1. نظرة عامة
يوضّح لك هذا الدرس التطبيقي حول الترميز كيفية إنشاء مصنِّف مخصَّص للنصوص باستخدام الضبط الفعال للمعلَمات (PET). بدلاً من ضبط النموذج بأكمله، تعدّل طرق PET عددًا قليلاً فقط من المَعلمات، ما يجعل عملية التدريب سهلة وسريعة نسبيًا. ويسهّل أيضًا على النموذج تعلُّم سلوكيات جديدة باستخدام قدر قليل نسبيًا من بيانات التدريب. تم وصف المنهجية بالتفصيل في Towards Agile Text Classifiers for Everyone التي توضّح كيفية تطبيق هذه التقنيات على مجموعة متنوعة من مهام الأمان وتحقيق أداء متطوّر باستخدام بضع مئات فقط من الأمثلة التدريبية.
تستخدم ورشة العمل هذه طريقة LoRA PET ونموذج Gemma الأصغر (gemma_instruct_2b_en) لأنّه يمكن تشغيلهما بشكل أسرع وأكثر كفاءة. تغطّي هذه الجلسة خطوات استيعاب البيانات وتنسيقها للنموذج اللغوي الكبير وتدريب أوزان LoRA ثم تقييم النتائج. يتدرب هذا الدرس العملي على مجموعة بيانات ETHOS، وهي مجموعة بيانات متاحة للجميع لرصد خطاب الكراهية، وتم إنشاؤها من تعليقات YouTube وReddit. عند تدريبه على 200 مثال فقط (ربع مجموعة البيانات)، يحقّق النموذج F1: 0.80 وROC-AUC: 0.78، أي أعلى قليلاً من أحدث النتائج التي تم تسجيلها حاليًا في قائمة الصدارة (في وقت كتابة هذا المقال، 15 فبراير 2024). عند تدريب النموذج على جميع الأمثلة البالغ عددها 800، يحقّق النموذج مقياس F1 بقيمة 83.74 ومقياس ROC-AUC بقيمة 88.17. بشكل عام، تقدّم النماذج الأكبر حجمًا، مثل gemma_instruct_7b_en، أداءً أفضل، ولكنّ تكاليف التدريب والتنفيذ تكون أعلى أيضًا.
تحذير: لأنّ هذا الدرس التطبيقي العملي يطوّر مصنّفًا للأمان لرصد خطاب الكراهية، تتضمّن الأمثلة وتقييم النتائج بعض العبارات البذيئة.
2. التثبيت والإعداد
في هذا الدرس التطبيقي حول الترميز، ستحتاج إلى إصدار حديث من keras (3) وkeras-nlp (0.8.0) وحساب على Kaggle لتنزيل النموذج الأساسي.
!pip install -q -U keras-nlp
!pip install -q -U keras
لتسجيل الدخول إلى Kaggle، يمكنك إما تخزين ملف بيانات اعتماد kaggle.json في ~/.kaggle/kaggle.json أو تنفيذ ما يلي في بيئة Colab:
import kagglehub
kagglehub.login()
تم اختبار هذا الدرس التطبيقي باستخدام Tensorflow كبرنامج Keras، ولكن يمكنك استخدام Tensorflow أو Pytorch أو JAX:
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3- تحميل مجموعة بيانات ETHOS
في هذا القسم، سيتم تحميل مجموعة البيانات التي سيتم تدريب المصنّف عليها ومعالجتها مسبقًا في مجموعة تدريب ومجموعة اختبار. ستستخدم مجموعة بيانات الأبحاث الشائعة ETHOS التي تم جمعها لرصد كلام يحض على الكراهية على وسائل التواصل الاجتماعي. يمكنك العثور على مزيد من المعلومات حول كيفية جمع مجموعة البيانات في المستند ETHOS: مجموعة بيانات لرصد الكلام الذي يحض على الكراهية على الإنترنت.
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
سيظهر لك ما يشبه ما يلي:
التصنيف | تعليق | |
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
4. تنزيل النموذج وإنشاء مثيل له
كما هو موضّح في المستندات، يمكنك استخدام نموذج Gemma بسهولة بعدة طرق. باستخدام Keras، عليك اتّخاذ الإجراءات التالية:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
يمكنك اختبار عمل النموذج من خلال إنشاء بعض النصوص:
model.generate('Question: what is the capital of France? ', max_length=32)
5- المعالجة المُسبَقة للنص والرموز المميزة للفواصل
لمساعدة النموذج في فهم هدفنا بشكل أفضل، يمكنك معالجة النص مسبقًا واستخدام رموز مميّزة للفصل. ويقلّل ذلك من احتمال أن ينشئ النموذج نصًا لا يتوافق مع التنسيق المتوقّع. على سبيل المثال، يمكنك محاولة طلب تصنيف المشاعر من النموذج من خلال كتابة طلب مثل هذا:
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
في هذه الحالة، قد يعرض النموذج المعلومات التي تبحث عنها أو لا يعرضها. على سبيل المثال، إذا كان النص يحتوي على أحرف سطر جديد، من المحتمل أن يكون له تأثير سلبي في أداء النموذج. هناك طريقة أكثر فعالية وهي استخدام رموز مميّزة للفصل. سيصبح الطلب بعد ذلك:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
يمكن تجريد ذلك باستخدام دالة تعالج النص مسبقًا:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
الآن، إذا شغّلت الدالة باستخدام الطلب والنص نفسهما كما كان من قبل، من المفترض أن تحصل على الناتج نفسه:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
يجب أن يظهر الناتج التالي:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
6. المعالجة اللاحقة للناتج
مخرجات النموذج هي رموز مميزة باحتمالات مختلفة. في العادة، لإنشاء نص، عليك الاختيار من بين أهم الرموز المميزة الأكثر احتمالاً وإنشاء جمل أو فقرات أو حتى مستندات كاملة. ومع ذلك، لأغراض التصنيف، ما يهمّ فعلاً هو ما إذا كان النموذج يعتقد أنّ Positive أكثر احتمالاً من Negative أو العكس.
بالنظر إلى النموذج الذي أنشأته سابقًا، إليك كيفية معالجة ناتجه إلى احتمالات مستقلة لما إذا كانت الرمز المميز التالي هو Positive أو Negative:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
يمكنك اختبار هذه الدالة من خلال تشغيلها باستخدام الطلب الذي أنشأته سابقًا:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
سيؤدي ذلك إلى عرض نتيجة مشابهة لما يلي:
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
7. تجميع كل ذلك في مصنِّف
لتسهيل الاستخدام، يمكنك تضمين جميع الدوال التي أنشأتها للتو في مصنّف واحد يشبه sklearn مع دوال سهلة الاستخدام ومألوفة مثل predict() وpredict_score().
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
8. ضبط النموذج
يشير الاختصار LoRA إلى Low-Rank Adaptation. وهي تقنية ضبط يمكن استخدامها لضبط النماذج اللغوية الكبيرة بكفاءة. يمكنك الاطّلاع على مزيد من المعلومات حول هذا الموضوع في مستند LoRA: Low-Rank Adaptation of Large Language Models.
يوفر تنفيذ Gemma في Keras طريقة enable_lora() يمكنك استخدامها لضبط النموذج بدقة:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
بعد تفعيل LoRA، يمكنك بدء عملية الضبط الدقيق. يستغرق ذلك 5 دقائق تقريبًا لكل حقبة على Colab:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
سيؤدي التدريب لعدد أكبر من الدورات إلى زيادة الدقة، إلى أن يحدث الإفراط في التكيّف.
9- فحص النتائج
يمكنك الآن فحص نتائج المصنّف السريع الذي درّبته للتو. ستعرض هذه التعليمات البرمجية نتيجة الفئة المتوقّعة عند إدخال جزء من النص:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
10. تقييم النموذج
أخيرًا، ستُقيّم أداء النموذج باستخدام مقياسَين شائعَين، وهما نتيجة F1 وAUC-ROC. يسجّل مقياس F1 أخطاء السالب الخاطئ والموجب الخاطئ من خلال تقييم المتوسط التوافقي للدقة والتذكّر عند عتبة تصنيف معيّنة. من ناحية أخرى، تسجّل المساحة تحت منحنى ROC المفاضلة بين معدل الموجب الصحيح ومعدل الموجب الخاطئ على مجموعة متنوعة من الحدود، وتحسب المساحة تحت هذا المنحنى.
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
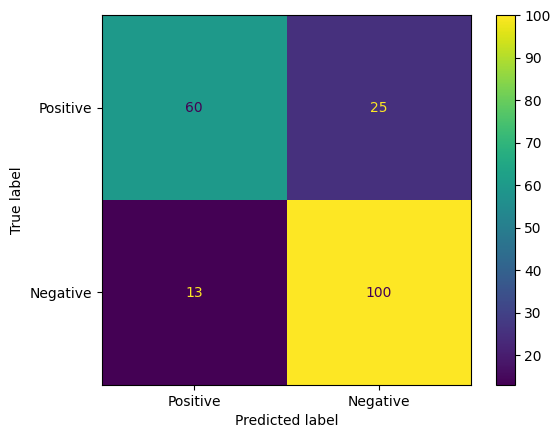
هناك طريقة أخرى مثيرة للاهتمام لتقييم توقّعات النموذج وهي مصفوفات التشويش. ستعرض مصفوفة نجاح التوقعات بشكل مرئي الأنواع المختلفة من أخطاء التوقّع.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
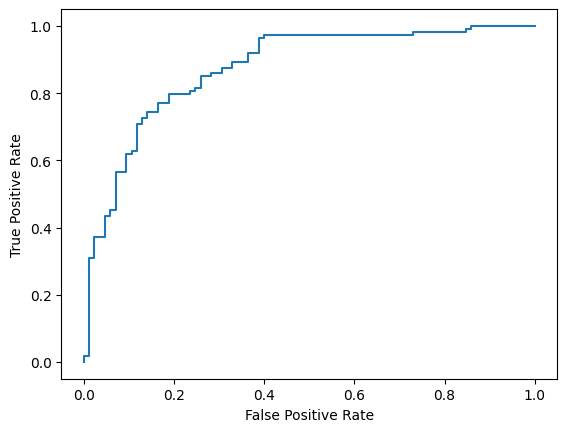
أخيرًا، يمكنك أيضًا الاطّلاع على منحنى ROC للتعرّف على أخطاء التوقّع المحتملة عند استخدام حدود تسجيل مختلفة.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()