
1. 概览
本 Codelab 将介绍如何在 Google Cloud Platform 上使用 Apache Spark 和 Dataproc 来创建数据处理流水线。数据科学和数据工程领域有一种常见的使用场景,即,从一个存储位置读取数据,对数据执行转换,然后将数据写入另一个存储位置。常见的转换包括更改数据内容、去除不必要的信息以及更改文件类型。
在本 Codelab 中,您将了解 Apache Spark,并使用 Dataproc 和 PySpark(Apache Spark 的 Python API)、 BigQuery、 Google Cloud Storage 以及 Reddit 中的数据运行示例流水线。
2. Apache Spark 简介(可选)
根据该网站的介绍,“Apache Spark 是一个用于进行大规模数据处理的统一分析引擎。”它可让您并行地在内存中分析和处理数据,从而实现跨多个不同机器和节点的大规模并行计算。它最初于 2014 年发布,是对传统 MapReduce 的升级,并且仍然是执行大规模计算的最受欢迎的框架之一。Apache Spark 使用 Scala 编写,随后在 Scala、Java、Python 和 R 中提供了 API。它包含大量库,例如用于对数据执行 SQL 查询的 Spark SQL 、用于流式传输数据的 Spark Streaming 、用于机器学习的 MLlib 以及用于图处理的 GraphX ,所有这些库都在 Apache Spark 引擎上运行。
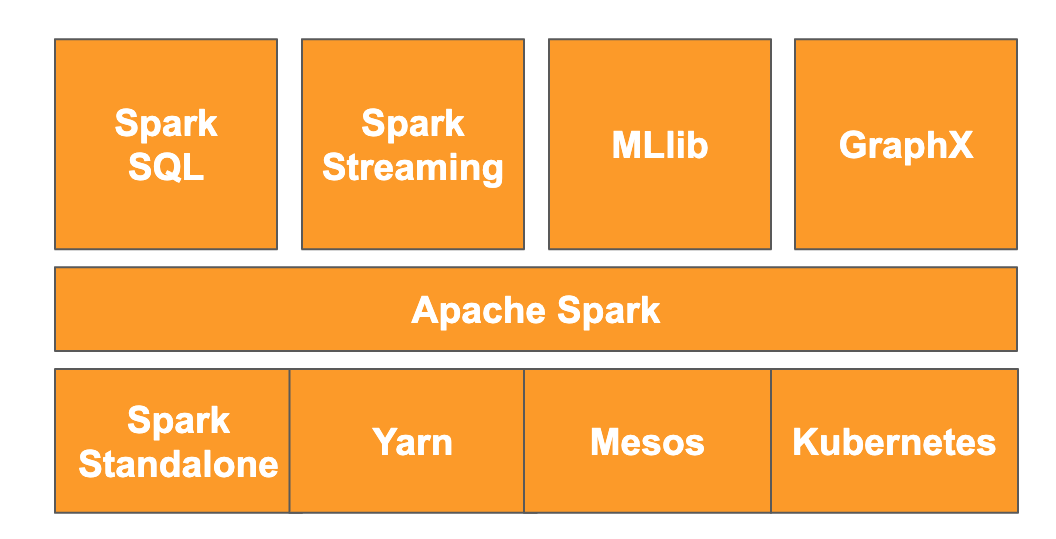
Spark 可以自行运行,也可以利用资源管理服务(例如 Yarn、Mesos 或 Kubernetes)进行扩缩。在本 Codelab 中,您将使用 Dataproc,它利用了 Yarn。
Spark 中的数据最初加载到内存中,即所谓的 RDD 或弹性分布式数据集。此后,Spark 的开发包括添加了两种新的列式数据类型:Dataset(已输入)和 Dataframe(未输入)。粗略地说,RDD 非常适合任何类型的数据,而 Dataset 和 Dataframe 则针对表格数据进行了优化。由于 Dataset 仅适用于 Java 和 Scala API,因此在本 Codelab 中,我们将继续使用 PySpark Dataframe API。如需了解详情,请参阅 Apache Spark 文档。
3. 应用场景
数据工程师通常需要让数据科学家能够轻松访问数据。但是,数据通常最初是脏数据(当前状态下难以用于分析),需要先进行清理,然后才能发挥很大作用。一个示例是从网络抓取的数据,这些数据可能包含奇怪的编码或多余的 HTML 标记。
在本实验中,您将以 Reddit 帖子形式从 BigQuery 加载一组数据到 Dataproc 上托管的 Spark 集群中,提取有用信息,并将处理后的数据作为压缩的 CSV 文件存储在 Google Cloud Storage 中。
贵公司的首席数据科学家希望其团队处理不同的自然语言处理问题。具体而言,他们对分析“r/food”子版块中的数据感兴趣。您将创建一个数据转储流水线,从 2017 年 1 月到 2019 年 8 月开始进行回填。
4. 通过 BigQuery Storage API 访问 BigQuery
使用 tabledata.list API 方法 从 BigQuery 中提取数据可能会非常耗时且效率不高,因为数据量会不断扩大。此方法会返回 JSON 对象列表,并且需要依序一次读取一页,才能读取整个数据集。
BigQuery Storage API 使用基于 RPC 的协议,显著改进了对 BigQuery 中数据的访问。它支持并行读取和写入数据,以及不同的序列化格式,例如 Apache Avro 和 Apache Arrow。从宏观层面来看,这可以显著提高性能,尤其是在处理较大数据集时。
在本 Codelab 中,您将使用 spark-bigquery-connector 在 BigQuery 和 Spark 之间读取和写入数据。
5. 创建项目
登录 Google Cloud Platform 控制台 (console.cloud.google.com) 并创建一个新项目:



接下来,您需要在 Cloud 控制台中启用结算功能,才能使用 Google Cloud 资源。
在此 Codelab 中运行仅花费几美元,但是如果您决定使用更多资源或继续让它们运行,费用可能更高。本 Codelab 的最后一节将引导您清理项目。
Google Cloud Platform 的新用户有资格获享 $300 免费试用。
6. 设置您的环境
您现在将通过以下方式设置环境:
- 启用 Compute Engine、Dataproc 和 BigQuery Storage API
- 配置项目设置
- 创建 Dataproc 集群
- 创建 Google Cloud Storage 存储分区
启用 API 并配置环境
按 Cloud 控制台右上角的按钮,打开 Cloud Shell。
Cloud Shell 加载完毕后,运行以下命令以启用 Compute Engine、Dataproc 和 BigQuery Storage API:
gcloud services enable compute.googleapis.com \
dataproc.googleapis.com \
bigquerystorage.googleapis.com
设置项目的项目 ID 。您可以前往项目选择页面并搜索您的项目来找到它。这可能与您的项目名称不同。

运行以下命令以设置您的项目 ID:
gcloud config set project <project_id>
从此处列表中选择一个,以设置项目的区域。例如,us-central1。
gcloud config set dataproc/region <region>
为 Dataproc 集群选择一个名称并为其创建环境变量。
CLUSTER_NAME=<cluster_name>
创建 Dataproc 集群
执行以下命令以创建 Dataproc 集群:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--worker-machine-type n1-standard-8 \
--num-workers 8 \
--image-version 1.5-debian \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--optional-components=ANACONDA \
--enable-component-gateway
此命令需要几分钟才能完成。如需分解该命令,请执行以下操作:
这将启动 Dataproc 集群的创建,并使用您之前提供的名称。使用 beta API 将启用 Dataproc 的 Beta 版功能,例如 组件网关。
gcloud beta dataproc clusters create ${CLUSTER_NAME}
这将设置用于工作器的机器类型。
--worker-machine-type n1-standard-8
这将设置集群将拥有的工作器数量。
--num-workers 8
这将设置 Dataproc 的 映像版本。
--image-version 1.5-debian
这将配置要在集群上使用的 初始化操作。在这里,您将添加 pip 初始化操作。
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh
这是要包含在集群中的元数据。在这里,您将为 pip 初始化操作提供元数据。
--metadata 'PIP_PACKAGES=google-cloud-storage'
这将设置要在集群上安装的 可选组件。
--optional-components=ANACONDA
这将启用组件网关,让您可以使用 Dataproc 的组件网关 查看常见界面,例如 Zeppelin、Jupyter 或 Spark History
--enable-component-gateway
如需详细了解 Dataproc,请查看此 Codelab。
创建 Google Cloud Storage 存储分区
您需要使用 Google Cloud Storage 存储分区来存储作业输出。确定存储分区的唯一名称,然后运行以下命令以创建新存储分区。存储分区名称在所有用户的 Google Cloud 项目中都是唯一的,因此您可能需要使用不同的名称尝试几次。如果您没有收到 ServiceException,则表示存储分区已成功创建。
BUCKET_NAME=<bucket_name>
gsutil mb gs://${BUCKET_NAME}
7. 探索性数据分析
在执行预处理之前,您应详细了解所处理数据的性质。为此,您将探索两种数据探索方法。首先,您将使用 BigQuery 网页界面查看一些原始数据,然后使用 PySpark 和 Dataproc 计算每个子版块的帖子数。
使用 BigQuery 网页界面
首先,使用 BigQuery 网页界面查看您的数据。在 Cloud 控制台中,向下滚动并按“BigQuery”以打开 BigQuery 网页界面。
接下来,在 BigQuery 网页界面查询编辑器中运行以下命令。这将返回 2017 年 1 月份数据的 10 个完整行:
select * from fh-bigquery.reddit_posts.2017_01 limit 10;
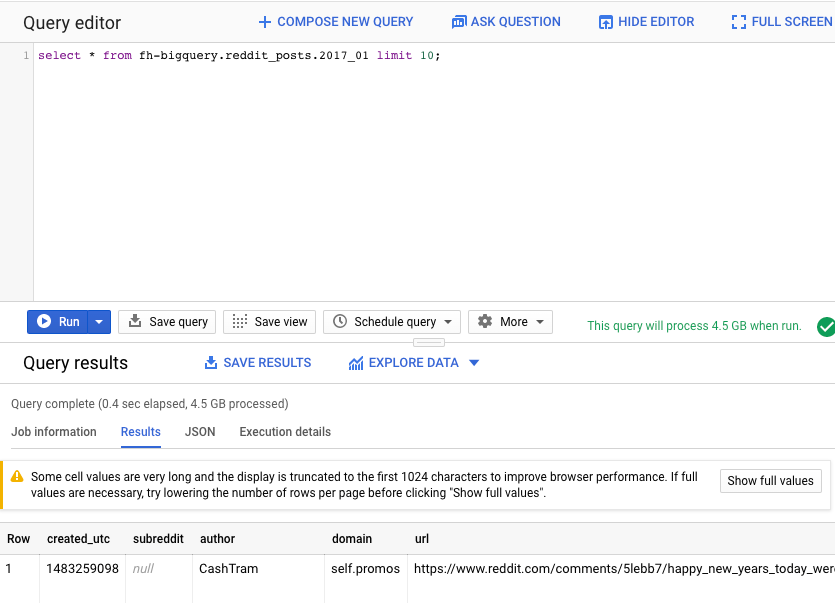
您可以滚动页面以查看所有可用列以及一些示例。具体而言,您将看到两列,它们表示每个信息帖的文本内容:“title”和“selftext”,后者是信息帖的正文。另请注意其他列,例如“created_utc”(帖子发布时的 UTC 时间)和“subreddit”(帖子所在的子版块)。
执行 PySpark 作业
在 Cloud Shell 中运行以下命令,以克隆包含示例代码的代码库并进入正确的目录:
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
您可以使用 PySpark 确定每个子版块的帖子数。您可以打开 Cloud Editor 并读取 脚本 cloud-dataproc/codelabs/spark-bigquery,然后在下一步中执行该脚本:
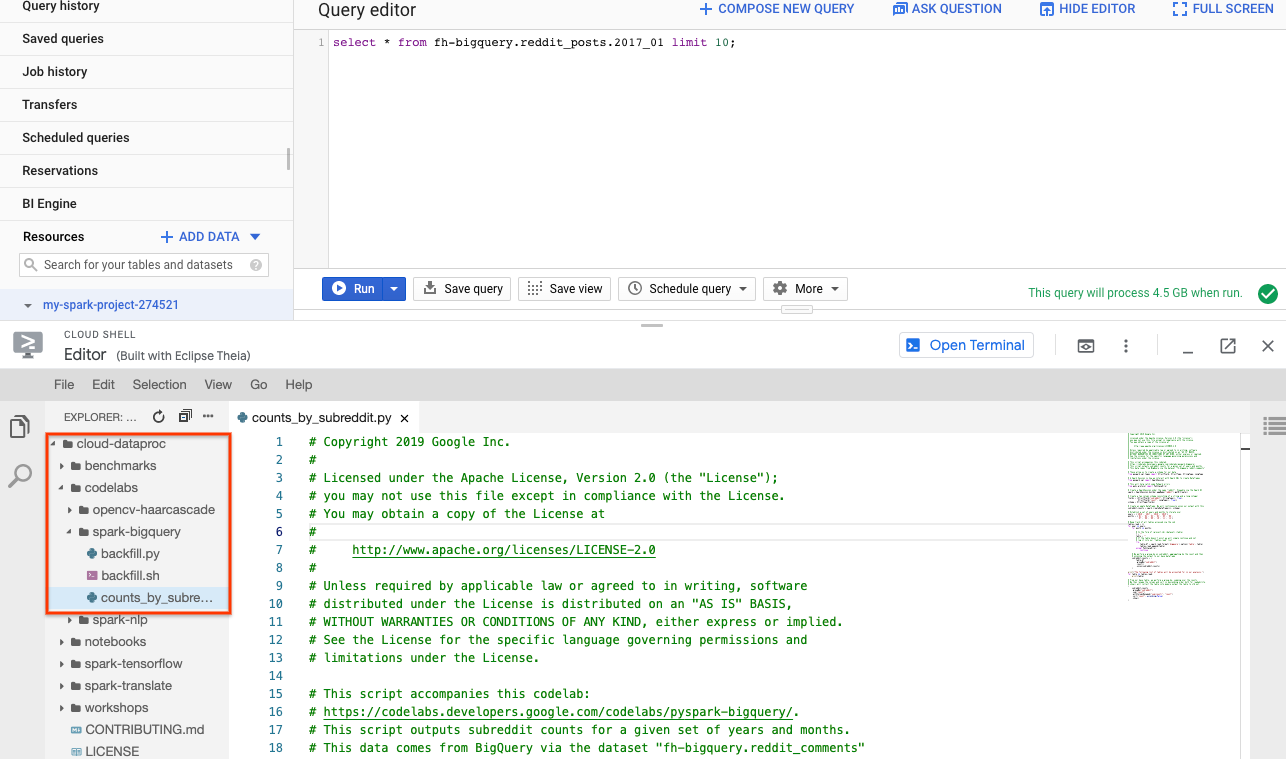
点击 Cloud Editor 中的“打开终端”按钮,切换回 Cloud Shell 并运行以下命令以执行您的第一个 PySpark 作业:
cd ~/cloud-dataproc/codelabs/spark-bigquery
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME} \
--jars gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar \
--driver-log-levels root=FATAL \
counts_by_subreddit.py
此命令可让您通过 Jobs API 将作业提交到 Dataproc。在这里,您将作业类型指定为 pyspark。您可以提供集群名称、 可选参数 以及包含作业的文件名称。在这里,您将提供 --jars 参数,以便将 spark-bigquery-connector 添加到作业中。您还可以使用 --driver-log-levels root=FATAL 设置日志输出级别,这将禁止所有日志输出,但错误除外。Spark 日志往往非常嘈杂。
这应该需要几分钟才能运行,最终输出应如下所示:
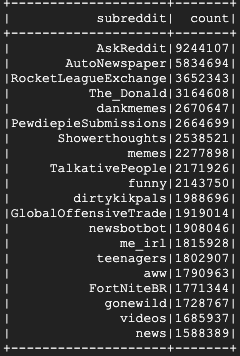
8. 探索 Dataproc 和 Spark 界面
在 Dataproc 上运行 Spark 作业时,您可以使用两个界面来检查作业 / 集群的状态。第一个是 Dataproc 界面,您可以通过点击菜单图标并向下滚动到 Dataproc 来找到它。在这里,您可以看到当前可用内存、待处理内存和工作器数量。
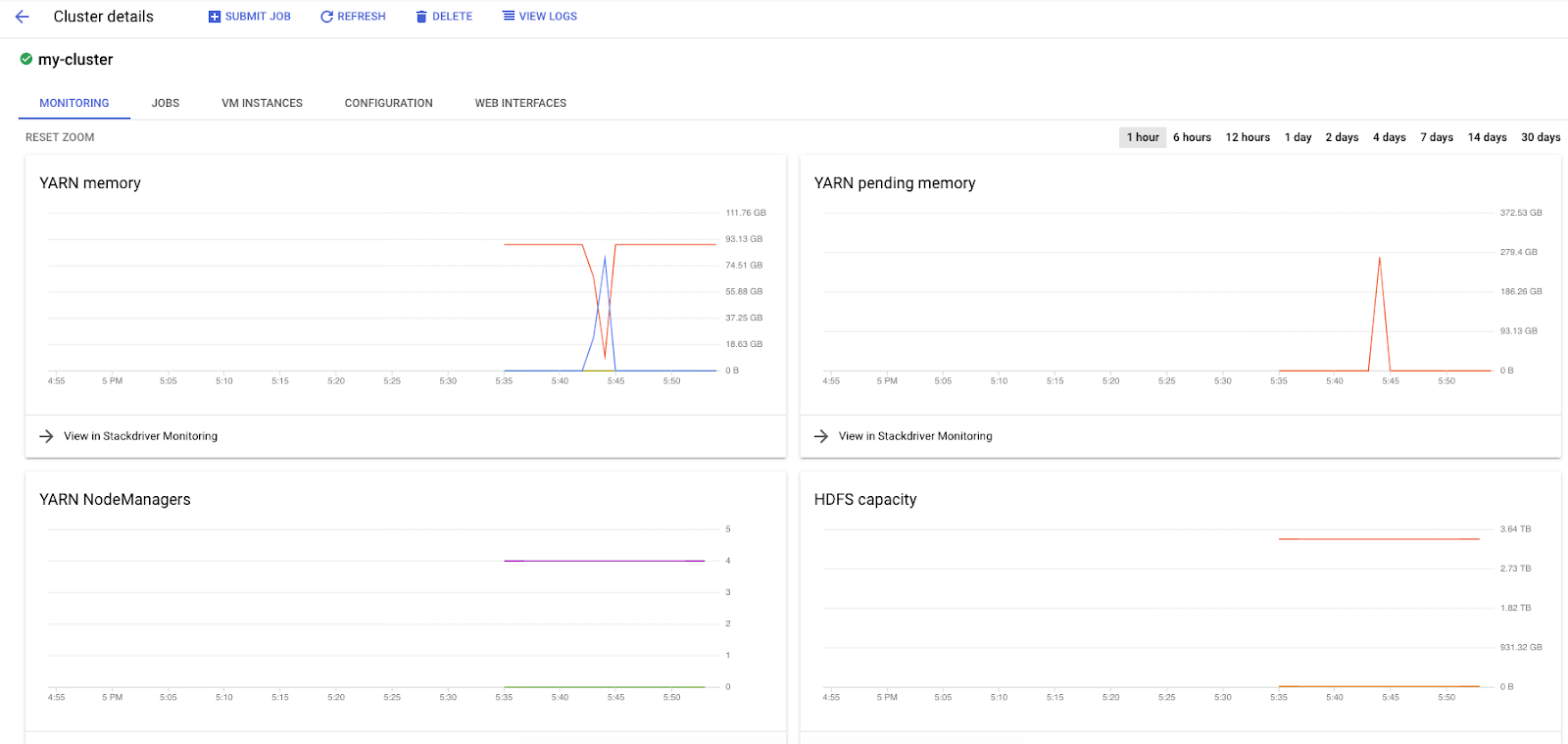
您还可以点击“作业”标签页以查看已完成的作业。点击特定作业的任务 ID,即可查看作业详细信息,例如这些作业的日志和输出。
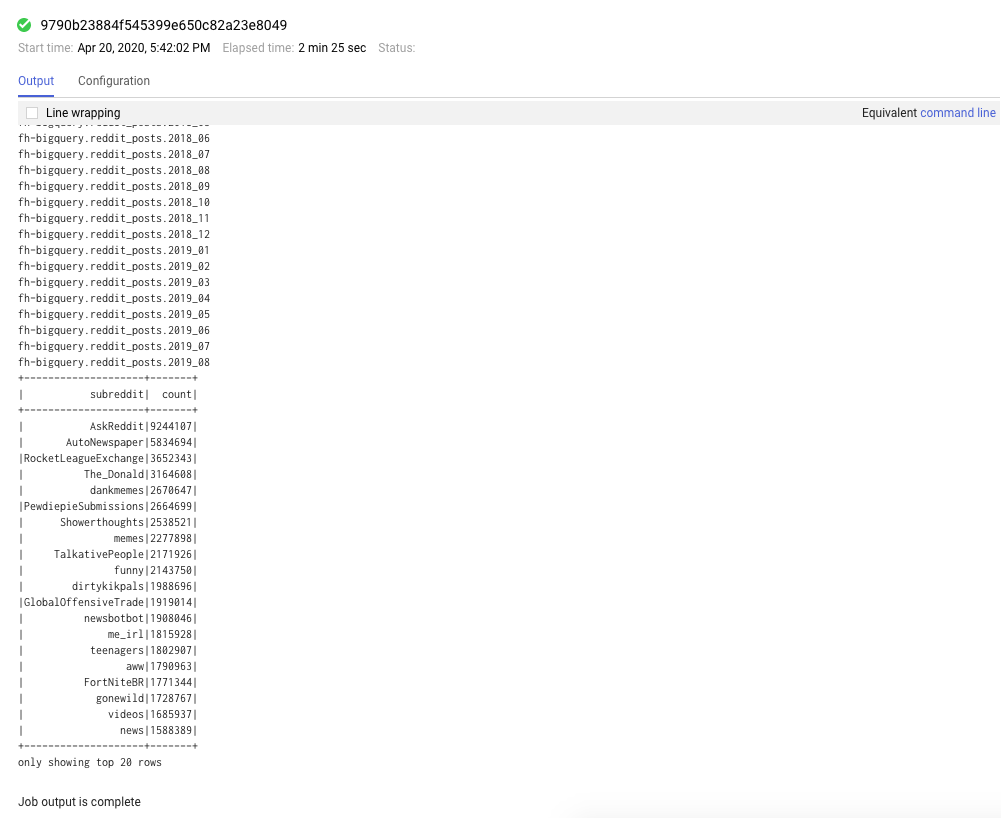
您还可以查看 Spark 界面。在作业页面中,点击后退箭头,然后点击“Web 界面”。您应该会在组件网关下看到多个选项。在设置集群时,可以通过 可选组件 启用其中许多选项。在本实验中,点击“Spark History Server”。

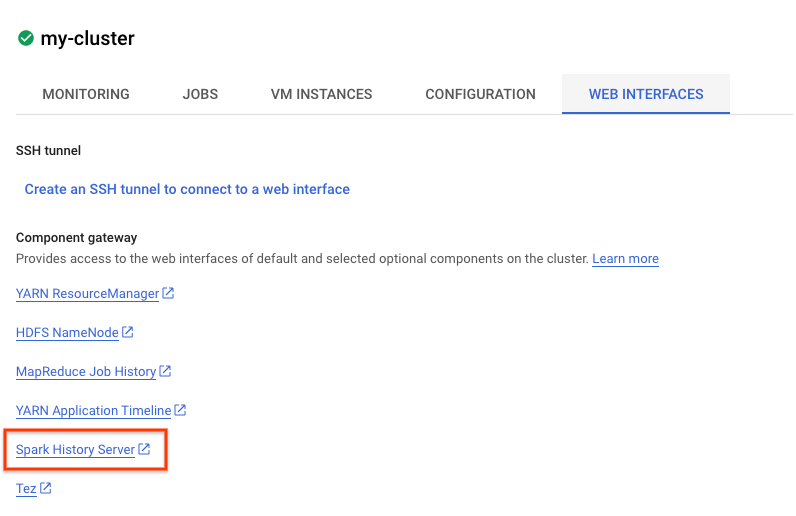
这应该会打开以下窗口:

所有已完成的作业都会显示在此处,您可以点击任何 application_id 以了解有关作业的更多信息。同样,您可以点击着陆页最底部的“显示未完成的应用”以查看当前正在运行的所有作业。
9. 运行回填作业
您现在将运行一个作业,该作业会将数据加载到内存中,提取必要的信息,并将输出转储到 Google Cloud Storage 存储分区中。您将提取每个 Reddit 评论的“title”“body”(原始文本)和“timestamp created”。然后,您将获取此数据,将其转换为 CSV 文件,对其进行压缩,并将其加载到 URI 为 gs://${BUCKET_NAME}/reddit_posts/YYYY/MM/food.csv.gz 的存储分区中。
您可以再次参阅 Cloud Editor,以通读 代码,这是一个用于执行 cloud-dataproc/codelabs/spark-bigquery/backfill.py 中 代码 的封装脚本。cloud-dataproc/codelabs/spark-bigquery/backfill.sh
cd ~/cloud-dataproc/codelabs/spark-bigquery
bash backfill.sh ${CLUSTER_NAME} ${BUCKET_NAME}
您应该很快就会看到一系列作业完成消息。作业可能需要长达 15 分钟才能完成。您还可以使用 gsutil 仔细检查存储分区,以验证数据输出是否成功。所有作业完成后,运行以下命令:
gsutil ls gs://${BUCKET_NAME}/reddit_posts/*/*/food.csv.gz
您应该会看到以下输出内容:
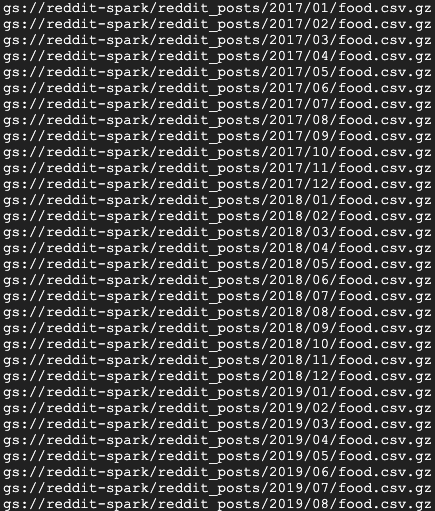
恭喜,您已成功完成 Reddit 评论数据的回填!如果您对如何在此数据的基础上构建模型感兴趣,请继续学习 Spark-NLP Codelab。
10. 清理
为避免在本快速入门完成后向您的 GCP 账号收取不必要的费用,请执行以下操作:
如果您专门为此 Codelab 创建了一个项目,您还可以选择删除该项目:
- 在 GCP 控制台中,转到 **项目** 页面。
- 在项目列表中,选择要删除的项目,然后点击删除 。
- 在框中输入项目 ID,然后点击关停 以删除项目。
许可
此作品已获得知识共享署名 3.0 通用许可和 Apache 2.0 许可授权。