1. সংক্ষিপ্ত বিবরণ
এই কোডল্যাবটি প্যারামিটার এফিশিয়েন্ট টিউনিং (PET) ব্যবহার করে কীভাবে একটি কাস্টমাইজড টেক্সট ক্লাসিফায়ার তৈরি করতে হয় তা ব্যাখ্যা করে। পুরো মডেলটিকে সূক্ষ্মভাবে সাজানোর পরিবর্তে, PET পদ্ধতিগুলি কেবলমাত্র অল্প পরিমাণে প্যারামিটার আপডেট করে, যা তুলনামূলকভাবে সহজ এবং দ্রুত প্রশিক্ষণ দেয়। এটি একটি মডেলের জন্য তুলনামূলকভাবে কম প্রশিক্ষণ ডেটা ব্যবহার করে নতুন আচরণ শেখা সহজ করে তোলে। পদ্ধতিটি "টুওয়ার্ডস অ্যাজাইল টেক্সট ক্লাসিফায়ারস ফর এভরিওন" বইতে বিস্তারিতভাবে বর্ণনা করা হয়েছে যা দেখায় যে কীভাবে এই কৌশলগুলি বিভিন্ন সুরক্ষা কাজে প্রয়োগ করা যেতে পারে এবং মাত্র কয়েকশ প্রশিক্ষণ উদাহরণ ব্যবহার করে অত্যাধুনিক কর্মক্ষমতা অর্জন করা যেতে পারে।
এই কোডল্যাবটি LoRA PET পদ্ধতি এবং ছোট Gemma মডেল ( gemma_instruct_2b_en ) ব্যবহার করে কারণ এটি দ্রুত এবং আরও দক্ষতার সাথে চালানো যেতে পারে। colab ডেটা গ্রহণ, LLM এর জন্য এটি ফর্ম্যাট করা, LoRA ওজন প্রশিক্ষণ দেওয়া এবং তারপর ফলাফল মূল্যায়ন করার ধাপগুলি কভার করে। এই কোডল্যাবটি ETHOS ডেটাসেটের উপর প্রশিক্ষণ দেয়, যা YouTube এবং Reddit মন্তব্য থেকে তৈরি ঘৃণ্য বক্তৃতা সনাক্ত করার জন্য একটি সর্বজনীনভাবে উপলব্ধ ডেটাসেট। মাত্র 200টি উদাহরণ (ডেটাসেটের 1/4) উপর প্রশিক্ষণ দেওয়া হলে এটি F1: 0.80 এবং ROC-AUC: 0.78 অর্জন করে, যা বর্তমানে লিডারবোর্ডে রিপোর্ট করা SOTA থেকে সামান্য বেশি (লেখার সময়, 15 ফেব্রুয়ারী 2024)। সম্পূর্ণ 800টি উদাহরণের উপর প্রশিক্ষণ দেওয়া হলে, এটি 83.74 এর F1 স্কোর এবং 88.17 এর ROC-AUC স্কোর অর্জন করে। gemma_instruct_7b_en এর মতো বৃহত্তর মডেলগুলি সাধারণত আরও ভাল পারফর্ম করবে, তবে প্রশিক্ষণ এবং কার্যকর করার খরচও বেশি।
ট্রিগার সতর্কতা : যেহেতু এই কোডল্যাব ঘৃণ্য বক্তৃতা সনাক্ত করার জন্য একটি সুরক্ষা শ্রেণিবদ্ধকারী তৈরি করে, ফলাফলের উদাহরণ এবং মূল্যায়নে কিছু ভয়ঙ্কর ভাষা রয়েছে।
2. ইনস্টলেশন এবং সেটআপ
এই কোডল্যাবের জন্য, বেস মডেলটি ডাউনলোড করার জন্য আপনার একটি সাম্প্রতিক সংস্করণ keras (3), keras-nlp (0.8.0) এবং একটি Kaggle অ্যাকাউন্টের প্রয়োজন হবে।
!pip install -q -U keras-nlp
!pip install -q -U keras
Kaggle-এ লগইন করার জন্য, আপনি আপনার kaggle.json ক্রেডেনশিয়াল ফাইলটি ~/.kaggle/kaggle.json এ সংরক্ষণ করতে পারেন অথবা Colab পরিবেশে নিম্নলিখিতটি চালাতে পারেন:
import kagglehub
kagglehub.login()
এই কোডল্যাবটি Keras ব্যাকএন্ড হিসেবে Tensorflow ব্যবহার করে পরীক্ষা করা হয়েছিল, তবে আপনি Tensorflow, Pytorch অথবা JAX ব্যবহার করতে পারেন:
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3. ETHOS ডেটাসেট লোড করুন
এই বিভাগে আপনি আমাদের ক্লাসিফায়ারকে প্রশিক্ষণ দেওয়ার জন্য ডেটাসেটটি লোড করবেন এবং এটিকে একটি ট্রেন এবং পরীক্ষা সেটে প্রি-প্রসেস করবেন। আপনি জনপ্রিয় গবেষণা ডেটাসেট ETHOS ব্যবহার করবেন যা সোশ্যাল মিডিয়ায় ঘৃণাত্মক বক্তব্য সনাক্ত করতে সংগ্রহ করা হয়েছিল। ডেটাসেটটি কীভাবে সংগ্রহ করা হয়েছিল সে সম্পর্কে আরও তথ্য আপনি "ETHOS: একটি অনলাইন ঘৃণাত্মক বক্তব্য সনাক্তকরণ ডেটাসেট" পত্রিকায় পেতে পারেন।
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
আপনি এর মতো কিছু দেখতে পাবেন:
লেবেল | মন্তব্য | |
0 | | |
১ | | |
২ | | |
৩ | | |
৪ | | |
৪. মডেলটি ডাউনলোড করুন এবং ইন্সট্যান্টিয়েট করুন
ডকুমেন্টেশনে বর্ণিত হিসাবে, আপনি সহজেই জেমা মডেলটি বিভিন্ন উপায়ে ব্যবহার করতে পারেন। কেরাসের সাথে, আপনাকে যা করতে হবে তা হল:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
আপনি কিছু টেক্সট তৈরি করে মডেলটি কাজ করছে কিনা তা পরীক্ষা করতে পারেন:
model.generate('Question: what is the capital of France? ', max_length=32)
৫. টেক্সট প্রিপ্রসেসিং এবং সেপারেটর টোকেন
মডেলটিকে আমাদের উদ্দেশ্য আরও ভালোভাবে বুঝতে সাহায্য করার জন্য, আপনি টেক্সটটি প্রি-প্রসেস করতে পারেন এবং সেপারেটর টোকেন ব্যবহার করতে পারেন। এর ফলে মডেলটি এমন টেক্সট তৈরি করার সম্ভাবনা কম করে যা প্রত্যাশিত ফর্ম্যাটের সাথে খাপ খায় না। উদাহরণস্বরূপ, আপনি এই ধরনের একটি প্রম্পট লিখে মডেল থেকে একটি অনুভূতি শ্রেণীবিভাগের অনুরোধ করার চেষ্টা করতে পারেন:
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
এই ক্ষেত্রে, মডেলটি আপনি যা খুঁজছেন তা আউটপুট করতে পারে বা নাও পারে। উদাহরণস্বরূপ, যদি টেক্সটে নতুন লাইনের অক্ষর থাকে, তাহলে মডেলের পারফরম্যান্সের উপর নেতিবাচক প্রভাব পড়ার সম্ভাবনা থাকে। আরও শক্তিশালী পদ্ধতি হল বিভাজক টোকেন ব্যবহার করা। তারপর প্রম্পটটি হয়ে ওঠে:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
এটি একটি ফাংশন ব্যবহার করে বিমূর্ত করা যেতে পারে যা পাঠ্যকে প্রাক-প্রক্রিয়াকরণ করে:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
এখন, যদি আপনি আগের মতো একই প্রম্পট এবং টেক্সট ব্যবহার করে ফাংশনটি চালান, তাহলে আপনার একই আউটপুট পাওয়া উচিত:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
কোনটি আউটপুট হওয়া উচিত:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
৬. আউটপুট পোস্টপ্রসেসিং
মডেলের আউটপুটগুলি বিভিন্ন সম্ভাব্যতা সহ টোকেন। সাধারণত, টেক্সট তৈরি করতে, আপনাকে শীর্ষ কয়েকটি সম্ভাব্য টোকেনগুলির মধ্যে থেকে নির্বাচন করতে হবে এবং বাক্য, অনুচ্ছেদ বা এমনকি সম্পূর্ণ নথি তৈরি করতে হবে। তবে, শ্রেণীবদ্ধকরণের উদ্দেশ্যে, আসলে গুরুত্বপূর্ণ বিষয় হল মডেলটি বিশ্বাস করে যে Positive Negative চেয়ে বেশি সম্ভাব্য, নাকি বিপরীত।
আপনি আগে যে মডেলটি ইনস্ট্যান্টিয়েট করেছেন, তার ভিত্তিতে আপনি পরবর্তী টোকেনটি Positive নাকি Negative তার স্বাধীন সম্ভাব্যতার মধ্যে এর আউটপুট প্রক্রিয়া করতে পারেন:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
আপনি আগে তৈরি করা প্রম্পটটি ব্যবহার করে ফাংশনটি পরীক্ষা করতে পারেন:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
যা নিম্নলিখিতগুলির মতো কিছু আউটপুট দেবে:
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
৭. ক্লাসিফায়ার হিসেবে সবকিছু গুছিয়ে নেওয়া
ব্যবহারের সুবিধার জন্য, আপনি আপনার তৈরি করা সমস্ত ফাংশনগুলিকে একটি একক sklearn-এর মতো ক্লাসিফায়ারে মুড়ে দিতে পারেন যাতে predict() এবং predict_score() এর মতো ব্যবহারযোগ্য এবং পরিচিত ফাংশন ব্যবহার করা যায়।
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
৮. মডেল ফাইন-টিউনিং
LoRA এর অর্থ হল নিম্ন-র্যাঙ্ক অভিযোজন। এটি একটি সূক্ষ্ম-সুরকরণ কৌশল যা বৃহৎ ভাষার মডেলগুলিকে দক্ষতার সাথে সূক্ষ্ম-সুরকরণ করতে ব্যবহার করা যেতে পারে। আপনি এটি সম্পর্কে আরও পড়তে পারেন LoRA: বৃহৎ ভাষার মডেলগুলির নিম্ন-র্যাঙ্ক অভিযোজন পত্রিকায় ।
জেমার কেরাস বাস্তবায়ন একটি enable_lora() পদ্ধতি প্রদান করে যা আপনি ফাইন-টিউনিংয়ের জন্য ব্যবহার করতে পারেন:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
LoRA সক্ষম করার পরে, আপনি ফাইন-টিউনিং প্রক্রিয়া শুরু করতে পারেন। Colab-এ প্রতি পর্বে এটি প্রায় ৫ মিনিট সময় নেয়:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
অতিরিক্ত ফিটিং না হওয়া পর্যন্ত, আরও যুগের জন্য প্রশিক্ষণের ফলে উচ্চতর নির্ভুলতা আসবে।
৯. ফলাফল পরীক্ষা করুন
আপনি এখন আপনার প্রশিক্ষিত অ্যাজাইল ক্লাসিফায়ারের আউটপুট পরীক্ষা করতে পারেন। এই কোডটি একটি টেক্সটের মাধ্যমে পূর্বাভাসিত ক্লাস স্কোর আউটপুট করবে:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
১০. মডেল মূল্যায়ন
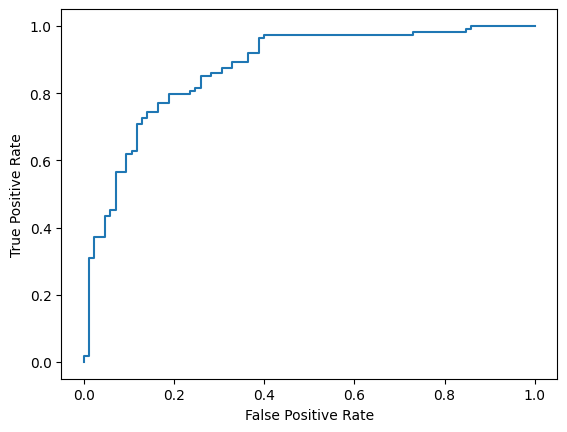
অবশেষে, আপনি দুটি সাধারণ মেট্রিক্স, F1 স্কোর এবং AUC-ROC ব্যবহার করে আমাদের মডেলের কর্মক্ষমতা মূল্যায়ন করবেন। F1 স্কোর একটি নির্দিষ্ট শ্রেণীবিভাগের থ্রেশহোল্ডে নির্ভুলতা এবং প্রত্যাহারের সুরেলা গড়ের মূল্যায়ন করে মিথ্যা নেতিবাচক এবং মিথ্যা ধনাত্মক ত্রুটিগুলি ক্যাপচার করে। অন্যদিকে, AUC-ROC বিভিন্ন থ্রেশহোল্ড জুড়ে সত্য ধনাত্মক হার এবং মিথ্যা ধনাত্মক হারের মধ্যে ট্রেডঅফ ক্যাপচার করে এবং এই বক্ররেখার অধীনে ক্ষেত্রফল গণনা করে।
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
মডেল ভবিষ্যদ্বাণী মূল্যায়নের আরেকটি আকর্ষণীয় উপায় হল কনফিউশন ম্যাট্রিক্স। একটি কনফিউশন ম্যাট্রিক্স বিভিন্ন ধরণের ভবিষ্যদ্বাণী ত্রুটি দৃশ্যত চিত্রিত করবে।
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()

পরিশেষে, বিভিন্ন স্কোরিং থ্রেশহোল্ড ব্যবহার করার সময় সম্ভাব্য ভবিষ্যদ্বাণী ত্রুটির ধারণা পেতে আপনি ROC বক্ররেখাটিও দেখতে পারেন।
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()