
1. Panoramica
Questo codelab illustrerà come creare una pipeline di elaborazione dei dati utilizzando Apache Spark con Dataproc su Google Cloud. È un caso d'uso comune in data science e data engineering leggere i dati da una posizione di archiviazione, eseguire trasformazioni e scriverli in un'altra posizione di archiviazione. Le trasformazioni comuni includono la modifica del contenuto dei dati, l'eliminazione delle informazioni non necessarie e la modifica dei tipi di file.
In questo codelab imparerai a utilizzare Apache Spark, a eseguire una pipeline di esempio utilizzando Dataproc con PySpark (l'API Python di Apache Spark), BigQuery, Google Cloud Storage e i dati di Reddit.
2. Introduzione ad Apache Spark (facoltativo)
Secondo il sito web, "Apache Spark è un motore di analisi unificato per l'elaborazione di dati su vasta scala". Consente di analizzare ed elaborare i dati in parallelo e in memoria, il che consente un calcolo parallelo massiccio su più macchine e nodi diversi. È stato rilasciato originariamente nel 2014 come upgrade di MapReduce ed è ancora uno dei framework più popolari per l'esecuzione di calcoli su larga scala. Apache Spark è scritto in Scala e di conseguenza ha API in Scala, Java, Python e R. Contiene una miriade di librerie come Spark SQL per l'esecuzione di query SQL sui dati, Spark Streaming per lo streaming di dati, MLlib per il machine learning e GraphX per l'elaborazione dei grafici, tutte eseguite sul motore Apache Spark.
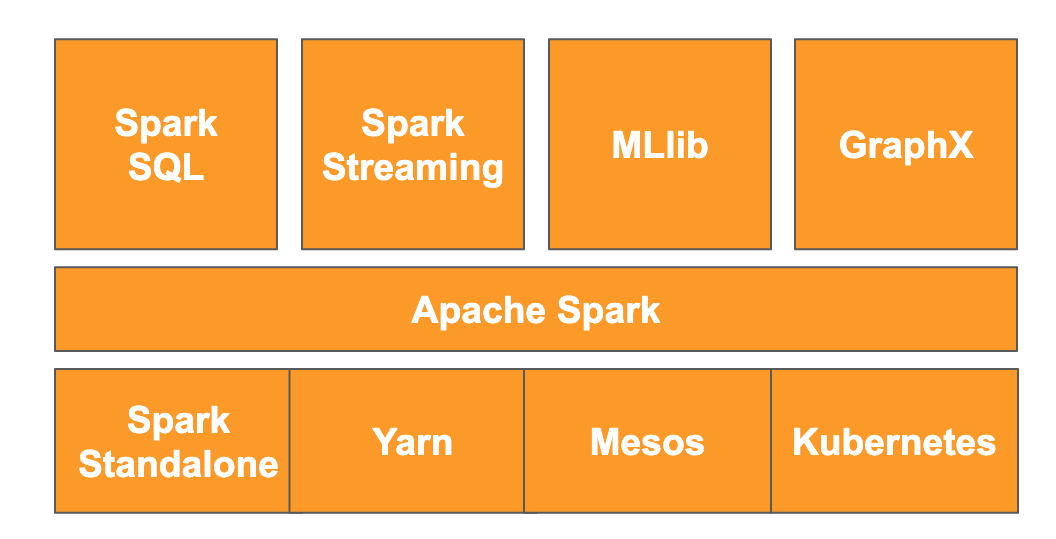
Spark può essere eseguito autonomamente o può sfruttare un servizio di gestione delle risorse come Yarn, Mesos o Kubernetes per la scalabilità. Per questo codelab utilizzerai Dataproc, che utilizza Yarn.
I dati in Spark sono stati originariamente caricati in memoria in quello che viene chiamato RDD o resilient distributed dataset. Lo sviluppo di Spark ha incluso l'aggiunta di due nuovi tipi di dati in stile colonnare: il set di dati, che è tipizzato, e il dataframe, che non è tipizzato. In generale, gli RDD sono ideali per qualsiasi tipo di dati, mentre i set di dati e i dataframe sono ottimizzati per i dati tabellari. Poiché i set di dati sono disponibili solo con le API Java e Scala, in questo codelab utilizzeremo l'API PySpark Dataframe. Per saperne di più, consulta la documentazione di Apache Spark.
3. Caso d'uso
I data engineer spesso hanno bisogno che i data scientist possano accedere facilmente ai dati. Tuttavia, i dati sono spesso inizialmente sporchi (difficili da utilizzare per i dati e analisi nel loro stato attuale) e devono essere puliti prima di poter essere utili. Un esempio sono i dati estratti dal web, che potrebbero contenere codifiche strane o tag HTML estranei.
In questo lab, caricherai un insieme di dati da BigQuery sotto forma di post di Reddit in un cluster Spark ospitato su Dataproc, estrarrai informazioni utili e archivierai i dati elaborati come file CSV compressi in Google Cloud Storage.
Il chief data scientist della tua azienda è interessato a far lavorare i suoi team su diversi problemi di elaborazione del linguaggio naturale. Nello specifico, sono interessati ad analizzare i dati del subreddit "r/food". Creerai una pipeline per un dump dei dati a partire da un backfill da gennaio 2017 ad agosto 2019.
4. Accesso a BigQuery tramite l'API BigQuery Storage
L'estrazione dei dati da BigQuery utilizzando il metodo API tabledata.list può rivelarsi dispendiosa in termini di tempo e non efficiente man mano che la quantità di dati aumenta. Questo metodo restituisce un elenco di oggetti JSON e richiede la lettura sequenziale di una pagina alla volta per leggere un intero set di dati.
L'API BigQuery Storage apporta miglioramenti significativi all'accesso ai dati in BigQuery utilizzando un protocollo basato su RPC. Supporta letture e scritture di dati in parallelo, nonché diversi formati di serializzazione come Apache Avro e Apache Arrow. A livello generale, ciò si traduce in un miglioramento significativo delle prestazioni, soprattutto su set di dati più grandi.
In questo codelab utilizzerai spark-bigquery-connector per leggere e scrivere dati tra BigQuery e Spark.
5. Creare un progetto
Accedi alla console Google Cloud all'indirizzo console.cloud.google.com e crea un nuovo progetto:



Successivamente, dovrai abilitare la fatturazione nella console Cloud per utilizzare le risorse Google Cloud.
L'esecuzione di questo codelab non dovrebbe costarti più di qualche dollaro, ma potrebbe essere più cara se decidi di utilizzare più risorse o se le lasci in esecuzione. L'ultima sezione di questo codelab ti guiderà nella pulizia del progetto.
I nuovi utenti di Google Cloud Platform possono beneficiare di una prova senza costi di 300$.
6. Configurazione dell'ambiente
Ora configurerai l'ambiente:
- Abilitazione delle API Compute Engine, Dataproc e BigQuery Storage
- Configurare le impostazioni progetto
- Creazione di un cluster Dataproc
- Creazione di un bucket Cloud Storage
Abilitazione delle API e configurazione dell'ambiente
Apri Cloud Shell premendo il pulsante nell'angolo in alto a destra di Cloud Console.
Una volta caricato Cloud Shell, esegui questi comandi per abilitare le API Compute Engine, Dataproc e BigQuery Storage:
gcloud services enable compute.googleapis.com \
dataproc.googleapis.com \
bigquerystorage.googleapis.com
Imposta l'ID progetto del tuo progetto. Puoi trovarlo andando alla pagina di selezione del progetto e cercando il tuo progetto. Potrebbe non corrispondere al nome del progetto.

Esegui questo comando per impostare l'ID progetto:
gcloud config set project <project_id>
Imposta la regione del tuo progetto scegliendone una dall'elenco qui. Un esempio potrebbe essere us-central1.
gcloud config set dataproc/region <region>
Scegli un nome per il cluster Dataproc e crea una variabile di ambiente.
CLUSTER_NAME=<cluster_name>
Creazione di un cluster Dataproc
Crea un cluster Dataproc eseguendo il seguente comando:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--worker-machine-type n1-standard-8 \
--num-workers 8 \
--image-version 1.5-debian \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--optional-components=ANACONDA \
--enable-component-gateway
Il completamento del comando richiederà un paio di minuti. Per analizzare il comando:
Verrà avviata la creazione di un cluster Dataproc con il nome che hai fornito in precedenza. L'utilizzo dell'API beta attiverà le funzionalità beta di Dataproc, ad esempio il gateway dei componenti.
gcloud beta dataproc clusters create ${CLUSTER_NAME}
In questo modo, verrà impostato il tipo di macchina da utilizzare per i worker.
--worker-machine-type n1-standard-8
In questo modo verrà impostato il numero di worker del cluster.
--num-workers 8
Verrà impostata la versione immagine di Dataproc.
--image-version 1.5-debian
In questo modo, le azioni di inizializzazione verranno configurate per essere utilizzate sul cluster. Qui includi l'azione di inizializzazione pip.
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh
Questi sono i metadati da includere nel cluster. Qui fornisci i metadati per l'azione di inizializzazione pip.
--metadata 'PIP_PACKAGES=google-cloud-storage'
In questo modo, i componenti facoltativi verranno installati sul cluster.
--optional-components=ANACONDA
In questo modo verrà attivato il gateway dei componenti, che ti consente di utilizzare il gateway dei componenti di Dataproc per visualizzare le UI comuni come Zeppelin, Jupyter o la cronologia Spark.
--enable-component-gateway
Per un'introduzione più approfondita a Dataproc, consulta questo codelab.
Creazione di un bucket Cloud Storage
Avrai bisogno di un bucket Cloud Storage per l'output del job. Determina un nome univoco per il bucket ed esegui questo comando per creare un nuovo bucket. I nomi dei bucket sono univoci in tutti i progetti Google Cloud per tutti gli utenti, quindi potresti dover riprovare più volte con nomi diversi. Un bucket viene creato correttamente se non ricevi un ServiceException.
BUCKET_NAME=<bucket_name>
gsutil mb gs://${BUCKET_NAME}
7. Analisi esplorativa dati
Prima di eseguire la pre-elaborazione, devi scoprire di più sulla natura dei dati che stai gestendo. Per farlo, esploreremo due metodi di esplorazione dei dati. Innanzitutto, visualizzerai alcuni dati non elaborati utilizzando l'interfaccia utente web di BigQuery, poi calcolerai il numero di post per subreddit utilizzando PySpark e Dataproc.
Using the BigQuery Web UI
Inizia utilizzando l'interfaccia utente web di BigQuery per visualizzare i dati. Dall'icona del menu nella console Cloud, scorri verso il basso e premi "BigQuery" per aprire la UI web di BigQuery.
Quindi, esegui il comando seguente nell'editor di query dell'UI web di BigQuery. Verranno restituite 10 righe complete di dati di gennaio 2017:
select * from fh-bigquery.reddit_posts.2017_01 limit 10;
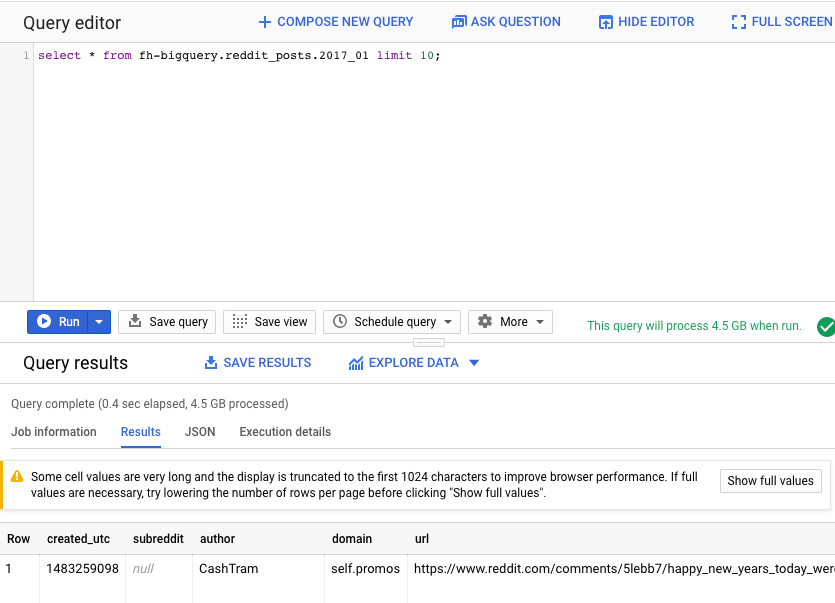
Puoi scorrere la pagina per visualizzare tutte le colonne disponibili, nonché alcuni esempi. In particolare, vedrai due colonne che rappresentano il contenuto testuale di ogni post: "title" (titolo) e"selftext " (testo personale), quest'ultima è il corpo del post. Nota anche altre colonne come "created_utc", che indica l'ora UTC in cui è stato creato un post, e "subreddit", che indica il subreddit in cui si trova il post.
Esecuzione di un job PySpark
Esegui i seguenti comandi in Cloud Shell per clonare il repository con il codice campione e passare alla directory corretta:
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
Puoi utilizzare PySpark per determinare il numero di post esistenti per ogni subreddit. Puoi aprire Cloud Editor e leggere lo script cloud-dataproc/codelabs/spark-bigquery prima di eseguirlo nel passaggio successivo:
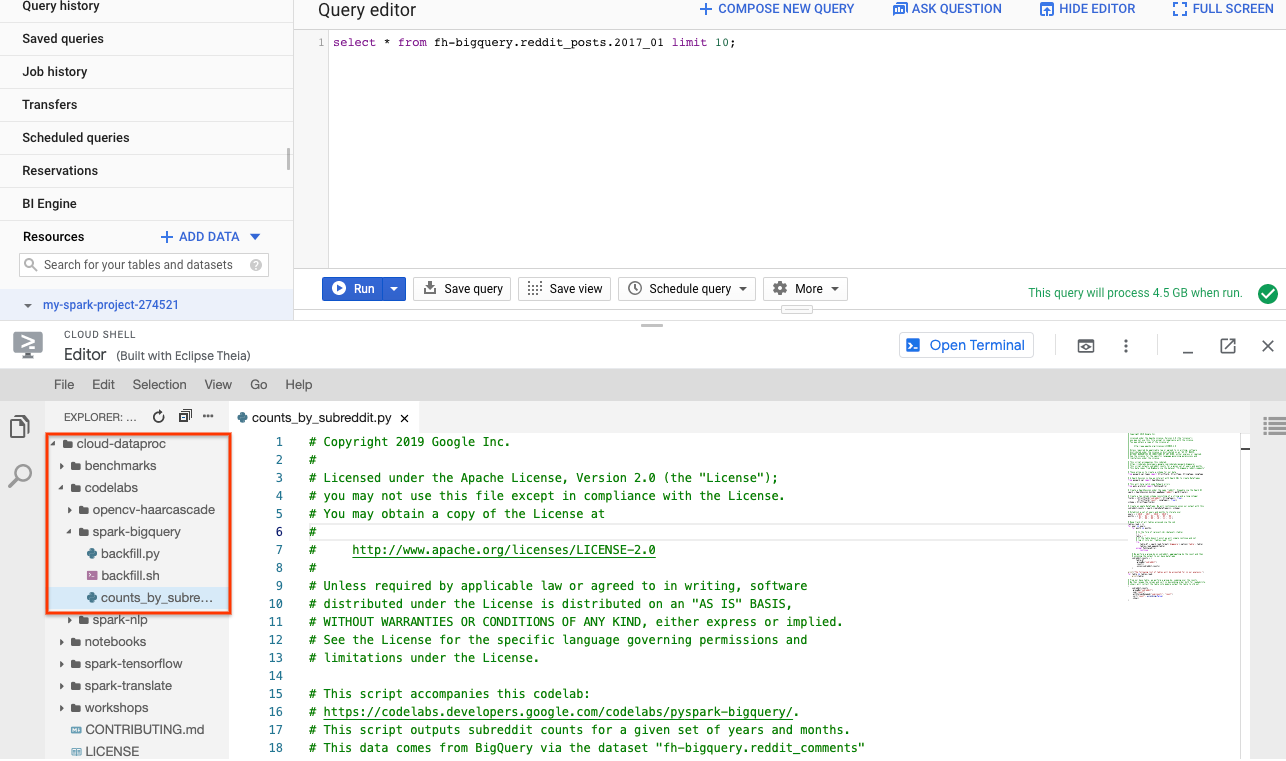
Fai clic sul pulsante "Apri terminale" in Cloud Editor per tornare a Cloud Shell ed esegui il comando seguente per eseguire il tuo primo job PySpark:
cd ~/cloud-dataproc/codelabs/spark-bigquery
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME} \
--jars gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar \
--driver-log-levels root=FATAL \
counts_by_subreddit.py
Questo comando consente di inviare job a Dataproc tramite l'API Jobs. Qui indichi il tipo di prestazione come pyspark. Puoi fornire il nome del cluster, i parametri facoltativi e il nome del file contenente il job. Qui fornisci il parametro --jars, che ti consente di includere spark-bigquery-connector nel tuo lavoro. Puoi anche impostare i livelli di output dei log utilizzando --driver-log-levels root=FATAL, che sopprime tutto l'output dei log, ad eccezione degli errori. I log di Spark tendono a essere piuttosto rumorosi.
L'esecuzione dovrebbe richiedere alcuni minuti e l'output finale dovrebbe essere simile al seguente:
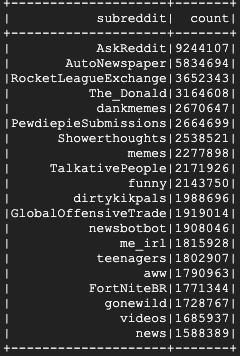
8. Esplorazione delle UI di Dataproc e Spark
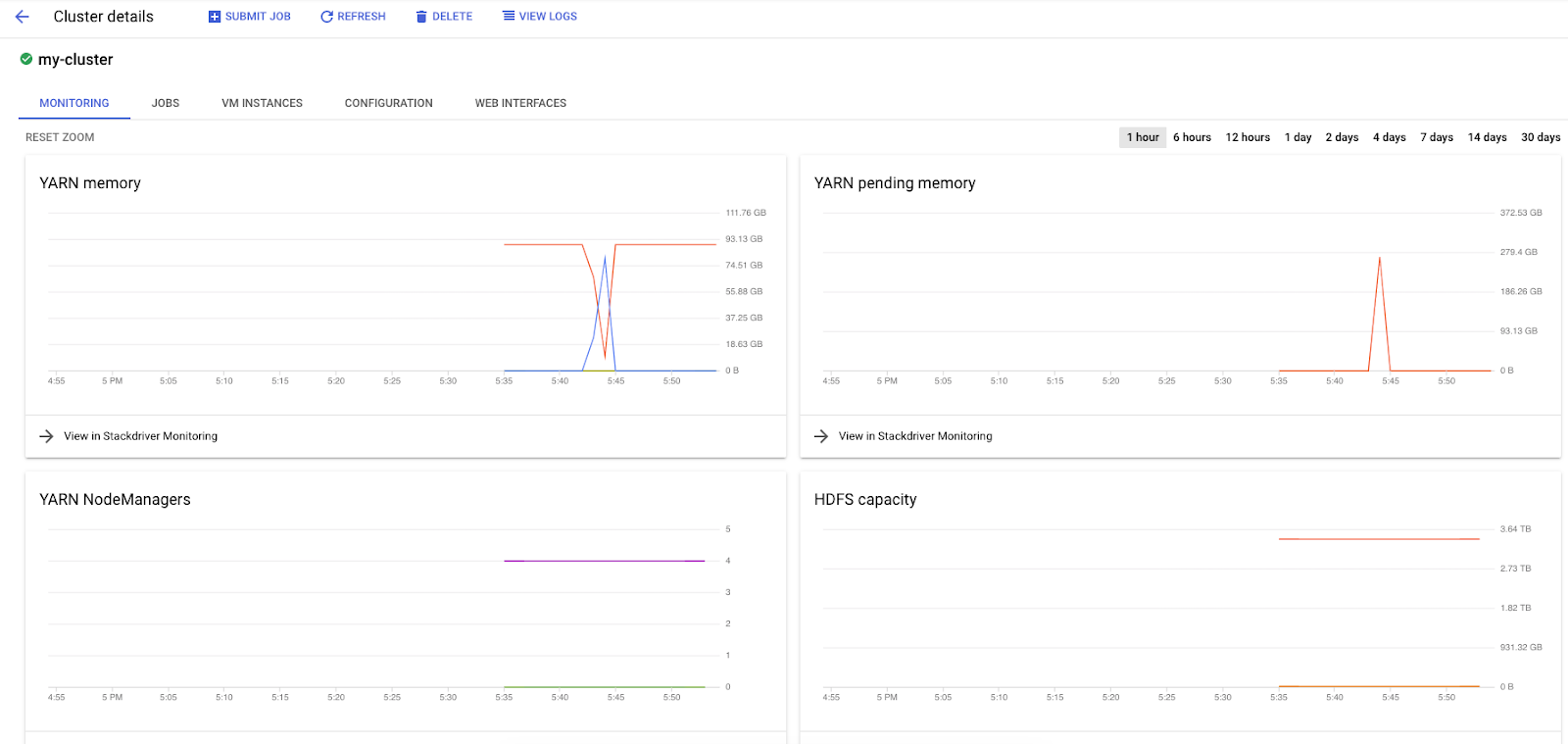
Quando esegui job Spark su Dataproc, hai accesso a due UI per controllare lo stato dei tuoi job / cluster. La prima è l'interfaccia utente di Dataproc, che puoi trovare facendo clic sull'icona del menu e scorrendo verso il basso fino a Dataproc. Qui puoi vedere la memoria disponibile attuale, la memoria in attesa e il numero di worker.
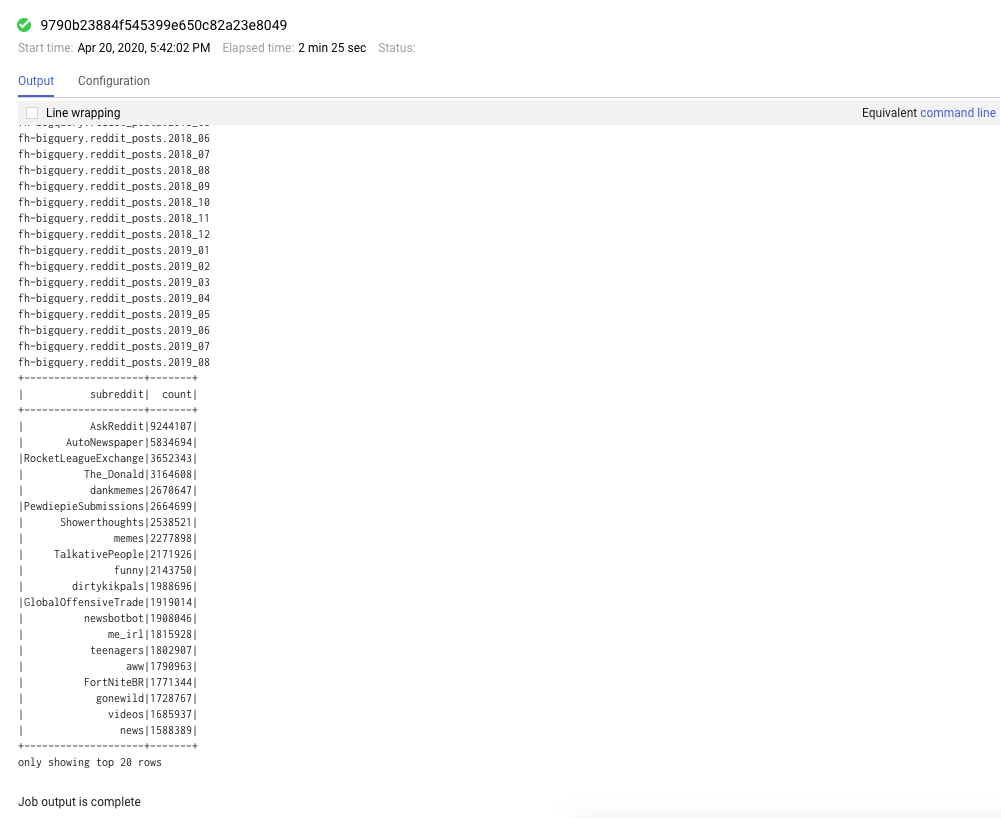
Puoi anche fare clic sulla scheda Job per visualizzare i job completati. Puoi visualizzare i dettagli del job, come i log e l'output, facendo clic sull'ID job di un job specifico. 
Puoi anche visualizzare l'interfaccia utente di Spark. Nella pagina del job, fai clic sulla freccia indietro e poi su Interfacce web. Dovresti visualizzare diverse opzioni in Gateway dei componenti. Molti di questi possono essere attivati tramite Componenti opzionali durante la configurazione del cluster. Per questo lab, fai clic su "Spark History Server.

Dovrebbe aprirsi la seguente finestra:

Qui verranno visualizzati tutti i job completati e potrai fare clic su qualsiasi application_id per saperne di più. Allo stesso modo, puoi fare clic su "Mostra candidature incomplete" in fondo alla pagina di destinazione per visualizzare tutti i lavori attualmente in corso.
9. Esecuzione del job di backfill
Ora eseguirai un job che carica i dati in memoria, estrae le informazioni necessarie e scarica l'output in un bucket Cloud Storage. Estrai "titolo", "corpo" (testo non formattato) e "timestamp di creazione" per ogni commento di Reddit. Quindi, prendi questi dati, convertili in un file CSV, comprimili e caricali in un bucket con un URI gs://${BUCKET_NAME}/reddit_posts/YYYY/MM/food.csv.gz.
Puoi fare riferimento di nuovo a Cloud Editor per leggere il codice per cloud-dataproc/codelabs/spark-bigquery/backfill.sh, che è uno script wrapper per eseguire il codice in cloud-dataproc/codelabs/spark-bigquery/backfill.py.
cd ~/cloud-dataproc/codelabs/spark-bigquery
bash backfill.sh ${CLUSTER_NAME} ${BUCKET_NAME}
A breve dovresti visualizzare una serie di messaggi di completamento del job. Il completamento del job potrebbe impiegare fino a 15 minuti. Puoi anche controllare il bucket di archiviazione per verificare l'output dei dati utilizzando gsutil. Al termine di tutti i job, esegui questo comando:
gsutil ls gs://${BUCKET_NAME}/reddit_posts/*/*/food.csv.gz
Dovresti vedere l'output seguente:
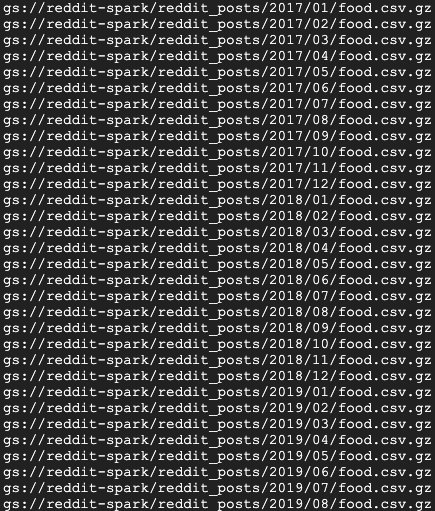
Congratulazioni, hai completato correttamente un backfill per i dati dei commenti di Reddit. Se ti interessa scoprire come creare modelli a partire da questi dati, continua con il codelab Spark-NLP.
10. Esegui la pulizia
Per evitare di incorrere in costi inutili per il tuo account GCP dopo aver completato questa guida rapida:
- Elimina il bucket Cloud Storage per l'ambiente che hai creato
- Elimina l'ambiente Dataproc.
Se hai creato un progetto solo per questo codelab, puoi anche eliminarlo facoltativamente:
- Nella console di GCP, vai alla pagina Progetti.
- Nell'elenco dei progetti, seleziona quello da eliminare e fai clic su Elimina.
- Nella casella, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
Licenza
Questo lavoro è concesso in licenza ai sensi di una licenza Creative Commons Attribution 3.0 Generic e di una licenza Apache 2.0.