
1. Visão geral
Neste laboratório, você vai conhecer várias ferramentas dos Notebooks da AI Platform para explorar seus dados e criar protótipos de modelos de ML.
Conteúdo do laboratório
Você vai aprender a:
- Criar e personalizar uma instância do AI Platform Notebooks
- Rastrear seu código de notebook com o git, diretamente integrado ao Notebooks do AI Platform
- Usar a Ferramenta What-If no notebook
O custo total da execução deste laboratório no Google Cloud é de aproximadamente US$ 1. Confira todos os detalhes sobre os preços do AI Platform Notebooks aqui.
2. Criar uma instância do AI Platform Notebooks
Para executar este codelab, você vai precisar de um projeto do Google Cloud Platform com o faturamento ativado. Para criar um projeto, siga estas instruções.
Etapa 2: ativar a API Compute Engine
Acesse o Compute Engine e selecione Ativar, caso essa opção ainda não esteja ativada. Você vai precisar disso para criar sua instância de notebook.
Etapa 3: criar uma instância de notebook
Acesse a seção AI Platform Notebooks do console do Cloud e clique em Nova instância. Em seguida, selecione o tipo de instância mais recente do TensorFlow 2 Enterprise sem GPUs:

Dê um nome à instância ou use o padrão. Em seguida, vamos conhecer as opções de personalização. Clique no botão Personalizar:

O AI Platform Notebooks tem várias opções de personalização, incluindo: a região em que sua instância é implantada, o tipo de imagem, o tamanho da máquina, o número de GPUs e muito mais. Vamos usar os padrões para região e ambiente. Para a configuração da máquina, vamos usar uma máquina n1-standard-8:

Não vamos adicionar GPUs e vamos usar os padrões para disco de inicialização, rede e permissão. Selecione Criar para criar a instância. Esse processo leva alguns minutos.
Quando a instância for criada, uma marca de seleção verde vai aparecer ao lado dela na interface do Notebooks. Selecione Abrir JupyterLab para abrir sua instância e começar a criar protótipos:

Ao abrir a instância, crie um diretório chamado codelab. Este é o diretório em que vamos trabalhar durante este laboratório:

Clique duas vezes no diretório codelab recém-criado e selecione o notebook Python 3 na tela de início:

Renomeie o notebook para demo.ipynb ou qualquer outro nome que você queira dar a ele.
Etapa 4: importar pacotes do Python
Crie uma célula no notebook e importe as bibliotecas que vamos usar neste codelab:
import pandas as pd
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
import json
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from google.cloud import bigquery
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
3. Conectar dados do BigQuery ao notebook
O BigQuery, data warehouse para Big Data do Google Cloud, disponibilizou vários conjuntos de dados para você explorar. Os notebooks da AI Platform oferecem suporte à integração direta com o BigQuery sem exigir autenticação.
Neste laboratório, vamos usar o conjunto de dados de natalidade. Ele contém dados de quase todos os nascimentos nos EUA em um período de 40 anos, incluindo o peso ao nascer da criança e informações demográficas sobre os pais do bebê. Vamos usar um subconjunto dos recursos para prever o peso de um bebê ao nascer.
Etapa 1: faça o download dos dados do BigQuery para o notebook
Vamos usar a biblioteca de cliente Python do BigQuery para fazer o download dos dados em um DataFrame do Pandas. O conjunto de dados original tem 21 GB e contém 123 milhões de linhas. Para simplificar,vamos usar apenas 10 mil linhas do conjunto de dados.
Construa a consulta e visualize o DataFrame resultante com o código a seguir. Aqui, estamos recebendo quatro recursos do conjunto de dados original, além do peso do bebê (o que nosso modelo vai prever). O conjunto de dados é de muitos anos atrás, mas, para este modelo, vamos usar apenas dados de depois de 2000:
query="""
SELECT
weight_pounds,
is_male,
mother_age,
plurality,
gestation_weeks
FROM
publicdata.samples.natality
WHERE year > 2000
LIMIT 10000
"""
df = bigquery.Client().query(query).to_dataframe()
df.head()
Para receber um resumo dos recursos numéricos no conjunto de dados, execute:
df.describe()
Isso mostra a média, o desvio padrão, o mínimo e outras métricas das colunas numéricas. Por fim, vamos coletar alguns dados sobre a coluna booleana que indica o sexo do bebê. Podemos fazer isso com o método value_counts do Pandas:
df['is_male'].value_counts()
Parece que o conjunto de dados está quase equilibrado em 50/50 por gênero.
Etapa 2: preparar o conjunto de dados para treinamento
Agora que baixamos o conjunto de dados para o notebook como um DataFrame do Pandas, podemos fazer um pré-processamento e dividi-lo em conjuntos de treinamento e teste.
Primeiro, vamos descartar as linhas com valores nulos do conjunto de dados e embaralhar os dados:
df = df.dropna()
df = shuffle(df, random_state=2)
Em seguida, extraia a coluna de rótulo para uma variável separada e crie um DataFrame com apenas nossos atributos. Como is_male é um booleano, vamos convertê-lo em um número inteiro para que todas as entradas do nosso modelo sejam numéricas:
labels = df['weight_pounds']
data = df.drop(columns=['weight_pounds'])
data['is_male'] = data['is_male'].astype(int)
Agora, se você visualizar o conjunto de dados executando data.head(), vai ver os quatro recursos que vamos usar para treinamento.
4. Inicializar o Git
O AI Platform Notebooks tem uma integração direta com o git para que você possa fazer o controle de versão diretamente no ambiente do notebook. Isso permite confirmar o código diretamente na interface do notebook ou pelo terminal disponível no JupyterLab. Nesta seção, vamos inicializar um repositório git no notebook e fazer nosso primeiro commit pela interface.
Etapa 1: inicializar um repositório Git
No diretório do codelab, selecione Git e Init na barra de menus superior do JupyterLab:

Quando perguntar se você quer transformar esse diretório em um repositório Git, selecione Sim. Em seguida, selecione o ícone do Git na barra lateral esquerda para conferir o status dos seus arquivos e commits:

Etapa 2: fazer seu primeiro commit
Nessa interface, é possível adicionar arquivos a um commit, ver as diferenças entre arquivos (vamos falar disso mais tarde) e confirmar as mudanças. Vamos começar confirmando o arquivo de notebook que acabamos de adicionar.
Marque a caixa ao lado do arquivo de notebook demo.ipynb para prepará-lo para o commit. Ignore o diretório .ipynb_checkpoints/. Insira uma mensagem de commit na caixa de texto e clique na marca de seleção para confirmar as mudanças:
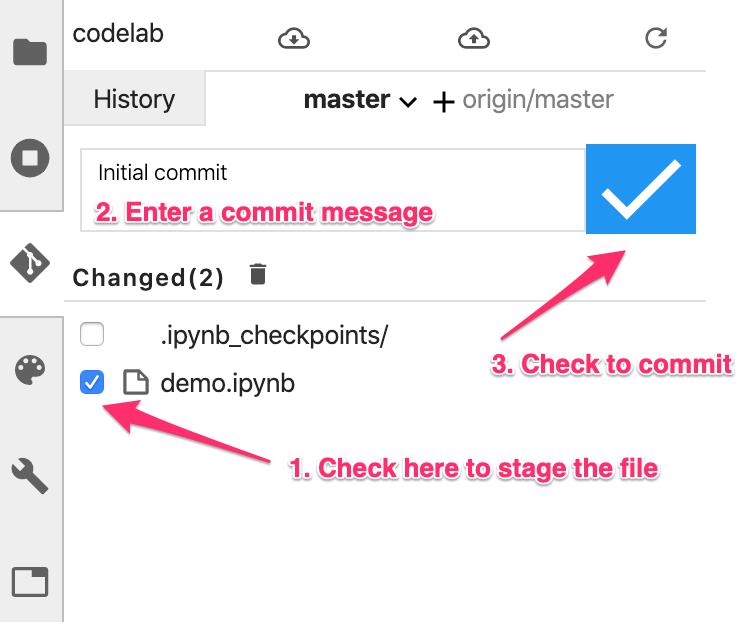
Insira seu nome e e-mail quando solicitado. Em seguida, volte para a guia Histórico para ver seu primeiro commit:
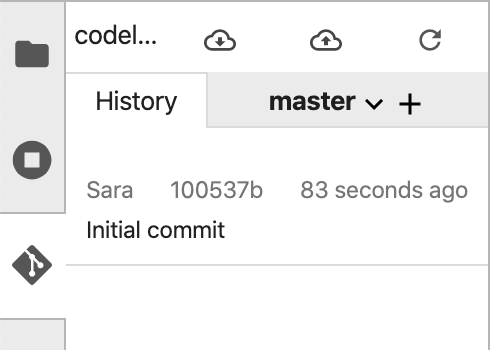
Observe que as capturas de tela podem não corresponder exatamente à sua interface devido a atualizações feitas desde a publicação deste laboratório.
5. Criar e treinar um modelo do TensorFlow
Vamos usar o conjunto de dados de natalidade do BigQuery que baixamos para o notebook e criar um modelo que prevê o peso do bebê. Neste laboratório, vamos focar nas ferramentas do notebook, e não na acurácia do modelo em si.
Etapa 1: dividir os dados em conjuntos de treinamento e teste
Vamos usar o utilitário train_test_split do Scikit Learn para dividir os dados antes de criar o modelo:
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
Agora estamos prontos para criar nosso modelo do TensorFlow.
Etapa 2: criar e treinar o modelo do TensorFlow
Vamos criar esse modelo usando a API de modelo Sequential do tf.keras, que permite definir o modelo como uma pilha de camadas. Todo o código necessário para criar nosso modelo está aqui:
model = Sequential([
Dense(64, activation='relu', input_shape=(len(x_train.iloc[0]),)),
Dense(32, activation='relu'),
Dense(1)]
)
Depois, vamos compilar o modelo para treiná-lo. Aqui, vamos escolher o otimizador, a função de perda e as métricas que queremos que o modelo registre durante o treinamento. Como este é um modelo de regressão (que prevê um valor numérico), usamos o erro quadrático médio em vez da acurácia como métrica:
model.compile(optimizer=tf.keras.optimizers.RMSprop(),
loss=tf.keras.losses.MeanSquaredError(),
metrics=['mae', 'mse'])
Use a função model.summary() do Keras para conferir o formato e o número de parâmetros treináveis do modelo em cada camada.
Agora podemos treinar nosso modelo. Basta chamar o método fit(), transmitindo os dados e rótulos de treinamento. Aqui, vamos usar o parâmetro opcional "validation_split", que vai reter uma parte dos nossos dados de treinamento para validar o modelo em cada etapa. O ideal é que a perda de treinamento e validação diminuam. Mas lembre-se de que, neste exemplo, estamos mais focados em ferramentas de modelo e notebook do que na qualidade do modelo:
model.fit(x_train, y_train, epochs=10, validation_split=0.1)
Etapa 3: gerar previsões em exemplos de teste
Para ver o desempenho do nosso modelo, vamos gerar algumas previsões de teste nos 10 primeiros exemplos do conjunto de dados de teste.
num_examples = 10
predictions = model.predict(x_test[:num_examples])
Em seguida, vamos iterar pelas previsões do modelo, comparando-as com o valor real:
for i in range(num_examples):
print('Predicted val: ', predictions[i][0])
print('Actual val: ',y_test.iloc[i])
print()
Etapa 4: usar git diff e confirmar as mudanças
Agora que você fez algumas mudanças no notebook, teste o recurso git diff disponível na interface do Git dos notebooks. O notebook demo.ipynb agora vai estar na seção "Mudanças" da interface. Passe o cursor sobre o nome do arquivo e clique no ícone de diff:

Assim, você poderá ver um diff das suas mudanças, como este:

Desta vez, vamos confirmar as mudanças pela linha de comando usando o Terminal. No menu Git na barra de menus superior do JupyterLab, selecione Comando do Git no terminal. Se você deixar a guia do git na barra lateral esquerda aberta enquanto executa os comandos abaixo, poderá ver as mudanças refletidas na interface do git.
Na nova instância do terminal, execute o seguinte comando para preparar o arquivo de notebook para commit:
git add demo.ipynb
Em seguida, execute o comando a seguir para confirmar as mudanças (use a mensagem de confirmação que quiser):
git commit -m "Build and train TF model"
Em seguida, você vai ver o commit mais recente no histórico:

6. Usar a Ferramenta What-If diretamente do notebook
A Ferramenta What-If é uma interface visual interativa criada para ajudar você a visualizar seus conjuntos de dados e entender melhor a saída dos modelos de ML. É uma ferramenta de código aberto criada pela equipe do PAIR no Google. Embora funcione com qualquer tipo de modelo, ele tem alguns recursos criados exclusivamente para a AI Platform da IA do Google Cloud.
A Ferramenta What-If vem pré-instalada em instâncias de notebooks do AI Platform do Google Cloud com TensorFlow. Aqui, vamos usá-lo para ver o desempenho geral do nosso modelo e inspecionar o comportamento dele em pontos de dados do nosso conjunto de teste.
Etapa 1: preparar os dados para a Ferramenta What-If
Para aproveitar ao máximo a ferramenta What-If, vamos enviar exemplos do nosso conjunto de teste junto com os rótulos de informações empíricas desses exemplos (y_test). Assim, podemos comparar o que nosso modelo previu com as informações empíricas. Execute a linha de código abaixo para criar um novo DataFrame com nossos exemplos de teste e os rótulos deles:
wit_data = pd.concat([x_test, y_test], axis=1)
Neste laboratório, vamos conectar a Ferramenta What-If ao modelo que acabamos de treinar no notebook. Para isso, precisamos escrever uma função que a ferramenta vai usar para executar esses pontos de dados de teste no nosso modelo:
def custom_predict(examples_to_infer):
preds = model.predict(examples_to_infer)
return preds
Etapa 2: instanciar a Ferramenta What-If
Vamos instanciar a Ferramenta What-If passando 500 exemplos do conjunto de dados de teste concatenado e os rótulos de informações empíricas que acabamos de criar. Criamos uma instância de WitConfigBuilder para configurar a ferramenta, transmitindo nossos dados, a função de previsão personalizada definida acima, junto com nosso destino (o que estamos prevendo) e o tipo de modelo:
config_builder = (WitConfigBuilder(wit_data[:500].values.tolist(), data.columns.tolist() + ['weight_pounds'])
.set_custom_predict_fn(custom_predict)
.set_target_feature('weight_pounds')
.set_model_type('regression'))
WitWidget(config_builder, height=800)
Você vai ver algo assim quando a Ferramenta What-If for carregada:

No eixo x, é possível ver os pontos de dados de teste distribuídos pelo valor de peso previsto do modelo, weight_pounds.
Etapa 3: analisar o comportamento do modelo com a Ferramenta What-If
Há muitas coisas legais que você pode fazer com a Ferramenta What-If. Vamos conhecer alguns deles. Primeiro, vamos analisar o editor de pontos de dados. É possível selecionar qualquer ponto de dados para ver os recursos e mudar os valores deles. Clique em qualquer ponto de dados:

À esquerda, você verá os valores de recursos do ponto de dados selecionado. Você também pode comparar o rótulo de informação empírica desse ponto de dados com o valor previsto pelo modelo. Na barra lateral à esquerda, também é possível mudar os valores dos recursos e executar novamente a previsão do modelo para ver o efeito dessa mudança. Por exemplo, podemos mudar gestation_weeks para 30 nesse ponto de dados clicando duas vezes nele e executando a previsão novamente:

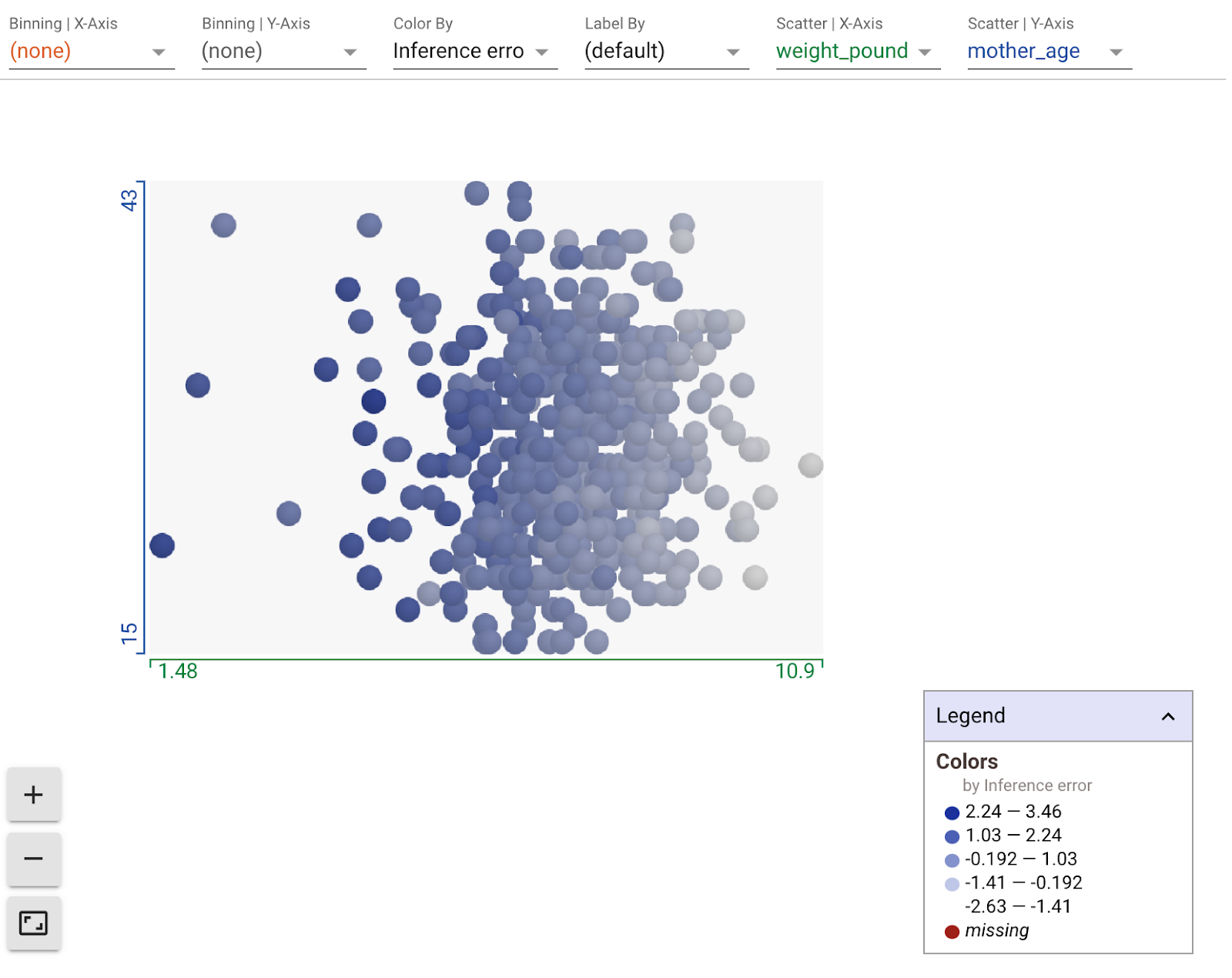
Usando os menus suspensos na seção de gráficos da Ferramenta What-If, é possível criar todos os tipos de visualizações personalizadas. Por exemplo, aqui está um gráfico com o peso previsto dos modelos no eixo x, a idade da mãe no eixo y e pontos coloridos pelo erro de inferência (quanto mais escuro, maior a diferença entre o peso previsto e o real). Aqui, parece que, à medida que o peso diminui, o erro do modelo aumenta um pouco:
Em seguida, marque o botão Gráficos de dependência parcial à esquerda. Isso mostra como cada atributo influencia a previsão do modelo. Por exemplo, à medida que o tempo de gestação aumenta, o peso previsto do bebê pelo modelo também aumenta:

Para mais ideias de exploração com a Ferramenta What-If, confira os links no início desta seção.
7. Opcional: conecte seu repositório git local ao GitHub
Por fim, vamos aprender a conectar o repositório git na nossa instância de notebook a um repositório na nossa conta do GitHub. Se quiser fazer isso, você vai precisar de uma conta do GitHub.
Etapa 1: criar um novo repositório no GitHub
Na sua conta do GitHub, crie um repositório. Dê um nome e uma descrição, decida se quer que ele seja público e selecione Criar repositório. Não é necessário inicializar com um README. Na próxima página, siga as instruções para enviar um repositório atual da linha de comando.
Abra uma janela do terminal e adicione o novo repositório como um controle remoto. Substitua username no URL do repositório abaixo pelo seu nome de usuário do GitHub e your-repo pelo nome do repositório que você acabou de criar:
git remote add origin git@github.com:username/your-repo.git
Etapa 2: autenticar no GitHub na instância do Notebooks
Em seguida, você precisará se autenticar no GitHub na instância do notebook. Esse processo varia de acordo com a ativação da autenticação de dois fatores no GitHub.
Se você não souber por onde começar, siga as etapas na documentação do GitHub para criar uma chave SSH e adicionar a nova chave ao GitHub.
Etapa 3: verificar se você vinculou o repositório do GitHub corretamente
Para verificar se você configurou tudo corretamente, execute git remote -v no terminal. O novo repositório vai aparecer como um remoto. Depois que o URL do seu repositório do GitHub aparecer e você tiver feito a autenticação no GitHub pelo notebook, já será possível enviar diretamente para o GitHub da instância do notebook.
Para sincronizar o repositório git do notebook local com o repositório do GitHub recém-criado, clique no botão de upload na nuvem na parte de cima da barra lateral do Git:

Atualize seu repositório do GitHub. O código do notebook vai aparecer com os commits anteriores. Se outras pessoas tiverem acesso ao seu repo do GitHub e você quiser extrair as mudanças mais recentes para seu notebook, clique no ícone de download na nuvem para sincronizar essas mudanças.
Na guia "Histórico" da interface do Git dos notebooks, é possível verificar se os commits locais estão sincronizados com o GitHub. Neste exemplo, origin/master corresponde ao nosso repositório no GitHub:

Sempre que você fizer novas confirmações, clique no botão de upload na nuvem novamente para enviar essas mudanças ao repositório do GitHub.
8. Parabéns!
Você fez muito neste laboratório 👏👏👏
Para recapitular, você aprendeu a:
- Criar e personalizar uma instância de notebook do AI Platform
- Inicialize um repositório git local nessa instância, adicione commits pela interface ou linha de comando do git e confira as diferenças do git na interface do Notebook.
- Criar e treinar um modelo simples do TensorFlow 2
- Usar a Ferramenta What-If na instância do notebook
- Conecte o repositório git do notebook a um repositório externo no GitHub
9. Limpeza
Se você quiser continuar usando esse notebook, recomendamos que o desative quando não estiver em uso. Na interface de Notebooks no console do Cloud, selecione o notebook e clique em Parar:

Se você quiser excluir todos os recursos criados neste laboratório, basta excluir a instância do notebook em vez de interrompê-la.
No menu de navegação do console do Cloud, acesse "Storage" e exclua os dois buckets criados para armazenar os recursos do modelo.