1. ภาพรวม
Codelab นี้แสดงวิธีสร้างเครื่องมือคัดแยกข้อความที่ปรับแต่งโดยใช้การปรับแต่งที่มีประสิทธิภาพของพารามิเตอร์ (PET) วิธีการ PET จะอัปเดตพารามิเตอร์เพียงเล็กน้อยเท่านั้นแทนที่จะปรับแต่งโมเดลทั้งหมด ซึ่งทำให้ฝึกได้ง่ายและรวดเร็ว นอกจากนี้ยังช่วยให้โมเดลเรียนรู้พฤติกรรมใหม่ๆ ได้ง่ายขึ้นด้วยข้อมูลการฝึกเพียงเล็กน้อย วิธีการนี้อธิบายไว้โดยละเอียดในTowards Agile Text Classifiers for Everyone ซึ่งแสดงให้เห็นว่าเทคนิคเหล่านี้สามารถนำไปใช้กับงานด้านความปลอดภัยต่างๆ และบรรลุประสิทธิภาพที่ล้ำสมัยด้วยตัวอย่างการฝึกเพียงไม่กี่ร้อยตัวอย่าง
Codelab นี้ใช้วิธี PET ของ LoRA และโมเดล Gemma ที่มีขนาดเล็กกว่า (gemma_instruct_2b_en) เนื่องจากสามารถเรียกใช้ได้เร็วขึ้นและมีประสิทธิภาพมากขึ้น Colab จะครอบคลุมขั้นตอนการนำเข้าข้อมูล การจัดรูปแบบข้อมูลสำหรับ LLM การฝึกน้ำหนัก LoRA และการประเมินผลลัพธ์ Codelab นี้ฝึกฝนเกี่ยวกับชุดข้อมูล ETHOS ซึ่งเป็นชุดข้อมูลที่เปิดเผยต่อสาธารณะสำหรับการตรวจจับการพูดที่สร้างความเกลียดชัง ซึ่งสร้างจากความคิดเห็นบน YouTube และ Reddit เมื่อฝึกด้วยตัวอย่างเพียง 200 รายการ (1/4 ของชุดข้อมูล) โมเดลจะให้ค่า F1 เท่ากับ 0.80 และ ROC-AUC เท่ากับ 0.78 ซึ่งสูงกว่า SOTA ที่รายงานในลีดเดอร์บอร์ดเล็กน้อย (ณ เวลาที่เขียนบทความนี้คือวันที่ 15 ก.พ. 2024) เมื่อฝึกกับตัวอย่างทั้ง 800 รายการ เช่น ได้คะแนน F1 ที่ 83.74 และคะแนน ROC-AUC ที่ 88.17 โมเดลขนาดใหญ่ เช่น gemma_instruct_7b_en มักจะทำงานได้ดีกว่า แต่ค่าใช้จ่ายในการฝึกและดำเนินการก็สูงกว่าด้วย
คำเตือนเกี่ยวกับเนื้อหาที่อาจสร้างความไม่สบายใจ: เนื่องจาก Codelab นี้พัฒนาเครื่องมือคัดแยกความปลอดภัยเพื่อตรวจจับคำพูดที่สร้างความเกลียดชัง ตัวอย่างและการประเมินผลลัพธ์จึงมีคำพูดที่น่ารังเกียจอยู่บ้าง
2. การติดตั้งและการตั้งค่า
สำหรับ Codelab นี้ คุณจะต้องมีเวอร์ชันล่าสุด keras (3), keras-nlp (0.8.0) และบัญชี Kaggle เพื่อดาวน์โหลดโมเดลพื้นฐาน
!pip install -q -U keras-nlp
!pip install -q -U keras
หากต้องการเข้าสู่ระบบ Kaggle คุณจะจัดเก็บไฟล์ข้อมูลเข้าสู่ระบบ kaggle.json ไว้ที่ ~/.kaggle/kaggle.json หรือเรียกใช้คำสั่งต่อไปนี้ในสภาพแวดล้อม Colab ก็ได้
import kagglehub
kagglehub.login()
เราทดสอบ Codelab นี้โดยใช้ TensorFlow เป็นแบ็กเอนด์ของ Keras แต่คุณจะใช้ TensorFlow, PyTorch หรือ JAX ก็ได้
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3. โหลดชุดข้อมูล ETHOS
ในส่วนนี้ คุณจะโหลดชุดข้อมูลที่จะใช้ฝึกเครื่องมือคัดแยก และประมวลผลล่วงหน้าเป็นชุดการฝึกและชุดทดสอบ คุณจะใช้ชุดข้อมูลการวิจัยยอดนิยม ETHOS ซึ่งรวบรวมขึ้นเพื่อตรวจจับการพูดแสดงความเกลียดชังในโซเชียลมีเดีย ดูข้อมูลเพิ่มเติมเกี่ยวกับวิธีรวบรวมชุดข้อมูลได้ในเอกสาร ETHOS: ชุดข้อมูลการตรวจจับวาจาสร้างความเกลียดชังออนไลน์
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
คุณจะเห็นข้อความคล้ายกับข้อความต่อไปนี้
ป้ายกำกับ | ความคิดเห็น | |
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
4. ดาวน์โหลดและสร้างอินสแตนซ์ของโมเดล
คุณใช้โมเดล Gemma ได้หลายวิธีอย่างง่ายดายตามที่อธิบายไว้ในเอกสารประกอบ หากใช้ Keras คุณจะต้องทำดังนี้
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
คุณทดสอบว่าโมเดลทำงานได้โดยสร้างข้อความดังนี้
model.generate('Question: what is the capital of France? ', max_length=32)
5. การประมวลผลข้อความเบื้องต้นและโทเค็นตัวคั่น
คุณสามารถประมวลผลข้อความล่วงหน้าและใช้โทเค็นตัวคั่นเพื่อให้โมเดลเข้าใจความตั้งใจของเราได้ดียิ่งขึ้น ซึ่งจะช่วยลดโอกาสที่โมเดลจะสร้างข้อความที่ไม่ตรงกับรูปแบบที่คาดไว้ เช่น คุณอาจพยายามขอการจัดประเภทความรู้สึกจากโมเดลโดยเขียนพรอมต์ดังนี้
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
ในกรณีนี้ โมเดลอาจแสดงผลลัพธ์ที่คุณต้องการหรือไม่ก็ได้ เช่น หากข้อความมีอักขระขึ้นบรรทัดใหม่ ก็มีแนวโน้มที่จะส่งผลเสียต่อประสิทธิภาพของโมเดล แนวทางที่มีประสิทธิภาพมากกว่าคือการใช้โทเค็นตัวคั่น จากนั้นพรอมต์จะเปลี่ยนเป็น
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
ซึ่งสามารถแยกออกได้โดยใช้ฟังก์ชันที่ประมวลผลข้อความล่วงหน้า ดังนี้
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
ตอนนี้หากเรียกใช้ฟังก์ชันโดยใช้พรอมต์และข้อความเดียวกันกับก่อนหน้านี้ คุณควรจะได้รับเอาต์พุตเดียวกัน
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
ซึ่งควรแสดงผลดังนี้
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
6. การประมวลผลเอาต์พุตภายหลัง
เอาต์พุตของโมเดลคือโทเค็นที่มีความน่าจะเป็นต่างๆ โดยปกติแล้ว หากต้องการสร้างข้อความ คุณจะต้องเลือกโทเค็นที่มีแนวโน้มมากที่สุด 2-3 อันดับแรกและสร้างประโยค ย่อหน้า หรือแม้แต่เอกสารทั้งฉบับ อย่างไรก็ตาม สำหรับวัตถุประสงค์ในการจัดประเภท สิ่งที่สำคัญจริงๆ คือโมเดลเชื่อว่า Positive มีแนวโน้มมากกว่า Negative หรือในทางกลับกัน
เมื่อพิจารณาจากโมเดลที่คุณสร้างอินสแตนซ์ก่อนหน้านี้ คุณจะประมวลผลเอาต์พุตเป็นความน่าจะเป็นอิสระที่ระบุว่าโทเค็นถัดไปคือ Positive หรือ Negative ได้ดังนี้
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
คุณทดสอบฟังก์ชันดังกล่าวได้โดยเรียกใช้ด้วยพรอมต์ที่สร้างไว้ก่อนหน้านี้
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
ซึ่งจะแสดงผลลัพธ์ที่คล้ายกับตัวอย่างต่อไปนี้
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
7. การรวมทุกอย่างเป็นตัวแยกประเภท
เพื่อให้ใช้งานได้ง่าย คุณสามารถรวมฟังก์ชันทั้งหมดที่เพิ่งสร้างขึ้นเป็นเครื่องมือจัดประเภทเดียวที่คล้ายกับ sklearn โดยมีฟังก์ชันที่ใช้งานง่ายและคุ้นเคย เช่น predict() และ predict_score()
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
8. การปรับแต่งโมเดล
LoRA ย่อมาจาก Low-Rank Adaptation เป็นเทคนิคการปรับแต่งที่ใช้เพื่อปรับแต่งโมเดลภาษาขนาดใหญ่ได้อย่างมีประสิทธิภาพ คุณสามารถอ่านข้อมูลเพิ่มเติมได้ในเอกสาร LoRA: Low-Rank Adaptation of Large Language Models
การใช้งาน Gemma ใน Keras มีenable_lora()วิธีที่คุณใช้สำหรับการปรับแต่งได้ ดังนี้
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
หลังจากเปิดใช้ LoRA แล้ว คุณจะเริ่มกระบวนการปรับแต่งได้ โดยจะใช้เวลาประมาณ 5 นาทีต่อ Epoch ใน Colab
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
การฝึกสำหรับจำนวน Epoch ที่มากขึ้นจะส่งผลให้มีความแม่นยำสูงขึ้นจนกว่าจะเกิดการปรับมากเกินไป
9. ตรวจสอบผลลัพธ์
ตอนนี้คุณสามารถตรวจสอบเอาต์พุตของเครื่องมือคัดแยกแบบ Agile ที่เพิ่งฝึกได้แล้ว โค้ดนี้จะแสดงคะแนนของคลาสที่คาดการณ์ไว้เมื่อได้รับข้อความ
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
10. การประเมินโมเดล
สุดท้าย คุณจะประเมินประสิทธิภาพของโมเดลโดยใช้เมตริกทั่วไป 2 รายการ ได้แก่ คะแนน F1 และ AUC-ROC คะแนน F1 จะบันทึกข้อผิดพลาดของผลลบลวงและผลบวกลวงโดยการประเมินค่าเฉลี่ยฮาร์โมนิกของความแม่นยำและความอ่อนไหวที่เกณฑ์การจัดประเภทหนึ่งๆ ในทางกลับกัน AUC-ROC จะบันทึกการทดแทนกันระหว่างอัตราผลบวกจริงกับอัตราผลบวกลวงในเกณฑ์ต่างๆ และคำนวณพื้นที่ใต้กราฟนี้
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
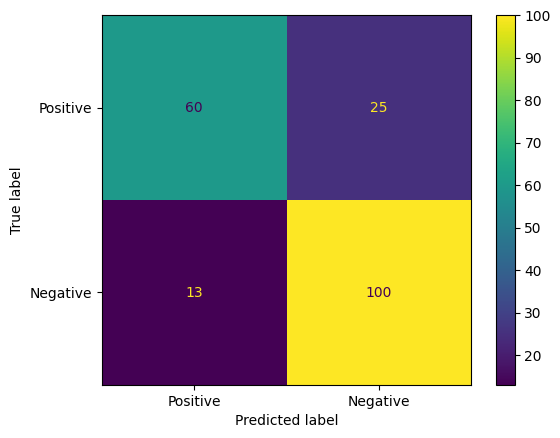
อีกวิธีที่น่าสนใจในการประเมินการคาดการณ์ของโมเดลคือเมทริกซ์ความสับสน เมทริกซ์ความสับสนจะแสดงข้อผิดพลาดในการคาดการณ์ประเภทต่างๆ ในรูปแบบภาพ
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
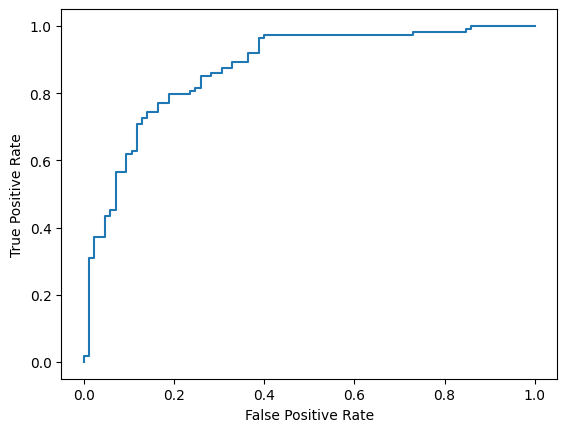
สุดท้ายนี้ คุณยังดูเส้นโค้ง ROC เพื่อดูข้อผิดพลาดในการคาดการณ์ที่อาจเกิดขึ้นเมื่อใช้เกณฑ์การให้คะแนนต่างๆ ได้ด้วย
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()