
1. Descripción general
En este codelab, se explicará cómo crear una canalización de procesamiento de datos con Apache Spark y Dataproc en Google Cloud Platform. Es un caso de uso común en la ciencia y la ingeniería de datos para leerlos desde una ubicación de almacenamiento, realizar transformaciones y escribirlos en otra ubicación de almacenamiento. Las transformaciones comunes incluyen cambiar el contenido de los datos, quitar la información innecesaria y cambiar los tipos de archivos.
En este codelab, aprenderás sobre Apache Spark, ejecutarás una canalización de muestra con Dataproc y PySpark (la API de Python de Apache Spark), BigQuery, Google Cloud Storage y datos de Reddit.
2. Introducción a Apache Spark (opcional)
Según el sitio web, "Apache Spark es un motor de analítica unificado para el procesamiento de datos a gran escala". Te permite analizar y procesar datos en paralelo y en la memoria, lo que permite realizar cálculos paralelos masivos en varias máquinas y nodos diferentes. Se lanzó originalmente en 2014 como una actualización de MapReduce tradicional y sigue siendo uno de los frameworks más populares para realizar cálculos a gran escala. Apache Spark está escrito en Scala y, posteriormente, tiene APIs en Scala, Java, Python y R. Contiene una gran cantidad de bibliotecas, como Spark SQL para realizar consultas SQL en los datos, Spark Streaming para transmitir datos, MLlib para aprendizaje automático y GraphX para procesamiento de gráficos, que se ejecutan en el motor de Apache Spark.
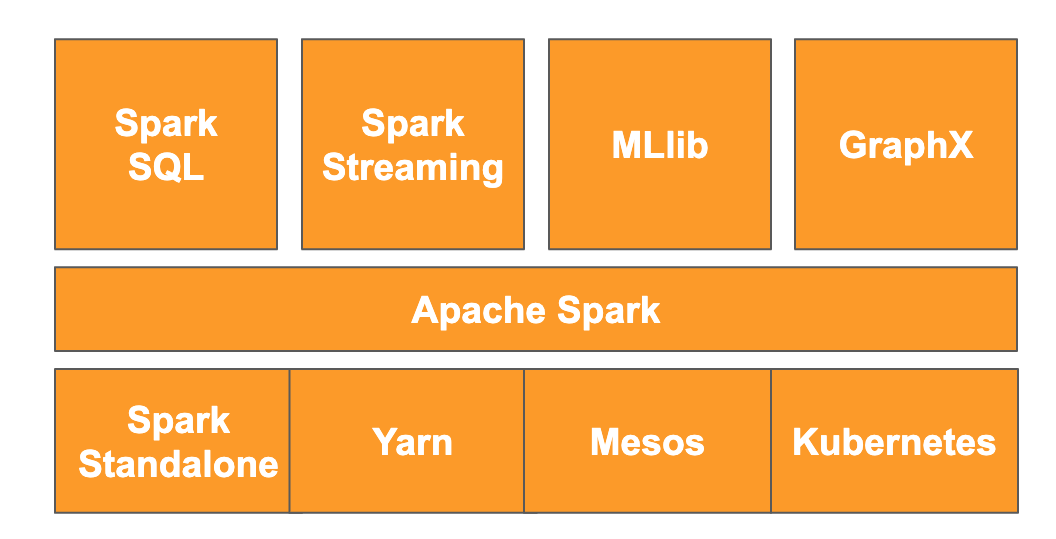
Spark puede ejecutarse por sí solo o puede aprovechar un servicio de administración de recursos como Yarn, Mesos o Kubernetes para el escalamiento. Usarás Dataproc para este codelab, que utiliza Yarn.
Los datos de Spark se cargaron originalmente en la memoria en lo que se denomina RDD o conjunto de datos resiliente y distribuido. Desde entonces, el desarrollo en Spark incluyó la adición de dos tipos de datos nuevos de estilo columnar: el conjunto de datos, que está escrito, y el marco de datos, que no está escrito. En términos generales, los RDD son excelentes para cualquier tipo de datos, mientras que los conjuntos de datos y los marcos de datos están optimizados para datos tabulares. Como los conjuntos de datos solo están disponibles con las APIs de Java y Scala, continuaremos usando la API de marco de datos de PySpark para este codelab. Para obtener más información, consulta la documentación de Apache Spark.
3. Caso de uso
Los ingenieros de datos a menudo necesitan que los datos sean de fácil acceso para los científicos de datos. Sin embargo, los datos suelen estar sucios inicialmente (difíciles de usar para el análisis en su estado actual) y deben limpiarse antes de que puedan ser de mucha utilidad. Un ejemplo de esto son los datos que se extrajeron de la Web, que pueden contener codificaciones extrañas o etiquetas HTML externas.
En este lab, cargarás un conjunto de datos de BigQuery en forma de publicaciones de Reddit en un clúster de Spark alojado en Dataproc, extraerás información útil y almacenarás los datos procesados como archivos CSV comprimidos en Google Cloud Storage.
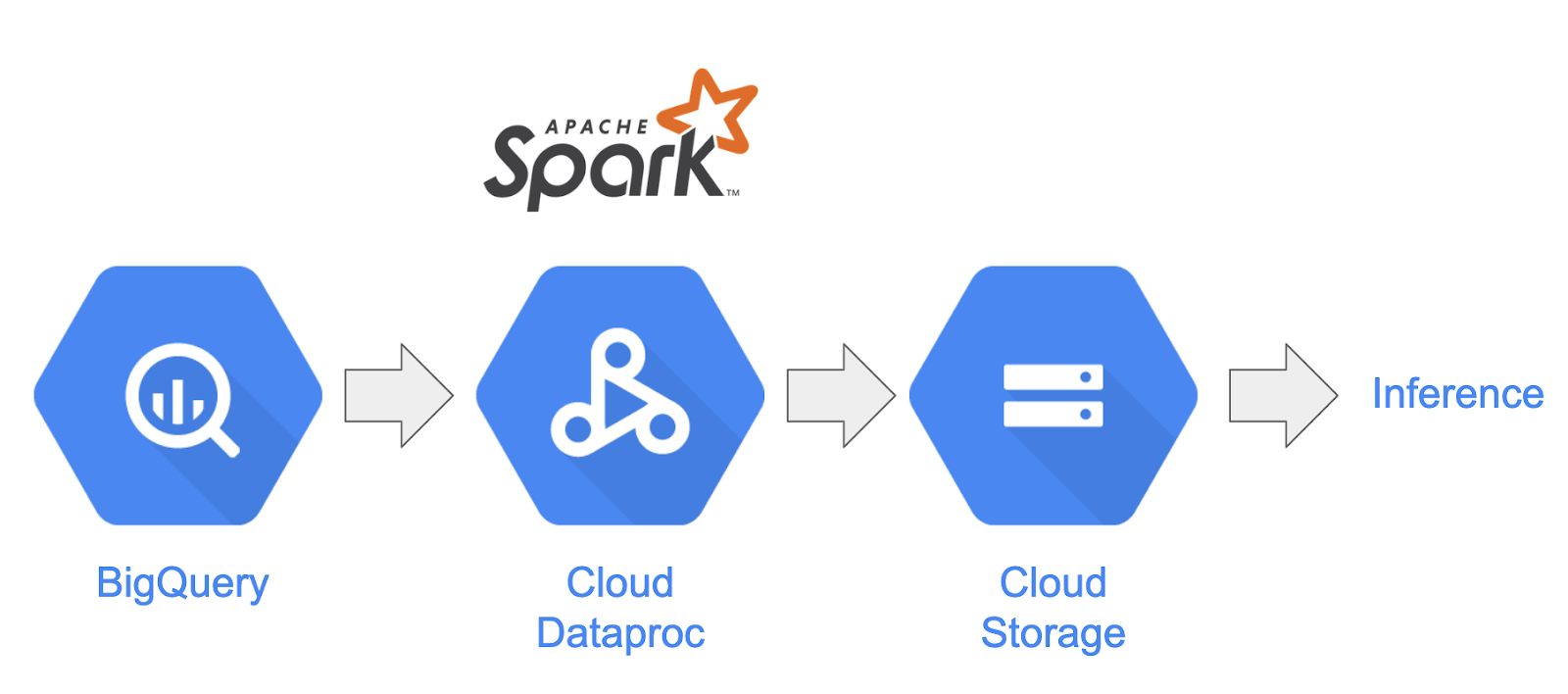
El científico de datos principal de tu empresa está interesado en que sus equipos trabajen en diferentes problemas de procesamiento del lenguaje natural. En particular, les interesa analizar los datos en el subreddit "r/food". Crearás una canalización para un volcado de datos que comience con un relleno de enero de 2017 a agosto de 2019.
4. Accede a BigQuery a través de la API de BigQuery Storage
Extraer datos de BigQuery con el método de API tabledata.list puede llevar mucho tiempo y no ser eficiente a medida que se escala la cantidad de datos. Este método muestra una lista de objetos JSON y requiere leer una página a la vez de forma secuencial para leer un conjunto de datos completo.
La API de BigQuery Storage aporta mejoras significativas al acceso a los datos en BigQuery mediante un protocolo basado en RPC. Admite lecturas y escrituras de datos en paralelo, así como diferentes formatos de serialización, como Apache Avro y Apache Arrow. En un nivel superior, esto se traduce en un rendimiento significativamente mejorado, en especial en conjuntos de datos más grandes.
En este codelab, usarás el spark-bigquery-connector para leer y escribir datos entre BigQuery y Spark.
5. Crea un proyecto
Accede a la consola de Google Cloud Platform en console.cloud.google.com y crea un proyecto nuevo:



A continuación, deberás habilitar la facturación en Cloud Console para usar los recursos de Google Cloud.
Ejecutar este codelab debería costar solo unos pocos dólares, pero su costo podría aumentar si decides usar más recursos o si los dejas en ejecución. En la última sección de este codelab, se te guiará para limpiar tu proyecto.
Los usuarios nuevos de Google Cloud Platform son aptos para obtener una prueba gratuita de 300 USD.
6. Configura el entorno
Ahora, configurarás tu entorno de la siguiente manera:
- Habilitar las APIs de Compute Engine, Dataproc y BigQuery Storage
- Definir la configuración del proyecto
- Crear un clúster de Dataproc
- Crear un bucket de Google Cloud Storage
Habilita las APIs y configura tu entorno
Para abrir Cloud Shell, presiona el botón en la esquina superior derecha de Cloud Console.
Después de que se cargue Cloud Shell, ejecuta los siguientes comandos para habilitar las APIs de Compute Engine, Dataproc y BigQuery Storage:
gcloud services enable compute.googleapis.com \
dataproc.googleapis.com \
bigquerystorage.googleapis.com
Establece el ID del proyecto de tu proyecto. Para encontrarlo, ve a la página de selección del proyecto y busca tu proyecto. Es posible que no sea el mismo que el nombre del proyecto.

Ejecuta el siguiente comando para establecer el ID del proyecto:
gcloud config set project <project_id>
Para establecer la región de tu proyecto, elige una de la lista aquí. Un ejemplo podría ser us-central1.
gcloud config set dataproc/region <region>
Elige un nombre para tu clúster de Dataproc y crea una variable de entorno para él.
CLUSTER_NAME=<cluster_name>
Crea un clúster de Dataproc
Para crear un clúster de Dataproc, ejecuta el siguiente comando:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--worker-machine-type n1-standard-8 \
--num-workers 8 \
--image-version 1.5-debian \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--optional-components=ANACONDA \
--enable-component-gateway
Este comando tardará un par de minutos en finalizar. Para desglosar el comando, haz lo siguiente:
Esto iniciará la creación de un clúster de Dataproc con el nombre que proporcionaste antes. El uso de la API de beta habilitará las funciones beta de Dataproc, como la puerta de enlace de componentes.
gcloud beta dataproc clusters create ${CLUSTER_NAME}
Esto establecerá el tipo de máquina que se usará para tus trabajadores.
--worker-machine-type n1-standard-8
Esto establecerá la cantidad de trabajadores que tendrá tu clúster.
--num-workers 8
Esto establecerá la versión de imagen de Dataproc.
--image-version 1.5-debian
Esto configurará las acciones de inicialización que se usarán en el clúster. Aquí, se incluye la acción de inicialización de pip.
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh
Estos son los metadatos que se incluirán en el clúster. Aquí, se proporcionan metadatos para la acción de inicialización de pip.
--metadata 'PIP_PACKAGES=google-cloud-storage'
Esto establecerá los componentes opcionales que se instalarán en el clúster.
--optional-components=ANACONDA
Esto habilitará la puerta de enlace de componentes, que te permite usar la puerta de enlace de componentes de Dataproc para ver las IU comunes, como Zeppelin, Jupyter o el historial de Spark.
--enable-component-gateway
Para obtener una introducción más detallada a Dataproc, consulta este codelab.
Crea un bucket de Google Cloud Storage
Necesitarás un bucket de Google Cloud Storage para el resultado de tu trabajo. Determina un nombre único para tu bucket y ejecuta el siguiente comando para crear un bucket nuevo. Los nombres de los buckets son únicos en todos los proyectos de Google Cloud para todos los usuarios, por lo que es posible que debas intentarlo varias veces con nombres diferentes. Un bucket se crea correctamente si no recibes una ServiceException.
BUCKET_NAME=<bucket_name>
gsutil mb gs://${BUCKET_NAME}
7. Análisis de datos exploratorio
Antes de realizar el procesamiento previo, debes obtener más información sobre la naturaleza de los datos con los que trabajas. Para ello, explorarás dos métodos de exploración de datos. Primero, verás algunos datos sin procesar con la IU web de BigQuery y, luego, calcularás la cantidad de publicaciones por subreddit con PySpark y Dataproc.
Usa la IU web de BigQuery
Comienza usando la IU web de BigQuery para ver tus datos. En el ícono de menú de Cloud Console, desplázate hacia abajo y presiona "BigQuery" para abrir la IU web de BigQuery.
A continuación, ejecuta el siguiente comando en el editor de consultas de la IU web de BigQuery. Esto mostrará 10 filas completas de los datos de enero de 2017:
select * from fh-bigquery.reddit_posts.2017_01 limit 10;
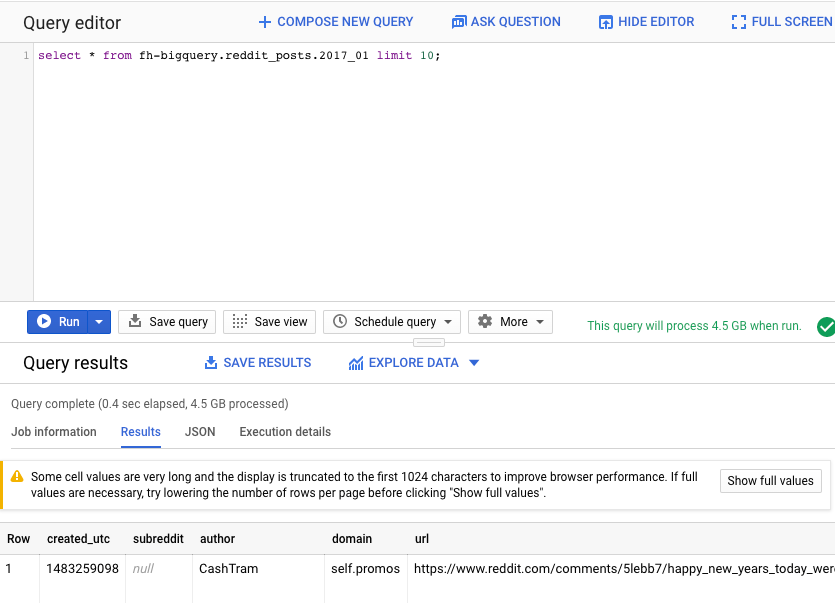
Puedes desplazarte por la página para ver todas las columnas disponibles, así como algunos ejemplos. En particular, verás dos columnas que representan el contenido textual de cada publicación: "title" y "selftext", esta última es el cuerpo de la publicación. También observa otras columnas, como "created_utc", que es la hora UTC en la que se realizó una publicación, y "subreddit", que es el subreddit en el que existe la publicación.
Ejecuta un trabajo de PySpark
Ejecuta los siguientes comandos en Cloud Shell para clonar el repositorio con el código de muestra y cambiar al directorio correcto:
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
Puedes usar PySpark para determinar un recuento de cuántas publicaciones existen para cada subreddit. Puedes abrir el editor de Cloud y leer la secuencia de comandos cloud-dataproc/codelabs/spark-bigquery antes de ejecutarla en el siguiente paso:
Haz clic en el botón "Abrir terminal" en el editor de Cloud para volver a Cloud Shell y ejecuta el siguiente comando para ejecutar tu primer trabajo de PySpark:
cd ~/cloud-dataproc/codelabs/spark-bigquery
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME} \
--jars gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar \
--driver-log-levels root=FATAL \
counts_by_subreddit.py
Este comando te permite enviar trabajos a Dataproc a través de la API de Jobs. Aquí, se indica el tipo de trabajo como pyspark. Puedes proporcionar el nombre del clúster, parámetros opcionales y el nombre del archivo que contiene el trabajo. Aquí, se proporciona el parámetro --jars, que te permite incluir el spark-bigquery-connector con tu trabajo. También puedes establecer los niveles de salida de registro con --driver-log-levels root=FATAL, que suprimirá toda la salida de registro, excepto los errores. Los registros de Spark suelen ser bastante ruidosos.
Esto debería tardar unos minutos en ejecutarse y el resultado final debería verse de la siguiente manera:
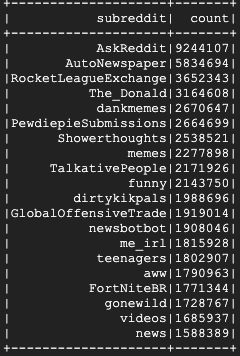
8. Explora las IU de Dataproc y Spark
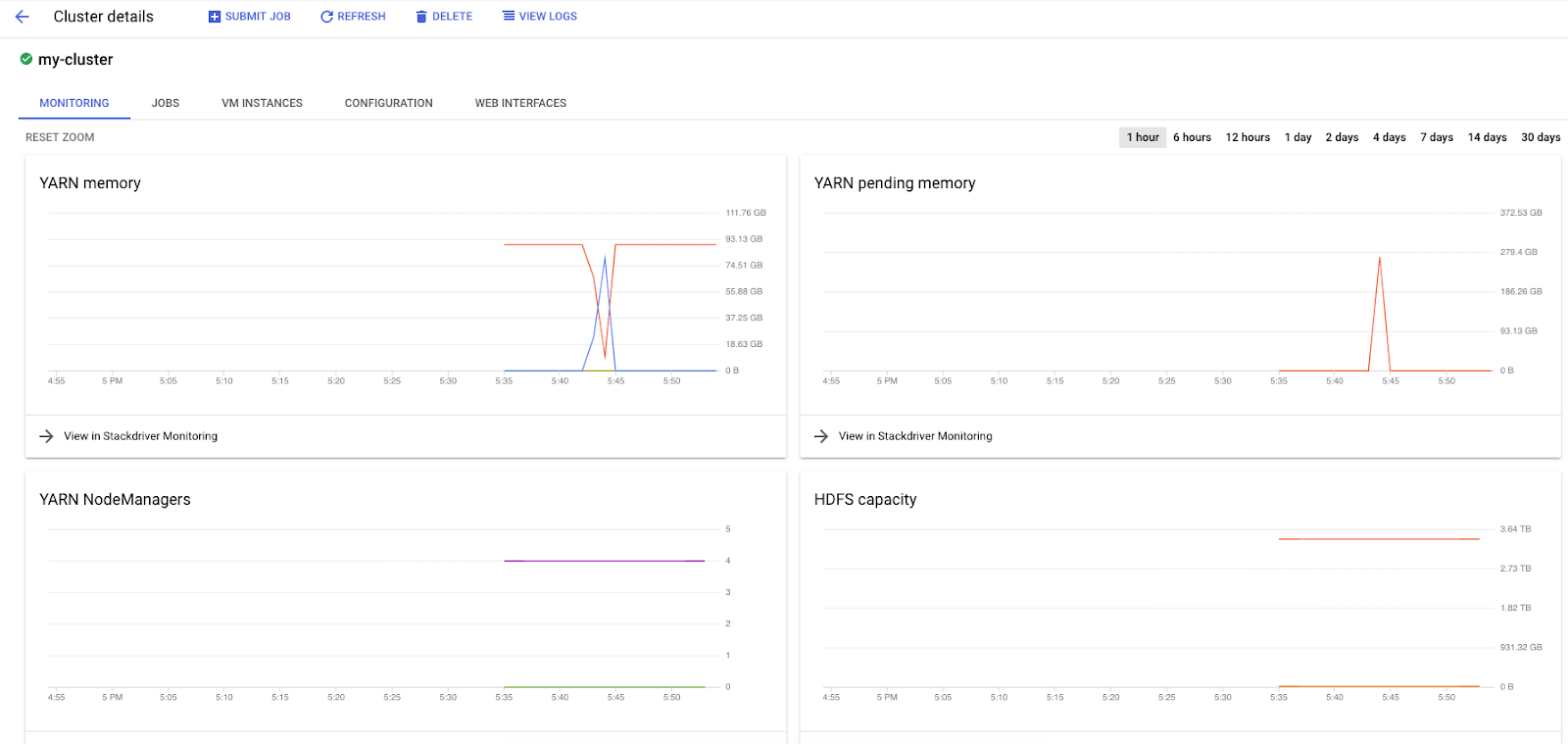
Cuando ejecutas trabajos de Spark en Dataproc, tienes acceso a dos IU para verificar el estado de tus trabajos o clústeres. La primera es la IU de Dataproc, que puedes encontrar haciendo clic en el ícono de menú y desplazándote hacia abajo hasta Dataproc. Aquí, puedes ver la memoria actual disponible, así como la memoria pendiente y la cantidad de trabajadores.
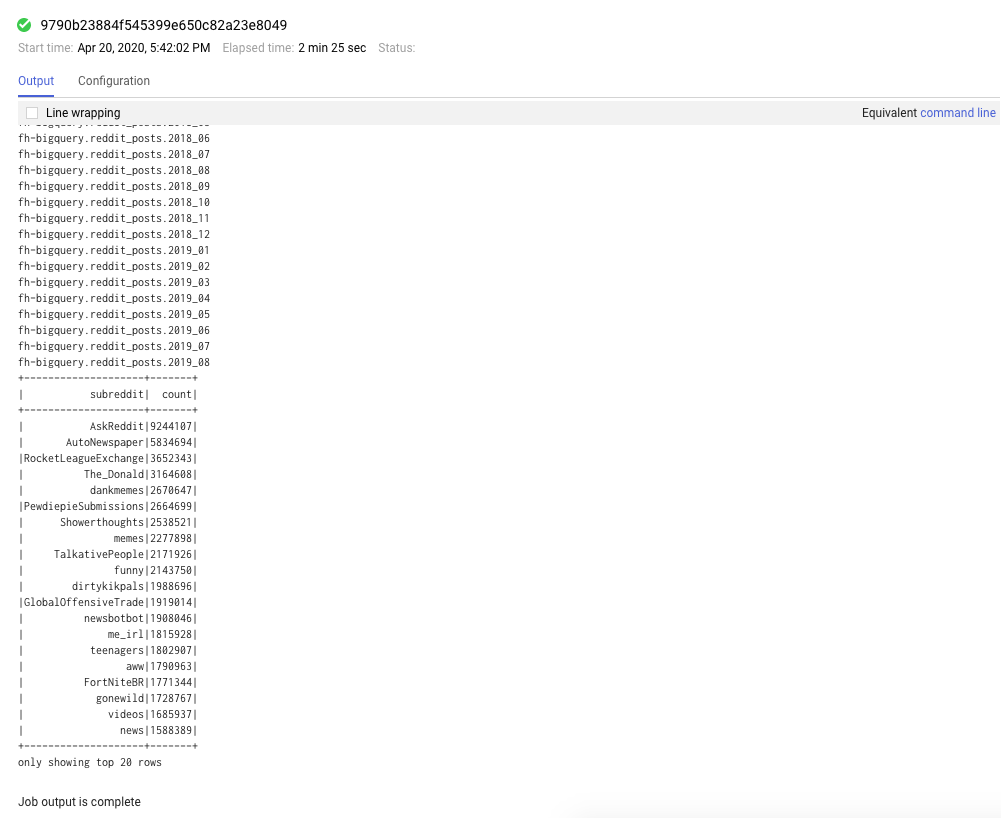
También puedes hacer clic en la pestaña Trabajos para ver los trabajos completados. Para ver los detalles del trabajo, como los registros y el resultado de esos trabajos, haz clic en el ID del trabajo de un trabajo en particular. 
También puedes ver la IU de Spark. En la página del trabajo, haz clic en la flecha hacia atrás y, luego, en Interfaces web. Deberías ver varias opciones en la puerta de enlace de componentes. Muchas de ellas se pueden habilitar a través de componentes opcionales cuando configuras tu clúster. Para este lab, haz clic en el servidor de historial de Spark.

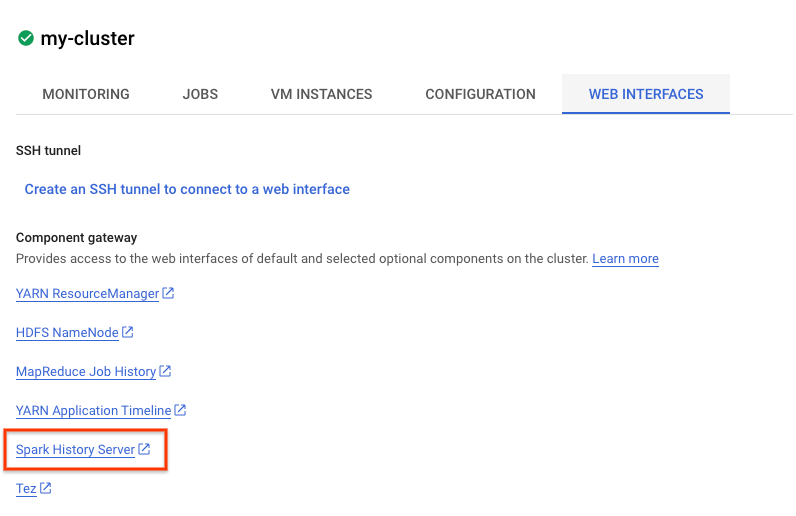
Se abrirá la siguiente ventana:

Aquí aparecerán todos los trabajos completados, y puedes hacer clic en cualquier application_id para obtener más información sobre el trabajo. Del mismo modo, puedes hacer clic en "Mostrar aplicaciones incompletas" en la parte inferior de la página de destino para ver todos los trabajos que se están ejecutando.
9. Ejecuta tu trabajo de relleno
Ahora, ejecutarás un trabajo que carga datos en la memoria, extrae la información necesaria y vuelca el resultado en un bucket de Google Cloud Storage. Extraerás el "título", el "cuerpo" (texto sin procesar) y la "marca de tiempo creada" para cada comentario de Reddit. Luego, tomarás estos datos, los convertirás en un archivo CSV, los comprimirás y los cargarás en un bucket con un URI de gs://${BUCKET_NAME}/reddit_posts/YYYY/MM/food.csv.gz.
Puedes volver a consultar el editor de Cloud para leer el código de cloud-dataproc/codelabs/spark-bigquery/backfill.sh, que es una secuencia de comandos de wrapper para ejecutar el código en cloud-dataproc/codelabs/spark-bigquery/backfill.py.
cd ~/cloud-dataproc/codelabs/spark-bigquery
bash backfill.sh ${CLUSTER_NAME} ${BUCKET_NAME}
En breve, verás varios mensajes de finalización de trabajos. El trabajo puede tardar hasta 15 minutos en completarse. También puedes verificar tu bucket de almacenamiento para verificar el resultado de datos correcto con gsutil. Una vez que se completen todos los trabajos, ejecuta el siguiente comando:
gsutil ls gs://${BUCKET_NAME}/reddit_posts/*/*/food.csv.gz
Deberías ver el siguiente resultado:
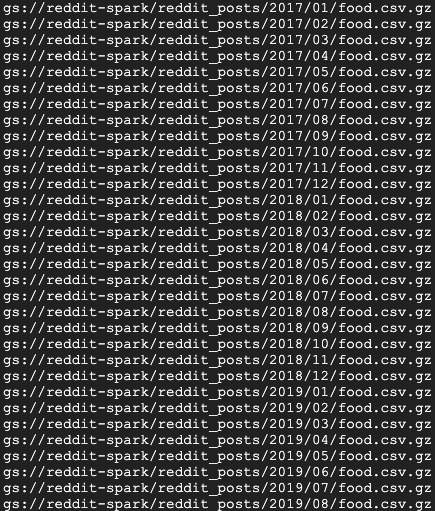
¡Felicitaciones! Completaste correctamente un relleno para los datos de tus comentarios de Reddit. Si te interesa saber cómo puedes compilar modelos sobre estos datos, continúa con el codelab de Spark-NLP.
10. Limpieza
Para evitar que se generen cargos innecesarios en tu cuenta de GCP después de completar esta guía de inicio rápido, haz lo siguiente:
- Borra el bucket de Cloud Storage para el entorno que creaste.
- Borra el entorno de Dataproc.
Si creaste un proyecto solo para este codelab, también puedes borrarlo de forma opcional:
- En GCP Console, ve a la página Proyectos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el cuadro, escribe el ID del proyecto y haz clic en Cerrar para borrar el proyecto.
Licencia
Este trabajo se ofrece bajo una licencia Atribución 3.0 Genérica de Creative Commons y una licencia Apache 2.0.