1. 概览
此 Codelab 演示了如何使用参数高效调优 (PET) 创建自定义文本分类器。PET 方法不会微调整个模型,而是仅更新少量参数,因此训练起来相对容易且快速。此外,它还使模型能够通过相对较少的训练数据更轻松地学习新行为。面向所有人的敏捷文本分类器一文中详细介绍了该方法,其中展示了如何将这些技术应用于各种安全任务,并仅使用数百个训练示例即可实现出色的性能。
此 Codelab 使用 LoRA PET 方法和较小的 Gemma 模型 (gemma_instruct_2b_en),因为这样可以更快、更高效地运行。此 Colab 涵盖了以下步骤:注入数据、将数据格式化为 LLM 可接受的格式、训练 LoRA 权重,然后评估结果。此 Codelab 使用 ETHOS 数据集进行训练,该数据集是一个公开可用的数据集,用于检测仇恨言论,由 YouTube 和 Reddit 评论构建而成。仅使用 200 个示例(数据集的 1/4)进行训练时,该模型的 F1 得分为 0.80,ROC-AUC 为 0.78,略高于排行榜上目前报告的 SOTA(截至撰写本文时,即 2024 年 2 月 15 日)。当使用全部 800 个示例进行训练时,模型可实现 83.74 的 F1 得分和 88.17 的 ROC-AUC 得分。像 gemma_instruct_7b_en 这样的大型模型通常性能更好,但训练和执行成本也更高。
触发警告:由于此 Codelab 会开发一个用于检测仇恨言论的安全分类器,因此示例和结果评估中包含一些令人反感的言论。
2. 安装和设置
在本 Codelab 中,您需要使用最新版本 keras (3)、keras-nlp (0.8.0),并拥有 Kaggle 账号才能下载基础模型。
!pip install -q -U keras-nlp
!pip install -q -U keras
如需登录 Kaggle,您可以将 kaggle.json 凭据文件存储在 ~/.kaggle/kaggle.json 中,也可以在 Colab 环境中运行以下命令:
import kagglehub
kagglehub.login()
此 Codelab 在测试时使用 TensorFlow 作为 Keras 后端,但您可以使用 TensorFlow、PyTorch 或 JAX:
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3. 加载 ETHOS 数据集
在本部分中,您将加载用于训练分类器的数据集,并将其预处理为训练集和测试集。您将使用热门研究数据集 ETHOS,该数据集旨在检测社交媒体中的仇恨言论。如需详细了解数据集的收集方式,请参阅论文 ETHOS:一个在线仇恨言论检测数据集。
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
您会看到类似如下的内容:
标签 | 条评论 | |
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
4. 下载并实例化模型
如文档中所述,您可以通过多种方式轻松使用 Gemma 模型。使用 Keras 时,您需要执行以下操作:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
您可以通过生成一些文本来测试模型是否正常运行:
model.generate('Question: what is the capital of France? ', max_length=32)
5. 文本预处理和分隔符令牌
为了帮助模型更好地理解我们的意图,您可以预处理文本并使用分隔符令牌。这样一来,模型生成不符合预期格式的文本的可能性就会降低。例如,您可以编写如下提示,尝试向模型请求情感分类:
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
在这种情况下,模型可能会输出您想要的结果,也可能不会。例如,如果文本包含换行符,则很可能会对模型性能产生负面影响。更可靠的方法是使用分隔符令牌。然后,提示会变为:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
可以使用预处理文本的函数来抽象化此过程:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
现在,如果您使用与之前相同的提示和文本运行该函数,您应该会得到相同的输出:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
该命令应输出:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
6. 输出后处理
模型的输出是具有不同概率的 token。通常,为了生成文本,您会从概率最高的几个 token 中进行选择,并构建句子、段落甚至完整文档。不过,对于分类而言,真正重要的是模型认为 Positive 比 Negative 更可能,还是反之。
假设您之前实例化了某个模型,以下展示了如何将该模型的输出处理为下一个 token 是 Positive 或 Negative 的独立概率:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
您可以运行该函数并使用之前创建的提示来测试该函数:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
这将输出类似如下内容的结果:
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
7. 将所有内容封装为分类器
为方便使用,您可以将刚刚创建的所有函数封装到一个类似 sklearn 的分类器中,该分类器具有易于使用且熟悉的函数,例如 predict() 和 predict_score()。
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
8. 模型微调
LoRA 是 Low-Rank Adaptation(低秩适应)的缩写。这是一种可用于高效微调大语言模型的微调技术。如需详细了解 LoRA,请参阅《LoRA:大语言模型的低秩适应》论文。
Gemma 的 Keras 实现提供了一个可用于微调的 enable_lora() 方法:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
启用 LoRA 后,您就可以开始微调流程了。在 Colab 上,每个周期的训练大约需要 5 分钟:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
在发生过拟合之前,训练周期数越多,准确率就越高。
9. 检查结果
现在,您可以检查刚刚训练的敏捷分类器的输出。此代码将输出给定文本的预测类得分:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
10. 模型评估
最后,我们将使用两个常用指标(即 F1 得分和 AUC-ROC)来评估模型的性能。F1 得分通过评估特定分类阈值下的精确率和召回率的调和平均值来捕获假负例和假正例错误。另一方面,AUC-ROC 可捕获各种阈值下真正例率与假正例率之间的权衡,并计算此曲线下的面积。
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
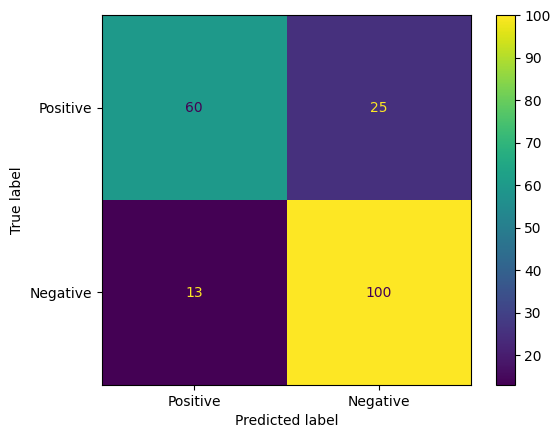
另一种评估模型预测的有趣方法是混淆矩阵。混淆矩阵将直观地展示不同类型的预测错误。
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
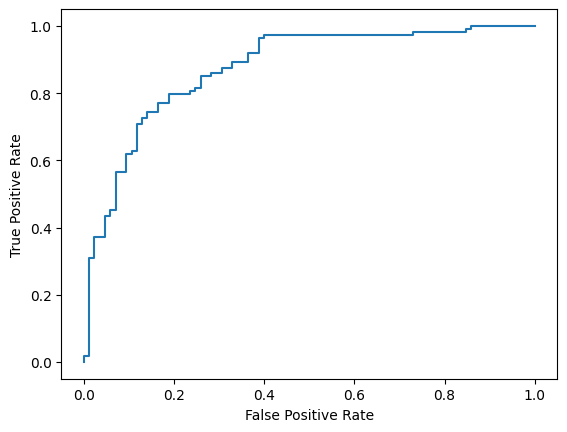
最后,您还可以查看 ROC 曲线,了解使用不同得分阈值时可能出现的预测错误。
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()