
1. Ringkasan
Codelab ini akan membahas cara membuat pipeline pemrosesan data menggunakan Apache Spark dengan Dataproc di Google Cloud Platform. Biasanya dalam ilmu data dan rekayasa data, membaca data dari satu lokasi penyimpanan, menjalankan transformasi di dalamnya, dan menulisnya ke lokasi penyimpanan lain adalah kasus-kasus penggunaan yang umum terjadi. Transformasi umum mencakup mengubah konten data, menghapus informasi yang tidak perlu, dan mengubah jenis file.
Dalam codelab ini, Anda akan mempelajari Apache Spark, menjalankan pipeline contoh menggunakan Dataproc dengan PySpark (Apache Spark Python API), BigQuery, Google Cloud Storage, dan data dari Reddit.
2. Pengantar Apache Spark (Opsional)
Menurut situs tersebut, "Apache Spark adalah mesin analisis terpadu untuk pemrosesan data berskala besar." Dengan begitu, Anda dapat menganalisis dan memproses data secara paralel dan dalam memori, yang memungkinkan komputasi paralel dalam jumlah besar di beberapa mesin dan node yang berbeda. Awalnya dirilis pada tahun 2014 sebagai upgrade untuk MapReduce tradisional dan masih menjadi salah satu framework paling populer untuk melakukan komputasi berskala besar. Apache Spark ditulis dalam Scala dan selanjutnya memiliki API di Scala, Java, Python, dan R. Spark berisi banyak library seperti Spark SQL untuk melakukan kueri SQL pada data, Spark Streaming untuk streaming data, MLlib untuk machine learning, dan GraphX untuk pemrosesan grafik, yang semuanya berjalan di mesin Apache Spark.
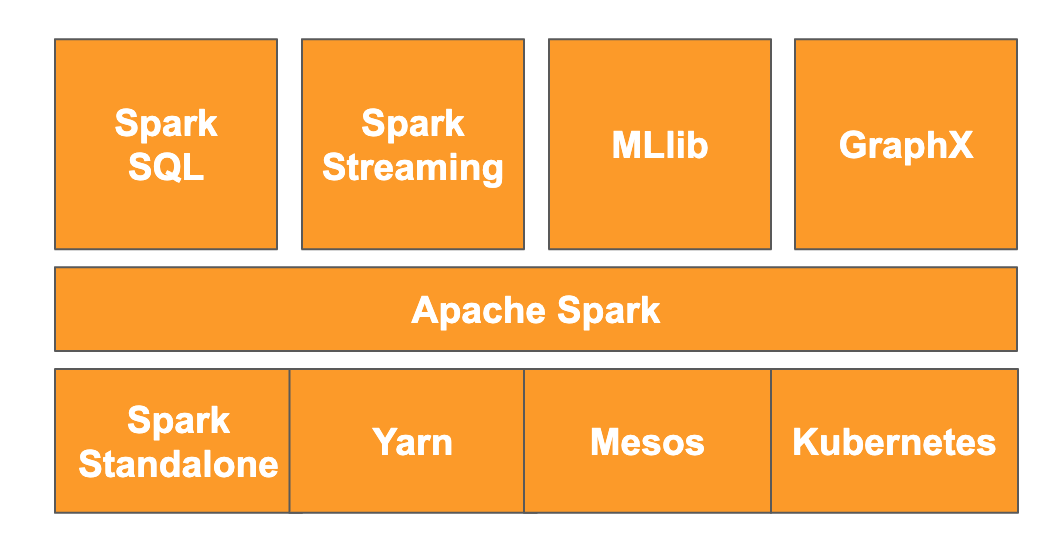
Spark dapat berjalan sendiri atau memanfaatkan layanan pengelolaan resource seperti Yarn, Mesos, atau Kubernetes untuk penskalaan. Anda akan menggunakan Dataproc untuk codelab ini, yang memanfaatkan Yarn.
Data di Spark awalnya dimuat ke dalam memori ke dalam apa yang disebut RDD, atau set data terdistribusi yang tangguh. Pengembangan di Spark sejak itu mencakup penambahan dua jenis data baru bergaya kolom: Dataset, yang diketik, dan Dataframe, yang tidak diketik. Secara umum, RDD sangat cocok untuk semua jenis data, sedangkan Dataset dan Dataframe dioptimalkan untuk data tabulasi. Karena Set Data hanya tersedia dengan Java dan Scala API, kita akan melanjutkan dengan menggunakan PySpark Dataframe API untuk codelab ini. Untuk mengetahui informasi selengkapnya, lihat dokumentasi Apache Spark.
3. Kasus Penggunaan
Data engineer sering kali memerlukan data yang mudah diakses oleh data scientist. Namun, data sering kali kotor pada awalnya (sulit digunakan untuk analisis dalam kondisi saat ini) dan perlu dibersihkan sebelum dapat digunakan secara efektif. Contohnya adalah data yang telah di-scrap dari web yang mungkin berisi encoding yang aneh atau tag HTML yang tidak relevan.
Di lab ini, Anda akan memuat sekumpulan data dari BigQuery dalam bentuk postingan Reddit ke dalam cluster Spark yang dihosting di Dataproc, mengekstrak informasi yang berguna, dan menyimpan data yang diproses sebagai file CSV yang di-zip di Google Cloud Storage.
Chief data scientist di perusahaan Anda tertarik untuk membuat timnya mengerjakan berbagai masalah pemrosesan bahasa alami. Secara khusus, mereka tertarik untuk menganalisis data di subreddit "r/food". Anda akan membuat pipeline untuk dump data yang dimulai dengan pengisian ulang dari Januari 2017 hingga Agustus 2019.
4. Mengakses BigQuery melalui BigQuery Storage API
Mengambil data dari BigQuery menggunakan metode API tabledata.list dapat terbukti memakan waktu dan tidak efisien seiring dengan peningkatan jumlah data. Metode ini menampilkan daftar objek JSON dan memerlukan pembacaan satu halaman secara berurutan untuk membaca seluruh set data.
BigQuery Storage API memberikan peningkatan signifikan pada akses data di BigQuery dengan menggunakan protokol berbasis RPC. Layanan ini mendukung pembacaan dan penulisan data secara paralel serta berbagai format serialisasi seperti Apache Avro dan Apache Arrow. Secara umum, hal ini menghasilkan peningkatan performa yang signifikan, terutama pada set data yang lebih besar.
Dalam codelab ini, Anda akan menggunakan spark-bigquery-connector untuk membaca dan menulis data antara BigQuery dan Spark.
5. Membuat Project
Login ke Konsol Google Cloud Platform di console.cloud.google.com dan buat project baru:



Selanjutnya, Anda harus mengaktifkan penagihan di Konsol Cloud untuk menggunakan resource Google Cloud.
Menjalankan operasi dalam codelab ini tidak akan menghabiskan biaya lebih dari beberapa dolar, tetapi bisa lebih jika Anda memutuskan untuk menggunakan lebih banyak resource atau jika Anda membiarkannya berjalan. Bagian terakhir codelab ini akan memandu Anda membersihkan project.
Pengguna baru Google Cloud Platform memenuhi syarat untuk mendapatkan uji coba gratis senilai$300.
6. Menyiapkan Lingkungan Anda
Sekarang Anda akan menyiapkan lingkungan dengan:
- Mengaktifkan Compute Engine, Dataproc, dan BigQuery Storage API
- Mengonfigurasi setelan project
- Membuat cluster Dataproc
- Membuat bucket Google Cloud Storage
Mengaktifkan API dan Mengonfigurasi Lingkungan Anda
Buka Cloud Shell dengan menekan tombol di pojok kanan atas Konsol Cloud Anda.
Setelah Cloud Shell dimuat, jalankan perintah berikut untuk mengaktifkan Compute Engine, Dataproc, dan BigQuery Storage API:
gcloud services enable compute.googleapis.com \
dataproc.googleapis.com \
bigquerystorage.googleapis.com
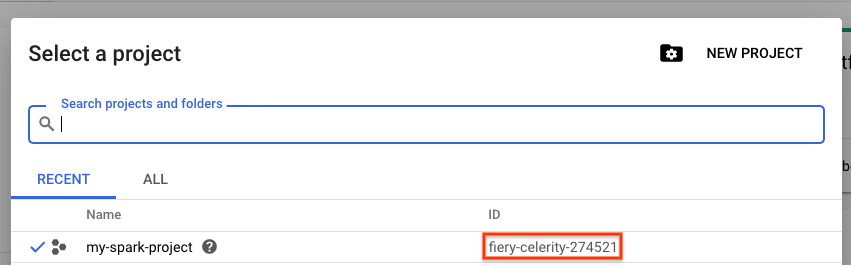
Tetapkan project id project Anda. Anda dapat menemukannya dengan membuka halaman pemilihan project dan menelusuri project Anda. Nama ini mungkin tidak sama dengan nama project Anda.

Jalankan perintah berikut untuk menetapkan project id Anda:
gcloud config set project <project_id>
Tetapkan region project Anda dengan memilih salah satu dari daftar di sini. Contohnya adalah us-central1.
gcloud config set dataproc/region <region>
Pilih nama untuk cluster Dataproc Anda dan buat variabel lingkungan untuknya.
CLUSTER_NAME=<cluster_name>
Membuat Cluster Dataproc
Buat cluster Dataproc dengan menjalankan perintah berikut:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--worker-machine-type n1-standard-8 \
--num-workers 8 \
--image-version 1.5-debian \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--optional-components=ANACONDA \
--enable-component-gateway
Perintah ini akan memerlukan waktu beberapa menit untuk diselesaikan. Untuk menguraikan perintah:
Tindakan ini akan memulai pembuatan cluster Dataproc dengan nama yang Anda berikan sebelumnya. Menggunakan beta API akan mengaktifkan fitur beta Dataproc seperti Component Gateway.
gcloud beta dataproc clusters create ${CLUSTER_NAME}
Tindakan ini akan menetapkan jenis mesin yang akan digunakan untuk pekerja Anda.
--worker-machine-type n1-standard-8
Tindakan ini akan menetapkan jumlah pekerja yang akan dimiliki cluster Anda.
--num-workers 8
Tindakan ini akan menetapkan versi image Dataproc.
--image-version 1.5-debian
Tindakan ini akan mengonfigurasi tindakan inisialisasi yang akan digunakan pada cluster. Di sini, Anda menyertakan tindakan inisialisasi pip.
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh
Ini adalah metadata yang akan disertakan pada cluster. Di sini, Anda memberikan metadata untuk tindakan inisialisasi pip.
--metadata 'PIP_PACKAGES=google-cloud-storage'
Tindakan ini akan menetapkan Komponen Opsional yang akan diinstal di cluster.
--optional-components=ANACONDA
Tindakan ini akan mengaktifkan gateway komponen yang memungkinkan Anda menggunakan Gateway Komponen Dataproc untuk melihat UI umum seperti Zeppelin, Jupyter, atau Histori Spark
--enable-component-gateway
Untuk pengantar yang lebih mendalam tentang Dataproc, lihat codelab ini.
Membuat Bucket Google Cloud Storage
Anda memerlukan bucket Google Cloud Storage untuk output tugas Anda. Tentukan nama unik untuk bucket Anda dan jalankan perintah berikut untuk membuat bucket baru. Nama bucket bersifat unik di semua project Google Cloud untuk semua pengguna, jadi Anda mungkin perlu mencoba beberapa kali dengan nama yang berbeda. Bucket berhasil dibuat jika Anda tidak menerima ServiceException.
BUCKET_NAME=<bucket_name>
gsutil mb gs://${BUCKET_NAME}
7. Analisis Data Eksploratif
Sebelum melakukan praproses, Anda harus mempelajari lebih lanjut sifat data yang Anda tangani. Untuk melakukannya, Anda akan mempelajari dua metode eksplorasi data. Pertama, Anda akan melihat beberapa data mentah menggunakan UI Web BigQuery, lalu menghitung jumlah postingan per subreddit menggunakan PySpark dan Dataproc.
Menggunakan UI Web BigQuery
Mulai dengan menggunakan UI Web BigQuery untuk melihat data Anda. Dari ikon menu di Konsol Cloud, scroll ke bawah dan tekan "BigQuery" untuk membuka UI Web BigQuery.
Selanjutnya, jalankan perintah berikut di Editor Kueri UI Web BigQuery. Tindakan ini akan menampilkan 10 baris lengkap data dari Januari 2017:
select * from fh-bigquery.reddit_posts.2017_01 limit 10;
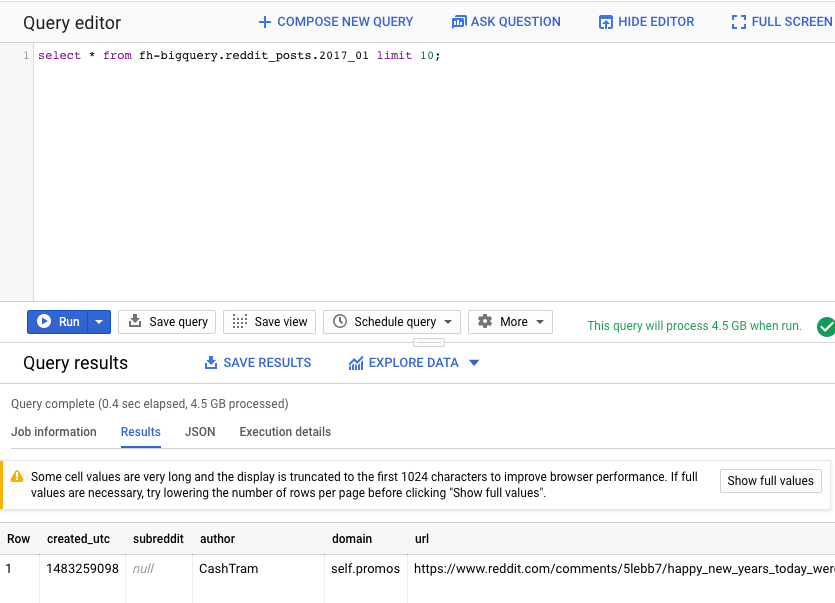
Anda dapat men-scroll halaman untuk melihat semua kolom yang tersedia serta beberapa contoh. Secara khusus, Anda akan melihat dua kolom yang merepresentasikan konten tekstual setiap postingan: "title" dan "selftext", yang terakhir adalah isi postingan. Perhatikan juga kolom lain seperti "created_utc" yang merupakan waktu utc saat postingan dibuat dan "subreddit" yang merupakan subreddit tempat postingan berada.
Menjalankan Tugas PySpark
Jalankan perintah berikut di Cloud Shell untuk meng-clone repositori dengan kode contoh dan cd ke direktori yang benar:
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
Anda dapat menggunakan PySpark untuk menentukan jumlah postingan yang ada untuk setiap subreddit. Anda dapat membuka Cloud Editor dan membaca skrip cloud-dataproc/codelabs/spark-bigquery sebelum mengeksekusinya di langkah berikutnya:
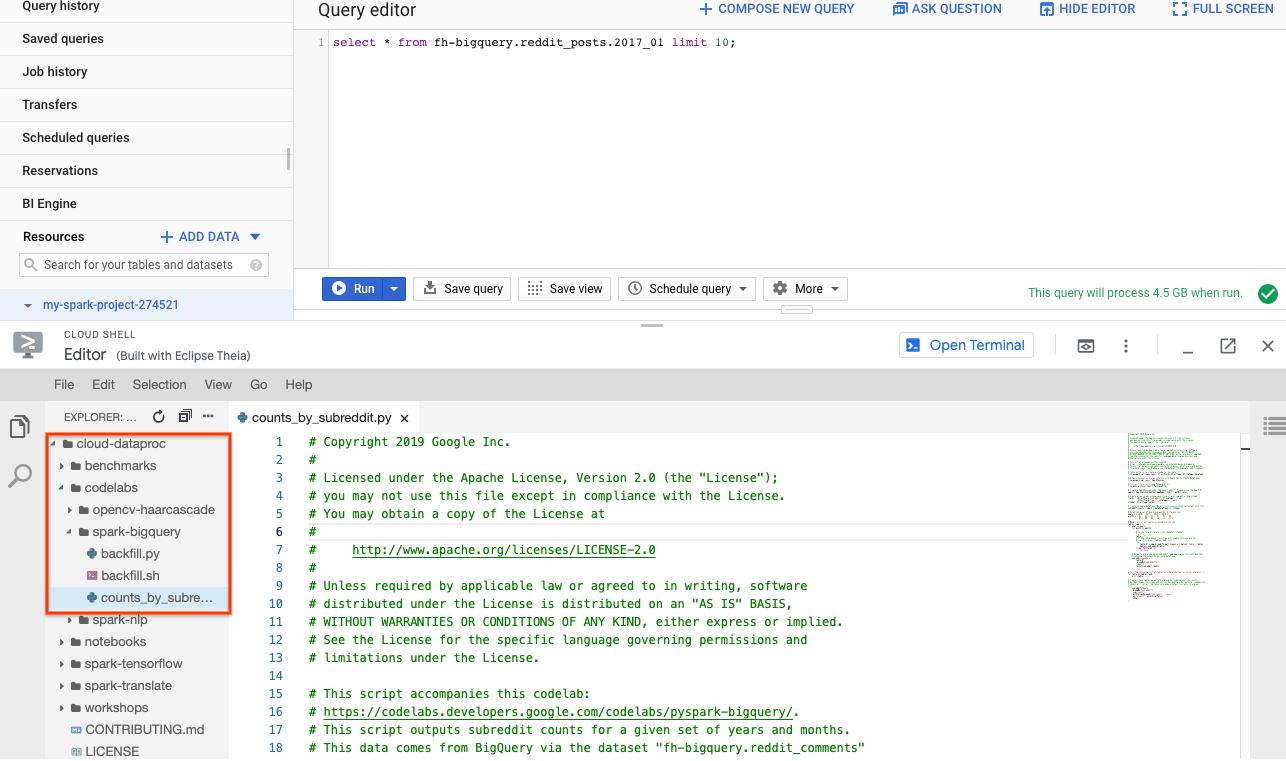
Klik tombol "Open Terminal" di Cloud Editor untuk beralih kembali ke Cloud Shell dan jalankan perintah berikut untuk menjalankan tugas PySpark pertama Anda:
cd ~/cloud-dataproc/codelabs/spark-bigquery
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME} \
--jars gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar \
--driver-log-levels root=FATAL \
counts_by_subreddit.py
Perintah ini memungkinkan Anda mengirimkan tugas ke Dataproc melalui Jobs API. Di sini Anda menunjukkan jenis pekerjaan sebagai pyspark. Anda dapat memberikan nama cluster, parameter opsional , dan nama file yang berisi tugas. Di sini, Anda memberikan parameter --jars yang memungkinkan Anda menyertakan spark-bigquery-connector dengan tugas Anda. Anda juga dapat menyetel level output log menggunakan --driver-log-levels root=FATAL yang akan menekan semua output log kecuali error. Log Spark cenderung cukup berisik.
Proses ini akan memerlukan waktu beberapa menit dan output akhir Anda akan terlihat seperti ini:
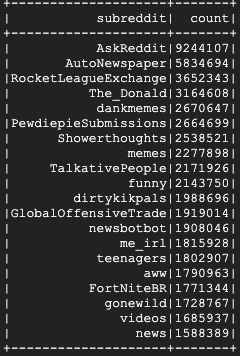
8. Mempelajari UI Dataproc dan Spark
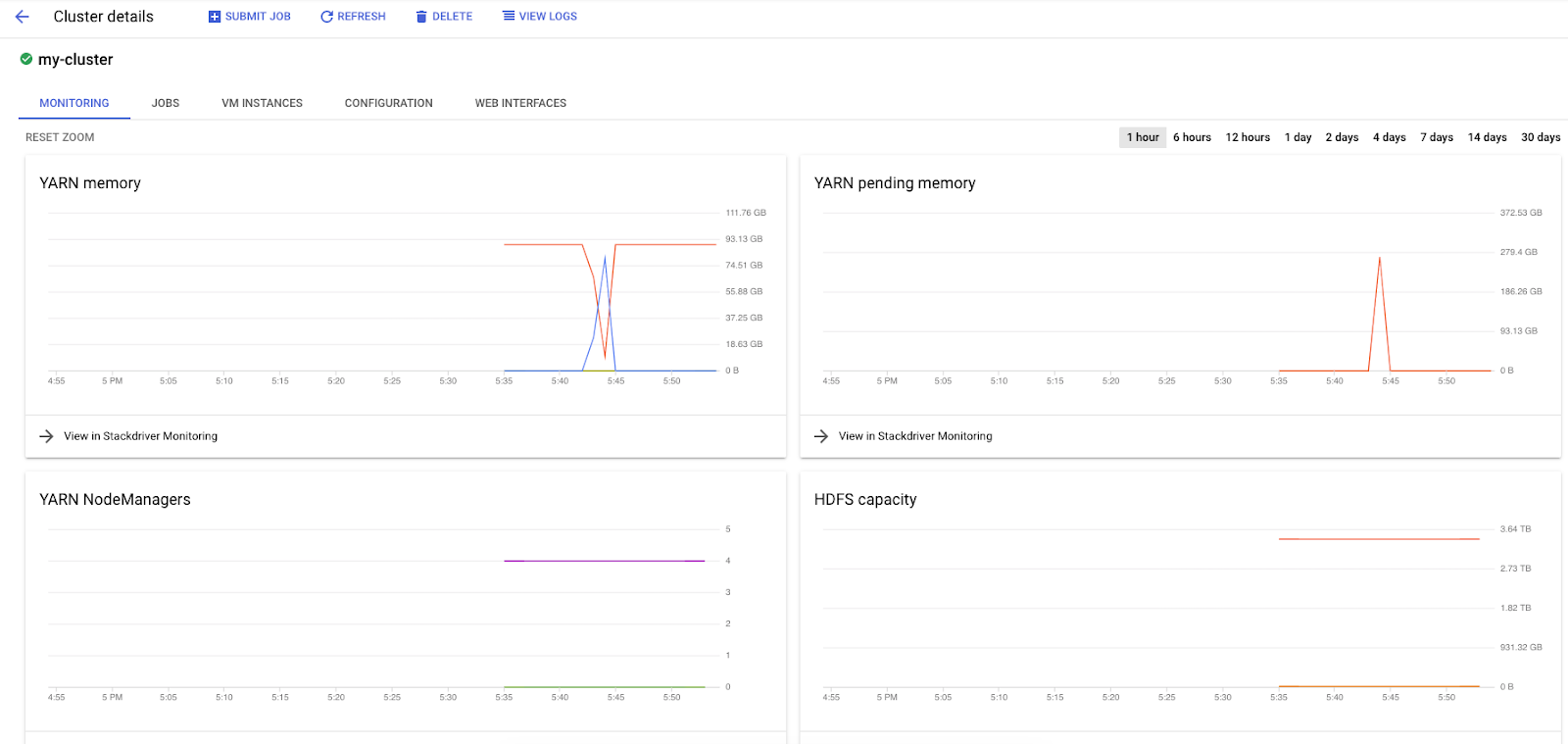
Saat menjalankan tugas Spark di Dataproc, Anda memiliki akses ke dua UI untuk memeriksa status tugas / cluster Anda. Yang pertama adalah UI Dataproc, yang dapat Anda temukan dengan mengklik ikon menu dan men-scroll ke bawah ke Dataproc. Di sini, Anda dapat melihat memori yang tersedia saat ini serta memori yang tertunda dan jumlah pekerja.
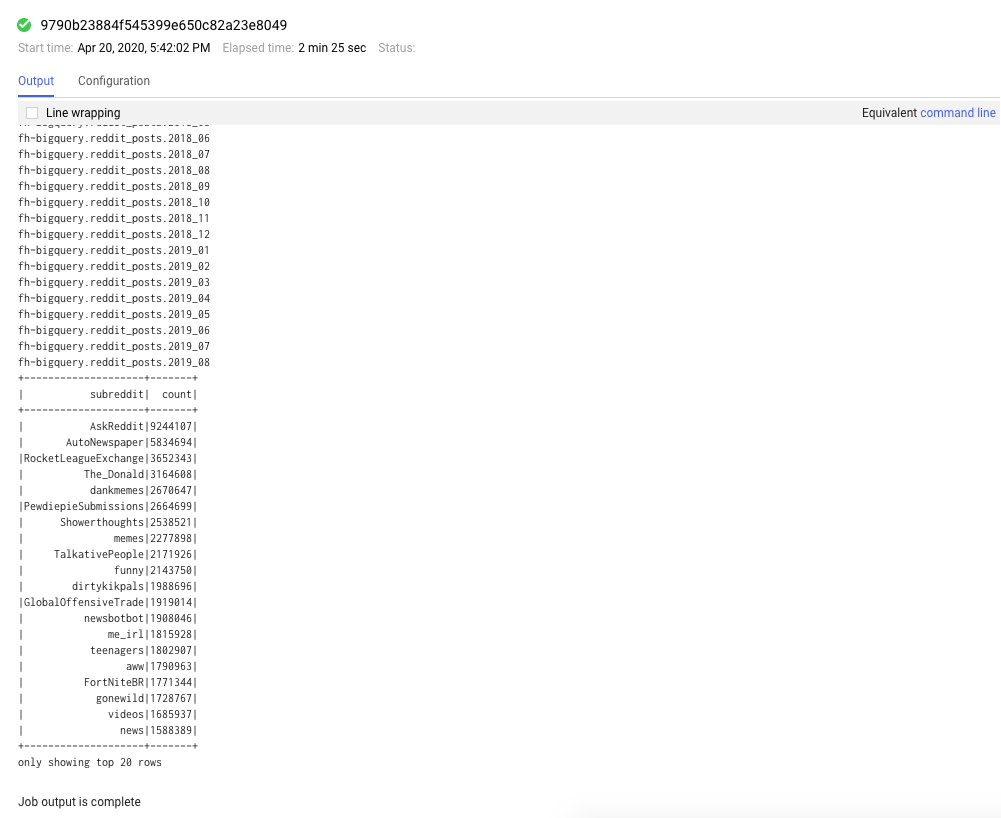
Anda juga dapat mengklik tab tugas untuk melihat tugas yang telah diselesaikan. Anda dapat melihat detail tugas seperti log dan output tugas tersebut dengan mengklik ID Tugas untuk tugas tertentu. 
Anda juga dapat melihat UI Spark. Dari halaman tugas, klik panah kembali, lalu klik Antarmuka Web. Anda akan melihat beberapa opsi di bagian gateway komponen. Banyak di antaranya dapat diaktifkan melalui Komponen Opsional saat menyiapkan cluster. Untuk lab ini, klik "Spark History Server.

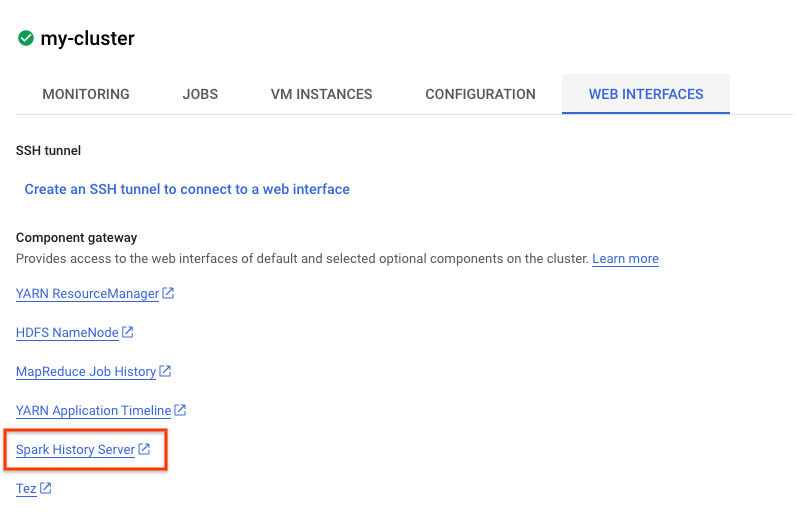
Tindakan ini akan membuka jendela berikut:

Semua tugas yang selesai akan muncul di sini, dan Anda dapat mengklik application_id untuk mempelajari informasi selengkapnya tentang tugas tersebut. Demikian pula, Anda dapat mengklik "Tampilkan Aplikasi yang Belum Selesai" di bagian paling bawah halaman landing untuk melihat semua tugas yang sedang berjalan.
9. Menjalankan Tugas Pengisian Ulang
Sekarang Anda akan menjalankan tugas yang memuat data ke dalam memori, mengekstrak informasi yang diperlukan, dan membuang output ke bucket Google Cloud Storage. Anda akan mengekstrak "title", "body" (teks mentah), dan "timestamp created" untuk setiap komentar reddit. Kemudian, Anda akan mengambil data ini, mengonversinya menjadi CSV, mengompresinya, dan memuatnya ke dalam bucket dengan URI gs://${BUCKET_NAME}/reddit_posts/YYYY/MM/food.csv.gz.
Anda dapat merujuk ke Cloud Editor lagi untuk membaca kode untuk cloud-dataproc/codelabs/spark-bigquery/backfill.sh yang merupakan skrip wrapper untuk menjalankan kode di cloud-dataproc/codelabs/spark-bigquery/backfill.py.
cd ~/cloud-dataproc/codelabs/spark-bigquery
bash backfill.sh ${CLUSTER_NAME} ${BUCKET_NAME}
Anda akan segera melihat banyak pesan penyelesaian tugas. Tugas ini mungkin memerlukan waktu hingga 15 menit untuk diselesaikan. Anda juga dapat memeriksa ulang bucket penyimpanan untuk memverifikasi keberhasilan output data menggunakan gsutil. Setelah semua tugas selesai, jalankan perintah berikut:
gsutil ls gs://${BUCKET_NAME}/reddit_posts/*/*/food.csv.gz
Anda akan melihat output berikut:
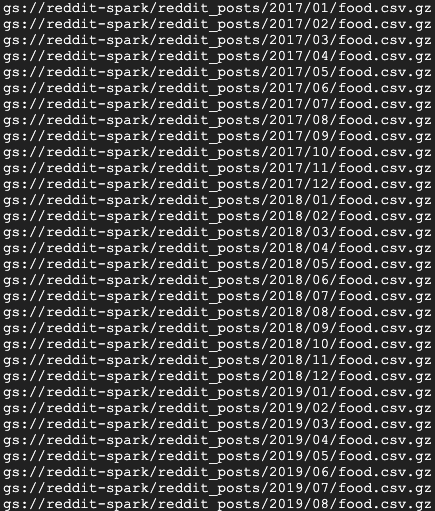
Selamat, Anda telah berhasil menyelesaikan pengisian ulang untuk data komentar reddit Anda. Jika Anda tertarik dengan cara membuat model berdasarkan data ini, lanjutkan ke codelab Spark-NLP.
10. Pembersihan
Agar tidak menimbulkan biaya yang tidak perlu pada akun GCP Anda setelah menyelesaikan panduan memulai ini:
- Hapus bucket Cloud Storage untuk lingkungan dan yang Anda buat
- Hapus lingkungan Dataproc.
Jika membuat project hanya untuk codelab ini, Anda juga dapat menghapus project tersebut jika mau:
- Di Konsol GCP, buka halaman Projects.
- Dalam daftar project, pilih project yang ingin Anda hapus, lalu klik Hapus.
- Di kotak, ketik project ID, lalu klik Shut down untuk menghapus project.
Lisensi
Karya ini dilisensikan berdasarkan Lisensi Umum Creative Commons Attribution 3.0, dan lisensi Apache 2.0.