1. Ringkasan
Codelab ini mengilustrasikan cara membuat pengklasifikasi teks yang disesuaikan menggunakan parameter-efficient tuning (PET). Daripada menyesuaikan seluruh model, metode PET hanya memperbarui sejumlah kecil parameter, sehingga pelatihan menjadi relatif mudah dan cepat. Hal ini juga mempermudah model mempelajari perilaku baru dengan data pelatihan yang relatif sedikit. Metodologinya dijelaskan secara mendetail dalam Towards Agile Text Classifiers for Everyone yang menunjukkan cara menerapkan teknik ini ke berbagai tugas keamanan dan mencapai performa terbaik hanya dengan beberapa ratus contoh pelatihan.
Codelab ini menggunakan metode PET LoRA dan model Gemma yang lebih kecil (gemma_instruct_2b_en) karena dapat dijalankan lebih cepat dan efisien. Colab ini mencakup langkah-langkah penyerapan data, memformatnya untuk LLM, melatih bobot LoRA, lalu mengevaluasi hasilnya. Codelab ini dilatih pada set data ETHOS, set data yang tersedia secara publik untuk mendeteksi ujaran kebencian, yang dibuat dari komentar YouTube dan Reddit. Saat dilatih hanya dengan 200 contoh (1/4 dari set data), model ini mencapai F1: 0,80 dan ROC-AUC: 0,78, sedikit di atas SOTA yang saat ini dilaporkan di papan peringkat (pada saat penulisan, 15 Februari 2024). Saat dilatih pada 800 contoh lengkap, model ini mencapai skor F1 83,74 dan skor ROC-AUC 88,17. Model yang lebih besar, seperti gemma_instruct_7b_en umumnya akan berperforma lebih baik, tetapi biaya pelatihan dan eksekusinya juga lebih besar.
Peringatan Konten Sensitif: karena codelab ini mengembangkan pengklasifikasi keamanan untuk mendeteksi ujaran kebencian, contoh dan evaluasi hasilnya berisi beberapa kata-kata yang mengerikan.
2. Penginstalan dan Penyiapan
Untuk codelab ini, Anda memerlukan versi keras (3) dan keras-nlp (0.8.0) terbaru serta akun Kaggle untuk mendownload model dasar.
!pip install -q -U keras-nlp
!pip install -q -U keras
Untuk login ke Kaggle, Anda dapat menyimpan file kredensial kaggle.json di ~/.kaggle/kaggle.json atau menjalankan perintah berikut di lingkungan Colab:
import kagglehub
kagglehub.login()
Codelab ini diuji menggunakan Tensorflow sebagai backend Keras, tetapi Anda dapat menggunakan Tensorflow, Pytorch, atau JAX:
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3. Memuat set data ETHOS
Di bagian ini, Anda akan memuat set data yang akan digunakan untuk melatih pengklasifikasi dan memprosesnya menjadi set pelatihan dan pengujian. Anda akan menggunakan set data riset populer ETHOS yang dikumpulkan untuk mendeteksi ujaran kebencian di media sosial. Anda dapat menemukan informasi selengkapnya tentang cara pengumpulan set data dalam makalah ETHOS: an Online Hate Speech Detection Dataset.
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
Anda akan melihat sesuatu yang mirip dengan:
label | komentar | |
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
4. Mendownload dan Membuat Instance Model
Seperti yang dijelaskan dalam dokumentasi, Anda dapat dengan mudah menggunakan model Gemma dengan berbagai cara. Dengan Keras, berikut yang perlu Anda lakukan:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
Anda dapat menguji apakah model berfungsi dengan membuat beberapa teks:
model.generate('Question: what is the capital of France? ', max_length=32)
5. Prapemrosesan Teks dan Token Pemisah
Untuk membantu model memahami maksud kita dengan lebih baik, Anda dapat memproses teks terlebih dahulu dan menggunakan token pemisah. Hal ini membuat model cenderung tidak menghasilkan teks yang tidak sesuai dengan format yang diharapkan. Misalnya, Anda dapat mencoba meminta klasifikasi sentimen dari model dengan menulis perintah seperti ini:
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
Dalam hal ini, model mungkin menghasilkan atau tidak menghasilkan output yang Anda cari. Misalnya, jika teks berisi karakter newline, kemungkinan akan berdampak negatif pada performa model. Pendekatan yang lebih efektif adalah menggunakan token pemisah. Kemudian, perintahnya menjadi:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
Hal ini dapat diabstraksi menggunakan fungsi yang memproses teks:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
Sekarang, jika Anda menjalankan fungsi menggunakan perintah dan teks yang sama seperti sebelumnya, Anda akan mendapatkan output yang sama:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
Yang akan menghasilkan output:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
6. Pasca-pemrosesan Output
Output model adalah token dengan berbagai probabilitas. Biasanya, untuk membuat teks, Anda akan memilih beberapa token yang paling mungkin dan menyusun kalimat, paragraf, atau bahkan dokumen lengkap. Namun, untuk tujuan klasifikasi, yang sebenarnya penting adalah apakah model yakin bahwa Positive lebih mungkin daripada Negative atau sebaliknya.
Mengingat model yang Anda buat sebelumnya, berikut cara memproses outputnya menjadi probabilitas independen apakah token berikutnya adalah Positive atau Negative:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
Anda dapat menguji fungsi tersebut dengan menjalankannya menggunakan perintah yang Anda buat sebelumnya:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
Yang akan menghasilkan output yang mirip dengan berikut ini:
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
7. Menggabungkan semuanya sebagai Pengklasifikasi
Agar mudah digunakan, Anda dapat menggabungkan semua fungsi yang baru saja dibuat ke dalam satu klasifikasi seperti sklearn dengan fungsi yang mudah digunakan dan sudah dikenal seperti predict() dan predict_score().
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
8. Penyesuaian Model
LoRA adalah singkatan dari Low-Rank Adaptation. Ini adalah teknik penyesuaian yang dapat digunakan untuk menyesuaikan model bahasa besar secara efisien. Anda dapat membaca selengkapnya di laporan LoRA: Low-Rank Adaptation of Large Language Models.
Implementasi Gemma di Keras menyediakan metode enable_lora() yang dapat Anda gunakan untuk penyesuaian:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
Setelah mengaktifkan LoRA, Anda dapat memulai proses penyesuaian. Proses ini memerlukan waktu sekitar 5 menit per epoch di Colab:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
Pelatihan untuk lebih banyak epoch akan menghasilkan akurasi yang lebih tinggi, hingga terjadi overfitting.
9. Memeriksa Hasil
Sekarang Anda dapat memeriksa output pengklasifikasi Agile yang baru saja Anda latih. Kode ini akan menampilkan skor class yang diprediksi berdasarkan potongan teks:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
10. Model Evaluation
Terakhir, Anda akan mengevaluasi performa model kita menggunakan dua metrik umum, yaitu skor F1 dan AUC-ROC. Skor F1 mencakup kesalahan negatif palsu dan positif palsu dengan mengevaluasi rata-rata harmonis presisi dan perolehan pada batas klasifikasi tertentu. Di sisi lain, AUC-ROC menangkap keseimbangan antara rasio positif benar dan rasio positif salah di berbagai nilai minimum dan menghitung area di bawah kurva ini.
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
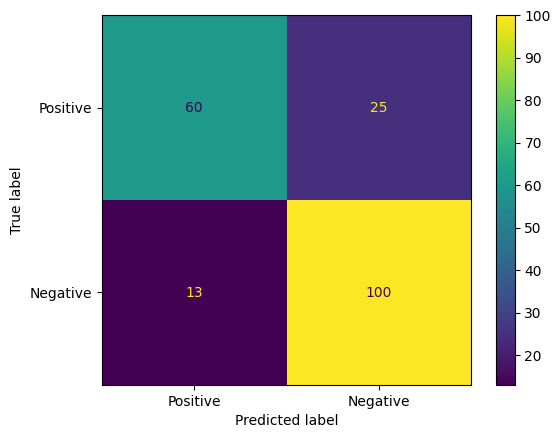
Cara menarik lainnya untuk mengevaluasi prediksi model adalah matriks konfusi. Matriks kebingungan akan menggambarkan secara visual berbagai jenis error prediksi.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
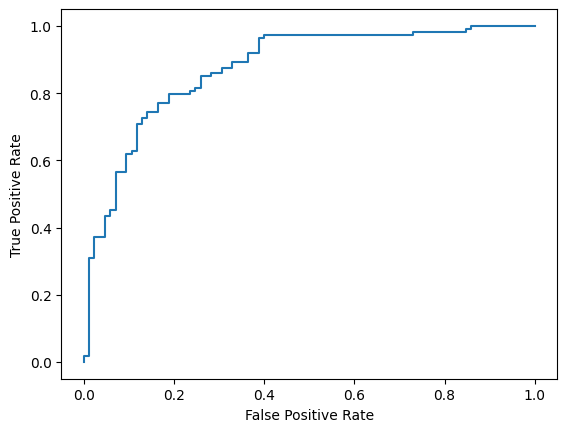
Terakhir, Anda juga dapat melihat kurva ROC untuk mendapatkan gambaran tentang potensi kesalahan prediksi saat menggunakan berbagai nilai minimum pemberian skor.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()