
1. Présentation
Cet atelier de programmation montre comment créer un classificateur de texte personnalisé à l'aide du réglage des paramètres avec optimisation (PET, Parameter-Efficient Tuning). Au lieu d'affiner l'ensemble du modèle, les méthodes PET ne mettent à jour qu'un petit nombre de paramètres, ce qui rend l'entraînement relativement facile et rapide. Il permet également à un modèle d'apprendre de nouveaux comportements avec relativement peu de données d'entraînement. La méthodologie est décrite en détail dans Towards Agile Text Classifiers for Everyone, qui montre comment ces techniques peuvent être appliquées à diverses tâches de sécurité et obtenir des performances de pointe avec seulement quelques centaines d'exemples d'entraînement.
Cet atelier de programmation utilise la méthode PET LoRA et le plus petit modèle Gemma (gemma_instruct_2b_en), car ils peuvent être exécutés plus rapidement et plus efficacement. Le notebook Colab couvre les étapes d'ingestion des données, de mise en forme pour le LLM, d'entraînement des pondérations LoRA et d'évaluation des résultats. Cet atelier de programmation s'appuie sur l'ensemble de données ETHOS, un ensemble de données disponible publiquement pour détecter les propos haineux, créé à partir de commentaires YouTube et Reddit. Lorsqu'il n'est entraîné que sur 200 exemples (1/4 de l'ensemble de données), il atteint un score F1 de 0,80 et un score ROC-AUC de 0,78, ce qui est légèrement supérieur à l'état de l'art actuellement indiqué dans le classement (au moment de la rédaction, le 15 février 2024). Lorsqu'il est entraîné sur les 800 exemples complets, il obtient un score F1 de 83,74 et un score ROC-AUC de 88,17. Les modèles plus volumineux, comme gemma_instruct_7b_en, sont généralement plus performants, mais les coûts d'entraînement et d'exécution sont également plus élevés.
Avertissement : cet atelier de programmation développe un classificateur de sécurité pour détecter les propos haineux. Les exemples et l'évaluation des résultats contiennent donc des propos horribles.
2. Installation et configuration
Pour cet atelier de programmation, vous aurez besoin d'une version récente de keras (3) et keras-nlp (0.8.0), ainsi que d'un compte Kaggle pour télécharger le modèle de base.
!pip install -q -U keras-nlp
!pip install -q -U keras
Pour vous connecter à Kaggle, vous pouvez stocker votre fichier d'identifiants kaggle.json à l'emplacement ~/.kaggle/kaggle.json ou exécuter la commande suivante dans un environnement Colab :
import kagglehub
kagglehub.login()
Cet atelier de programmation a été testé avec TensorFlow comme backend Keras, mais vous pouvez utiliser TensorFlow, PyTorch ou JAX :
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3. Charger l'ensemble de données ETHOS
Dans cette section, vous allez charger l'ensemble de données sur lequel entraîner notre classificateur et le prétraiter en un ensemble d'entraînement et un ensemble de test. Vous utiliserez l'ensemble de données de recherche populaire ETHOS, qui a été collecté pour détecter les propos haineux sur les réseaux sociaux. Pour en savoir plus sur la façon dont l'ensemble de données a été collecté, consultez l'article ETHOS: an Online Hate Speech Detection Dataset.
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
Un résultat semblable aux lignes suivantes s'affiche :
étiquette | commentaire | |
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
4. Télécharger et instancier le modèle
Comme décrit dans la documentation, vous pouvez utiliser le modèle Gemma de différentes manières. Avec Keras, voici ce que vous devez faire :
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
Vous pouvez tester le fonctionnement du modèle en générant du texte :
model.generate('Question: what is the capital of France? ', max_length=32)
5. Prétraitement du texte et jetons de séparation
Pour aider le modèle à mieux comprendre notre intention, vous pouvez prétraiter le texte et utiliser des jetons de séparation. Le modèle est ainsi moins susceptible de générer du texte qui ne correspond pas au format attendu. Par exemple, vous pouvez essayer de demander une classification des sentiments au modèle en écrivant un prompt comme celui-ci :
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
Dans ce cas, le modèle peut ou non générer ce que vous recherchez. Par exemple, si le texte contient des caractères de retour à la ligne, cela aura probablement un impact négatif sur les performances du modèle. Une approche plus robuste consiste à utiliser des jetons de séparation. La requête devient alors :
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
Cela peut être abstrait à l'aide d'une fonction qui prétraite le texte :
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
Maintenant, si vous exécutez la fonction en utilisant la même invite et le même texte qu'auparavant, vous devriez obtenir le même résultat :
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
Le résultat devrait être le suivant :
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
6. Post-traitement de la sortie
Les sorties du modèle sont des jetons avec différentes probabilités. Normalement, pour générer du texte, vous sélectionnez les jetons les plus probables et construisez des phrases, des paragraphes ou même des documents entiers. Toutefois, pour la classification, ce qui compte réellement, c'est de savoir si le modèle estime que Positive est plus probable que Negative ou inversement.
Compte tenu du modèle que vous avez instancié précédemment, voici comment vous pouvez traiter sa sortie pour obtenir les probabilités indépendantes indiquant si le jeton suivant est Positive ou Negative :
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
Vous pouvez tester cette fonction en l'exécutant avec la requête que vous avez créée précédemment :
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
Vous obtiendrez un résultat semblable à celui-ci :
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
7. Tout regrouper en tant que classificateur
Pour faciliter l'utilisation, vous pouvez regrouper toutes les fonctions que vous venez de créer dans un seul classificateur de type sklearn avec des fonctions simples et familières telles que predict() et predict_score().
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
8. Affinage de modèles
LoRA signifie "Low-Rank Adaptation" (adaptation à faible rang). Il s'agit d'une technique d'affinage qui peut être utilisée pour affiner efficacement les grands modèles de langage. Pour en savoir plus, consultez l'article LoRA : Low-Rank Adaptation of Large Language Models.
L'implémentation Keras de Gemma fournit une méthode enable_lora() que vous pouvez utiliser pour l'ajustement précis :
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
Une fois LoRA activé, vous pouvez commencer le processus de réglage fin. Cela prend environ cinq minutes par époque sur Colab :
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
L'entraînement sur un plus grand nombre d'époques permet d'obtenir une plus grande précision, jusqu'à ce qu'un surapprentissage se produise.
9. Inspecter les résultats
Vous pouvez maintenant examiner la sortie du classificateur agile que vous venez d'entraîner. Ce code génère le score de la classe prédite pour un extrait de texte donné :
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
10. Évaluation du modèle
Enfin, vous évaluerez les performances de notre modèle à l'aide de deux métriques courantes : le score F1 et l'AUC-ROC. Le score F1 capture les erreurs de faux négatifs et de faux positifs en évaluant la moyenne harmonique de la précision et du rappel à un certain seuil de classification. L'AUC-ROC, quant à elle, capture le compromis entre le taux de vrais positifs et le taux de faux positifs pour différents seuils, et calcule l'aire sous cette courbe.
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
Les matrices de confusion sont un autre moyen intéressant d'évaluer les prédictions des modèles. Une matrice de confusion représente visuellement les différents types d'erreurs de prédiction.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
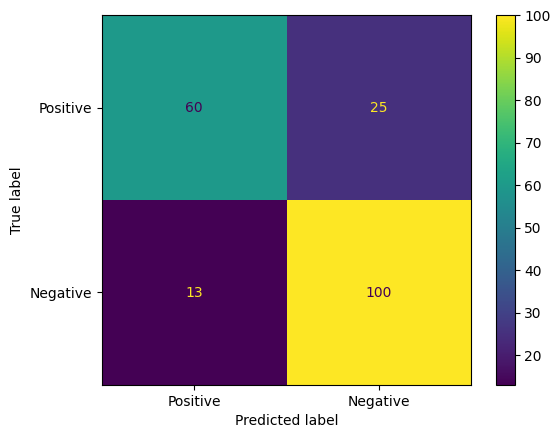
Enfin, vous pouvez également examiner la courbe ROC pour avoir une idée des erreurs de prédiction potentielles lorsque vous utilisez différents seuils de score.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()
