
1. Introduzione
I prodotti di AI generativa sono relativamente nuovi e il comportamento di un'applicazione può variare più rispetto alle forme precedenti di software. Per questo motivo, è importante analizzare i modelli di machine learning utilizzati, esaminare esempi del comportamento del modello e indagare sulle sorprese.
Learning Interpretability Tool (LIT; sito web, GitHub) è una piattaforma per il debug e l'analisi dei modelli ML per capire perché e come si comportano in un determinato modo.
In questo codelab imparerai a utilizzare LIT per ottenere di più dal modello Gemma di Google. Questo codelab mostra come utilizzare la salienza della sequenza, una tecnica di interpretabilità, per analizzare diversi approcci di prompt engineering.
Obiettivi di apprendimento:
- Comprendere la salienza della sequenza e i relativi usi nell'analisi del modello.
- Configurazione di LIT per consentire a Gemma di calcolare gli output dei prompt e la salienza della sequenza.
- Utilizzo della salienza della sequenza tramite il modulo Salienza LM per comprendere l'impatto dei prompt sugli output del modello.
- Testare i miglioramenti ipotizzati dei prompt in LIT e verificarne l'impatto.
Nota: questo codelab utilizza l'implementazione KerasNLP di Gemma e TensorFlow v2 per il backend. Ti consigliamo vivamente di utilizzare un kernel GPU per seguire la procedura.
2. Sequence Salience e i suoi utilizzi nell'analisi dei modelli
I modelli generativi da testo a testo, come Gemma, prendono una sequenza di input sotto forma di testo tokenizzato e generano nuovi token che sono tipici follow-on o completamenti di quell'input. Questa generazione avviene un token alla volta, aggiungendo (in un ciclo) ogni token appena generato all'input più le generazioni precedenti finché il modello non raggiunge una condizione di arresto. Ad esempio, quando il modello genera un token di fine sequenza (EOS) o raggiunge la lunghezza massima predefinita.
I metodi di salienza sono una classe di tecniche di AI interpretabile (XAI) che possono indicare quali parti di un input sono importanti per il modello per le diverse parti del suo output. LIT supporta metodi di salienza per una serie di attività di classificazione, che spiegano l'impatto di una sequenza di token di input sull'etichetta prevista. La salienza della sequenza generalizza questi metodi ai modelli generativi da testo a testo e spiega l'impatto dei token precedenti sui token generati.
Qui utilizzerai il metodo Grad L2 Norm per la salienza della sequenza, che analizza i gradienti del modello e fornisce una magnitudo dell'influenza che ogni token precedente ha sull'output. Questo metodo è semplice ed efficiente ed è stato dimostrato che funziona bene nella classificazione e in altre impostazioni. Maggiore è il punteggio di salienza, maggiore è l'influenza. Questo metodo viene utilizzato in LIT perché è ben compreso e ampiamente utilizzato dalla community di ricerca sull'interpretabilità.
I metodi di salience più avanzati basati sui gradienti includono Grad ⋅ Input e gradienti integrati. Sono disponibili anche metodi basati sull'ablazione, come LIME e SHAP, che possono essere più robusti ma significativamente più costosi da calcolare. Per un confronto dettagliato dei diversi metodi di salienza, consulta questo articolo.
Puoi scoprire di più sulla scienza dei metodi di salienza in questa esplorazione interattiva introduttiva alla salienza.
3. Importazioni, ambiente e altro codice di configurazione
È consigliabile seguire questo codelab nel nuovo Colab. Ti consigliamo di utilizzare un runtime dell'acceleratore, poiché caricherai un modello in memoria, ma tieni presente che le opzioni dell'acceleratore variano nel tempo e sono soggette a limitazioni. Colab offre abbonamenti a pagamento se vuoi accedere ad acceleratori più potenti. In alternativa, puoi utilizzare un runtime locale se la tua macchina dispone di una GPU appropriata.
Nota: potresti visualizzare alcuni avvisi del modulo
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
Questi possono essere ignorati.
Installare LIT e Keras NLP
Per questo codelab, avrai bisogno di una versione recente di keras (3) keras-nlp (0.14.) e lit-nlp (1.2) e di un account Kaggle per scaricare il modello di base.
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Accesso a Kaggle
Per eseguire l'autenticazione con Kaggle, puoi:
- Archivia le tue credenziali in un file, ad esempio
~/.kaggle/kaggle.json; - Utilizza le variabili di ambiente
KAGGLE_USERNAMEeKAGGLE_KEYoppure - Esegui il seguente codice in un ambiente Python interattivo, ad esempio Google Colab.
import kagglehub
kagglehub.login()
Per ulteriori dettagli, consulta la documentazione di kagglehub e assicurati di accettare il contratto di licenza di Gemma.
Configurazione di Keras
Keras 3 supporta più backend di deep learning, tra cui TensorFlow (impostazione predefinita), PyTorch e JAX. Il backend viene configurato utilizzando la variabile di ambiente KERAS_BACKEND, che deve essere impostata prima di importare la libreria Keras. Il seguente snippet di codice mostra come impostare questa variabile in un ambiente Python interattivo.
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. Configurazione di LIT
LIT può essere utilizzato nei notebook Python o tramite un server web. Questo Codelab si concentra sul caso d'uso del notebook, quindi consigliamo di seguirlo in Google Colab.
In questo Codelab caricherai Gemma v2 2B IT utilizzando il preset KerasNLP. Il seguente snippet inizializza Gemma e carica un set di dati di esempio in un widget LIT Notebook.
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
Puoi configurare il widget modificando i valori passati ai due argomenti posizionali obbligatori:
datasets_config: un elenco di stringhe contenenti i nomi e i percorsi dei set di dati da caricare, nel formato "dataset:path", dove path può essere un URL o un percorso file locale. L'esempio seguente utilizza il valore specialesample_promptsper caricare i prompt di esempio forniti nella distribuzione LIT.models_config: un elenco di stringhe contenenti i nomi dei modelli e i percorsi da cui caricarli, nel formato "model:path", dove path può essere un URL, un percorso di file locale o il nome di un preset per il framework di deep learning configurato.
Una volta configurato LIT per utilizzare il modello che ti interessa, esegui il seguente snippet di codice per eseguire il rendering del widget nel notebook.
lit_widget.render(open_in_new_tab=True)
Utilizzo dei propri dati
In quanto modello generativo da testo a testo, Gemma prende un input di testo e genera un output di testo. LIT utilizza un'API basata su opinioni per comunicare la struttura dei set di dati caricati ai modelli. Gli LLM in LIT sono progettati per funzionare con set di dati che forniscono due campi:
prompt: l'input del modello da cui verrà generato il testo;target: una sequenza target facoltativa, ad esempio una risposta "basata su dati di fatto" di valutatori umani o una risposta pregenerata di un altro modello.
LIT include un piccolo insieme di sample_prompts con esempi delle seguenti fonti che supportano questo codelab e il tutorial sul debug dei prompt esteso di LIT.
- GSM8K: risoluzione di problemi matematici della scuola elementare con esempi few-shot.
- Benchmark Gigaword: generazione di titoli per una raccolta di articoli brevi.
- Prompt costituzionali: generare nuove idee su come utilizzare gli oggetti con linee guida/limiti.
Puoi anche caricare facilmente i tuoi dati, come file .jsonl contenenti record con i campi prompt e, facoltativamente, target (esempio) o da qualsiasi formato utilizzando l'API Dataset di LIT.
Esegui la cella seguente per caricare i prompt di esempio.
5. Analisi dei prompt few-shot per Gemma in LIT
Oggi, la creazione di prompt è tanto arte quanto scienza e LIT può aiutarti a migliorare empiricamente i prompt per i modelli linguistici di grandi dimensioni, come Gemma. Di seguito vedrai un esempio di come LIT può essere utilizzato per esplorare i comportamenti di Gemma, prevedere potenziali problemi e migliorare la sua sicurezza.
Identificare gli errori nelle richieste complesse
Due delle tecniche di prompting più importanti per prototipi e applicazioni di alta qualità basati su LLM sono il prompt few-shot (che include esempi del comportamento desiderato nel prompt) e la chain-of-thought (che include una forma di spiegazione o ragionamento prima dell'output finale dell'LLM). Tuttavia, creare un prompt efficace è spesso ancora difficile.
Prendi in considerazione un esempio di aiuto per valutare se a una persona piacerà un cibo in base ai suoi gusti. Un modello di prompt iniziale per la catena di pensiero potrebbe avere il seguente aspetto:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
Hai notato i problemi con questo prompt? LIT ti aiuterà a esaminare il prompt con il modulo LM Salience.
6. Utilizzare la salienza della sequenza per il debug
La salienza viene calcolata al livello più piccolo possibile (ovvero per ogni token di input), ma LIT può aggregare la salienza dei token in intervalli più grandi e interpretabili, come righe, frasi o parole. Scopri di più sulla salienza e su come utilizzarla per identificare i pregiudizi involontari nel nostro Saliency Explorable.
Iniziamo fornendo al prompt un nuovo input di esempio per le variabili del modello di prompt:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
Se hai aperto la UI di LIT nella cella sopra o in una scheda separata, puoi utilizzare l'editor di punti dati di LIT per aggiungere questo prompt:
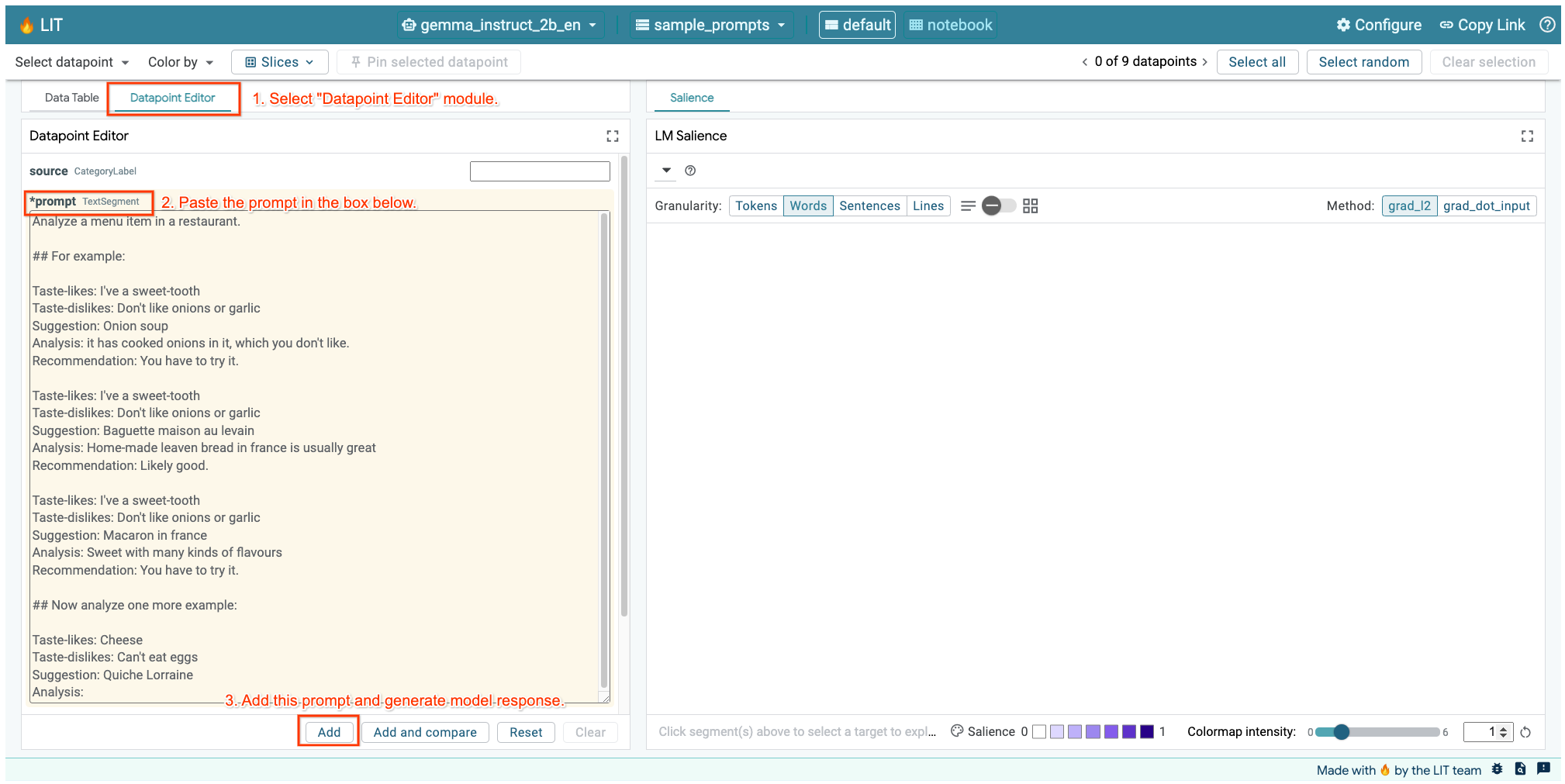
Un altro modo è eseguire nuovamente il rendering del widget direttamente con il prompt di interesse:
lit_widget.render(data=[fewshot_mistake_example])
Prendi nota del completamento sorprendente del modello:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
Perché il modello ti suggerisce di mangiare qualcosa che hai chiaramente detto di non poter mangiare?
La salienza della sequenza può contribuire a evidenziare il problema principale, che si trova nei nostri esempi few-shot. Nel primo esempio, il ragionamento della catena di pensiero nella sezione di analisi it has cooked onions in it, which you don't like non corrisponde al consiglio finale You have to try it.
Nel modulo LM Salience, seleziona "Frasi" e poi la riga del suggerimento. L'interfaccia utente ora dovrebbe avere il seguente aspetto:
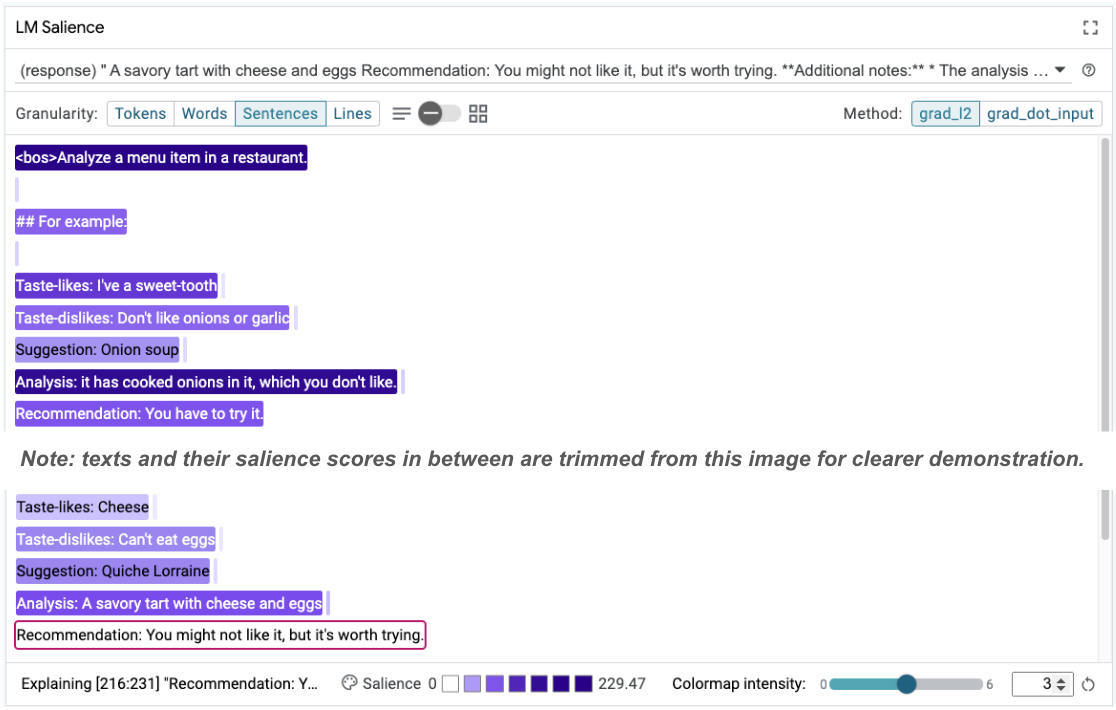
Ciò evidenzia un errore umano: un copia e incolla accidentale della parte del suggerimento e il mancato aggiornamento.
Ora correggiamo "Recommendation" nel primo esempio impostando Avoid e riproviamo. LIT ha precaricato questo esempio nei prompt di esempio, quindi puoi utilizzare questa piccola funzione di utilità per recuperarlo:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
Ora il completamento del modello diventa:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
Un insegnamento importante da trarre è che la prototipazione precoce aiuta a rivelare rischi che potresti non considerare in anticipo e la natura soggetta a errori dei modelli linguistici implica che è necessario progettare in modo proattivo per gli errori. Per ulteriori informazioni, consulta la nostra guida People + AI per la progettazione con l'AI.
Anche se il prompt di correzione con pochi esempi è migliore, non è ancora del tutto corretto: indica correttamente all'utente di evitare le uova, ma il ragionamento non è giusto, dice che non gli piacciono le uova, quando in realtà l'utente ha dichiarato di non poterle mangiare. Nella sezione seguente, vedrai come puoi migliorare.
7. Testare le ipotesi per migliorare il comportamento del modello
LIT ti consente di testare le modifiche ai prompt all'interno della stessa interfaccia. In questo caso, testerai l'aggiunta di una costituzione per migliorare il comportamento del modello. Le costituzioni si riferiscono a prompt di progettazione con principi per guidare la generazione del modello. I metodi recenti consentono persino la derivazione interattiva dei principi costituzionali.
Utilizziamo questa idea per migliorare ulteriormente il prompt. Aggiungi una sezione con i principi per la generazione nella parte superiore del prompt, che ora inizia come segue:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
Con questo aggiornamento, l'esempio può essere eseguito di nuovo e osservare un output molto diverso:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
La salienza del prompt può quindi essere riesaminata per capire perché si verifica questa modifica:
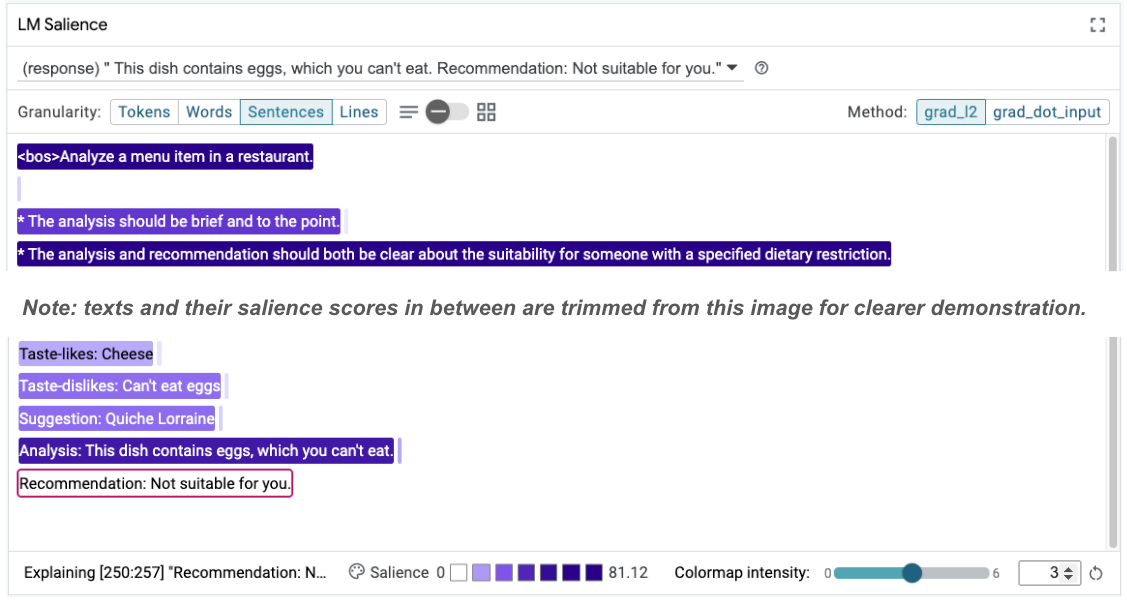
Nota che il consiglio è molto più sicuro. Inoltre, la dicitura "Non adatto a te" è influenzata dal principio di indicare chiaramente l'idoneità in base alla restrizione alimentare, insieme all'analisi (la cosiddetta catena di pensiero). In questo modo, avrai la certezza che l'output viene generato per il giusto motivo.
8. Includere team non tecnici nell'analisi e nell'esplorazione dei modelli
L'interpretabilità è pensata per essere un lavoro di squadra, che abbraccia competenze in XAI, policy, ambito legale e altro ancora.
L'interazione con i modelli nelle prime fasi di sviluppo ha sempre richiesto competenze tecniche significative, il che ha reso più difficile per alcuni collaboratori accedervi e analizzarli. Storicamente, non sono mai esistiti strumenti che consentissero a questi team di partecipare alle prime fasi di prototipazione.
L'obiettivo di LIT è cambiare questo paradigma. Come hai visto in questo codelab, il mezzo visivo e la capacità interattiva di LIT di esaminare la salienza ed esplorare gli esempi possono aiutare i diversi stakeholder a condividere e comunicare i risultati. In questo modo, puoi coinvolgere un gruppo più eterogeneo di colleghi per l'esplorazione, il test e il debug del modello. Se vengono esposti a questi metodi tecnici, possono comprendere meglio il funzionamento dei modelli. Inoltre, un insieme più diversificato di competenze nei test iniziali del modello può anche contribuire a scoprire risultati indesiderati che possono essere migliorati.
9. Riepilogo
Riepilogo:
- La GUI LIT fornisce un'interfaccia per l'esecuzione interattiva del modello, consentendo agli utenti di generare direttamente gli output e testare gli scenari "what if". Ciò è particolarmente utile per testare diverse varianti di prompt.
- Il modulo LM Salience fornisce una rappresentazione visiva della salienza e una granularità controllabile dei dati, in modo da poter comunicare su costrutti incentrati sull'uomo (ad es. frasi e parole) anziché su costrutti incentrati sul modello (ad es. token).
Quando trovi esempi problematici nelle valutazioni del modello, importali in LIT per il debug. Inizia analizzando l'unità di contenuti più grande e sensata che ti viene in mente e che si riferisce logicamente all'attività di modellazione, utilizza le visualizzazioni per vedere dove il modello presta attenzione correttamente o meno ai contenuti del prompt, quindi esamina in dettaglio unità di contenuti più piccole per descrivere ulteriormente il comportamento errato che stai osservando al fine di identificare possibili correzioni.
Infine, Lit è in continuo miglioramento. Scopri di più sulle nostre funzionalità e condividi i tuoi suggerimenti qui.