
1. Visão geral
Este codelab aborda como criar um pipeline de processamento de dados usando o Apache Spark com Dataproc no Google Cloud Platform. Ler dados de um local de armazenamento, realizar transformações nele e gravá-los em outro local de armazenamento é um caso de uso comum em ciência de dados e engenharia de dados. As transformações comuns incluem mudar o conteúdo dos dados, remover informações desnecessárias e alterar os tipos de arquivo.
Neste codelab, você vai aprender sobre o Apache Spark, executar um pipeline de amostra usando o Dataproc com o PySpark (API Python do Apache Spark), BigQuery, Google Cloud Storage e dados do Reddit.
2. Introdução ao Apache Spark (opcional)
De acordo com o site, " o Apache Spark é um mecanismo de análise unificado para processamento de dados em grande escala". Ele permite analisar e processar dados em paralelo e na memória, o que permite uma computação paralela massiva em várias máquinas e nós diferentes. Ele foi lançado originalmente em 2014 como uma atualização do MapReduce tradicional e ainda é um dos frameworks mais populares para realizar computações em grande escala. O Apache Spark é escrito em Scala e, posteriormente, tem APIs em Scala, Java, Python e R. Ele contém uma grande quantidade de bibliotecas, como o Spark SQL para realizar consultas SQL nos dados, o Spark Streaming para streaming de dados, o MLlib para machine learning e o GraphX para processamento de gráficos, que são executados no mecanismo do Apache Spark.
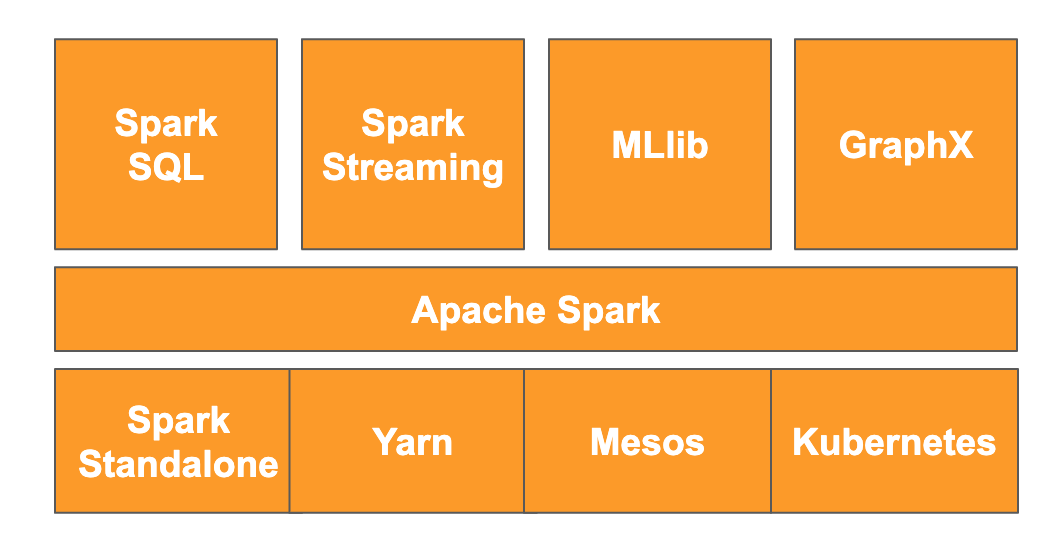
O Spark pode ser executado sozinho ou pode aproveitar um serviço de gerenciamento de recursos, como Yarn, Mesos ou Kubernetes para escalonamento. Você vai usar o Dataproc para este codelab, que utiliza o Yarn.
Os dados no Spark foram carregados originalmente na memória no que é chamado de RDD ou conjunto de dados distribuídos resilientes. O desenvolvimento no Spark incluiu a adição de dois novos tipos de dados colunares: o conjunto de dados, que é digitado, e o DataFrame, que não é digitado. De modo geral, os RDDs são ótimos para qualquer tipo de dados, enquanto os conjuntos de dados e DataFrames são otimizados para dados tabulares. Como os conjuntos de dados só estão disponíveis com as APIs Java e Scala, vamos usar a API DataFrame do PySpark para este codelab. Para mais informações, consulte a documentação do Apache Spark documentation.
3. Caso de uso
Os engenheiros de dados geralmente precisam que os dados sejam facilmente acessíveis aos cientistas de dados. No entanto, os dados geralmente são inicialmente sujos (difíceis de usar para análise no estado atual) e precisam ser limpos antes de serem úteis. Um exemplo disso são os dados extraídos da Web, que podem conter codificações estranhas ou tags HTML estranhas.
Neste laboratório, você vai carregar um conjunto de dados do BigQuery na forma de postagens do Reddit em um cluster do Spark hospedado no Dataproc, extrair informações úteis e armazenar os dados processados como arquivos CSV compactados no Google Cloud Storage.

O cientista de dados principal da sua empresa tem interesse em que as equipes trabalhem em diferentes problemas de processamento de linguagem natural. Especificamente, eles estão interessados em analisar os dados no subreddit "r/food". Você vai criar um pipeline para um despejo de dados começando com um backfill de janeiro de 2017 a agosto de 2019.
4. Como acessar o BigQuery pela API BigQuery Storage
Extrair dados do BigQuery usando o método de API tabledata.list pode ser demorado e ineficiente à medida que a quantidade de dados aumenta. Esse método retorna uma lista de objetos JSON e exige a leitura sequencial de uma página por vez para ler um conjunto de dados inteiro.
A API BigQuery Storage traz melhorias significativas para o acesso a dados no BigQuery usando um protocolo baseado em RPC. Ela oferece suporte a leituras e gravações de dados em paralelo, bem como a diferentes formatos de serialização, como Apache Avro e Apache Arrow. Em um nível alto, isso se traduz em um desempenho significativamente melhor, especialmente em conjuntos de dados maiores.
Neste codelab, você vai usar o spark-bigquery-connector para ler e gravar dados entre o BigQuery e o Spark.
5. Como criar um projeto
Faça login no console do Google Cloud Platform em console.cloud.google.com e crie um novo projeto:



Em seguida, será necessário ativar o faturamento no console do Cloud para usar os recursos do Google Cloud.
A execução por meio deste codelab terá um custo baixo, mas poderá ser maior se você decidir usar mais recursos ou se deixá-los em execução. A última seção deste codelab vai orientar você na limpeza do projeto.
Novos usuários do Google Cloud Platform estão qualificados para um teste sem custo financeiro de US$300.
6. Como configurar seu ambiente
Agora, você vai configurar seu ambiente:
- Ativar as APIs Compute Engine, Dataproc e BigQuery Storage
- Definir configurações do projeto
- Como criar um cluster do Dataproc
- Criar um bucket do Cloud Storage
Ativar APIs e configurar seu ambiente
Abra o Cloud Shell pressionando o botão no canto superior direito do console do Cloud.
Depois que o Cloud Shell for carregado, execute os comandos a seguir para ativar as APIs Compute Engine, Dataproc e BigQuery Storage:
gcloud services enable compute.googleapis.com \
dataproc.googleapis.com \
bigquerystorage.googleapis.com
Defina o ID do projeto. Para encontrar o ID, acesse a página de seleção de projetos e pesquise o projeto. Ele pode não ser o mesmo que o nome do projeto.

Execute o comando a seguir para definir o ID do projeto:
gcloud config set project <project_id>
Defina a região do projeto escolhendo uma na lista aqui. Um exemplo pode ser us-central1.
gcloud config set dataproc/region <region>
Escolha um nome para o cluster do Dataproc e crie uma variável de ambiente para ele.
CLUSTER_NAME=<cluster_name>
Como criar um cluster do Dataproc
Crie um cluster do Dataproc executando o comando a seguir:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--worker-machine-type n1-standard-8 \
--num-workers 8 \
--image-version 1.5-debian \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--optional-components=ANACONDA \
--enable-component-gateway
Esse comando leva alguns minutos para ser concluído. Para detalhar o comando:
Isso vai iniciar a criação de um cluster do Dataproc com o nome fornecido anteriormente. O uso da API beta vai ativar os recursos Beta do Dataproc, como o Gateway de componentes.
gcloud beta dataproc clusters create ${CLUSTER_NAME}
Isso vai definir o tipo de máquina a ser usada para os workers.
--worker-machine-type n1-standard-8
Isso vai definir o número de workers que o cluster terá.
--num-workers 8
Isso vai definir a versão da imagem do Dataproc.
--image-version 1.5-debian
Isso vai configurar as ações de inicialização a serem usadas no cluster. Aqui, você está incluindo a ação de inicialização do pip.
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh
Esses são os metadados a serem incluídos no cluster. Aqui, você está fornecendo metadados para a ação de inicialização pip.
--metadata 'PIP_PACKAGES=google-cloud-storage'
Isso vai definir os componentes opcionais a serem instalados no cluster.
--optional-components=ANACONDA
Isso vai ativar o Gateway de componentes, que permite usar o Gateway de componentes do Dataproc para visualizar interfaces comuns, como Zeppelin, Jupyter ou o histórico do Spark.
--enable-component-gateway
Para uma introdução mais detalhada ao Dataproc, consulte este codelab.
Criar um bucket do Cloud Storage
Você vai precisar de um bucket do Cloud Storage para a saída do job. Determine um nome exclusivo para o bucket e execute o comando a seguir para criar um novo bucket. Os nomes de bucket são exclusivos em todos os projetos do Google Cloud para todos os usuários. Portanto, talvez seja necessário tentar algumas vezes com nomes diferentes. Um bucket é criado com sucesso se você não receber uma ServiceException.
BUCKET_NAME=<bucket_name>
gsutil mb gs://${BUCKET_NAME}
7. Análise exploratória de dados
Antes de realizar o pré-processamento, aprenda mais sobre a natureza dos dados com que você está trabalhando. Para fazer isso, você vai explorar dois métodos de exploração de dados. Primeiro, você vai visualizar alguns dados brutos usando a interface da Web do BigQuery e, em seguida, calcular o número de postagens por subreddit usando o PySpark e o Dataproc.
Como usar a interface da Web do BigQuery
Comece usando a interface da Web do BigQuery para visualizar seus dados. No ícone de menu do console do Cloud, role para baixo e pressione "BigQuery" para abrir a interface da Web do BigQuery.
Em seguida, execute o comando a seguir no editor de consultas da interface da Web do BigQuery. Isso vai retornar 10 linhas completas dos dados de janeiro de 2017:
select * from fh-bigquery.reddit_posts.2017_01 limit 10;
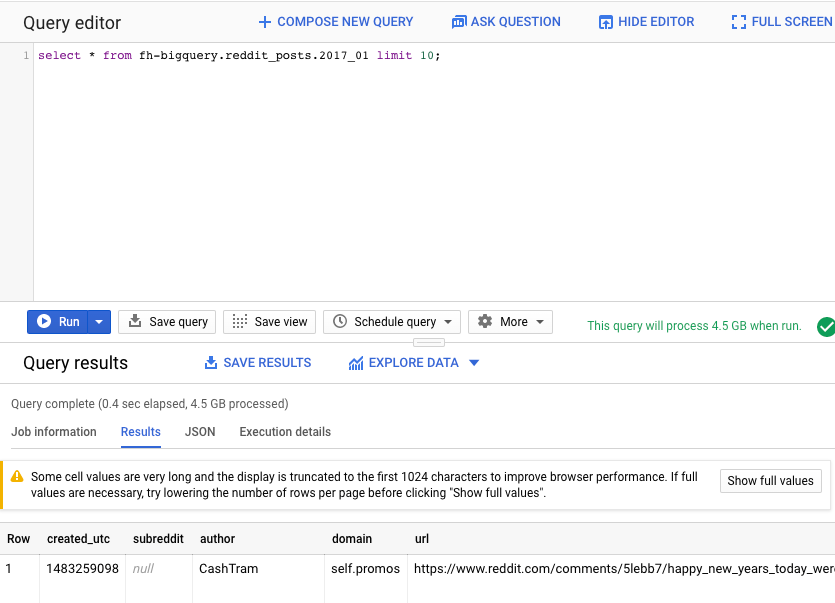
Role a página para ver todas as colunas disponíveis, bem como alguns exemplos. Em particular, você vai encontrar duas colunas que representam o conteúdo textual de cada postagem: "título" e "selftext", sendo a última o corpo da postagem. Observe também outras colunas, como "created_utc", que é a hora UTC em que uma postagem foi feita, e "subreddit", que é o subreddit em que a postagem existe.
Executar um job do PySpark
Execute os comandos a seguir no Cloud Shell para clonar o repositório com o exemplo de código e cd no diretório correto:
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
É possível usar o PySpark para determinar uma contagem de quantas postagens existem para cada subreddit. Você pode abrir o Cloud Editor e ler o script cloud-dataproc/codelabs/spark-bigquery antes de executá-lo na próxima etapa:
Clique no botão "Abrir terminal" no Cloud Editor para voltar ao Cloud Shell e execute o comando a seguir para executar seu primeiro job do PySpark:
cd ~/cloud-dataproc/codelabs/spark-bigquery
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME} \
--jars gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar \
--driver-log-levels root=FATAL \
counts_by_subreddit.py
Esse comando permite enviar jobs ao Dataproc pela API Jobs. Aqui, você está indicando o tipo de serviço como pyspark. É possível fornecer o nome do cluster, parâmetros opcionais e o nome do arquivo que contém o job. Aqui, você está fornecendo o parâmetro --jars, que permite incluir o spark-bigquery-connector com seu job. Também é possível definir os níveis de saída de registro usando --driver-log-levels root=FATAL, que vai suprimir toda a saída de registro, exceto erros. Os registros do Spark tendem a ser bastante ruidosos.
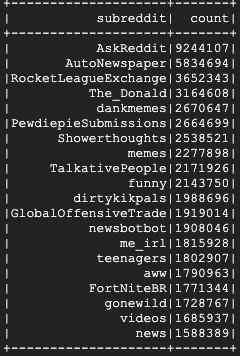
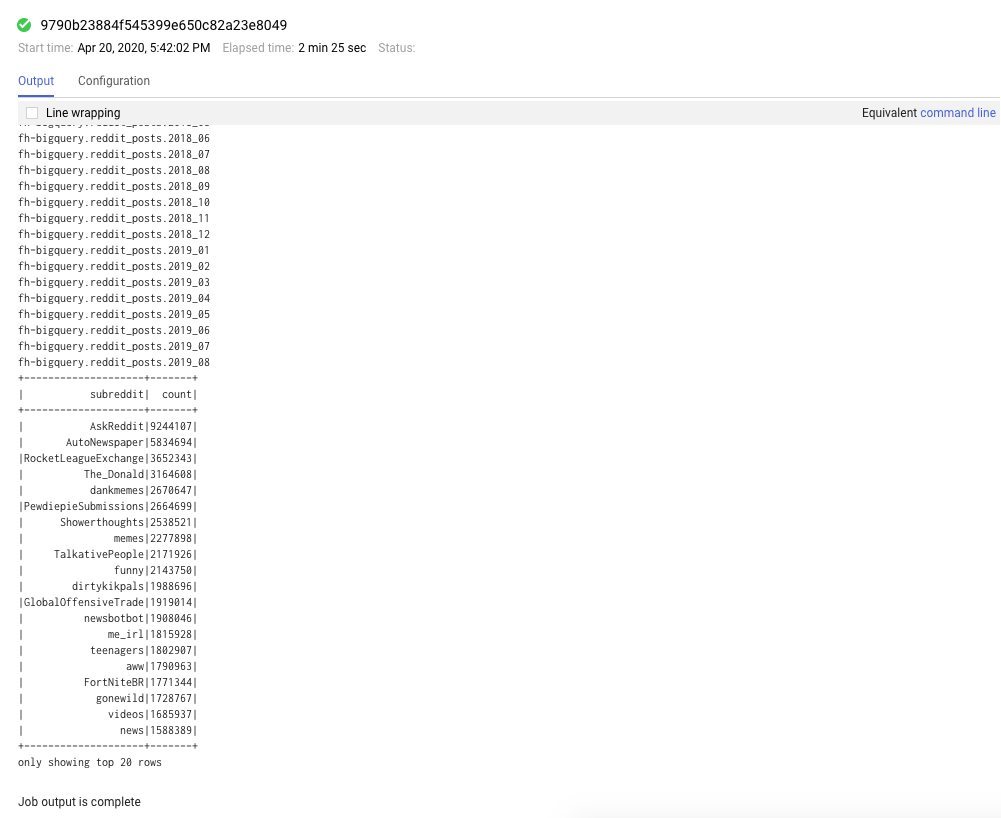
Isso leva alguns minutos para ser executado e a saída final será semelhante a esta:
8. Como explorar as interfaces do Dataproc e do Spark
Ao executar jobs do Spark no Dataproc, você tem acesso a duas interfaces para verificar o status dos jobs / clusters. A primeira é a interface do Dataproc, que pode ser encontrada clicando no ícone de menu e rolando para baixo até o Dataproc. Aqui, você pode conferir a memória disponível atual, bem como a memória pendente e o número de workers.
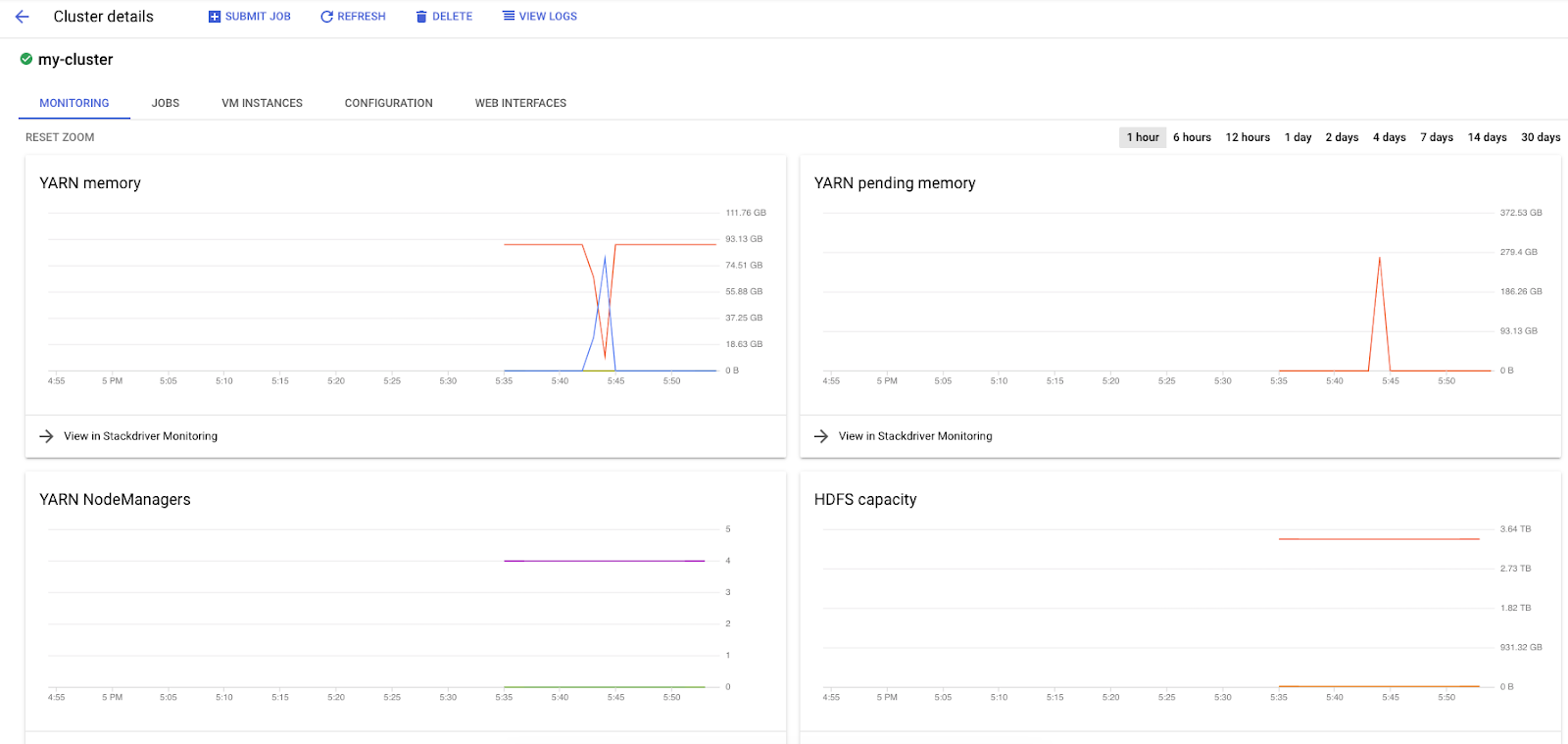
Também é possível clicar na guia "Jobs" para conferir os jobs concluídos. Para conferir detalhes da tarefa, como os registros e a saída dessas tarefas, clique no código da tarefa de uma tarefa específica. 
Também é possível conferir a interface do Spark. Na página de jobs, clique na seta para voltar e, em seguida, em "Interfaces da Web". Várias opções vão aparecer em "Gateway de componentes". Muitas delas podem ser ativadas usando "Componentes opcionais" ao configurar o cluster. Para este laboratório, clique em "Servidor de histórico do Spark".

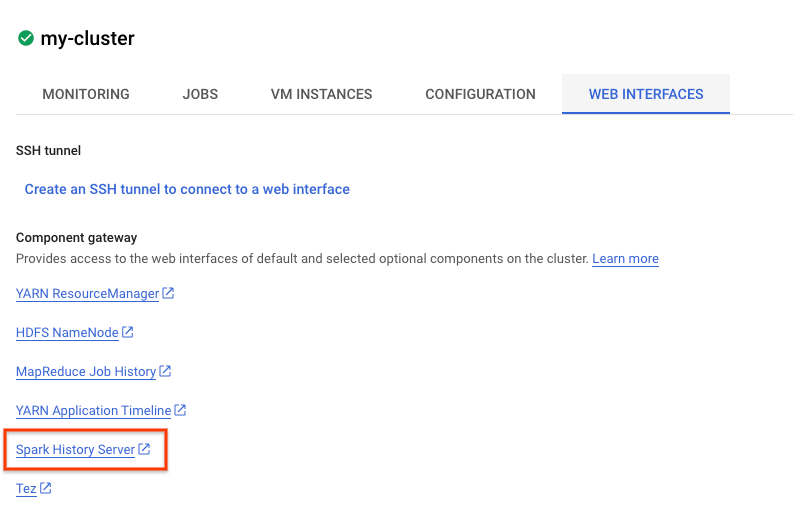
Isso vai abrir a seguinte janela:

Todos os jobs concluídos vão aparecer aqui, e você pode clicar em qualquer application_id para saber mais informações sobre o job. Da mesma forma, é possível clicar em "Mostrar aplicativos incompletos" na parte de baixo da página de destino para conferir todos os jobs em execução.
9. Executar o job de backfill
Agora, você vai executar um job que carrega dados na memória, extrai as informações necessárias e despeja a saída em um bucket do Cloud Storage. Você vai extrair o "título", o "corpo" (texto bruto) e o "carimbo de data/hora criado" para cada comentário do Reddit. Em seguida, você vai usar esses dados, convertê-los em um CSV, compactá-los e carregá-los em um bucket com um URI de gs://${BUCKET_NAME}/reddit_posts/YYYY/MM/food.csv.gz.
Você pode consultar o Cloud Editor novamente para ler o código de cloud-dataproc/codelabs/spark-bigquery/backfill.sh, que é um script wrapper para executar o código em cloud-dataproc/codelabs/spark-bigquery/backfill.py.
cd ~/cloud-dataproc/codelabs/spark-bigquery
bash backfill.sh ${CLUSTER_NAME} ${BUCKET_NAME}
Em breve, você vai encontrar várias mensagens de conclusão de job. O job pode levar até 15 minutos para ser concluído. Você também pode verificar o bucket de armazenamento para verificar a saída de dados bem-sucedida usando o gsutil. Quando todos os jobs forem concluídos, execute o comando a seguir:
gsutil ls gs://${BUCKET_NAME}/reddit_posts/*/*/food.csv.gz
Você verá esta resposta:
Parabéns, você concluiu um backfill para os dados de comentários do Reddit. Se você tiver interesse em como criar modelos com base nesses dados, continue para o codelab do Spark-NLP.
10. Revisão dos dados
Para evitar cobranças desnecessárias na sua conta do GCP após a conclusão deste guia de início rápido:
- Exclua o bucket do Cloud Storage do ambiente que você criou.
- Exclua o ambiente do Dataproc.
Se você criou um projeto apenas para este codelab, também poderá excluir o projeto:
- No console do GCP, acesse a página Projetos.
- Na lista de projetos, selecione um e clique em Excluir.
- Na caixa, digite o ID do projeto e clique em desligar para excluir o projeto.
Licença
Este trabalho está licenciado sob a Licença Creative Commons Atribuição 3.0 genérica e a licença Apache 2.0.