1. Panoramica
Questo codelab illustra come creare un classificatore di testo personalizzato utilizzando il tuning efficiente dei parametri (PET). Anziché ottimizzare l'intero modello, i metodi PET aggiornano solo una piccola quantità di parametri, il che rende l'addestramento relativamente facile e veloce. Inoltre, consente a un modello di apprendere nuovi comportamenti con dati di addestramento relativamente scarsi. La metodologia è descritta in dettaglio in Towards Agile Text Classifiers for Everyone, che mostra come queste tecniche possono essere applicate a una serie di attività di sicurezza e ottenere prestazioni all'avanguardia con solo poche centinaia di esempi di addestramento.
Questo codelab utilizza il metodo PET LoRA e il modello Gemma più piccolo (gemma_instruct_2b_en), in quanto può essere eseguito in modo più rapido ed efficiente. Il colab illustra i passaggi per l'importazione dei dati, la loro formattazione per il modello LLM, l'addestramento dei pesi LoRA e la valutazione dei risultati. Questo codelab si basa sul set di dati ETHOS, un set di dati disponibile pubblicamente per il rilevamento di discorsi incitanti all'odio, creato a partire dai commenti di YouTube e Reddit. Quando viene addestrato su soli 200 esempi (1/4 del set di dati), raggiunge F1: 0,80 e ROC-AUC: 0,78, leggermente al di sopra dello stato dell'arte attualmente riportato nella classifica (al momento della stesura, 15 febbraio 2024). Quando viene addestrato su tutti gli 800 esempi, ottiene un punteggio F1 di 83,74 e un punteggio ROC-AUC di 88,17. I modelli più grandi, come gemma_instruct_7b_en, in genere hanno un rendimento migliore, ma anche i costi di addestramento ed esecuzione sono maggiori.
Avviso: poiché questo codelab sviluppa un classificatore di sicurezza per il rilevamento di discorsi carichi di odio, gli esempi e la valutazione dei risultati contengono un linguaggio orribile.
2. Installazione e configurazione
Per questo codelab, avrai bisogno di una versione recente keras (3), keras-nlp (0.8.0) e di un account Kaggle per scaricare il modello di base.
!pip install -q -U keras-nlp
!pip install -q -U keras
Per accedere a Kaggle, puoi memorizzare il file delle credenziali kaggle.json in ~/.kaggle/kaggle.json o eseguire il seguente comando in un ambiente Colab:
import kagglehub
kagglehub.login()
Questo codelab è stato testato utilizzando TensorFlow come backend Keras, ma puoi utilizzare TensorFlow, PyTorch o JAX:
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3. Carica il set di dati ETHOS
In questa sezione caricherai il set di dati su cui addestrare il classificatore e lo pre-elaborerai in un set di addestramento e test. Utilizzerai il popolare set di dati di ricerca ETHOS, raccolto per rilevare i discorsi di odio sui social media. Puoi trovare ulteriori informazioni su come è stato raccolto il set di dati nell'articolo ETHOS: an Online Hate Speech Detection Dataset.
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
Visualizzerai un messaggio simile a questo:
etichetta | commento | |
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
4. Scaricare e creare un'istanza del modello
Come descritto nella documentazione, puoi utilizzare facilmente il modello Gemma in molti modi. Con Keras, ecco cosa devi fare:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
Puoi verificare che il modello funzioni generando del testo:
model.generate('Question: what is the capital of France? ', max_length=32)
5. Pre-elaborazione del testo e token separatori
Per aiutare il modello a comprendere meglio la nostra intenzione, puoi preelaborare il testo e utilizzare token separatori. In questo modo, è meno probabile che il modello generi testo che non corrisponde al formato previsto. Ad esempio, potresti tentare di richiedere una classificazione del sentiment al modello scrivendo un prompt come questo:
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
In questo caso, il modello potrebbe o meno restituire ciò che stai cercando. Ad esempio, se il testo contiene caratteri di nuova riga, è probabile che influisca negativamente sul rendimento del modello. Un approccio più efficace consiste nell'utilizzare i token separatori. Il prompt diventa quindi:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
Questo può essere estratto utilizzando una funzione che preelabora il testo:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
Ora, se esegui la funzione utilizzando lo stesso prompt e lo stesso testo di prima, dovresti ottenere lo stesso output:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
che dovrebbe restituire:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
6. Post-elaborazione dell'output
Gli output del modello sono token con varie probabilità. Normalmente, per generare testo, si selezionano i primi token più probabili e si costruiscono frasi, paragrafi o persino documenti completi. Tuttavia, ai fini della classificazione, ciò che conta davvero è se il modello ritiene che Positive sia più probabile di Negative o viceversa.
Dato il modello che hai istanziato in precedenza, ecco come puoi elaborare il suo output nelle probabilità indipendenti che il token successivo sia Positive o Negative:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
Puoi testare la funzione eseguendola con il prompt che hai creato in precedenza:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
che genererà un output simile al seguente:
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
7. Raggruppare tutto come classificatore
Per facilità d'uso, puoi raggruppare tutte le funzioni che hai appena creato in un unico classificatore simile a sklearn con funzioni facili da usare e familiari come predict() e predict_score().
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
8. Ottimizzazione del modello
LoRA è l'acronimo di Low-Rank Adaptation. Si tratta di una tecnica di ottimizzazione che può essere utilizzata per ottimizzare in modo efficiente i modelli linguistici di grandi dimensioni. Per saperne di più, consulta l'articolo LoRA: Low-Rank Adaptation of Large Language Models.
L'implementazione di Gemma in Keras fornisce un metodo enable_lora() che puoi utilizzare per il fine-tuning:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
Dopo aver attivato LoRA, puoi iniziare la procedura di perfezionamento. L'operazione richiede circa 5 minuti per epoca su Colab:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
L'addestramento per un numero maggiore di epoche comporterà una maggiore accuratezza, fino a quando non si verifica l'overfitting.
9. Esaminare i risultati
Ora puoi esaminare l'output del classificatore agile che hai appena addestrato. Questo codice restituirà il punteggio della classe prevista dato un testo:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
10. valutazione del modello
Infine, valuterai le prestazioni del nostro modello utilizzando due metriche comuni, lo score F1 e l'AUC-ROC. Il punteggio F1 acquisisce gli errori di falsi negativi e falsi positivi valutando la media armonica di precisione e richiamo a una determinata soglia di classificazione. L'AUC-ROC, invece, acquisisce il tradeoff tra il tasso di veri positivi e il tasso di falsi positivi in una serie di soglie e calcola l'area sotto questa curva.
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
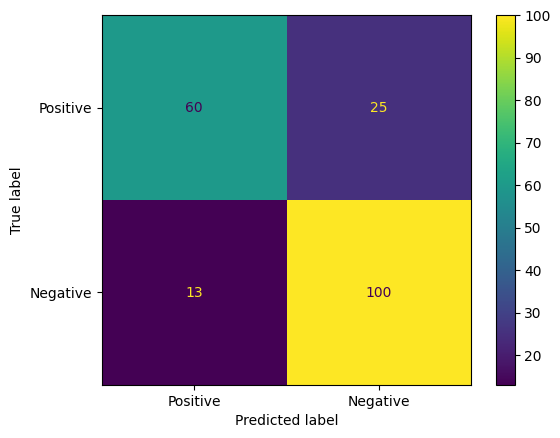
Un altro modo interessante per valutare le previsioni del modello sono le matrici di confusione. Una matrice di confusione mostrerà visivamente i diversi tipi di errori di previsione.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
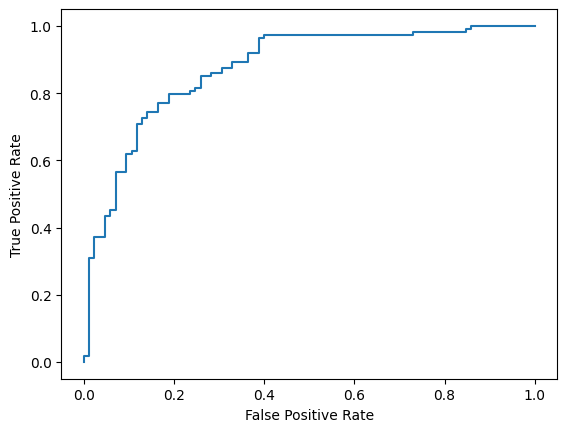
Infine, puoi anche esaminare la curva ROC per farti un'idea dei potenziali errori di previsione quando utilizzi soglie di punteggio diverse.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()