1. Przegląd
W tym ćwiczeniu w Codelabs dowiesz się, jak utworzyć dostosowany klasyfikator tekstu za pomocą wydajnego dostrajania parametrów (PET). Metody PET nie wymagają dostrajania całego modelu, lecz tylko niewielkiej liczby parametrów, co sprawia, że trenowanie jest stosunkowo łatwe i szybkie. Ułatwia to też modelowi uczenie się nowych zachowań przy stosunkowo niewielkiej ilości danych treningowych. Metodologia została szczegółowo opisana w artykule Towards Agile Text Classifiers for Everyone, który pokazuje, jak można zastosować te techniki w różnych zadaniach związanych z bezpieczeństwem i osiągnąć najwyższą skuteczność przy użyciu zaledwie kilkuset przykładów szkoleniowych.
W tym samouczku używamy metody PET LoRA i mniejszego modelu Gemma (gemma_instruct_2b_en), ponieważ można go uruchamiać szybciej i wydajniej. W tym Colabie znajdziesz instrukcje dotyczące pozyskiwania danych, formatowania ich pod kątem LLM, trenowania wag LoRA i oceny wyników. W tym samouczku wykorzystujemy zbiór danych ETHOS, który jest publicznie dostępny i służy do wykrywania mowy nienawiści. Został on utworzony na podstawie komentarzy z YouTube i Reddita. Po wytrenowaniu na podstawie tylko 200 przykładów (1/4 zbioru danych) osiąga wyniki F1: 0,80 i ROC-AUC: 0,78, czyli nieco powyżej najlepszych wyników zgłoszonych obecnie na tablicy wyników (w momencie pisania tego tekstu, 15 lutego 2024 r.). Po wytrenowaniu na wszystkich 800 przykładach osiąga wynik F1 na poziomie 83,74 i wynik ROC-AUC na poziomie 88,17. Większe modele, takie jak gemma_instruct_7b_en, zwykle działają lepiej, ale koszty trenowania i wykonywania są też wyższe.
Ostrzeżenie: ten przewodnik zawiera przykłady i ocenę wyników, które mogą zawierać obraźliwe treści, ponieważ dotyczy tworzenia klasyfikatora bezpieczeństwa do wykrywania mowy nienawiści.
2. Instalacja i konfiguracja
Aby ukończyć ten kurs, potrzebujesz najnowszej wersji keras (3), keras-nlp (0.8.0) i konta Kaggle, aby pobrać model podstawowy.
!pip install -q -U keras-nlp
!pip install -q -U keras
Aby zalogować się w Kaggle, możesz zapisać plik z danymi logowania kaggle.json w lokalizacji ~/.kaggle/kaggle.json lub uruchomić w środowisku Colab to polecenie:
import kagglehub
kagglehub.login()
Ten samouczek został przetestowany przy użyciu TensorFlow jako backendu Keras, ale możesz użyć TensorFlow, PyTorch lub JAX:
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3. Wczytywanie zbioru danych ETHOS
W tej sekcji wczytasz zbiór danych, na którym wytrenujesz klasyfikator, i przetworzysz go wstępnie na zbiór treningowy i testowy. Użyjesz popularnego zbioru danych badawczych ETHOS, który został zebrany w celu wykrywania wypowiedzi szerzących nienawiść w mediach społecznościowych. Więcej informacji o sposobie zbierania danych znajdziesz w publikacji ETHOS: an Online Hate Speech Detection Dataset (ETHOS: zbiór danych do wykrywania mowy nienawiści w internecie).
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
Zobaczysz coś podobnego do tego:
etykieta | komentarz | |
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
4. Pobieranie i tworzenie instancji modelu
Jak opisano w dokumentacji, model Gemma możesz łatwo wykorzystać na wiele sposobów. W Kerasie musisz wykonać te czynności:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
Możesz sprawdzić, czy model działa, generując tekst:
model.generate('Question: what is the capital of France? ', max_length=32)
5. Przetwarzanie wstępne tekstu i tokeny separatora
Aby pomóc modelowi lepiej zrozumieć nasz zamiar, możesz wstępnie przetworzyć tekst i użyć tokenów separatora. Dzięki temu model rzadziej generuje tekst, który nie pasuje do oczekiwanego formatu. Możesz na przykład spróbować poprosić model o sklasyfikowanie sentymentu, pisząc prompta w ten sposób:
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
W takim przypadku model może, ale nie musi, wygenerować oczekiwane przez Ciebie wyniki. Jeśli na przykład tekst zawiera znaki nowego wiersza, prawdopodobnie wpłynie to negatywnie na wydajność modelu. Bardziej niezawodne podejście polega na użyciu tokenów separatora. Prompt będzie wyglądać tak:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
Możesz to uprościć za pomocą funkcji, która wstępnie przetwarza tekst:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
Jeśli teraz uruchomisz funkcję, używając tego samego prompta i tekstu co wcześniej, powinny pojawić się te same wyniki:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
Wynik powinien wyglądać tak:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
6. Przetwarzanie końcowe danych wyjściowych
Dane wyjściowe modelu to tokeny o różnych prawdopodobieństwach. Zwykle, aby wygenerować tekst, wybierasz kilka najbardziej prawdopodobnych tokenów i budujesz zdania, akapity lub nawet całe dokumenty. Na potrzeby klasyfikacji istotne jest jednak to, czy model uważa, że Positive jest bardziej prawdopodobne niż Negative, czy odwrotnie.
W przypadku utworzonego wcześniej modelu możesz przetworzyć jego dane wyjściowe na niezależne prawdopodobieństwa tego, czy następny token to Positive czy Negative:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
Możesz przetestować tę funkcję, uruchamiając ją za pomocą utworzonego wcześniej prompta:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
Wyświetli dane wyjściowe podobne do tych:
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
7. Łączenie wszystkiego w klasyfikator
Aby ułatwić sobie pracę, możesz połączyć wszystkie utworzone funkcje w jeden klasyfikator podobny do sklearn z łatwymi w użyciu i znanymi funkcjami, takimi jak predict() i predict_score().
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
8. Dostrajanie modelu
LoRA to skrót od Low-Rank Adaptation (adaptacja o niskim rzędzie). Jest to technika dostrajania, która umożliwia efektywne dostrajanie dużych modeli językowych. Więcej informacji znajdziesz w artykule LoRA: adaptacja o niskim rzędzie dużych modeli językowych.
Implementacja Gemma w Keras udostępnia metodę enable_lora(), której możesz użyć do dostrajania:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
Po włączeniu LoRA możesz rozpocząć proces dostrajania. Zajmuje to około 5 minut na epokę w Colab:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
Trenowanie przez większą liczbę epok zwiększy dokładność, dopóki nie nastąpi przeuczenie.
9. Sprawdzanie wyników
Możesz teraz sprawdzić wyniki wytrenowanego właśnie klasyfikatora elastycznego. Ten kod zwróci przewidywany wynik klasy dla danego fragmentu tekstu:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
10. Ocena modelu
Na koniec ocenisz skuteczność modelu za pomocą 2 popularnych danych: wyniku F1 i AUC-ROC. Wynik F1 uwzględnia błędy fałszywie negatywne i fałszywie pozytywne, oceniając średnią harmoniczną precyzji i czułości przy określonym progu klasyfikacji. Z kolei AUC-ROC pokazuje równowagę między współczynnikiem wyników prawdziwie pozytywnych a współczynnikiem wyników fałszywie pozytywnych w przypadku różnych wartości progowych i oblicza obszar pod tą krzywą.
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
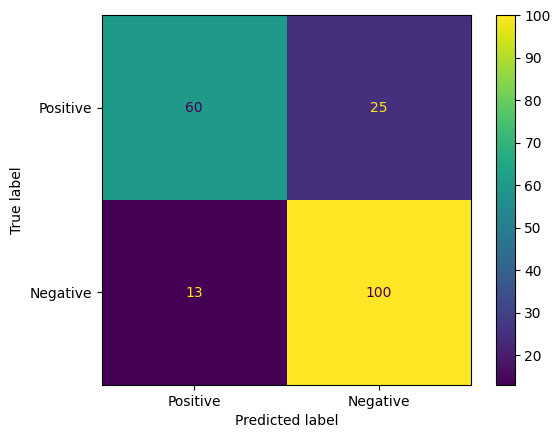
Innym ciekawym sposobem oceny prognoz modelu są tablice pomyłek. Tablica pomyłek przedstawia wizualnie różne rodzaje błędów prognozowania.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
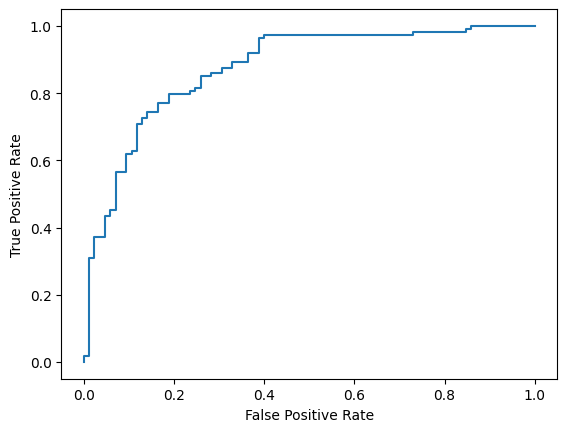
Możesz też sprawdzić krzywą ROC, aby poznać potencjalne błędy prognozowania przy użyciu różnych progów punktacji.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()