
1. Introdução

Última atualização:28/02/2020
Este codelab demonstra um padrão de ingestão de dados para ingerir dados de saúde formatados em CSV no BigQuery em tempo real. Vamos usar o pipeline de dados em tempo real do Cloud Data Fusion neste laboratório. Dados de teste de saúde realistas foram gerados e disponibilizados para você no bucket do Cloud Storage do Google (gs://hcls_testing_data_fhir_10_patients/csv/).
Neste codelab, você vai aprender:
- Como ingerir dados CSV (carregamento em tempo real) do Pub/Sub para o BigQuery usando o Cloud Data Fusion.
- Como criar visualmente um pipeline de integração de dados no Cloud Data Fusion para carregar, transformar e mascarar dados de saúde em tempo real.
O que você precisa para executar esta demonstração?
- Você precisa ter acesso a um projeto do GCP.
- Você precisa ter o papel de proprietário atribuído ao projeto do GCP.
- Dados de saúde em formato CSV, incluindo o cabeçalho.
Se você não tiver um projeto do GCP, siga estas etapas para criar um.
Os dados de saúde em formato CSV foram pré-carregados no bucket do GCS em gs://hcls_testing_data_fhir_10_patients/csv/. Cada arquivo de recurso CSV tem uma estrutura de esquema exclusiva. Por exemplo, "Patients.csv" tem um esquema diferente de "Providers.csv". Os arquivos de esquema pré-carregados podem ser encontrados em gs://hcls_testing_data_fhir_10_patients/csv_schemas.
Se você precisar de um novo conjunto de dados, gere um usando o SyntheaTM. Em seguida, faça o upload para o GCS em vez de copiar do bucket na etapa "Copiar dados de entrada".
2. Configuração do projeto do GCP
Inicialize as variáveis de shell para seu ambiente.
Para encontrar o PROJECT_ID, consulte Como identificar projetos.
<!-- CODELAB: Initialize shell variables -> <!-- Your current GCP Project ID -> export PROJECT_ID=<PROJECT_ID> <!-- A new GCS Bucket in your current Project - INPUT -> export BUCKET_NAME=<BUCKET_NAME> <!-- A new BQ Dataset ID - OUTPUT -> export DATASET_ID=<DATASET_ID>
Crie um bucket do GCS para armazenar dados de entrada e registros de erros usando a ferramenta gsutil.
gsutil mb -l us gs://$BUCKET_NAME
Acessar o conjunto de dados sintéticos.
- Envie um e-mail para hcls-solutions-external+subscribe@google.com com o endereço de e-mail que você usa para fazer login no console do Cloud e peça para participar.
- Você vai receber um e-mail com instruções sobre como confirmar a ação.
- Use a opção para responder ao e-mail e participar do grupo. NÃO clique no botão
 .
. - Depois de receber o e-mail de confirmação, siga para a próxima etapa do codelab.
Copie os dados de entrada.
gsutil -m cp -r gs://hcls_testing_data_fhir_10_patients/csv gs://$BUCKET_NAME
Crie um conjunto de dados do BigQuery.
bq mk --location=us --dataset $PROJECT_ID:$DATASET_ID
Instale e inicialize o SDK do Google Cloud e crie um tópico e assinaturas do Pub/Sub.
gcloud init gcloud pubsub topics create your-topic gcloud pubsub subscriptions create --topic your-topic your-sub
3. Configuração do ambiente do Cloud Data Fusion
Siga estas etapas para ativar a API Data Fusion e conceder as permissões necessárias:
Ative as APIs.
- Acesse a Biblioteca de APIs do Console do GCP.
- Selecione um projeto na lista.
- Na biblioteca de APIs, selecione a API que você quer ativar ( API Data Fusion,API Cloud Pub/Sub). Se precisar de ajuda para encontrar a API, use o campo de pesquisa e os filtros.
- Na página da API, clique em ATIVAR.
Crie uma instância do Cloud Data Fusion.
- No console do GCP, selecione seu ProjectID.
- Selecione "Data Fusion" no menu à esquerda e clique no botão "CRIAR UMA INSTÂNCIA" no meio da página (primeira criação) ou no botão "CRIAR INSTÂNCIA" no menu superior (criação adicional).


- Informe o nome da instância. Selecione Enterprise.

- Clique no botão "CRIAR".
Configure as permissões da instância.
Depois de criar uma instância, siga estas etapas para conceder à conta de serviço associada à instância permissões no seu projeto:
- Clique no nome da instância para acessar a página de detalhes dela.

- Copie a conta de serviço.

- Acesse a página do IAM do projeto.
- Na página "Permissões do IAM", clique no botão Adicionar para conceder à conta de serviço o papel Agente de serviço da API Data Fusion do Cloud. Cole a "conta de serviço" no campo "Novos membros" e selecione "Gerenciamento de serviços" -> função "Agente de serviço do servidor da API Cloud Data Fusion".

- Clique em + Adicionar outro papel (ou Editar agente de serviço da API Cloud Data Fusion) para adicionar um papel de assinante do Pub/Sub.
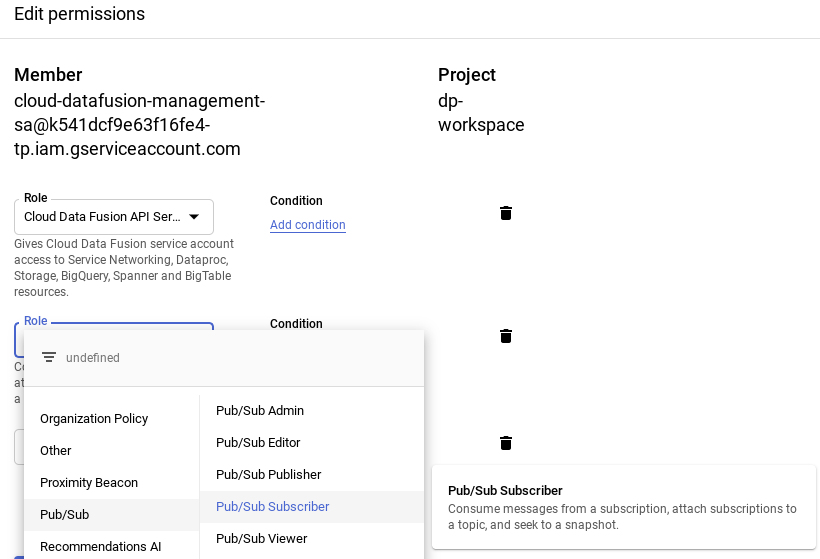
- Clique em Salvar.
Depois que essas etapas forem concluídas, o Cloud Data Fusion já estará pronto para ser usado. Basta clicar no link Visualizar instância na página de instâncias do Cloud Data Fusion ou na página de detalhes de uma instância.
Configure a regra de firewall.
- Navegue até o Console do GCP -> Rede VPC -> Regras de firewall para verificar se a regra default-allow-ssh existe ou não.

- Caso contrário, adicione uma regra de firewall que permita todo o tráfego SSH de entrada para a rede padrão.
Usando a linha de comando:
gcloud beta compute --project={PROJECT_ID} firewall-rules create default-allow-ssh --direction=INGRESS --priority=1000 --network=default --action=ALLOW --rules=tcp:22 --source-ranges=0.0.0.0/0 --enable-logging
Usando a interface: clique em "Criar regra de firewall" e preencha as informações:


4. Criar nós para o pipeline
Agora que temos o ambiente do Cloud Data Fusion no GCP, vamos começar a criar os pipelines de dados no Cloud Data Fusion seguindo estas etapas:
- Na janela do Cloud Data Fusion, clique no link "Visualizar instância" na coluna "Ação". Você será redirecionado para outra página. Clique no URL fornecido para abrir a instância do Cloud Data Fusion. Sua escolha de clicar no botão "Iniciar tour" ou "Não, obrigado" no pop-up de boas-vindas.
- Abra o menu "hambúrguer" e selecione "Pipeline" -> "List".

- Clique no botão verde + no canto superior direito e selecione Criar pipeline. Ou clique em "Criar" um link de pipeline.


- Quando a janela do pipeline aparecer, no canto superior esquerdo, selecione Pipeline de dados – tempo real no menu suspenso.

- Na interface do Data Pipelines, você encontra diferentes seções no painel esquerdo, como "Filtro", "Origem", "Transformação", "Análise", "Destino", "Processadores de erros" e "Alertas", em que é possível selecionar um ou mais nós para o pipeline.

Selecione um nó de origem.
- Na seção "Origem" da paleta de plug-ins à esquerda, clique duas vezes no nó Google Cloud Pub/Sub, que aparece na interface do Data Pipelines.
- Aponte para o nó de origem do Pub/Sub e clique em Propriedades.

- Preencha os campos obrigatórios. Defina os seguintes campos:
- Rótulo = {qualquer texto}
- Nome de referência = {qualquer texto}
- ID do projeto = detecção automática
- Subscription = assinatura criada na seção "Criar tópico do Pub/Sub" (por exemplo, your-sub)
- Tópico = tópico criado na seção "Criar tópico do Pub/Sub" (por exemplo, seu-tópico)
- Clique em Documentação para uma explicação detalhada. Clique no botão "Validar" para validar todas as informações inseridas. A mensagem verde "Nenhum erro encontrado" indica sucesso.

- Para fechar as propriedades do Pub/Sub, clique no botão X.
Selecione o nó Transformar.
- Na seção "Transform" da paleta de plug-ins à esquerda, clique duas vezes no nó Projection, que aparece na interface do usuário do Data Pipelines. Conecte o nó de origem do Pub/Sub ao nó de transformação de projeção.
- Passe o cursor sobre o nó Projeção e clique em Propriedades.

- Preencha os campos obrigatórios. Defina os seguintes campos:
- Convert = converte message do tipo byte para o tipo string.
- Campos a serem descartados = {qualquer campo}
- Campos a serem mantidos = {message, timestamp e attributes} (por exemplo, attributes: key=‘filename':value=‘patients' enviados pelo Pub/Sub)
- Campos a serem renomeados = {message, timestamp}
- Clique em Documentação para uma explicação detalhada. Clique no botão "Validar" para validar todas as informações inseridas. A mensagem verde "Nenhum erro encontrado" indica sucesso.

- Na seção "Transformar" da paleta de plug-ins à esquerda, clique duas vezes no nó Wrangler, que aparece na interface do Data Pipelines. Conecte o nó de transformação de projeção ao nó de transformação do Wrangler. Passe o cursor sobre o nó do Wrangler e clique em Propriedades.
- Clique no menu suspenso Ações e selecione Importar para importar um esquema salvo (por exemplo: gs://hcls_testing_data_fhir_10_patients/csv_schemas/ schema (Patients).json).
- Adicione o campo TIMESTAMP no esquema de saída (se ele não existir) clicando no botão + ao lado do último campo e marque a caixa "Nulo".
- Preencha os campos obrigatórios. Defina os seguintes campos:
- Rótulo = {qualquer texto}
- Nome do campo de entrada = {*}
- Condição prévia = {attributes.get("filename") != "patients"} para distinguir cada tipo de registro ou mensagem (por exemplo, pacientes, provedores, alergias etc.) enviado do nó de origem do PubSub.
- Clique em Documentação para uma explicação detalhada. Clique no botão "Validar" para validar todas as informações inseridas. A mensagem verde "Nenhum erro encontrado" indica sucesso.

- Defina os nomes das colunas na ordem que preferir e solte os campos desnecessários. Copie o snippet de código a seguir e cole na caixa "Receita".
drop attributes parse-as-csv :body ',' false drop body set columns TIMESTAMP,Id,BIRTHDATE,DEATHDATE,SSN,DRIVERS,PASSPORT,PREFIX,FIRST,LAST,SUFFIX,MAIDEN,MARITAL,RACE,ETHNICITY,GENDER,BIRTHPLACE,ADDRESS,CITY,STATE,ZIP mask-number SSN xxxxxxx####

- Consulte Codelab em lote: CSV para BigQuery via CDF para mascaramento e desidentificação de dados. Ou adicione este snippet de código mask-number SSN xxxxxxx#### na caixa de receita
- Para fechar a janela "Propriedades da transformação", clique no botão X.
Selecione o nó de coletor.
- Na seção "Coletor" da paleta de plug-ins à esquerda, clique duas vezes no nó BigQuery, que aparece na interface do Data Pipeline. Conecte o nó de transformação do Wrangler ao nó de coletor do BigQuery.
- Aponte para o nó de coletor do BigQuery e clique em "Propriedades".

- Preencha os campos obrigatórios:
- Rótulo = {qualquer texto}
- Nome de referência = {qualquer texto}
- ID do projeto = detecção automática
- Conjunto de dados = conjunto de dados do BigQuery usado no projeto atual (por exemplo, DATASET_ID)
- Tabela = {table name}
- Clique em Documentação para uma explicação detalhada. Clique no botão "Validar" para validar todas as informações inseridas. A mensagem verde "Nenhum erro encontrado" indica sucesso.

- Para fechar as propriedades do BigQuery, clique no botão X.
5. Criar um pipeline de dados em tempo real
Na seção anterior, criamos os nós necessários para criar um pipeline de dados no Cloud Data Fusion. Nesta seção, vamos conectar os nós para criar o pipeline real.
Conectar todos os nós em um pipeline
- Arraste uma seta de conexão > da extremidade direita do nó de origem e solte na extremidade esquerda do nó de destino.
- Um pipeline pode ter várias ramificações que recebem mensagens publicadas do mesmo nó de origem do Pub/Sub.

- Nomeie o pipeline.
É isso. Você acabou de criar seu primeiro pipeline de dados em tempo real para implantação e execução.
Enviar mensagens pelo Cloud Pub/Sub
Usando a interface do Pub/Sub:
- Navegue até o console do GCP -> Pub/Sub -> Tópicos, selecione seu-tópico e clique em PUBLICAR MENSAGEM no menu superior.

- Coloque apenas uma linha de registro por vez no campo "Mensagem". Clique no botão +ADICIONAR UM ATRIBUTO. Forneça Key = filename, Value = <type of record> (por exemplo, pacientes, provedores, alergias etc.).
- Clique no botão "Publicar" para enviar a mensagem.
Usando o comando gcloud:
- Forneça a mensagem manualmente.
gcloud pubsub topics publish <your-topic> --attribute <key>=<value> --message \ "paste one record row here"
- Forneça a mensagem de forma semiautomática usando os comandos cat e sed do Unix. Esse comando pode ser executado várias vezes com parâmetros diferentes.
gcloud pubsub topics publish <your-topic> --attribute <key>=<value> --message \ "$(gsutil cat gs://$BUCKET_NAME/csv/<value>.csv | sed -n '#p')"
6. Configurar, implantar e executar o pipeline
Agora que desenvolvemos o pipeline de dados, podemos implantá-lo e executá-lo no Cloud Data Fusion.

- Mantenha os padrões de Configurar.
- Clique em Visualizar para conferir uma prévia dos dados. Clique em **Visualizar** de novo para voltar à janela anterior. Você também pode executar o pipeline no modo de visualização clicando em **EXECUTAR**.

- Clique em Registros para ver os registros.
- Clique em Salvar para salvar todas as mudanças.
- Clique em Importar para importar a configuração salva ao criar um novo pipeline.
- Clique em Exportar para exportar uma configuração de pipeline.
- Clique em Implantar para implantar o pipeline.
- Depois da implantação, clique em Executar e aguarde a conclusão do pipeline.

- Clique em Parar para interromper a execução do pipeline a qualquer momento.
- Para duplicar o pipeline, selecione "Duplicar" no botão Ações.
- Para exportar a configuração do pipeline, selecione "Exportar" no botão Ações.

- Clique em Resumo para mostrar gráficos do histórico de execução, registros, registros de erros e avisos.
7. Validação
Nesta seção, vamos validar a execução do pipeline de dados.
- Valide se o pipeline foi executado corretamente e está em execução contínua.

- Valide se as tabelas do BigQuery foram carregadas com registros atualizados com base no TIMESTAMP. Neste exemplo, dois registros ou mensagens de pacientes e um registro ou mensagem de alergia foram publicados no tópico do Pub/Sub em 25/06/2019.
bq query --nouse_legacy_sql 'select (select count(*) from \ '$PROJECT_ID.$DATASET_ID.Patients' where TIMESTAMP > "2019-06-25 \ 01:29:00.0000 UTC" ) as Patients, (select count(*) from \ '$PROJECT_ID.$DATASET_ID.Allergies' where TIMESTAMP > "2019-06-25 \ 01:29:00.0000 UTC") as Allergies;'
Waiting on bqjob_r14c8b94c1c0fe06a_0000016b960df4e1_1 ... (0s) Current status: DONE
+----------+-----------+
| Patients | Allergies |
+----------+-----------+
| 2 | 1 |
+----------+-----------+
- Valide se as mensagens publicadas em <your-topic> foram recebidas pelo assinante <your-sub>.
gcloud pubsub subscriptions pull --auto-ack <your-sub>

Como ver os resultados
Para conferir os resultados depois que as mensagens são publicadas no tópico do Pub/Sub enquanto o pipeline em tempo real está em execução:
- Consulte a tabela na interface do BigQuery. ACESSAR A IU DO BIGQUERY
- Atualize a consulta abaixo com o nome do seu projeto, conjunto de dados e tabela.

8. Limpar
Para evitar que os recursos usados nesse tutorial sejam cobrados na sua conta do Google Cloud Platform:
Depois de concluir o tutorial, libere memória dos recursos criados no GCP para que eles não ocupem cota e você não seja cobrado por eles no futuro. As próximas seções descrevem como excluir ou desativar esses recursos.
Excluir o conjunto de dados do BigQuery
Siga estas instruções para excluir o conjunto de dados do BigQuery criado como parte deste tutorial.
Excluir o bucket do GCS
Siga estas instruções para excluir o bucket do GCS criado como parte deste tutorial.
Como excluir a instância do Cloud Data Fusion
Siga estas instruções para excluir a instância do Cloud Data Fusion.
Excluir o projeto
O jeito mais fácil de evitar cobranças é excluindo o projeto que você criou para este tutorial.
Para excluir o projeto:
- No Console do GCP, acesse a página Projetos. ACESSAR A PÁGINA "PROJETOS"
- Na lista de projetos, selecione um e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
9. Parabéns
Parabéns! Você concluiu o codelab para ingerir dados de saúde no BigQuery usando o Cloud Data Fusion.
Você publicou dados CSV em um tópico do Pub/Sub e os carregou no BigQuery.
Você criou visualmente um pipeline de integração de dados para carregar, transformar e mascarar dados de saúde em tempo real.
Agora você conhece as principais etapas necessárias para começar sua jornada de análise de dados de saúde com o BigQuery no Google Cloud Platform.