1. Übersicht
In diesem Codelab wird veranschaulicht, wie Sie mithilfe von parametereffizienter Abstimmung (Parameter-efficient Tuning, PET) einen benutzerdefinierten Text-Klassifikator erstellen. Anstatt das gesamte Modell abzustimmen, werden bei PET-Methoden nur wenige Parameter aktualisiert, was das Training relativ einfach und schnell macht. Außerdem kann ein Modell so leichter neue Verhaltensweisen mit relativ wenigen Trainingsdaten lernen. Die Methodik wird ausführlich in Towards Agile Text Classifiers for Everyone beschrieben. Dort wird gezeigt, wie diese Techniken auf eine Vielzahl von Sicherheitsaufgaben angewendet werden können und mit nur wenigen Hundert Trainingsbeispielen eine erstklassige Leistung erzielt werden kann.
In diesem Codelab wird die PET-Methode LoRA und das kleinere Gemma-Modell (gemma_instruct_2b_en) verwendet, da es schneller und effizienter ausgeführt werden kann. Im Colab werden die Schritte zum Erfassen von Daten, zum Formatieren der Daten für das LLM, zum Trainieren von LoRA-Gewichten und zum Auswerten der Ergebnisse behandelt. In diesem Codelab wird das ETHOS-Dataset verwendet, ein öffentlich verfügbares Dataset zum Erkennen von Hassreden, das aus YouTube- und Reddit-Kommentaren erstellt wurde. Wenn das Modell nur mit 200 Beispielen (ein Viertel des Datasets) trainiert wird, erreicht es F1: 0,80 und ROC-AUC: 0,78.Das ist etwas mehr als der derzeit auf der Bestenliste angegebene SOTA-Wert (Stand: 15.Februar 2024). Wenn das Modell mit allen 800 Beispielen trainiert wird, erreicht es einen F1-Wert von 83,74 und einen ROC-AUC-Wert von 88,17. Größere Modelle wie gemma_instruct_7b_en sind in der Regel leistungsfähiger, aber die Kosten für Training und Ausführung sind auch höher.
Triggerwarnung: In diesem Codelab wird ein Sicherheitsklassifikator zum Erkennen von Hassreden entwickelt. Die Beispiele und die Auswertung der Ergebnisse enthalten daher einige schreckliche Formulierungen.
2. Installation und Einrichtung
Für dieses Codelab benötigen Sie eine aktuelle Version von keras (3), keras-nlp (0.8.0) und ein Kaggle-Konto, um das Basismodell herunterzuladen.
!pip install -q -U keras-nlp
!pip install -q -U keras
Wenn Sie sich bei Kaggle anmelden möchten, können Sie entweder Ihre kaggle.json-Anmeldedatendatei unter ~/.kaggle/kaggle.json speichern oder Folgendes in einer Colab-Umgebung ausführen:
import kagglehub
kagglehub.login()
Dieses Codelab wurde mit TensorFlow als Keras-Backend getestet. Sie können aber auch TensorFlow, PyTorch oder JAX verwenden:
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3. ETHOS-Dataset laden
In diesem Abschnitt laden Sie das Dataset, mit dem der Klassifikator trainiert werden soll, und bereiten es für das Training und den Test vor. Sie verwenden den beliebten Forschungs-Dataset ETHOS, der zur Erkennung von Hassreden in sozialen Medien erhoben wurde. Weitere Informationen dazu, wie das Dataset erhoben wurde, finden Sie im Artikel ETHOS: an Online Hate Speech Detection Dataset.
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
Die Ausgabe sollte in etwa so aussehen:
Label | Kommentar | |
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
4. Modell herunterladen und instanziieren
Wie in der Dokumentation beschrieben, können Sie das Gemma-Modell auf vielfältige Weise verwenden. So gehts mit Keras:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
Sie können testen, ob das Modell funktioniert, indem Sie etwas Text generieren:
model.generate('Question: what is the capital of France? ', max_length=32)
5. Textvorverarbeitung und Trennzeichen-Tokens
Damit das Modell unsere Absicht besser versteht, können Sie den Text vorverarbeiten und Trennzeichen-Tokens verwenden. Dadurch ist es weniger wahrscheinlich, dass das Modell Text generiert, der nicht dem erwarteten Format entspricht. Sie könnten beispielsweise versuchen, eine Sentimentklassifizierung vom Modell anzufordern, indem Sie einen Prompt wie diesen schreiben:
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
In diesem Fall gibt das Modell möglicherweise das aus, wonach Sie suchen, oder auch nicht. Wenn der Text beispielsweise Zeilenumbruchzeichen enthält, wirkt sich das wahrscheinlich negativ auf die Modellleistung aus. Ein robusterer Ansatz ist die Verwendung von Trennzeichen-Tokens. Der Prompt lautet dann:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
Dies kann mit einer Funktion abstrahiert werden, die den Text vorverarbeitet:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
Wenn Sie die Funktion jetzt mit demselben Prompt und Text wie zuvor ausführen, sollten Sie dieselbe Ausgabe erhalten:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
Die Ausgabe sollte so aussehen:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
6. Nachbearbeitung der Ausgabe
Die Ausgaben des Modells sind Tokens mit unterschiedlichen Wahrscheinlichkeiten. Normalerweise wählen Sie zum Generieren von Text aus den wahrscheinlichsten Tokens aus und erstellen Sätze, Absätze oder sogar ganze Dokumente. Für die Klassifizierung ist jedoch nur wichtig, ob das Modell Positive für wahrscheinlicher als Negative hält oder umgekehrt.
So können Sie die Ausgabe des zuvor instanziierten Modells in die unabhängigen Wahrscheinlichkeiten dafür umwandeln, ob das nächste Token Positive oder Negative ist:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
Sie können diese Funktion testen, indem Sie sie mit dem Prompt ausführen, den Sie zuvor erstellt haben:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
Die Ausgabe sollte in etwa so aussehen:
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
7. Alles als Classifier zusammenfassen
Zur besseren Bedienbarkeit können Sie alle Funktionen, die Sie gerade erstellt haben, in einen einzelnen sklearn-ähnlichen Klassifikator mit benutzerfreundlichen und vertrauten Funktionen wie predict() und predict_score() einbinden.
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
8. Modellabstimmung
LoRA steht für Low-Rank Adaptation. Es ist eine Feinabstimmungstechnik, mit der Large Language Models effizient abgestimmt werden können. Weitere Informationen finden Sie im LoRA: Low-Rank Adaptation of Large Language Models-Paper.
Die Keras-Implementierung von Gemma bietet eine enable_lora()-Methode, die Sie für das Fine-Tuning verwenden können:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
Nachdem Sie LoRA aktiviert haben, können Sie mit dem Feinabstimmungsprozess beginnen. Das dauert in Colab etwa 5 Minuten pro Epoche:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
Wenn Sie das Modell für mehr Epochen trainieren, wird die Genauigkeit erhöht, bis es zu einer Überanpassung kommt.
9. Ergebnisse prüfen
Sie können sich jetzt die Ausgabe des agilen Klassifikators ansehen, den Sie gerade trainiert haben. Mit diesem Code wird der vorhergesagte Klassenwert für einen Text ausgegeben:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
10. Modellbewertung
Schließlich bewerten Sie die Leistung des Modells anhand von zwei gängigen Messwerten: dem F1-Wert und der AUC-ROC. Der F1-Wert erfasst falsch negative und falsch positive Fehler, indem er den harmonischen Mittelwert von Precision und Recall bei einem bestimmten Klassifizierungsschwellenwert berechnet. Die AUC-ROC erfasst dagegen den Kompromiss zwischen der Rate richtig positiver Ergebnisse und der Rate falsch positiver Ergebnisse über eine Vielzahl von Schwellenwerten hinweg und berechnet die Fläche unter dieser Kurve.
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
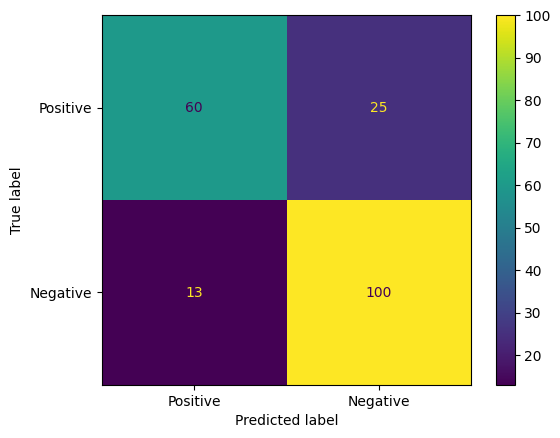
Eine weitere interessante Möglichkeit, Modellvorhersagen zu bewerten, sind Wahrheitsmatrizen. In einer Konfusionsmatrix werden die verschiedenen Arten von Vorhersagefehlern visuell dargestellt.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
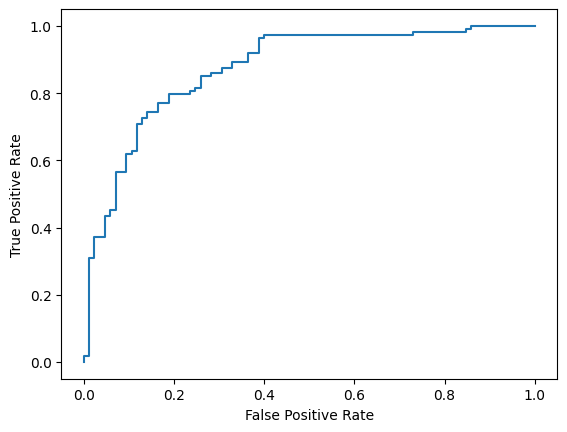
Schließlich können Sie sich auch die ROC-Kurve ansehen, um potenzielle Vorhersagefehler bei Verwendung verschiedener Scoring-Schwellenwerte zu erkennen.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()