1. Tổng quan
Lớp học lập trình này minh hoạ cách tạo một trình phân loại văn bản tuỳ chỉnh bằng cách sử dụng phương pháp điều chỉnh hiệu quả tham số (PET). Thay vì tinh chỉnh toàn bộ mô hình, các phương pháp PET chỉ cập nhật một lượng nhỏ tham số, giúp việc huấn luyện trở nên tương đối dễ dàng và nhanh chóng. Điều này cũng giúp mô hình dễ dàng học được các hành vi mới với tương đối ít dữ liệu huấn luyện. Phương pháp này được mô tả chi tiết trong Hướng tới các trình phân loại văn bản linh hoạt cho mọi người. Bài viết này cho thấy cách áp dụng các kỹ thuật này cho nhiều nhiệm vụ an toàn và đạt được hiệu suất hiện đại chỉ với vài trăm ví dụ huấn luyện.
Lớp học lập trình này sử dụng phương thức PET LoRA và mô hình Gemma nhỏ hơn (gemma_instruct_2b_en) vì có thể chạy nhanh hơn và hiệu quả hơn. Colab này trình bày các bước nhập dữ liệu, định dạng dữ liệu cho LLM, huấn luyện trọng số LoRA, rồi đánh giá kết quả. Lớp học lập trình này đào tạo về tập dữ liệu ETHOS, một tập dữ liệu công khai để phát hiện lời nói hận thù, được xây dựng từ bình luận trên YouTube và Reddit. Khi được huấn luyện chỉ trên 200 ví dụ (1/4 tập dữ liệu), mô hình này đạt F1: 0,80 và ROC-AUC: 0,78, cao hơn một chút so với SOTA hiện được báo cáo trên bảng xếp hạng (tại thời điểm viết bài, ngày 15 tháng 2 năm 2024). Khi được huấn luyện trên 800 ví dụ đầy đủ, mô hình này đạt điểm F1 là 83,74 và điểm ROC-AUC là 88,17. Các mô hình lớn hơn, chẳng hạn như gemma_instruct_7b_en, thường hoạt động hiệu quả hơn, nhưng chi phí huấn luyện và thực thi cũng lớn hơn.
Cảnh báo nội dung nhạy cảm: vì lớp học lập trình này phát triển một trình phân loại an toàn để phát hiện lời nói hận thù, nên các ví dụ và kết quả đánh giá có chứa một số ngôn từ thô tục.
2. Cài đặt và thiết lập
Đối với lớp học lập trình này, bạn sẽ cần một phiên bản keras (3), keras-nlp (0.8.0) gần đây và một tài khoản Kaggle để tải mô hình cơ sở xuống.
!pip install -q -U keras-nlp
!pip install -q -U keras
Để đăng nhập vào Kaggle, bạn có thể lưu tệp thông tin đăng nhập kaggle.json tại ~/.kaggle/kaggle.json hoặc chạy lệnh sau trong môi trường Colab:
import kagglehub
kagglehub.login()
Lớp học lập trình này được kiểm thử bằng Tensorflow làm phần phụ trợ Keras, nhưng bạn có thể sử dụng Tensorflow, Pytorch hoặc JAX:
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3. Tải tập dữ liệu ETHOS
Trong phần này, bạn sẽ tải tập dữ liệu mà bạn muốn dùng để huấn luyện thuật toán phân loại và xử lý trước tập dữ liệu đó thành một tập huấn luyện và tập kiểm định. Bạn sẽ sử dụng tập dữ liệu nghiên cứu phổ biến ETHOS. Tập dữ liệu này được thu thập để phát hiện lời nói hận thù trên mạng xã hội. Bạn có thể tìm thêm thông tin về cách thu thập tập dữ liệu này trong bài viết ETHOS: an Online Hate Speech Detection Dataset (ETHOS: tập dữ liệu phát hiện lời nói hận thù trên mạng).
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
Bạn sẽ thấy nội dung tương tự như sau:
nhãn | bình luận | |
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
4. Tải xuống và tạo thực thể mô hình
Như mô tả trong tài liệu, bạn có thể dễ dàng sử dụng mô hình Gemma theo nhiều cách. Với Keras, bạn cần làm như sau:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
Bạn có thể kiểm thử xem mô hình có hoạt động hay không bằng cách tạo một số văn bản:
model.generate('Question: what is the capital of France? ', max_length=32)
5. Xử lý trước văn bản và mã phân tách
Để giúp mô hình hiểu rõ hơn ý định của chúng ta, bạn có thể tiền xử lý văn bản và sử dụng mã thông báo phân cách. Điều này giúp giảm khả năng mô hình tạo ra văn bản không đúng định dạng theo yêu cầu. Ví dụ: bạn có thể cố gắng yêu cầu mô hình phân loại cảm xúc bằng cách viết một câu lệnh như sau:
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
Trong trường hợp này, mô hình có thể đưa ra hoặc không đưa ra kết quả bạn đang tìm kiếm. Ví dụ: nếu văn bản chứa các ký tự dòng mới, thì văn bản đó có thể ảnh hưởng tiêu cực đến hiệu suất của mô hình. Một phương pháp mạnh mẽ hơn là sử dụng mã thông báo dấu phân cách. Sau đó, lời nhắc sẽ trở thành:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
Bạn có thể trừu tượng hoá điều này bằng cách sử dụng một hàm tiền xử lý văn bản:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
Giờ đây, nếu chạy hàm bằng cùng một câu lệnh và văn bản như trước, bạn sẽ nhận được kết quả tương tự:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
Kết quả sẽ là:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
6. Xử lý hậu kỳ đầu ra
Đầu ra của mô hình là các mã thông báo với nhiều xác suất. Thông thường, để tạo văn bản, bạn sẽ chọn trong số ít mã thông báo có khả năng xuất hiện cao nhất và tạo câu, đoạn văn hoặc thậm chí là toàn bộ tài liệu. Tuy nhiên, đối với mục đích phân loại, điều thực sự quan trọng là liệu mô hình có tin rằng Positive có khả năng xảy ra hơn Negative hay ngược lại.
Với mô hình mà bạn đã khởi tạo trước đó, đây là cách bạn có thể xử lý đầu ra của mô hình thành các xác suất độc lập về việc mã thông báo tiếp theo là Positive hay Negative:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
Bạn có thể kiểm thử hàm đó bằng cách chạy hàm với câu lệnh mà bạn đã tạo trước đó:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
Thao tác này sẽ xuất ra nội dung tương tự như sau:
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
7. Gói tất cả dưới dạng một Trình phân loại
Để dễ sử dụng, bạn có thể gói tất cả các hàm mà bạn vừa tạo vào một trình phân loại duy nhất giống như sklearn với các hàm quen thuộc và dễ sử dụng như predict() và predict_score().
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
8. Tinh chỉnh mô hình
LoRA là viết tắt của Low-Rank Adaptation (Thích ứng cấp thấp). Đây là một kỹ thuật tinh chỉnh có thể được dùng để tinh chỉnh hiệu quả các mô hình ngôn ngữ lớn. Bạn có thể đọc thêm về vấn đề này trong tài liệu LoRA: Thích ứng thứ hạng thấp của các mô hình ngôn ngữ lớn.
Việc triển khai Gemma bằng Keras cung cấp một phương thức enable_lora() mà bạn có thể dùng để tinh chỉnh:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
Sau khi bật LoRA, bạn có thể bắt đầu quy trình tinh chỉnh. Quá trình này mất khoảng 5 phút cho mỗi giai đoạn trên Colab:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
Việc huấn luyện trong nhiều giai đoạn sẽ giúp tăng độ chính xác cho đến khi xảy ra tình trạng khớp quá mức.
9. Kiểm tra kết quả
Giờ đây, bạn có thể kiểm tra đầu ra của trình phân loại linh hoạt mà bạn vừa huấn luyện. Đoạn mã này sẽ xuất điểm số của lớp được dự đoán cho một đoạn văn bản:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
10. Đánh giá mô hình
Cuối cùng, bạn sẽ đánh giá hiệu suất của mô hình bằng cách sử dụng 2 chỉ số phổ biến là điểm F1 và AUC-ROC. Điểm F1 ghi lại các lỗi âm tính giả và dương tính giả bằng cách đánh giá trung bình điều hoà của độ chính xác và khả năng thu hồi tại một ngưỡng phân loại nhất định. Mặt khác, AUC-ROC ghi lại sự đánh đổi giữa tỷ lệ dương tính thực và tỷ lệ dương tính giả trên nhiều ngưỡng và tính toán diện tích dưới đường cong này.
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
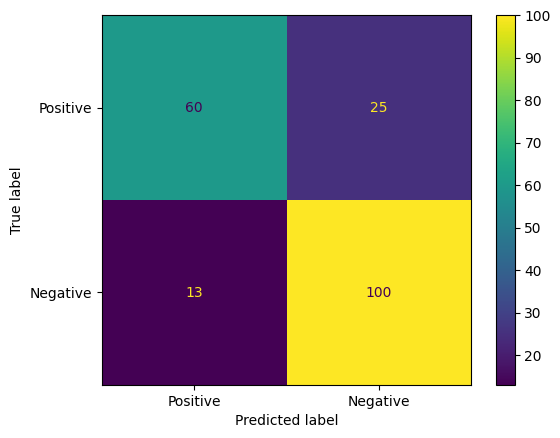
Một cách thú vị khác để đánh giá các dự đoán của mô hình là ma trận nhầm lẫn. Ma trận nhầm lẫn sẽ mô tả trực quan các loại lỗi dự đoán.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
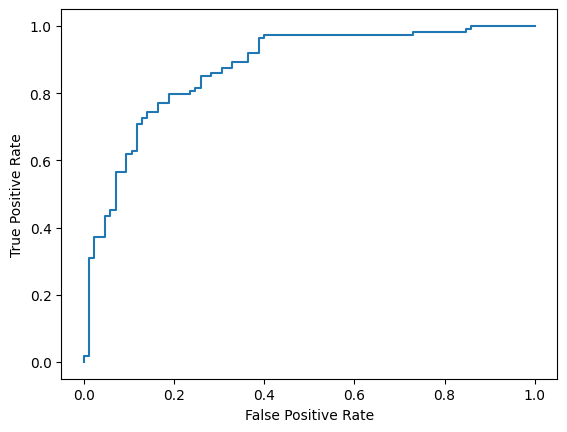
Cuối cùng, bạn cũng có thể xem đường cong ROC để nắm được các lỗi dự đoán tiềm ẩn khi sử dụng các ngưỡng tính điểm khác nhau.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()