1. Descripción general
En este codelab, se ilustra cómo crear un clasificador de texto personalizado con ajustes eficientes en cuanto a parámetros (PET). En lugar de ajustar todo el modelo, los métodos PET solo actualizan una pequeña cantidad de parámetros, lo que hace que el entrenamiento sea relativamente fácil y rápido. También facilita que un modelo aprenda comportamientos nuevos con relativamente pocos datos de entrenamiento. La metodología se describe en detalle en Towards Agile Text Classifiers for Everyone, que muestra cómo se pueden aplicar estas técnicas a una variedad de tareas de seguridad y lograr un rendimiento de vanguardia con solo unos cientos de ejemplos de entrenamiento.
En este codelab, se usa el método PET LoRA y el modelo Gemma más pequeño (gemma_instruct_2b_en), ya que se puede ejecutar de forma más rápida y eficiente. En el Colab, se explican los pasos para ingerir datos, darles formato para el LLM, entrenar los pesos de LoRA y, luego, evaluar los resultados. En este codelab, se entrena con el conjunto de datos ETHOS, un conjunto de datos disponible públicamente para detectar el discurso de odio, creado a partir de comentarios de YouTube y Reddit. Cuando se entrena con solo 200 ejemplos (1/4 del conjunto de datos), alcanza un F1 de 0.80 y un AUC de ROC de 0.78, ligeramente por encima del SOTA que se informa actualmente en el ranking (en el momento de la redacción, el 15 de febrero de 2024). Cuando se entrena con los 800 ejemplos completos, alcanza una puntuación F1 de 83.74 y una puntuación ROC-AUC de 88.17. Por lo general, los modelos más grandes, como gemma_instruct_7b_en, tienen un mejor rendimiento, pero los costos de entrenamiento y ejecución también son más altos.
Advertencia de contenido sensible: Debido a que este codelab desarrolla un clasificador de seguridad para detectar el discurso de odio, los ejemplos y la evaluación de los resultados contienen lenguaje horrible.
2. Instalación y configuración
Para este codelab, necesitarás una versión reciente de keras (3), keras-nlp (0.8.0) y una cuenta de Kaggle para descargar el modelo base.
!pip install -q -U keras-nlp
!pip install -q -U keras
Para acceder a Kaggle, puedes almacenar tu archivo de credenciales kaggle.json en ~/.kaggle/kaggle.json o ejecutar lo siguiente en un entorno de Colab:
import kagglehub
kagglehub.login()
Este codelab se probó con TensorFlow como backend de Keras, pero puedes usar TensorFlow, PyTorch o JAX:
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3. Carga el conjunto de datos de ETHOS
En esta sección, cargarás el conjunto de datos con el que entrenaremos nuestro clasificador y lo preprocesarás en un conjunto de entrenamiento y prueba. Usarás el popular conjunto de datos de investigación ETHOS, que se recopiló para detectar el discurso de odio en las redes sociales. Puedes encontrar más información sobre cómo se recopiló el conjunto de datos en el documento ETHOS: an Online Hate Speech Detection Dataset.
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
Verás un resultado similar al siguiente:
etiqueta | comentario | |
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
4. Descarga el modelo y crea una instancia
Como se describe en la documentación, puedes usar el modelo de Gemma de muchas maneras. Con Keras, debes hacer lo siguiente:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
Para probar que el modelo funciona, genera algo de texto:
model.generate('Question: what is the capital of France? ', max_length=32)
5. Procesamiento previo de texto y tokens de separador
Para ayudar al modelo a comprender mejor nuestra intención, puedes preprocesar el texto y usar tokens de separador. Esto hace que sea menos probable que el modelo genere texto que no se ajuste al formato esperado. Por ejemplo, puedes intentar solicitar una clasificación de opiniones al modelo escribiendo una instrucción como esta:
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
En este caso, es posible que el modelo genere o no lo que buscas. Por ejemplo, si el texto contiene caracteres de salto de línea, es probable que tenga un efecto negativo en el rendimiento del modelo. Un enfoque más sólido es usar tokens de separador. Luego, la instrucción se convierte en la siguiente:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
Esto se puede abstraer con una función que preprocese el texto:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
Ahora, si ejecutas la función con la misma instrucción y el mismo texto que antes, deberías obtener el mismo resultado:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
El resultado debería ser el siguiente:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
6. Posprocesamiento de la salida
Los resultados del modelo son tokens con varias probabilidades. Normalmente, para generar texto, seleccionarías entre los pocos tokens más probables y construirías oraciones, párrafos o incluso documentos completos. Sin embargo, para la clasificación, lo que realmente importa es si el modelo cree que Positive es más probable que Negative o viceversa.
Dado el modelo que creaste una instancia anteriormente, así es como puedes procesar su salida en las probabilidades independientes de si el siguiente token es Positive o Negative:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
Puedes probar esa función ejecutándola con la instrucción que creaste antes:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
Esto generará un resultado similar al siguiente:
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
7. Cómo unir todo como un clasificador
Para facilitar el uso, puedes unir todas las funciones que acabas de crear en un solo clasificador similar a sklearn con funciones conocidas y fáciles de usar, como predict() y predict_score().
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
8. Ajuste del modelo
LoRA significa Low-Rank Adaptation (adaptación de bajo rango). Es una técnica de ajuste que se puede usar para ajustar de manera eficiente los modelos de lenguaje grandes. Puedes obtener más información al respecto en el artículo LoRA: Low-Rank Adaptation of Large Language Models.
La implementación de Gemma en Keras proporciona un método enable_lora() que puedes usar para el ajuste fino:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
Después de habilitar LoRA, puedes comenzar el proceso de ajuste. Este proceso tarda aproximadamente 5 minutos por época en Colab:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
Entrenar el modelo durante más ciclos de entrenamiento generará una mayor precisión hasta que se produzca un sobreajuste.
9. Inspecciona los resultados
Ahora puedes inspeccionar el resultado del clasificador ágil que acabas de entrenar. Este código generará la puntuación de la clase predicha para un fragmento de texto:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
10. Evaluación de modelos
Por último, evaluarás el rendimiento de nuestro modelo con dos métricas comunes: la puntuación F1 y el AUC-ROC. La puntuación F1 captura los errores de falsos negativos y falsos positivos evaluando la media armónica de la precisión y la recuperación en un determinado umbral de clasificación. Por otro lado, el AUC-ROC captura la compensación entre la tasa de verdaderos positivos y la tasa de falsos positivos en una variedad de umbrales, y calcula el área bajo esta curva.
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
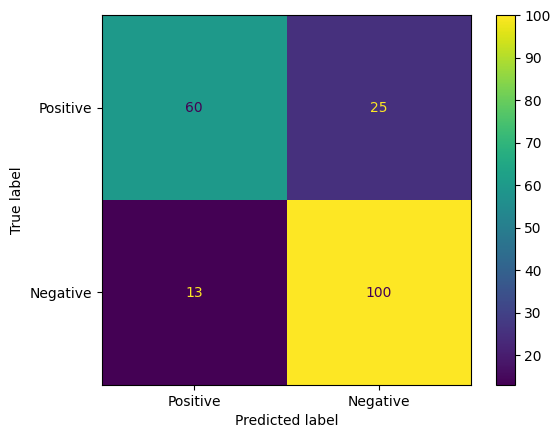
Otra forma interesante de evaluar las predicciones del modelo son las matrices de confusión. Una matriz de confusión representará visualmente los diferentes tipos de errores de predicción.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
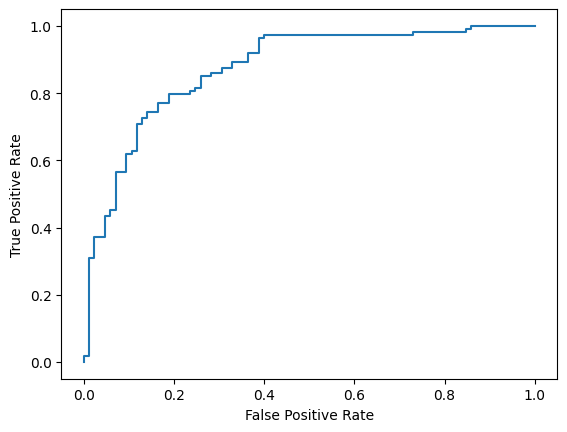
Por último, también puedes consultar la curva ROC para tener una idea de los posibles errores de predicción cuando se usan diferentes umbrales de puntuación.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()