
1. Introduction
Generative AI products are relatively new and the behaviors of an application can vary more than earlier forms of software. This makes it important to probe the machine learning models being used, examine examples of the model's behavior and investigate surprises.
The Learning Interpretability Tool (LIT; website, GitHub) is a platform for debugging and analyzing ML models to understand why and how they behave the way they do.
In this codelab, you'll learn how to use LIT to get more out of Google's Gemma model. This codelab demonstrates how to use sequence salience, an interpretability technique, to analyze different prompt engineering approaches.
Learning objectives:
- Understanding sequence salience and its uses in model analysis.
- Setting up LIT for Gemma to compute prompt outputs and sequence salience.
- Using sequence salience through the LM Salience module to understand the impact of prompt designs on model outputs.
- Testing hypothesized prompt improvements in LIT and see their impact.
Note: that this codelab uses the KerasNLP implementation of Gemma, and TensorFlow v2 for the backend. It's highly recommended using a GPU kernel to follow along.
2. Sequence Salience and its Uses in Model Analysis
Text-to-text generative models, such as Gemma, take an input sequence in the form of tokenized text and generate new tokens that are typical follow-ons or completions to that input. This generation happens one token at a time, appending (in a loop) each newly generated token to the input plus any previous generations until the model reaches a stopping condition. Examples include when the model generates an end-of-sequence (EOS) token or reaches the predefined maximum length.
Salience methods are a class of explainable AI (XAI) techniques that can tell you which parts of an input are important to the model for different parts of its output. LIT supports salience methods for a variety of classification tasks, which explain the impact of a sequence of input tokens on the predicted label. Sequence salience generalizes these methods to text-to-text generative models and explains the impact of the preceding tokens on the generated tokens.
You'll use the Grad L2 Norm method here for sequence salience, which analyzes the gradients of the model and provides a magnitude of the influence that each preceding token has on the output. This method is simple and efficient, and has been shown to perform well in classification and other settings. The larger the salience score, the higher the influence. This method is used within LIT because it's well-understood and utilized widely across the interpretability research community.
More advanced gradient-based salience methods include Grad ⋅ Input and integrated gradients. There are also ablation-based methods available, such as LIME and SHAP, which can be more robust but significantly more expensive to compute. Refer to this article for a detailed comparison of different salience methods.
You can learn more about the science of salience methods in this introductory interactive explorable to salience.
3. Imports, Environment, and Other Setup Code
It is best to follow along with this codelab in new Colab. We recommend using an accelerator runtime, since you will be loading a model into memory, though be aware that the accelerator options vary over time and are subject to limitations. Colab offers paid subscriptions if you would like access to more powerful accelerators. Alternately, you could use a local runtime if your machine has an appropriate GPU.
Note: you may see some warnings of the form
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
These are safe to ignore.
Install LIT and Keras NLP
For this codelab, you will need a recent version of keras (3) keras-nlp (0.14.) and lit-nlp (1.2), and a Kaggle account to download the base model.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Kaggle Access
To authenticate with Kaggle, you can either:
- Store your credentials in a file, such as
~/.kaggle/kaggle.json; - Use the
KAGGLE_USERNAMEandKAGGLE_KEYenvironment variables; or - Run the following in an interactive Python environment, such as Google Colab.
import kagglehub
kagglehub.login()
See the kagglehub documentation for more details, and be sure to accept the Gemma license agreement.
Configuring Keras
Keras 3 supports multiple deep learning backends, including Tensorflow (default), PyTorch, and JAX. The backend is configured using the KERAS_BACKEND environment variable, which must be set before importing the Keras library. The following code snippet shows you how to set this variable in an interactive Python environment.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. Setting up LIT
LIT can be used in Python Notebooks or via a web server. This Codelab focuses on the Notebook use case, can we recommend following along in Google Colab.
In this Codelab, you will load Gemma v2 2B IT using the KerasNLP preset. The following snippet initializes Gemma and loads an example dataset in a LIT Notebook widget.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
You can configure the widget by two changing the values passed to the two required positional arguments:
datasets_config: A list of strings containing the dataset names and paths to load from, as "dataset:path", where path can be a URL or a local file path. The example below uses the special value,sample_prompts, to load the example prompts provided in the LIT distribution.models_config: A list of strings containing the model names and paths to load from, as "model:path", where path can be a URL, a local file path, or the name of a preset for the configured deep learning framework.
Once you have LIT configured to use the model you're interested in, run the following code snippet to render the widget in your Notebook.
lit_widget.render(open_in_new_tab=True)
Using Your Own Data
As a text-to-text generative model, Gemma takes text input and generates text output. LIT uses an opinionated API to communicate the structure of the loaded datasets to models models. LLMs in LIT are designed to work with datasets that provide two fields:
prompt: The input to the model from which text will be generated; andtarget: An optional target sequence, such as a "ground truth" response from human raters or a pre-generated response from another model.
LIT includes a small set of sample_prompts with examples from the following sources that support this Codelab and LIT's extended prompt debugging tutorial.
- GSM8K: Solving grade school math problems with few-shot examples.
- Gigaword Benchmark: Headline generation for a collection of short articles.
- Constitutional Prompting: Generating new ideas on how to use objects with guidelines/boundaries.
You can also easily load your own data, either as a .jsonl file containing records with fields prompt and optionally target (example), or from any format by using LIT's Dataset API.
Run the cell below to load the sample prompts.
5. Analyzing Few Shot Prompts for Gemma in LIT
Today, prompting is as much art as it is science, and LIT can help you empirically improve prompts for large language models, such as Gemma. Ahead, you will see an example of how LIT can be used to explore Gemma's behaviors, anticipate potential issues, and improve its safety.
Identify errors in complex prompts
Two of the most important prompting techniques for high quality LLM-based prototypes and applications are few-shot prompting (including examples of the desired behavior in the prompt) and chain-of-thought (including a form of explanation or reasoning before the final output of the LLM). But creating an effective prompt is often still challenging.
Consider an example of helping someone assess if they will like food based on their tastes. An initial prototype chain-of-thought prompt-template might look like this:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
Did you spot the issues with this prompt? LIT will help you examine the prompt with the LM Salience module.
6. Use sequence salience for debugging
Salience is computed at the smallest possible level (i.e., for each input token), but LIT can aggregate token-saliency into more interpretable larger spans, such as lines, sentences, or words. Learn more about saliency and how to use it to identify unintended biases in our Saliency Explorable.
Let's start by giving the prompt a new example input for the prompt-template variables:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
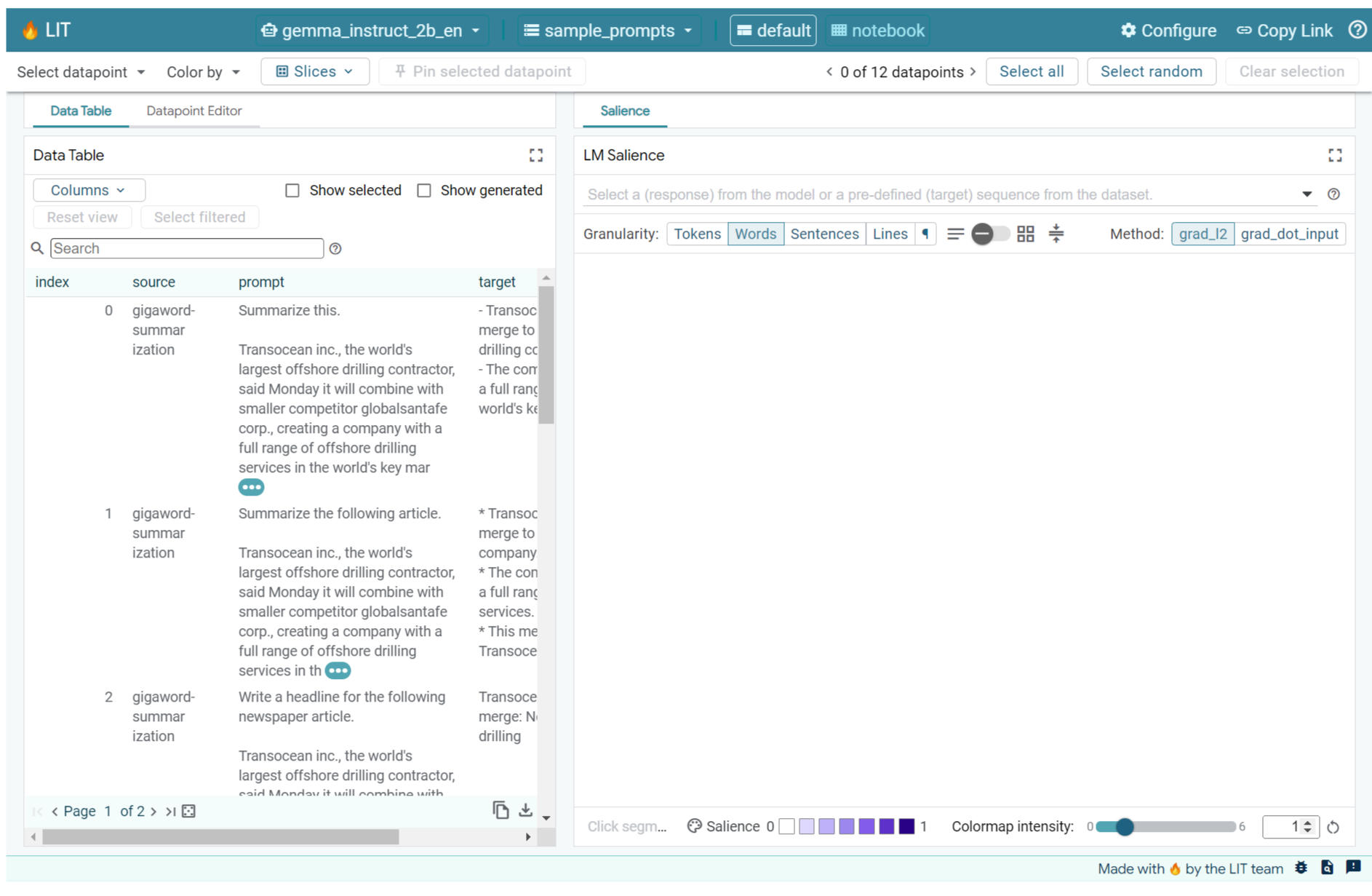
If you have the LIT UI opened in the cell above or in a separate tab, you can use LIT's Datapoint Editor to add this prompt:
Another way is to re-render the widget directly with the prompt of interest:
lit_widget.render(data=[fewshot_mistake_example])
Note the surprising model completion:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
Why is the model suggesting you eat something that you clearly said you can't eat?
Sequence salience can help highlight the root problem, which is in our few-shot examples. In the first example, the chain-of-thought reasoning in the analysis section it has cooked onions in it, which you don't like doesn't match the final recommendation You have to try it.
In the LM Salience module, select "Sentences" and then select the recommendation line. The UI should now look as follows:
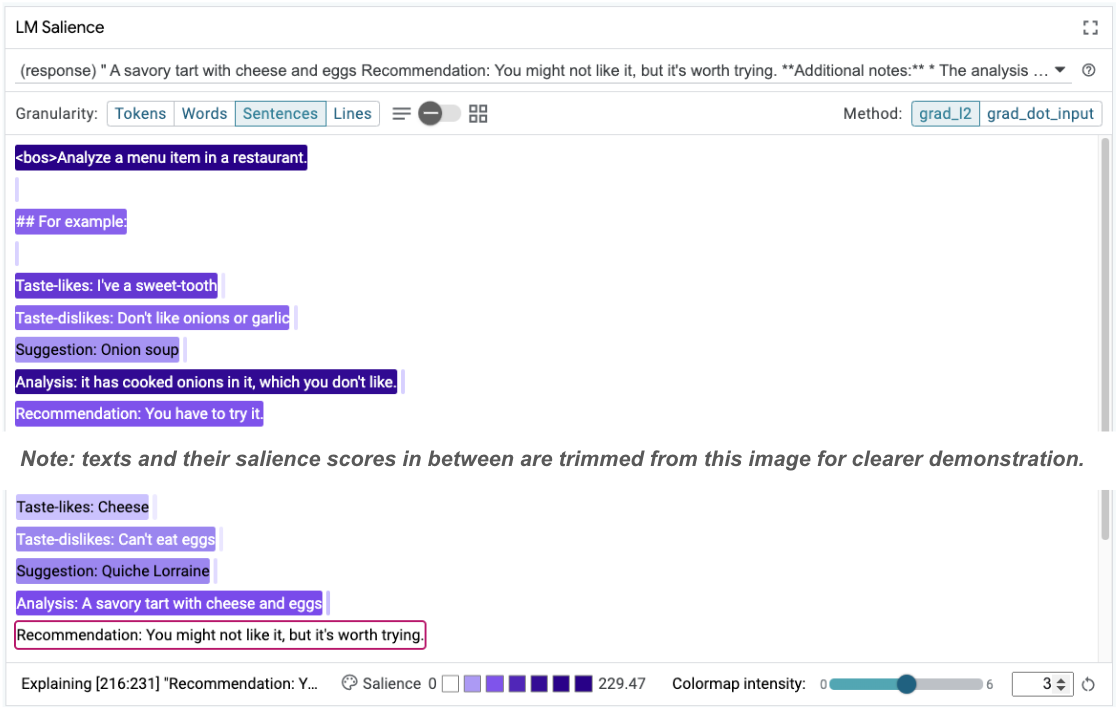
This highlights a human error: an accidental copy and paste of the recommendation part and failure to update it!
Now lets correct the "Recommendation" in the first example to Avoid, and try again. LIT has this example pre-loaded in the sample prompts, so you can use this little utility function to grab it:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
Now the model completion becomes:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
An important lesson to take away from this is: early prototyping helps reveal risks you might not think of ahead of time, and the error-prone nature of language models means that one has to proactively design for errors. Further discussion of this can be found in our People + AI Guidebook for designing with AI.
While the corrected few shot prompt is better, it's still not quite right: it correctly tells the user to avoid eggs, but the reasoning is not right, it says they don't like eggs, when in fact the user has stated that they can't eat eggs. In the following section, you'll see how you can do better.
7. Test hypotheses to improve model behavior
LIT enables you to test changes to prompts within the same interface. In this instance, you're going to test adding a constitution to improve the model's behavior. Constitutions refer to design prompts with principles to help guide the model's generation. Recent methods even enable interactive derivation of constitutional principles.
Let's use this idea to help improve the prompt further. Add a section with the principles for the generation at the top of our prompt, which now starts as follows:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
With this update, the example can be rerun and observe a very different output:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
The prompt salience can then be re-examined to help get a sense of why this change is happening:
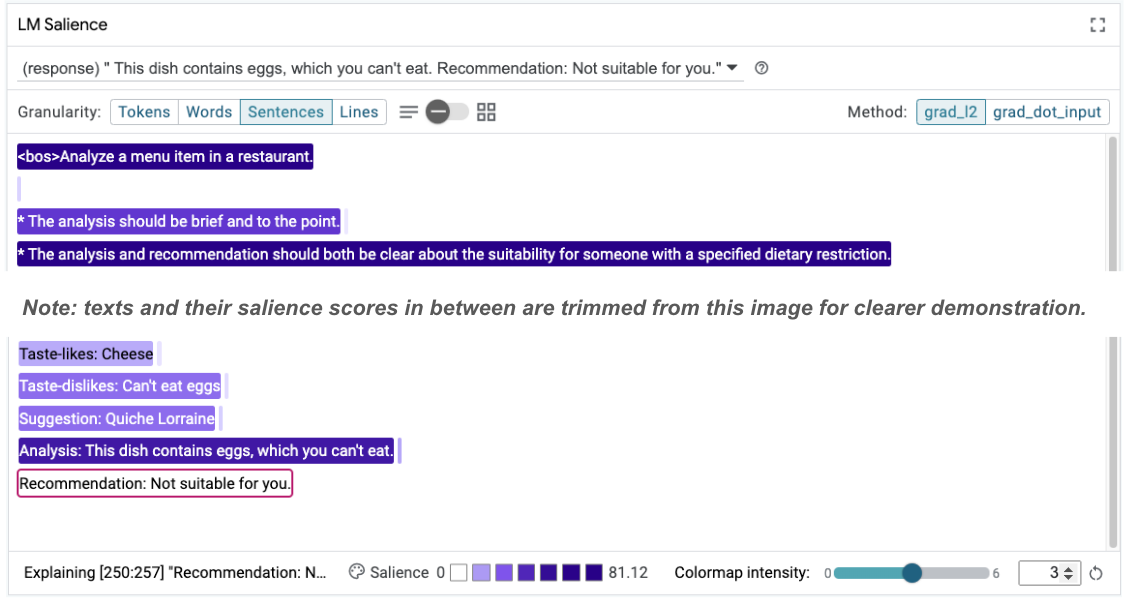
Notice the recommendation is much safer. Furthermore, the "Not suitable for you" is influenced by the principle of clearly stating suitability according to the dietary restriction, along with the analysis (the so-called chain of thought). This helps gives additional confidence that the output is happening for the right reason.
8. Include non-technical teams in model probing and exploration
Interpretability is meant to be a team effort, spanning expertise across XAI, policy, legal, and more.
Interacting with models in the early development stages has traditionally required significant technical expertise, which made it more difficult for some collaborators to access and probe them. Tooling has historically not existed to enable these teams to participate in the early prototyping phases.
Through LIT, the hope is that this paradigm can change. As you've seen through this codelab, LIT's visual medium and interactive ability to examine salience and explore examples can help different stakeholders share and communicate findings. This can enable you to bring in a broader diversity of teammates for model exploration, probing, and debugging. Exposing them to these technical methods can enhance their understanding of how models work. In addition, a more diverse set of expertise in early model testing can also help uncover undesirable outcomes that can be improved.
9. Recap
To recap:
- The LIT UI provides an interface for interactive model execution, enabling users to generate outputs directly and test "what if" scenarios. This is particularly useful for testing different prompt variations.
- The LM Salience module provides a visual representation of salience, and provides controllable data granularity so you can communicate about human-centered constructs (e.g., sentences and words) instead of model-centered constructs (e.g., tokens).
When you find problematic examples in your model evaluations, bring them into LIT for debugging. Start by analyzing the largest sensible unit of content you can think of that logically relates to the modeling task, use the visualizations to see where the model is correctly or incorrectly attending to the prompt content, and then drill down into smaller units of content to further describe the incorrect behavior you're seeing in order to identify possible fixes.
Lastly: Lit is constantly improving! Learn more about our features and share your suggestions here.