
1. Présentation
Cet atelier de programmation explique comment créer un pipeline de traitement de données à l'aide d'Apache Spark avec Dataproc sur Google Cloud Platform. Il s'agit d'un cas d'utilisation courant de la data science et de l'ingénierie des données pour lire des données à partir d'un emplacement de stockage, et les transformer et les écrire dans un autre emplacement de stockage. Les transformations courantes incluent la modification du contenu des données, la suppression des informations inutiles et la modification des types de fichiers.
Dans cet atelier de programmation, vous allez découvrir Apache Spark, exécuter un exemple de pipeline à l'aide de Dataproc avec PySpark (l'API Python d'Apache Spark), BigQuery, Google Cloud Storage et des données provenant de Reddit.
2. Présentation d'Apache Spark (facultatif)
Selon le site Web, " Apache Spark est un moteur d'analyse unifié pour le traitement des données à grande échelle". Il vous permet d'analyser et de traiter les données en parallèle et en mémoire, ce qui permet un calcul parallèle massif sur plusieurs machines et nœuds différents. Il a été publié en 2014 pour remplacer le MapReduce traditionnel et reste l'un des frameworks les plus populaires pour effectuer des calculs à grande échelle. Apache Spark est écrit en Scala et dispose d'API en Scala, Java, Python et R. Il contient une pléthore de bibliothèques telles que Spark SQL pour exécuter des requêtes SQL sur les données, Spark Streaming pour le streaming de données, MLlib pour le machine learning et GraphX pour le traitement de graphiques, qui s'exécutent toutes sur le moteur Apache Spark.
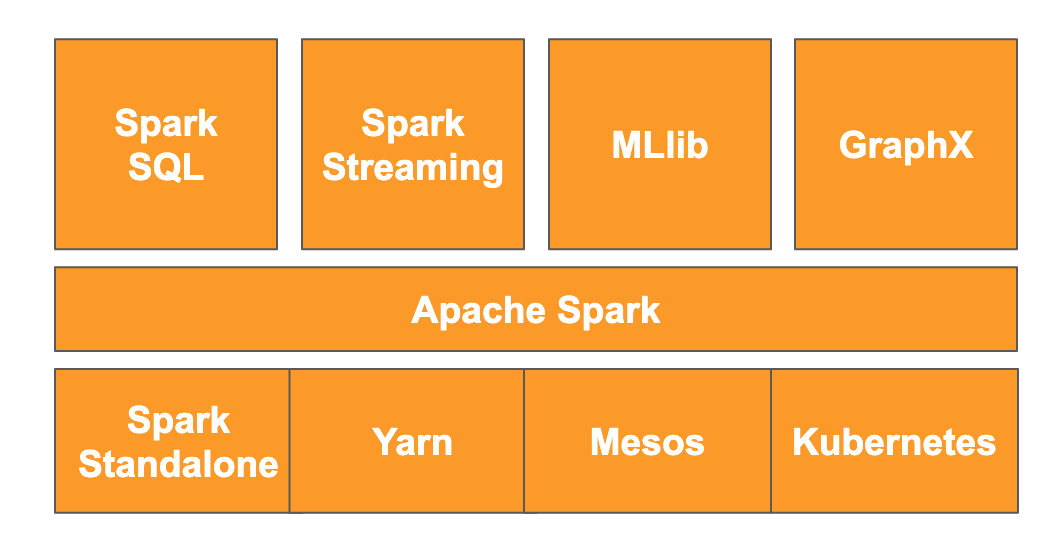
Spark peut s'exécuter seul ou utiliser un service de gestion des ressources tel que Yarn, Mesos ou Kubernetes pour le scaling. Pour cet atelier de programmation, vous utiliserez Dataproc, qui utilise Yarn.
Les données de Spark étaient initialement chargées en mémoire dans ce que l'on appelle un RDD (resilient distributed dataset, ou jeu de données distribué résilient). Le développement sur Spark a depuis inclus l'ajout de deux nouveaux types de données de style colonne : le Dataset, qui est typé, et le DataFrame, qui ne l'est pas. En termes simples, les RDD sont idéaux pour tout type de données, tandis que les ensembles de données et les DataFrames sont optimisés pour les données tabulaires. Étant donné que les ensembles de données ne sont disponibles qu'avec les API Java et Scala, nous allons utiliser l'API PySpark DataFrame pour cet atelier de programmation. Pour en savoir plus, veuillez consulter la documentation Apache Spark.
3. Cas d'utilisation
Les ingénieurs de données ont souvent besoin que les data scientists puissent accéder facilement aux données. Toutefois, les données sont souvent "sales" au départ (difficiles à utiliser pour l'analyse dans leur état actuel) et doivent être nettoyées avant de pouvoir être utiles. Par exemple, les données extraites du Web peuvent contenir des encodages étranges ou des balises HTML superflues.
Dans cet atelier, vous allez charger un ensemble de données BigQuery sous la forme de posts Reddit dans un cluster Spark hébergé sur Dataproc, extraire des informations utiles et stocker les données traitées sous forme de fichiers CSV compressés dans Google Cloud Storage.
Le responsable des data scientists de votre entreprise souhaite que ses équipes travaillent sur différents problèmes de traitement du langage naturel. Plus précisément, il souhaite analyser les données du sous-reddit "r/food". Vous allez créer un pipeline pour un vidage de données en commençant par un remplissage de janvier 2017 à août 2019.
4. Accéder à BigQuery via l'API BigQuery Storage
L'extraction de données depuis BigQuery à l'aide de la méthode d'API tabledata.list peut s'avérer chronophage et inefficace à mesure que la quantité de données augmente. Cette méthode renvoie une liste d'objets JSON et nécessite de lire séquentiellement une page à la fois pour lire un ensemble de données complet.
L'API BigQuery Storage apporte des améliorations significatives à l'accès aux données dans BigQuery en utilisant un protocole basé sur RPC. Il permet de lire et d'écrire des données en parallèle, et prend en charge différents formats de sérialisation tels qu'Apache Avro et Apache Arrow. En résumé, cela se traduit par des performances considérablement améliorées, en particulier sur les ensembles de données volumineux.
Dans cet atelier de programmation, vous utiliserez le connecteur spark-bigquery pour lire et écrire des données entre BigQuery et Spark.
5. Créer un projet
Connectez-vous à la console Google Cloud Platform sur console.cloud.google.com et créez un projet :



Vous devez ensuite activer la facturation dans la console Cloud pour pouvoir utiliser les ressources Google Cloud.
Suivre cet atelier de programmation ne devrait pas vous coûter plus d'un euro. Cependant, cela peut s'avérer plus coûteux si vous décidez d'utiliser davantage de ressources ou si vous ne les interrompez pas. La dernière section de cet atelier de programmation vous expliquera comment nettoyer votre projet.
Les nouveaux utilisateurs de Google Cloud Platform peuvent bénéficier d'un essai sans frais avec 300$de crédits.
6. Configurer votre environnement
Vous allez maintenant configurer votre environnement en procédant comme suit :
- Activer les API Compute Engine, Dataproc et BigQuery Storage
- Configurer les paramètres du projet
- Créer un cluster Dataproc
- Créer un bucket Google Cloud Storage
Activer les API et configurer votre environnement
Ouvrez Cloud Shell en cliquant sur le bouton en haut à droite de la console Cloud.
Une fois Cloud Shell chargé, exécutez les commandes suivantes pour activer les API Compute Engine, Dataproc et BigQuery Storage :
gcloud services enable compute.googleapis.com \
dataproc.googleapis.com \
bigquerystorage.googleapis.com
Définissez l'ID de projet de votre projet. Pour le trouver, accédez à la page de sélection du projet et recherchez votre projet. Il peut être différent du nom de votre projet.

Exécutez la commande suivante pour définir l'ID de votre projet :
gcloud config set project <project_id>
Définissez la région de votre projet en choisissant-en une dans la liste ici. Par exemple, us-central1.
gcloud config set dataproc/region <region>
Choisissez un nom pour votre cluster Dataproc et créez une variable d'environnement pour celui-ci.
CLUSTER_NAME=<cluster_name>
Création d'un cluster Dataproc
Créez un cluster Dataproc en exécutant la commande suivante :
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--worker-machine-type n1-standard-8 \
--num-workers 8 \
--image-version 1.5-debian \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--optional-components=ANACONDA \
--enable-component-gateway
L'exécution de cette commande prend quelques minutes. Pour décomposer la commande :
Cette commande lance la création d'un cluster Dataproc portant le nom que vous avez fourni précédemment. L'utilisation de l'API beta permet d'activer les fonctionnalités bêta de Dataproc, telles que la passerelle des composants.
gcloud beta dataproc clusters create ${CLUSTER_NAME}
Cela définira le type de machine à utiliser pour vos nœuds de calcul.
--worker-machine-type n1-standard-8
Cela définira le nombre de nœuds de calcul de votre cluster.
--num-workers 8
Cela définira la version d'image de Dataproc.
--image-version 1.5-debian
Cela permet de configurer les actions d'initialisation à utiliser sur le cluster. Ici, vous incluez l'action d'initialisation pip.
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh
Il s'agit des métadonnées à inclure dans le cluster. Ici, vous fournissez des métadonnées pour l'action d'initialisation pip.
--metadata 'PIP_PACKAGES=google-cloud-storage'
Cela définira les composants facultatifs à installer sur le cluster.
--optional-components=ANACONDA
Cela activera la passerelle des composants, qui vous permettra d'utiliser la passerelle des composants Dataproc pour afficher les interfaces utilisateur courantes telles que Zeppelin, Jupyter ou l'historique Spark.
--enable-component-gateway
Pour une présentation plus détaillée de Dataproc, consultez cet atelier de programmation.
Créer un bucket Google Cloud Storage
Vous aurez besoin d'un bucket Google Cloud Storage pour la sortie de votre job. Déterminez un nom unique pour votre bucket et exécutez la commande suivante pour en créer un. Les noms de buckets sont uniques pour tous les projets Google Cloud et tous les utilisateurs. Vous devrez peut-être réessayer plusieurs fois avec des noms différents. Un bucket est créé si vous ne recevez pas de ServiceException.
BUCKET_NAME=<bucket_name>
gsutil mb gs://${BUCKET_NAME}
7. Analyse exploratoire des données
Avant d'effectuer votre prétraitement, vous devez en savoir plus sur la nature des données que vous traitez. Pour ce faire, vous allez explorer deux méthodes d'exploration des données. Vous allez d'abord afficher des données brutes à l'aide de l'interface utilisateur Web de BigQuery, puis calculer le nombre de posts par sous-reddit à l'aide de PySpark et Dataproc.
Utiliser l'UI Web de BigQuery
Commencez par utiliser l'UI Web de BigQuery pour afficher vos données. Dans l'icône de menu de la console Cloud, faites défiler la page vers le bas et appuyez sur "BigQuery" pour ouvrir l'UI Web de BigQuery.
Ensuite, exécutez la commande suivante dans l'éditeur de requête de l'UI Web BigQuery. Cette requête renverra 10 lignes complètes de données de janvier 2017 :
select * from fh-bigquery.reddit_posts.2017_01 limit 10;
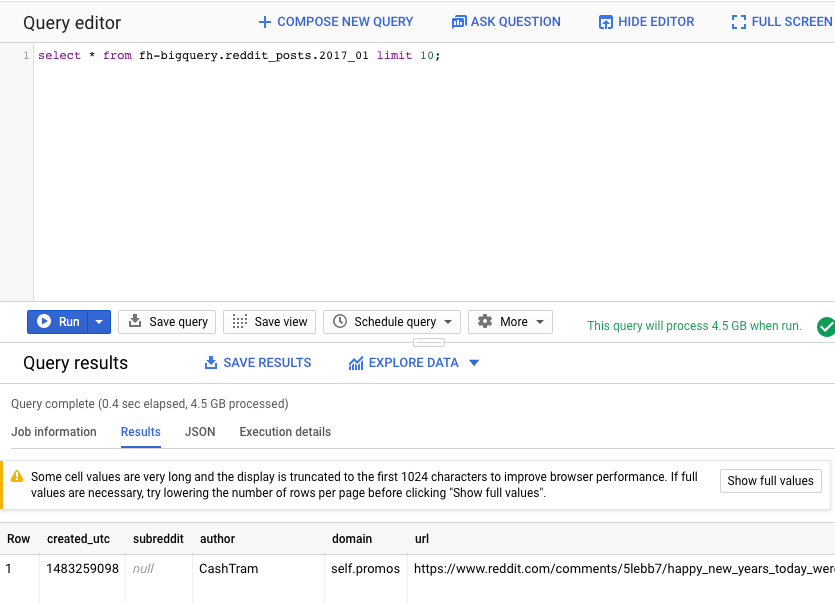
Vous pouvez faire défiler la page pour afficher toutes les colonnes disponibles, ainsi que quelques exemples. Vous verrez en particulier deux colonnes qui représentent le contenu textuel de chaque post : "title" (titre) et "selftext" (texte), cette dernière étant le corps du post. Notez également d'autres colonnes telles que "created_utc", qui correspond à l'heure UTC à laquelle un post a été créé, et "subreddit", qui correspond au subreddit dans lequel le post existe.
Exécuter un job PySpark
Exécutez les commandes suivantes dans Cloud Shell pour cloner le dépôt avec l'exemple de code et accéder au bon répertoire :
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
Vous pouvez utiliser PySpark pour déterminer le nombre de posts existants pour chaque sous-reddit. Vous pouvez ouvrir l'éditeur Cloud et lire le script cloud-dataproc/codelabs/spark-bigquery avant de l'exécuter à l'étape suivante :
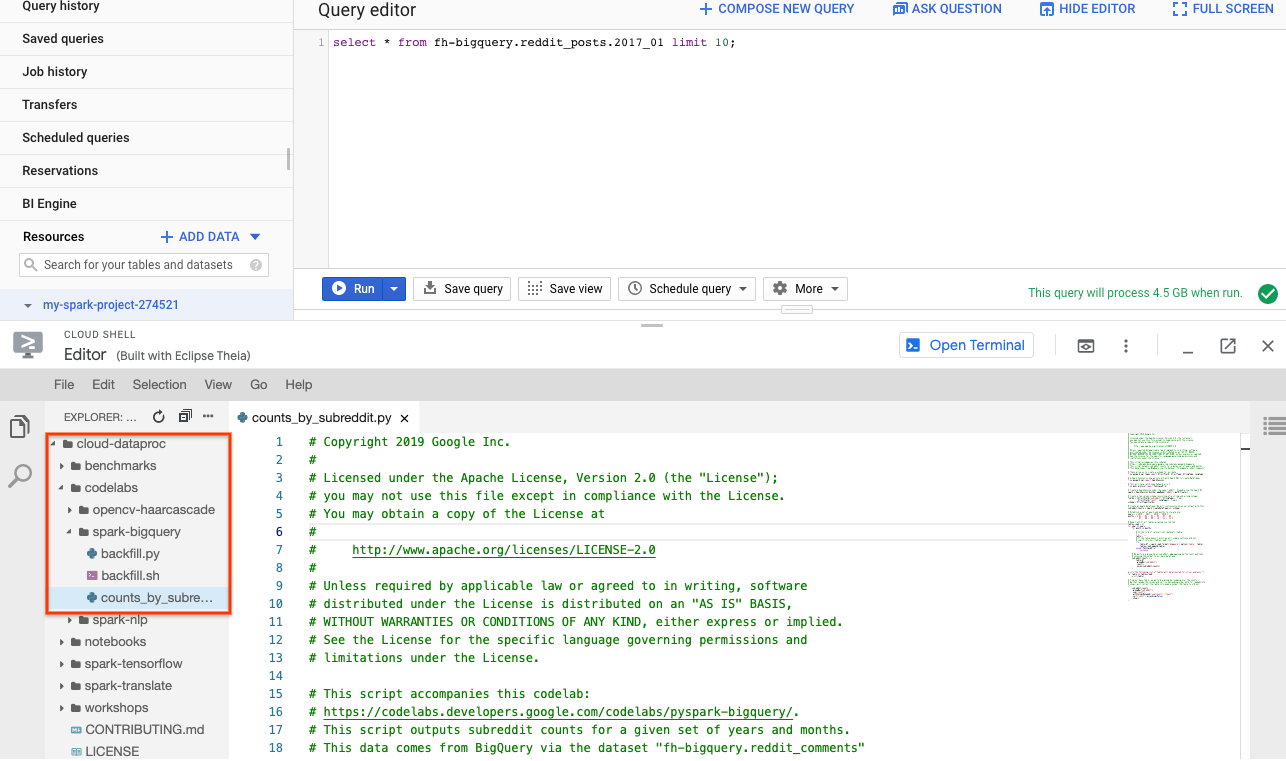
Cliquez sur le bouton "Ouvrir le terminal" dans Cloud Editor pour revenir à Cloud Shell et exécutez la commande suivante pour exécuter votre premier job PySpark :
cd ~/cloud-dataproc/codelabs/spark-bigquery
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME} \
--jars gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar \
--driver-log-levels root=FATAL \
counts_by_subreddit.py
Cette commande vous permet d'envoyer des tâches à Dataproc via l'API Jobs. Ici, vous indiquez que le type de poste est pyspark. Vous pouvez fournir le nom du cluster, les paramètres facultatifs et le nom du fichier contenant le job. Ici, vous fournissez le paramètre --jars qui vous permet d'inclure le spark-bigquery-connector à votre job. Vous pouvez également définir les niveaux de sortie des journaux à l'aide de --driver-log-levels root=FATAL, ce qui supprimera toutes les sorties de journaux, à l'exception des erreurs. Les journaux Spark ont tendance à être assez bruyants.
L'exécution de cette commande prendra quelques minutes. Le résultat final devrait se présenter comme suit :
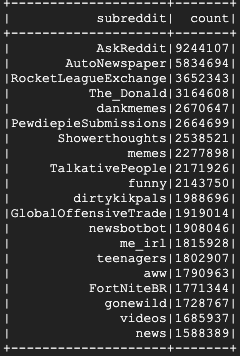
8. Explorer les interfaces utilisateur de Dataproc et Spark
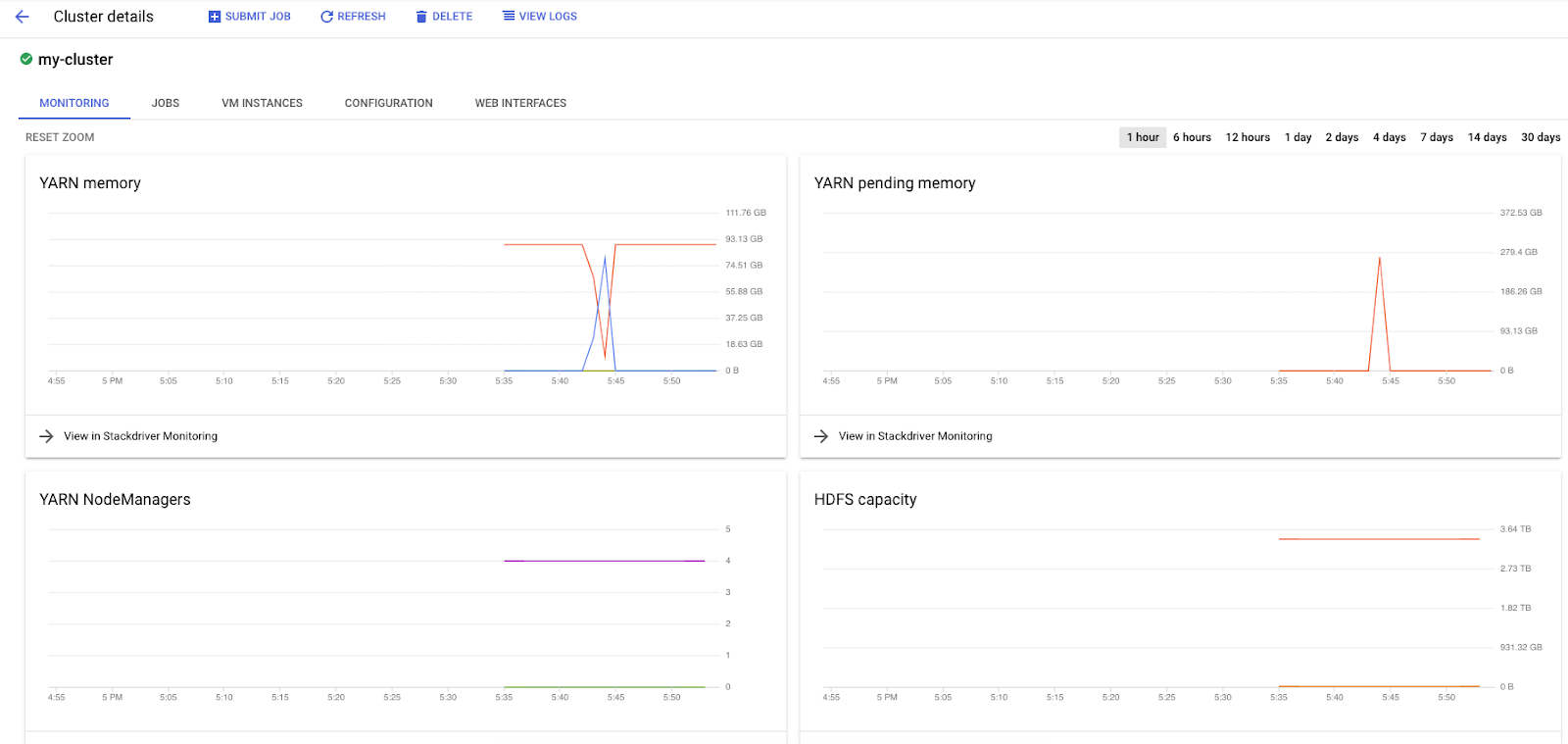
Lorsque vous exécutez des tâches Spark sur Dataproc, vous avez accès à deux interfaces utilisateur pour vérifier l'état de vos tâches / clusters. La première est l'interface utilisateur Dataproc, que vous trouverez en cliquant sur l'icône de menu et en faisant défiler la page jusqu'à Dataproc. Vous pouvez y voir la mémoire disponible actuelle, la mémoire en attente et le nombre de nœuds de calcul.
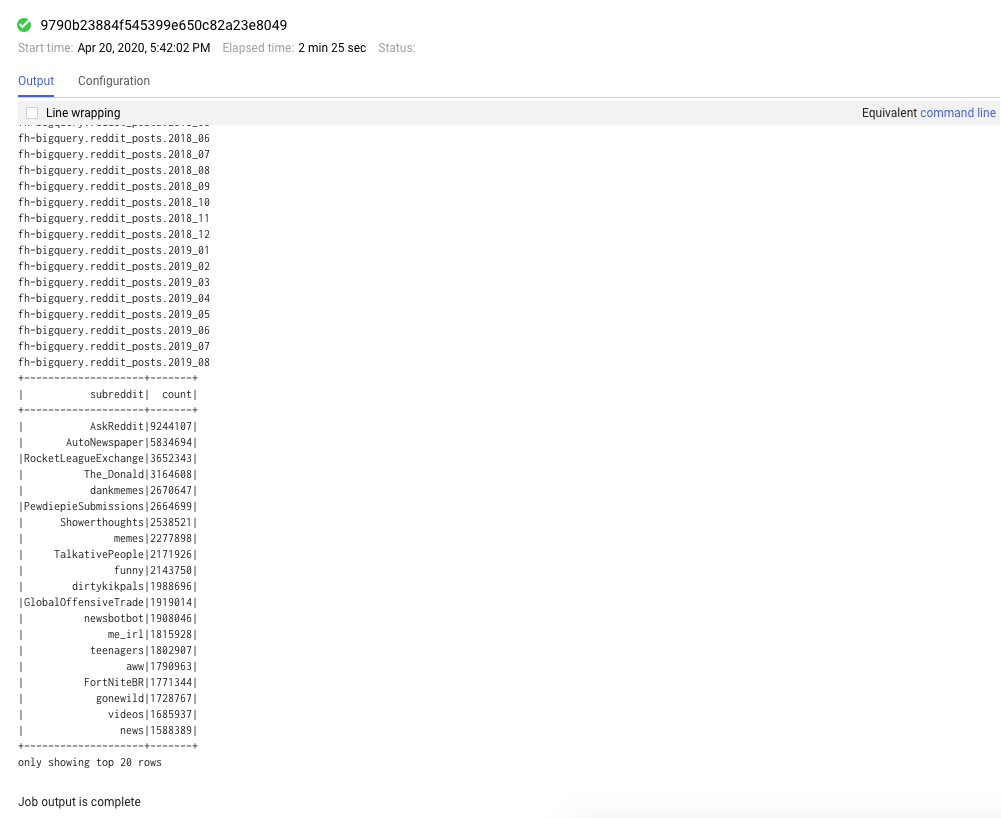
Vous pouvez également cliquer sur l'onglet "Tâches" pour afficher les tâches terminées. Pour afficher les journaux et les résultats d'un job spécifique, cliquez sur son ID. 
Vous pouvez également afficher l'UI Spark. Sur la page du job, cliquez sur la flèche "Retour", puis sur "Interfaces Web". Plusieurs options devraient s'afficher sous "Passerelle des composants". Vous pouvez en activer un grand nombre via les composants facultatifs lorsque vous configurez votre cluster. Pour cet atelier, cliquez sur "Serveur d'historique Spark".

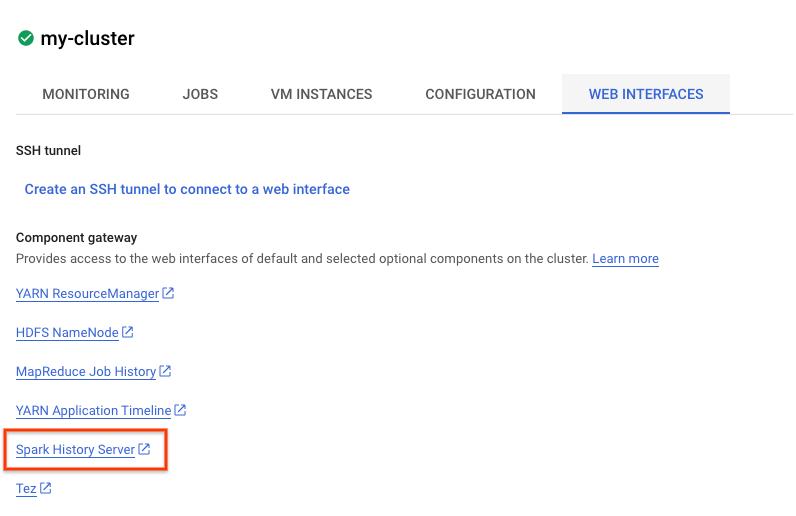
La fenêtre suivante devrait s'ouvrir :

Toutes les tâches terminées s'affichent ici. Vous pouvez cliquer sur n'importe quel application_id pour en savoir plus sur la tâche. De même, vous pouvez cliquer sur "Afficher les applications incomplètes" tout en bas de la page de destination pour afficher tous les jobs en cours d'exécution.
9. Exécuter votre job de remplissage
Vous allez maintenant exécuter un job qui charge les données en mémoire, extrait les informations nécessaires et transfère la sortie dans un bucket Google Cloud Storage. Vous extrairez le "titre", le "corps" (texte brut) et le "timestamp de création" pour chaque commentaire Reddit. Vous prendrez ensuite ces données, les convertirez au format CSV, les compresserez et les chargerez dans un bucket avec un URI gs://${BUCKET_NAME}/reddit_posts/YYYY/MM/food.csv.gz.
Vous pouvez vous référer à nouveau à l'éditeur Cloud pour lire le code de cloud-dataproc/codelabs/spark-bigquery/backfill.sh, qui est un script wrapper permettant d'exécuter le code dans cloud-dataproc/codelabs/spark-bigquery/backfill.py.
cd ~/cloud-dataproc/codelabs/spark-bigquery
bash backfill.sh ${CLUSTER_NAME} ${BUCKET_NAME}
Vous devriez rapidement voir s'afficher plusieurs messages de fin de job. Son exécution peut prendre jusqu'à 15 minutes. Vous pouvez également vérifier votre bucket de stockage pour vous assurer que les données ont bien été générées à l'aide de gsutil. Une fois toutes les tâches terminées, exécutez la commande suivante :
gsutil ls gs://${BUCKET_NAME}/reddit_posts/*/*/food.csv.gz
Vous devriez obtenir le résultat suivant :
Bravo ! Vous avez bien effectué un remplissage pour vos données de commentaires Reddit. Si vous souhaitez savoir comment créer des modèles à partir de ces données, veuillez consulter l'atelier de programmation Spark-NLP.
10. Nettoyage
Pour éviter que des frais inutiles ne soient facturés sur votre compte GCP une fois ce guide de démarrage rapide terminé :
- Supprimez le bucket Cloud Storage pour l'environnement que vous avez créé.
- Supprimez l'environnement Dataproc.
Si vous avez créé un projet spécifiquement pour cet atelier de programmation, vous pouvez également le supprimer :
- Dans la console GCP, accédez à la page Projets.
- Dans la liste des projets, sélectionnez celui que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Licence
Ce contenu est concédé sous licence Creative Commons Attribution 3.0 Generic et Apache 2.0.