1. Обзор
В этом практическом занятии показано, как создать настраиваемый текстовый классификатор с использованием параметрически эффективной настройки (PET). Вместо тонкой настройки всей модели, методы PET обновляют лишь небольшое количество параметров, что делает обучение относительно простым и быстрым. Это также упрощает обучение модели новым моделям поведения при относительно небольшом объеме обучающих данных. Методология подробно описана в статье «К созданию гибких текстовых классификаторов для всех» , где показано, как эти методы могут быть применены к различным задачам безопасности и достичь передовых результатов всего лишь с несколькими сотнями обучающих примеров.
В этом практическом занятии используется метод LoRA PET и уменьшенная модель Gemma ( gemma_instruct_2b_en ), поскольку она работает быстрее и эффективнее. Занятие охватывает этапы загрузки данных, их форматирования для LLM, обучения весов LoRA и последующей оценки результатов. Обучение проводится на наборе данных ETHOS , общедоступном наборе данных для обнаружения ненавистнических высказываний, созданном на основе комментариев YouTube и Reddit. При обучении всего на 200 примерах (1/4 набора данных) достигается показатель F1: 0,80 и ROC-AUC: 0,78, что немного выше текущего показателя, зафиксированного в таблице лидеров (на момент написания, 15 февраля 2024 г.). При обучении на всех 800 примерах достигается показатель F1 83,74 и показатель ROC-AUC 88,17. Более крупные модели, такие как gemma_instruct_7b_en как правило, показывают лучшие результаты, но при этом увеличиваются затраты на обучение и выполнение.
Предупреждение : поскольку в этом практическом занятии разрабатывается классификатор безопасности для обнаружения разжигающих ненависть высказываний, примеры и оценка результатов содержат нецензурную лексику.
2. Установка и настройка
Для выполнения этого практического задания вам потребуется последняя версия keras (3), keras-nlp (0.8.0) и учетная запись Kaggle для загрузки базовой модели.
!pip install -q -U keras-nlp
!pip install -q -U keras
Для входа в Kaggle вы можете либо сохранить файл учетных данных kaggle.json в папке ~/.kaggle/kaggle.json , либо выполнить следующую команду в среде Colab:
import kagglehub
kagglehub.login()
Данный практический пример был протестирован с использованием TensorFlow в качестве бэкенда Keras, но вы можете использовать TensorFlow, PyTorch или JAX:
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3. Загрузите набор данных ETHOS.
В этом разделе вы загрузите набор данных для обучения нашего классификатора и предварительно обработаете его, разделив на обучающую и тестовую выборки. Вы будете использовать популярный исследовательский набор данных ETHOS, собранный для обнаружения разжигающих ненависть высказываний в социальных сетях. Более подробную информацию о том, как был собран этот набор данных, можно найти в статье ETHOS: an Online Hate Speech Detection Dataset .
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
Вы увидите нечто подобное:
этикетка | комментарий | |
0 | | |
1 | | |
2 | | |
3 | | |
4 | | |
4. Загрузите и создайте экземпляр модели.
Как описано в документации , модель Gemma можно легко использовать различными способами. В Keras для этого нужно сделать следующее:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
Проверить работоспособность модели можно, сгенерировав текст:
model.generate('Question: what is the capital of France? ', max_length=32)
5. Предварительная обработка текста и разделительные токены
Чтобы помочь модели лучше понять наши намерения, вы можете предварительно обработать текст и использовать разделительные токены. Это снизит вероятность того, что модель сгенерирует текст, не соответствующий ожидаемому формату. Например, вы можете попытаться запросить у модели классификацию тональности, написав запрос примерно такого вида:
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
В этом случае модель может выдать то, что вы ищете, а может и нет. Например, если текст содержит символы новой строки, это, вероятно, негативно повлияет на производительность модели. Более надежный подход — использовать разделительные токены. Тогда запрос будет выглядеть так:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
Это можно упростить, используя функцию предварительной обработки текста:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
Теперь, если вы запустите функцию, используя ту же подсказку и текст, что и раньше, вы должны получить тот же результат:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
В результате должно получиться следующее:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
6. Постобработка выходных данных
Выходные данные модели представляют собой токены с различными вероятностями. Обычно для генерации текста выбираются несколько наиболее вероятных токенов, из которых формируются предложения, абзацы или даже целые документы. Однако для целей классификации важно то, считает ли модель, что Positive вариант более вероятен, чем Negative , или наоборот.
Исходя из созданной вами ранее модели, вы можете преобразовать ее выходные данные в независимые вероятности того, будет ли следующий токен Positive или Negative :
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
Вы можете протестировать эту функцию, запустив её с помощью созданной вами ранее командной строки:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
В результате получится что-то похожее на следующее:
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
7. Объединив все это в классификатор.
Для удобства использования вы можете объединить все только что созданные функции в один классификатор, подобный sklearn, с простыми в использовании и знакомыми функциями, такими как predict() и predict_score() .
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
8. Тонкая настройка модели
LoRA расшифровывается как Low-Rank Adaptation (адаптация низкого ранга). Это метод тонкой настройки, который можно эффективно использовать для доработки больших языковых моделей. Подробнее об этом можно прочитать в статье LoRA: Low-Rank Adaptation of Large Language Models .
В реализации Gemma в Keras есть метод enable_lora() , который можно использовать для тонкой настройки:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
После включения LoRA можно приступать к процессу тонкой настройки. В Colab это занимает приблизительно 5 минут на эпоху:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
Обучение в течение большего количества эпох приведет к повышению точности, пока не возникнет переобучение.
9. Проверьте результаты
Теперь вы можете просмотреть результаты работы только что обученного вами гибкого классификатора. Этот код выведет прогнозируемый балл класса для заданного фрагмента текста:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
10. Оценка модели
Наконец, вы оцените производительность нашей модели, используя две распространенные метрики: F1-меру и AUC-ROC . F1-мера отражает ошибки ложноотрицательных и ложноположительных результатов, оценивая гармоническое среднее точности и полноты при определенном пороговом значении классификации. AUC-ROC, с другой стороны, отражает компромисс между частотой истинноположительных и ложноположительных результатов при различных пороговых значениях и вычисляет площадь под этой кривой.
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
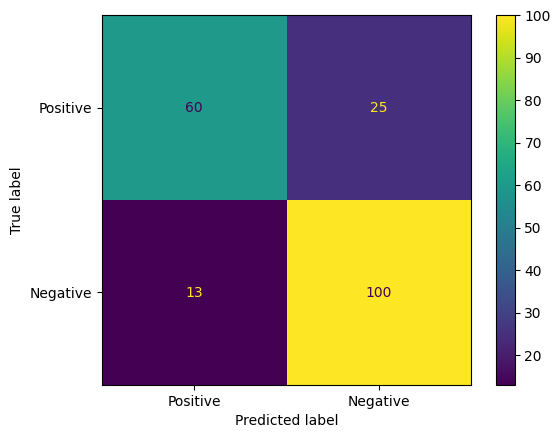
Еще один интересный способ оценки точности прогнозов модели — это матрицы ошибок. Матрица ошибок визуально отображает различные типы ошибок прогнозирования.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
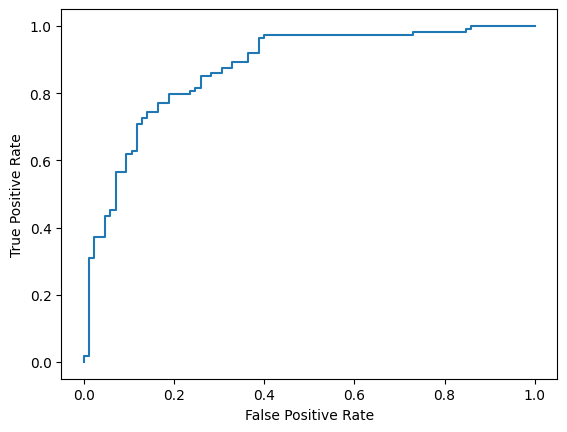
Наконец, вы также можете взглянуть на ROC-кривую, чтобы оценить потенциальные ошибки прогнозирования при использовании различных пороговых значений оценки.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()