
1. Genel Bakış
Bu codelab'de, parametre açısından verimli ayarlama (PET) kullanarak nasıl özelleştirilmiş bir metin sınıflandırıcı oluşturulacağı gösterilmektedir. PET yöntemleri, modelin tamamına ince ayar yapmak yerine yalnızca az sayıda parametreyi günceller. Bu da eğitimin nispeten kolay ve hızlı olmasını sağlar. Ayrıca, modelin nispeten az eğitim verisiyle yeni davranışlar öğrenmesini kolaylaştırır. Metodoloji, Towards Agile Text Classifiers for Everyone adlı makalede ayrıntılı olarak açıklanmaktadır. Bu makalede, bu tekniklerin çeşitli güvenlik görevlerine nasıl uygulanabileceği ve yalnızca birkaç yüz eğitim örneğiyle en iyi performansın nasıl elde edilebileceği gösterilmektedir.
Bu codelab'de, daha hızlı ve verimli çalışabildiği için LoRA PET yöntemi ve daha küçük Gemma modeli (gemma_instruct_2b_en) kullanılmaktadır. Colab'de verileri alma, LLM için biçimlendirme, LoRA ağırlıklarını eğitme ve sonuçları değerlendirme adımları ele alınmaktadır. Bu codelab, YouTube ve Reddit yorumlarından oluşturulan, nefret söylemini tespit etmeye yönelik herkese açık bir veri kümesi olan ETHOS veri kümesi üzerinde eğitim verir. Yalnızca 200 örnekle (veri kümesinin 1/4'ü) eğitildiğinde F1: 0,80 ve ROC-AUC: 0,78 değerlerine ulaşır. Bu değerler, liderlik tablosunda (15 Şubat 2024 itibarıyla) bildirilen mevcut SOTA'nın biraz üzerindedir. 800 örneğin tamamıyla eğitildiğinde %83,74 F1 puanı ve %88,17 ROC-AUC puanı elde eder. gemma_instruct_7b_en gibi daha büyük modeller genellikle daha iyi performans gösterir ancak eğitim ve yürütme maliyetleri de daha yüksektir.
Tetikleyici İçerik Uyarısı: Bu codelab, nefret söylemini tespit etmek için bir güvenlik sınıflandırıcı geliştirdiğinden sonuçların örnekleri ve değerlendirmesi bazı korkunç ifadeler içerir.
2. Yükleme ve Kurulum
Bu codelab için keras (3) ve keras-nlp (0.8.0) sürümlerinin güncel bir sürümüne ve temel modeli indirmek için bir Kaggle hesabına ihtiyacınız vardır.
!pip install -q -U keras-nlp
!pip install -q -U keras
Kaggle'da oturum açmak için kaggle.json kimlik bilgileri dosyanızı ~/.kaggle/kaggle.json konumunda saklayabilir veya Colab ortamında aşağıdakileri çalıştırabilirsiniz:
import kagglehub
kagglehub.login()
Bu codelab, Keras arka ucu olarak TensorFlow kullanılarak test edilmiştir ancak TensorFlow, PyTorch veya JAX'i kullanabilirsiniz:
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
3. ETHOS veri kümesini yükleme
Bu bölümde, sınıflandırıcıyı eğitmek için kullanılacak veri kümesini yükleyecek ve eğitim ile test kümesi olarak ön işleme tabi tutacaksınız. Sosyal medyada nefret söylemini tespit etmek için toplanan popüler araştırma veri kümesi ETHOS'u kullanacaksınız. Veri kümesinin nasıl toplandığı hakkında daha fazla bilgiyi ETHOS: an Online Hate Speech Detection Dataset (ETHOS: Çevrimiçi Nefret Söylemi Algılama Veri Kümesi) adlı makalede bulabilirsiniz.
import pandas as pd
gh_root = 'https://raw.githubusercontent.com'
gh_repo = 'intelligence-csd-auth-gr/Ethos-Hate-Speech-Dataset'
gh_path = 'master/ethos/ethos_data/Ethos_Dataset_Binary.csv'
data_url = f'{gh_root}/{gh_repo}/{gh_path}'
df = pd.read_csv(data_url, delimiter=';')
df['hateful'] = (df['isHate'] >= df['isHate'].median()).astype(int)
# Shuffle the dataset.
df = df.sample(frac=1, random_state=32)
# Split into train and test.
df_train, df_test = df[:800], df[800:]
# Display a sample of the data.
df.head(5)[['hateful', 'comment']]
Aşağıdakine benzer bir ifade görürsünüz:
etiket | yorum | |
0 |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
4. Modeli İndirme ve Örneklendirme
Dokümanlarda açıklandığı gibi, Gemma modelini birçok şekilde kolayca kullanabilirsiniz. Keras ile yapmanız gerekenler:
import keras
import keras_nlp
# For reproducibility purposes.
keras.utils.set_random_seed(1234)
# Download the model from Kaggle using Keras.
model = keras_nlp.models.GemmaCausalLM.from_preset('gemma_instruct_2b_en')
# Set the sequence length to a small enough value to fit in memory in Colab.
model.preprocessor.sequence_length = 128
Modelin çalıştığını test etmek için metin oluşturabilirsiniz:
model.generate('Question: what is the capital of France? ', max_length=32)
5. Metin Ön İşleme ve Ayırıcı Jetonlar
Modelin amacımızı daha iyi anlamasına yardımcı olmak için metni önceden işleyebilir ve ayırıcı jetonlar kullanabilirsiniz. Bu sayede modelin, beklenen biçime uymayan metinler oluşturma olasılığı azalır. Örneğin, şu istemi yazarak modelden duygu sınıflandırması isteyebilirsiniz:
Classify the following text into one of the following classes:[Positive,Negative] Text: you look very nice today Classification:
Bu durumda model, aradığınız sonucu verebilir veya vermeyebilir. Örneğin, metin yeni satır karakterleri içeriyorsa model performansını olumsuz etkilemesi muhtemeldir. Daha sağlam bir yaklaşım, ayırıcı jetonlar kullanmaktır. İstem şu şekilde olur:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text: you look very nice today <separator> Prediction:
Bu, metni önceden işleyen bir işlev kullanılarak soyutlanabilir:
def preprocess_text(
text: str,
labels: list[str],
instructions: str,
separator: str,
) -> str:
prompt = f'{instructions}:[{",".join(labels)}]'
return separator.join([prompt, f'Text:{text}', 'Prediction:'])
Şimdi, işlevi aynı istem ve metni kullanarak çalıştırırsanız aynı çıkışı alırsınız:
text = 'you look very nice today'
prompt = preprocess_text(
text=text,
labels=['Positive', 'Negative'],
instructions='Classify the following text into one of the following classes',
separator='\n<separator>\n',
)
print(prompt)
Bu komutun çıkışı şu şekilde olmalıdır:
Classify the following text into one of the following classes:[Positive,Negative] <separator> Text:well, looks like its time to have another child <separator> Prediction:
6. Çıkış İşleme Sonrası
Modelin çıkışları, çeşitli olasılıklara sahip jetonlardır. Normalde metin oluşturmak için en olası birkaç jeton arasından seçim yapıp cümleler, paragraflar ve hatta tam belgeler oluşturursunuz. Ancak sınıflandırma amacıyla, modelin Positive'nın Negative'dan daha olası olduğuna inanıp inanmadığı veya bunun tam tersi önemlidir.
Daha önce oluşturduğunuz modeli göz önünde bulundurarak, çıkışını bir sonraki jetonun Positive veya Negative olup olmayacağına dair bağımsız olasılıklara nasıl dönüştürebileceğiniz aşağıda açıklanmıştır:
import numpy as np
def compute_output_probability(
model: keras_nlp.models.GemmaCausalLM,
prompt: str,
target_classes: list[str],
) -> dict[str, float]:
# Shorthands.
preprocessor = model.preprocessor
tokenizer = preprocessor.tokenizer
# NOTE: If a token is not found, it will be considered same as "<unk>".
token_unk = tokenizer.token_to_id('<unk>')
# Identify the token indices, which is the same as the ID for this tokenizer.
token_ids = [tokenizer.token_to_id(word) for word in target_classes]
# Throw an error if one of the classes maps to a token outside the vocabulary.
if any(token_id == token_unk for token_id in token_ids):
raise ValueError('One of the target classes is not in the vocabulary.')
# Preprocess the prompt in a single batch. This is done one sample at a time
# for illustration purposes, but it would be more efficient to batch prompts.
preprocessed = model.preprocessor.generate_preprocess([prompt])
# Identify output token offset.
padding_mask = preprocessed["padding_mask"]
token_offset = keras.ops.sum(padding_mask) - 1
# Score outputs, extract only the next token's logits.
vocab_logits = model.score(
token_ids=preprocessed["token_ids"],
padding_mask=padding_mask,
)[0][token_offset]
# Compute the relative probability of each of the requested tokens.
token_logits = [vocab_logits[ix] for ix in token_ids]
logits_tensor = keras.ops.convert_to_tensor(token_logits)
probabilities = keras.activations.softmax(logits_tensor)
return dict(zip(target_classes, probabilities.numpy()))
Bu işlevi, daha önce oluşturduğunuz istemle çalıştırarak test edebilirsiniz:
compute_output_probability(
model=model,
prompt=prompt,
target_classes=['Positive', 'Negative'],
)
Bu komut, aşağıdakine benzer bir çıktı verir:
{'Positive': 0.99994016, 'Negative': 5.984089e-05}
7. Tümünü sınıflandırıcı olarak sarmalama
Kullanım kolaylığı için, yeni oluşturduğunuz tüm işlevleri predict() ve predict_score() gibi kolayca kullanabileceğiniz ve tanıdık işlevlerle tek bir sklearn benzeri sınıflandırıcıya sarmalayabilirsiniz.
import dataclasses
@dataclasses.dataclass(frozen=True)
class AgileClassifier:
"""Agile classifier to be wrapped around a LLM."""
# The classes whose probability will be predicted.
labels: tuple[str, ...]
# Provide default instructions and control tokens, can be overridden by user.
instructions: str = 'Classify the following text into one of the following classes'
separator_token: str = '<separator>'
end_of_text_token: str = '<eos>'
def encode_for_prediction(self, x_text: str) -> str:
return preprocess_text(
text=x_text,
labels=self.labels,
instructions=self.instructions,
separator=self.separator_token,
)
def encode_for_training(self, x_text: str, y: int) -> str:
return ''.join([
self.encode_for_prediction(x_text),
self.labels[y],
self.end_of_text_token,
])
def predict_score(
self,
model: keras_nlp.models.GemmaCausalLM,
x_text: str,
) -> list[float]:
prompt = self.encode_for_prediction(x_text)
token_probabilities = compute_output_probability(
model=model,
prompt=prompt,
target_classes=self.labels,
)
return [token_probabilities[token] for token in self.labels]
def predict(
self,
model: keras_nlp.models.GemmaCausalLM,
x_eval: str,
) -> int:
return np.argmax(self.predict_score(model, x_eval))
agile_classifier = AgileClassifier(labels=('Positive', 'Negative'))
8. Model İnce Ayarı
LoRA, Low-Rank Adaptation (Düşük Dereceli Adaptasyon) anlamına gelir. Bu teknik, büyük dil modellerini verimli bir şekilde ince ayarlamak için kullanılabilen bir ince ayar tekniğidir. Bu konu hakkında daha fazla bilgiyi LoRA: Low-Rank Adaptation of Large Language Models (LoRA: Büyük Dil Modellerinin Düşük Dereceli Adaptasyonu) adlı makalede bulabilirsiniz.
Gemma'nın Keras uygulaması, ince ayar için kullanabileceğiniz bir enable_lora() yöntemi sunar:
# Enable LoRA for the model and set the LoRA rank to 4.
model.backbone.enable_lora(rank=4)
LoRA'yı etkinleştirdikten sonra ince ayar işlemine başlayabilirsiniz. Bu işlem, Colab'da dönem başına yaklaşık 5 dakika sürer:
import tensorflow as tf
# Create dataset with preprocessed text + labels.
map_fn = lambda xy: agile_classifier.encode_for_training(*xy)
x_train = list(map(map_fn, df_train[['comment', 'hateful']].values))
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(2)
# Compile the model using the Adam optimizer and appropriate loss function.
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(learning_rate=0.0005),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Begin training.
model.fit(ds_train, epochs=4)
Aşırı uyum gerçekleşene kadar daha fazla dönem için eğitim, daha yüksek doğrulukla sonuçlanır.
9. Sonuçları inceleme
Artık yeni eğittiğiniz çevik sınıflandırıcıdan alınan çıktıyı inceleyebilirsiniz. Bu kod, bir metin parçası verildiğinde tahmin edilen sınıf puanını verir:
text = 'you look really nice today'
scores = agile_classifier.predict_score(model, text)
dict(zip(agile_classifier.labels, scores))
{'Positive': 0.99899644, 'Negative': 0.0010035498}
10. Model Değerlendirmesi
Son olarak, modelimizin performansını iki yaygın metrik olan F1 puanı ve AUC-ROC ile değerlendireceksiniz. F1 puanı, belirli bir sınıflandırma eşiğinde hassasiyet ve geri çağırmanın harmonik ortalamasını değerlendirerek yanlış negatif ve yanlış pozitif hataları yakalar. Diğer yandan AUC-ROC, çeşitli eşiklerdeki gerçek pozitif oranı ile yanlış pozitif oranı arasındaki dengeyi yakalar ve bu eğrinin altındaki alanı hesaplar.
from sklearn.metrics import f1_score, roc_auc_score
y_true = df_test['hateful'].values
# Compute the scores (aka probabilities) for each of the labels.
y_score = [agile_classifier.predict_score(model, x) for x in df_test['comment']]
# The label with highest score is considered the predicted class.
y_pred = np.argmax(y_score, axis=1)
# Extract the probability of a comment being considered hateful.
y_prob = [x[agile_classifier.labels.index('Negative')] for x in y_score]
# Compute F1 and AUC-ROC scores.
print(f'F1: {f1_score(y_true, y_pred):.2f}')
print(f'AUC-ROC: {roc_auc_score(y_true, y_prob):.2f}')
F1: 0.84 AUC-ROC: = 0.88
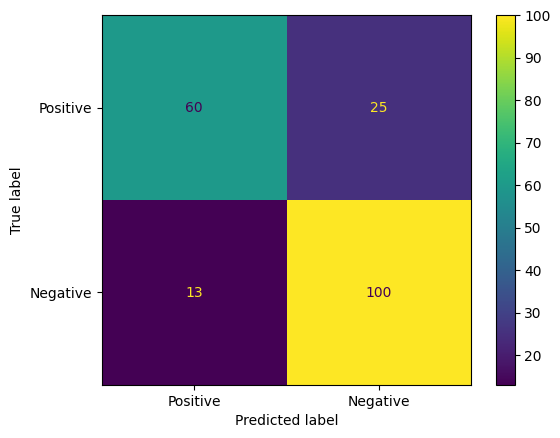
Model tahminlerini değerlendirmenin bir diğer ilginç yolu da karışıklık matrisleridir. Karmaşıklık matrisi, farklı tahmin hatalarını görsel olarak gösterir.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_true, y_pred)
ConfusionMatrixDisplay(
confusion_matrix=cm,
display_labels=agile_classifier.labels,
).plot()
Son olarak, farklı puanlama eşikleri kullanırken olası tahmin hataları hakkında fikir edinmek için ROC eğrisine de bakabilirsiniz.
from sklearn.metrics import RocCurveDisplay, roc_curve
fpr, tpr, _ = roc_curve(y_true, y_prob, pos_label=1)
RocCurveDisplay(fpr=fpr, tpr=tpr).plot()
