼーションを作成できます。たとえば、次のグラフでは、x 軸にモデルの予測体重、y 軸に母親の年齢、推論エラーで色分けされたポイントが表示されます(色が濃いほど、予測体重と実際の体重の差が大きくなります)。ここでは、体重が減少するにつれて、モデルのエラーがわずかに増加しているようです。

次に、左側の [Partial dependence plots] ボタンをクリックします。これにより、各特徴がモデルの予測に与える影響を確認できます。たとえば、妊娠期間が長くなるにつれて、モデルが予測する赤ちゃんの体重も増加します。

What-If ツールを使用した探索のアイデアについては、このセクションの冒頭にあるリンクをご覧ください。
7. 省略可: ローカルの Git リポジトリを GitHub に接続する
最後に、ノートブック インスタンスの Git リポジトリを GitHub アカウントのリポジトリに接続する方法について説明します。この手順を行うには、GitHub アカウントが必要です。
ステップ 1: GitHub に新しいリポジトリを作成する
GitHub アカウントで、新しいリポジトリを作成します。名前と説明を入力し、公開するかどうかを決定して、[リポジトリを作成] を選択します(README で初期化する必要はありません)。次のページで、コマンドラインから既存のリポジトリを push する手順に沿って操作します。
ターミナル ウィンドウを開き、新しいリポジトリをリモートとして追加します。次のリポジトリ URL の username を GitHub ユーザー名に、your-repo を作成したリポジトリの名前に置き換えます。
git remote add origin git@github.com:username/your-repo.git
ステップ 2: ノートブック インスタンスで GitHub を認証する
次に、ノートブック インスタンス内から GitHub を認証する必要があります。このプロセスは、GitHub で 2 要素認証が有効になっているかどうかによって異なります。
どこから始めればよいかわからない場合は、GitHub ドキュメントの手順に沿って SSH 認証鍵を作成 し、 新しい鍵を GitHub に追加 します。
ステップ 3: GitHub リポジトリが正しくリンクされていることを確認する
正しく設定されていることを確認するには、ターミナルで git remote -v を実行します。新しいリポジトリがリモートとして表示されます。GitHub リポジトリの URL が表示され、ノートブックから GitHub を認証したら、ノートブック インスタンスから GitHub に直接 push する準備が整います。
ローカルのノートブック Git リポジトリを新しく作成した GitHub リポジトリと同期するには、Git サイドバーの上部にあるクラウド アップロード ボタンをクリックします。

GitHub リポジトリを更新すると、以前の commit を含むノートブック コードが表示されます。他のユーザーが GitHub リポジトリにアクセスでき、ノートブックの最新の変更を pull したい場合は、クラウド ダウンロード アイコンをクリックして変更を同期します。
Notebooks Git UI の [履歴] タブで、ローカルの commit が GitHub と同期されているかどうかを確認できます。この例では、origin/master は GitHub のリポジトリに対応しています。

新しい commit を行うたびに、クラウド アップロード ボタンをもう一度クリックして、変更を GitHub リポジトリに push します。
8. お疲れさまでした。
このラボでは多くのことを学びました。👏👏👏
まとめると、次の方法を学習しました。
- AI Platform Notebook インスタンスを作成してカスタマイズする
- そのインスタンスでローカルの Git リポジトリを初期化し、Git UI またはコマンドラインから commit を追加し、Notebook Git UI で Git の差分を表示する
- シンプルな TensorFlow 2 モデルを構築してトレーニングする
- Notebook インスタンス内で What-If ツールを使用する
- Notebook Git リポジトリを GitHub の外部リポジトリに接続する
9. クリーンアップ
このノートブックを引き続き使用する場合は、未使用時にオフにすることをおすすめします。Cloud コンソールの Notebooks UI で、ノートブックを選択して [停止] をクリックします。

このラボで作成したリソースをすべて削除する場合は、ノートブック インスタンスを停止するのではなく削除します。
Cloud コンソールのナビゲーション メニューで [ストレージ] に移動し、モデルアセットの保存用に作成した両方のバケットを削除します。